들어가며
getWorkInfosByTagFlow()는 단순 이벤트 버스처럼 생겼지만, 이벤트 스트림이 아닌 데이터베이스 쿼리입니다.
WorkManager는 Android 생태계에서 지연 가능한 백그라운드 작업을 스케줄링하는 데 가장 신뢰할 수 있는 도구 중 하나입니다. 프로세스 종료, 기기 재부팅, OS 수준의 제약 조건 처리까지 기본적으로 제공합니다. 대부분의 경우에는 Worker를 enqueue하고, 결과를 관측하면 그만입니다.
상황
사진 여러 장을 업로드하는 기능을 구현한다고 가정합니다. 각 사진을 독립적으로 처리하고 싶어서, 사진마다 별도의 Worker를 enqueue하는 설계를 선택했습니다.
photos.forEach { photo ->
val request = OneTimeWorkRequestBuilder<UploadWorker>()
.addTag(UPLOAD_TAG)
.setInputData(workDataOf("photo_id" to photo.id))
.build()
workManager.enqueue(request)
}N개의 Worker를 각각의 식별자로 추적하는 것은 번거로우므로, 대신 공통 태그 하나로 묶어서 전체 진행 상황을 한 번에 집계하도록 할 수 있습니다.
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.map { infos ->
val succeeded = infos.count { it.state == WorkInfo.State.SUCCEEDED }
val total = infos.size
UploadState(succeeded = succeeded, total = total)
}
.collect { state -> updateProgressUI(state) }하지만 getWorkInfosByTagFlow()가 일반적인 Flow 형태를 반환하는 특성으로 인해 구현 중 치명적인 실수를 하기 쉽습니다.
이 API는 겉보기에 반응형처럼 느껴집니다. Flow를 반환하고, WorkInfo 업데이트를 발행합니다. 데이터를 받아보는 측에서 단순히 구독만 하면 되는 것으로 느껴지기 쉽습니다.
하지만 문제는 WorkManager가 이벤트 시스템이 아니라는 것입니다. WorkManager는 Room 데이터베이스로 뒷받침되는 영속적인 작업 큐이며, 이것이 노출하는 모든 Flow는 데이터베이스 쿼리로부터 나오는 것들입니다.
이 글에서는 WorkManager가 내부적으로 어떻게 동작하는지, 개발자가 이 멘탈 모델을 건너뛸 때 어떤 문제가 생기는지, 그리고 작업 결과를 안전하게 관측하는 처리 방법을 살펴봅니다.
WorkManager의 내부 동작 원리
WorkManager는 설계부터 영속적이다
WorkManager는 Room 데이터베이스로 작업 큐를 관리합니다. enqueue된 모든 Worker와 그 상태는 디스크에 기록되며, 핵심 테이블은 세 가지입니다.
- workspec: enqueue된 Worker 한 개당 한 행. Worker 클래스 이름, 상태(state enum), 입출력
Data, 백오프 정책, 제약 조건(네트워크 타입, 충전 여부 등), 실행 시도 횟수가 담깁니다. 이 데이터가 이른바 source of truth입니다. - worktag: Worker ID와 문자열 태그 간의 다대다 조인 테이블로,
getWorkInfosByTagFlow()같은 메서드를 호출하면 이 테이블을 쿼리합니다. - workprogress: Worker가
RUNNING상태일 때setProgressAsync()로 emit되는 중간 진행 상황.
이 영속성은 의도적인 설계입니다. WorkManager는 프로세스 종료, 기기 재부팅, OS 수준의 킬(kill)에서도 살아남도록 설계되었습니다. 영속성은 버그가 아니라 기능입니다.
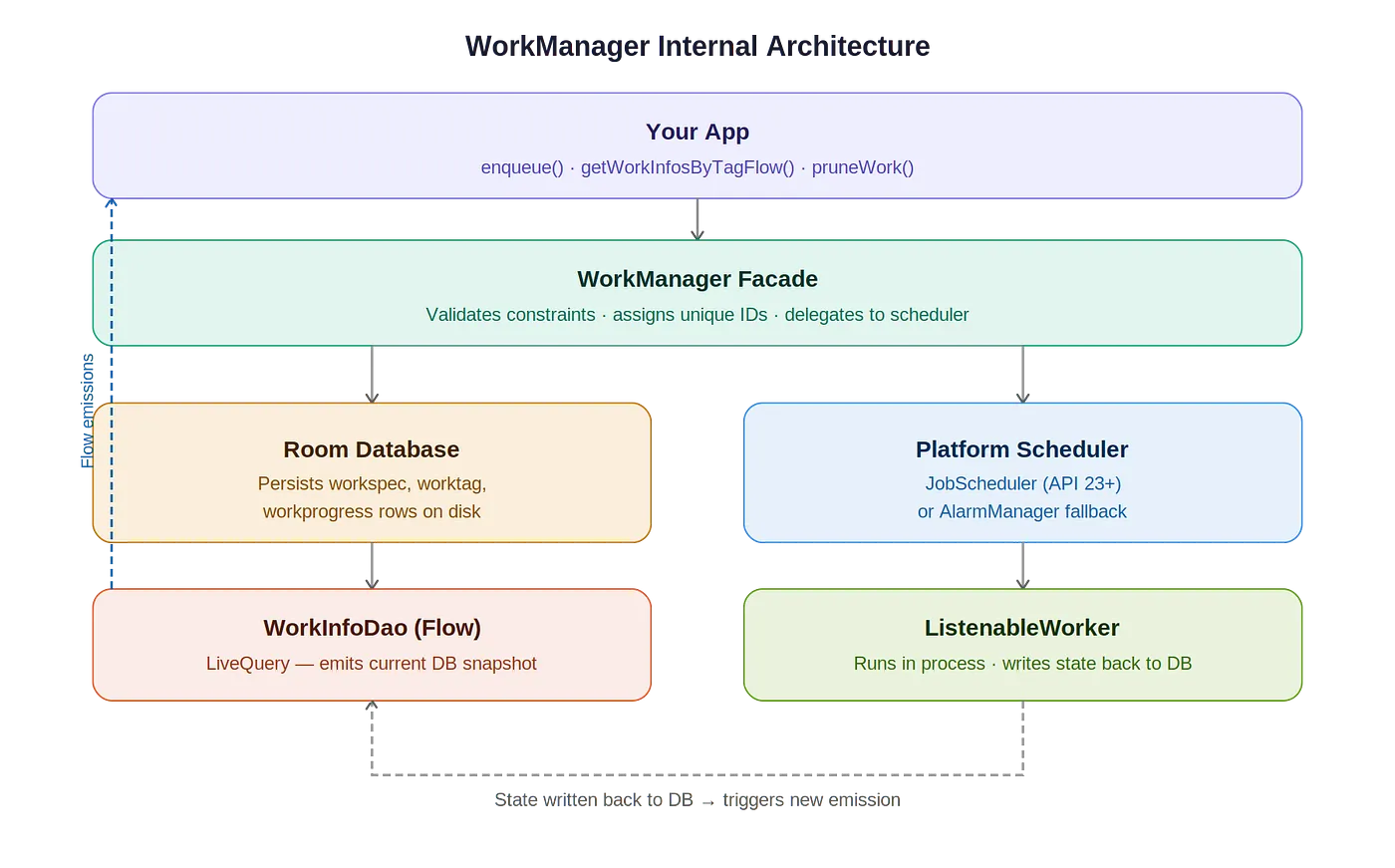
getWorkInfosByTagFlow()는 이벤트 스트림이 아닌 데이터베이스 쿼리다
Work들에 관한 데이터를 구독할 때, 아래와 같은 메서드를 많이 사용합니다.
workManager.getWorkInfosByTagFlow(tag)이는 미래의 이벤트를 위한 리스너를 등록하는 것이 아닙니다. Room 쿼리로 뒷받침된 Flow를 구독하는 것입니다. WorkManager는 worktag와 workspec 테이블을 태그로 조인하고, 매칭되는 각 행을 WorkInfo 객체로 래핑합니다. 이 Flow는 Room의 InvalidationTracker로 구동되므로, 두 테이블 중 어느 하나에 쓰기가 발생하면 새로운 발행이 트리거됩니다.
구독 즉시 해당 태그와 매칭되는 모든 영속화된 Worker의 현재 스냅샷이 발행됩니다. 여기에는 pruneWork() 메서드가 호출되기 이전까지의 모든 Worker들까지 포함됩니다.
ListenableWorker 실행 모델
WorkManager에서는 백그라운드 작업을 위해 ListenableWorker로 실행을 감싼 형태를 사용합니다. CoroutineWorker가 가장 일반적으로 사용되는 ListenableWorker의 서브클래스입니다. 단일 실행 중의 라이프사이클은 다음과 같습니다.
- 플랫폼 스케줄러(API 23+에서는 JobScheduler, 그 이하에서는 AlarmManager)가 제약 조건에 따라 실행을 트리거
- WorkManager가 Room에서
WorkSpec을 꺼내WorkerFactory를 통해 Worker 클래스를 인스턴스화하고,startWork()/doWork()를 호출 - Worker의 반환 값(
Result.success(),Result.failure(),Result.retry())이workspec테이블에 상태 전환으로 기록 - 해당 쓰기가
getWorkInfosByTagFlow()의 Room 쿼리를 무효화하여 새로운 발행 트리거
Worker가 Result.retry()를 반환하면, ENQUEUED 상태로 다시 전환되며, 동시에 시도 횟수가 동일한 행에서 증가하게 됩니다. runAttemptCount가 설정된 최대 재시도 횟수를 초과하면 Worker는 FAILED로 전환됩니다.
WorkInfo 상태 라이프사이클
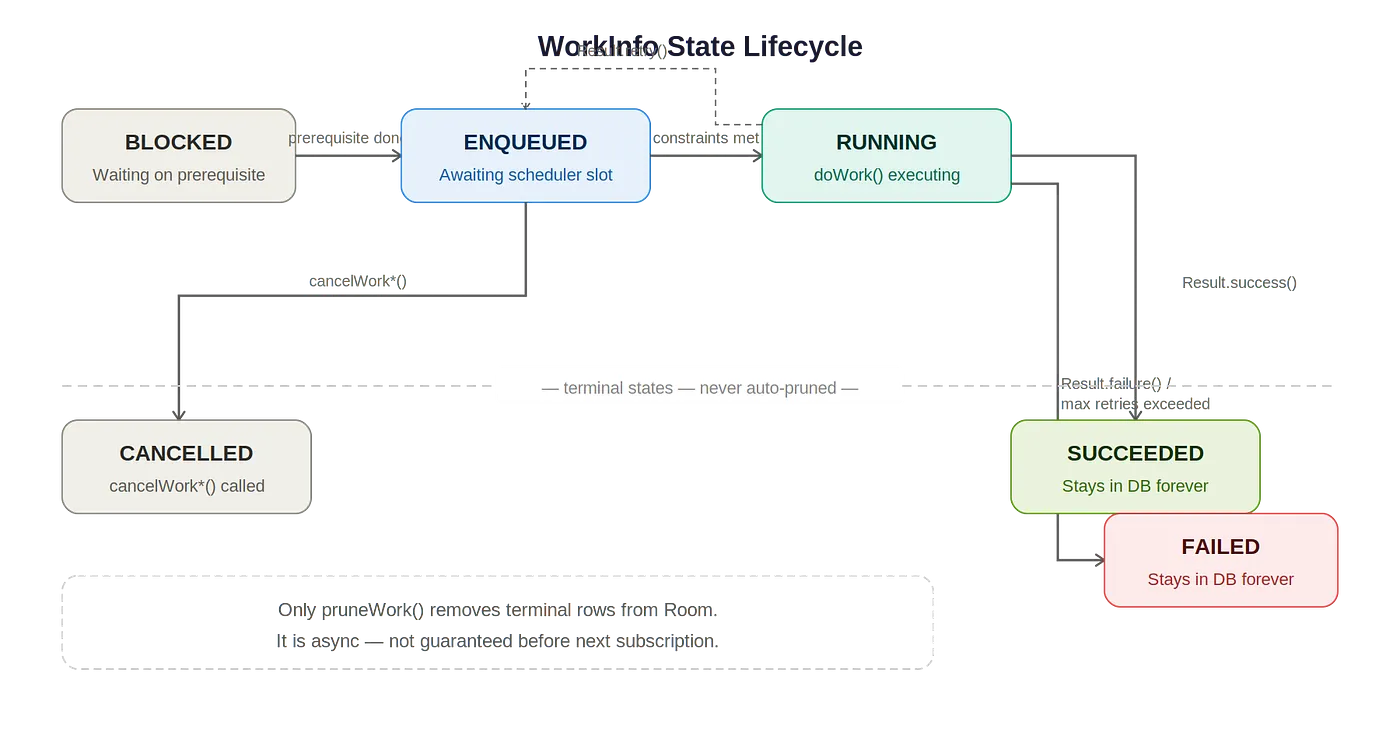
최종 상태까지 온(SUCCEEDED, FAILED, CANCELLED) Worker들은 자동으로 DB에서 제거되지 않습니다. WorkManager.pruneWork()를 명시적으로 호출하기 전까지 WorkManager 데이터베이스에 남아 있습니다.
ExistingWorkPolicy와 Stale State의 관계
이름이나 태그가 있는 작업을 enqueue할 때, 같은 이름/태그의 Worker가 이미 존재하는 경우 어떻게 처리할지 결정해야 합니다. 이 결정이 Flow에 나타나는 내용에 직접 영향을 줍니다.
REPLACE: 실행 중인 Worker를 포함하여 기존 Worker를 취소하고 새 것을 enqueue합니다. 기존 Worker는CANCELLED로 전환되며, 이 역시 DB에 남습니다.KEEP: 최종 상태가 아닌(ENQUEUED, RUNNING) Worker가 이미 존재하면, 새enqueue()호출은 no-op입니다. 최종 상태로 존재하는 경우, 새 Worker가 fresh하게 enqueue됩니다.SUCCEEDED행은 다음 enqueue 전까지 남아 있습니다.APPEND/APPEND_OR_REPLACE: Worker를 순차적으로 체인합니다. 새 Worker는 선행 작업이 완료될 때까지BLOCKED상태로 진입합니다.
최종으로 받아본 상태가 자동으로 제거되지 않는 이유
이것은 의도적인 설계라 볼 수 있습니다. 최종 상태까지 완료된 Worker의 행들이 자동으로 제거된다면, WorkManager는 다음을 할 수 없게 됩니다.
- 재부팅 후 중복 실행을 방지하기 위해 이전에 예약된 작업이 이미 실행되었음을 감지하는 것
- 완료 후 구독하는 호출자에게 완료된 Worker의 출력 데이터(
WorkInfo.outputData)를 노출하는 것 (분할 화면이나 백그라운드 상태에서 재개하는 Activity에서 흔한 패턴) - 선행 작업의
SUCCEEDED또는FAILED결과에 의존하는 체인된 Worker에 최종 상태를 전달하는 것
pruneWork()는 명시적인 옵트인 정리 수단으로 존재하지만, 비동기로 실행되며 다음 구독이 실행되기 전에 완료된다는 보장이 없습니다.
위험한 가정
사실 직접 작업을 하기 전에는 이렇게 생각하곤 했습니다.
Flow에서
SUCCEEDED를 보면 Worker가 방금 완료된 것이다.
하지만 진실은 이렇습니다.
SUCCEEDED는 어느 시점에 완료되었음을 의미한다. 이전 세션에서 몇 시간 혹은 며칠 전에 완료된 것일 수 있다.
Cold Flow처럼 다루면 어떻게 될까?
흔하게 등장하는 오해와 실제 동작을 하나씩 살펴보겠습니다.
오해 1. 첫 번째로 발행된 데이터는 가장 최근에 enqueue한 작업의 현재 상태이다?
Flow를 구독하면 현재 세션에서 방금 시작한 Worker의 상태가 올까?
// ❌ 이전 세션의 SUCCEEDED Worker가 있다면 새 Worker 실행 전에 즉시 resolve
workManager.enqueue(uploadRequest)
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.first { it.any { info -> info.state == WorkInfo.State.SUCCEEDED } }이 태그에 이전 세션에서 성공한 Worker가 하나라도 존재한다면, first는 새로 enqueue한 Worker가 스케줄러에 픽업되기도 전에 첫 번째 발행에서 즉시 종료됩니다. 방금 enqueue한 작업은 실제로 관측되지 않습니다.
Tag 기반 Flow의 첫 발행은 DB 스냅샷이므로, UUID 등 특정 식별자로 특정 Worker를 직접 구독해야 합니다.
// ✅ 새로 enqueue한 Worker의 UUID를 먼저 추적
val request = OneTimeWorkRequestBuilder<UploadWorker>()
.build()
val workId = request.id
workManager.enqueue(request)
workManager.getWorkInfoByIdFlow(workId)
.filter { it?.state == WorkInfo.State.SUCCEEDED }오해 2. drop(1)으로 초기 stale 데이터의 발행을 건너뛸 수 있다?
첫 번째 발행이 과거 데이터라면, drop(1)으로 한 번만 건너뛰면 될까?
// ❌ emission 하나를 건너뛸 뿐,
// 새 Worker enqueue 전에 WorkManager가 여러 번 emit할 가능성도 존재
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.drop(1)
.map { ... }drop(1)은 첫 발행을 건너뛸 뿐, 세션 하나를 건너뛰는 것이 아닙니다. 제약 조건 재평가나 스케줄러 혼잡(churn)으로 인해 새 Worker가 enqueue되기 전에 WorkManager가 여러 번 emit될 수 있습니다. 이전 stale 데이터의 수가 정확히 하나임은 보장되지 않습니다.
제약 조건 재평가나 스케줄러 혼잡으로 새 Worker enqueue 전에 여러 번 emit될 수 있기 때문입니다. 발행된 데이터 개수가 아닌 Worker의 신원(여기서는 UUID)으로 필터링해야 합니다.
// ✅ scan으로 현재 세션에서 ENQUEUED/RUNNING을 관측한 UUID를 누적해서 추적
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.scan(emptySet<UUID>() to emptyList<WorkInfo>()) { (prevIds, _), infos ->
val activeIds = infos
.filter { it.state == WorkInfo.State.ENQUEUED ||
it.state == WorkInfo.State.RUNNING }
.map { it.id }.toSet()
(prevIds + activeIds) to infos.filter { it.id in prevIds + activeIds }
}오해 3. Flow에서 SUCCEEDED를 보면 작업이 방금 완료된 것이다
Flow에서 SUCCEEDED 상태를 받으면 해당 작업이 현재 세션에서 막 끝난 것이라고 볼 수 있을까?
// ❌ 훨씬 이전에 성공한 Worker도 DB에 SUCCEEDED로 남아 있을 수 있음
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.filter { infos -> infos.any { it.state == WorkInfo.State.SUCCEEDED } }
.collect { showSuccessBadge() }SUCCEEDED는 영속화된 상태이지, 이벤트가 아닙니다. WorkManager는 pruneWork()를 명시적으로 호출하기 전까지 최종으로 확인한 상태들을 DB에 보존합니다. 즉 이전 실행 기록이 그대로 남습니다.
따라서 이전에 성공한 Worker가 데이터베이스에 SUCCEEDED로 남아 있을 수 있습니다. 이전 실행이 성공적으로 끝난 적이 있다면, 이 collector는 앱이 실행될 때마다 cold start 시점에 즉시 실행됩니다.
// ✅ 현재 세션에서 활성 상태를 거친 Worker만 평가해서 SUCCEEDED 처리
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.scan(...) // UUID 누적 추적
.drop(1)
.map { (_, infos) ->
when {
infos.any { it.state == WorkInfo.State.SUCCEEDED } ->
Result.success(Unit)
else -> null
}
}
.filterNotNull()
.collect { showSuccessBadge() }오해 4. 최종 상태를 확인하고 collection을 취소하면 된다
최종 상태(SUCCEEDED/FAILED/CANCELLED)를 확인하고 first로 종료하면 새 작업 완료 소식을 정확히 받아볼 수 있을까?
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.first { infos -> infos.any { it.state.isFinished } }isFinished는 SUCCEEDED, FAILED, CANCELLED 모두에서 true를 반환합니다. SUCCEEDED, FAILED, CANCELLED 모두 이전 세션에서 영속화된 상태로 남을 수 있습니다. 단순히 isFinished를 체크하면 first 연산자는 어떤 새 작업도 실행되지 않은 채 초기 emission에서 바로 종료됩니다.
// ✅ 현재 세션 식별자를 추적한 뒤 해당 ID가 최종 상태가 됐을 때만 종료
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.scan(emptySet<UUID>() to emptyList<WorkInfo>()) { (prevIds, _), infos ->
val nowActive = infos.filter {
it.state == WorkInfo.State.ENQUEUED ||
it.state == WorkInfo.State.RUNNING
}.map { it.id }.toSet()
(prevIds + nowActive) to infos.filter { it.id in prevIds + nowActive }
}
.drop(1)
.first { (_, infos) -> infos.any { it.state.isFinished } }오해 5. runAttemptCount > 0으로 필터링하면 stale Worker를 제외할 수 있다
아직 실행되지 않은 새 Worker는 runAttemptCount가 0일 테니, 이보다 큰 것만 보면 과거 데이터를 걸러낼 수 있을까?
// ❌ runAttemptCount도 DB에 영속화
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.map { infos -> infos.filter { it.runAttemptCount > 0 } }runAttemptCount는 상태와 마찬가지로 workspec 행에 저장되며 세션을 가로질러 영속됩니다. 지난주에 두 번 재시도된 Worker는 오늘도 runAttemptCount = 2로 DB에 남아 있습니다. 이 필터로는 현재 세션의 Worker와 과거의 것을 구분할 수 없습니다.
그 이유는 runAttemptCount는 state와 동일하게 workspec 테이블에 영속화되기 때문입니다. 이 값으로는 현재 세션의 Worker와 과거 세션의 Worker를 구분할 수 없습니다. 유일한 기준은 현재 세션에서 활성 상태를 관측했는지 여부입니다.
// ✅ runAttemptCount 대신 ENQUEUED/RUNNING 상태 관측 이력으로 현재 세션 Worker를 식별
workManager.getWorkInfosByTagFlow(UPLOAD_TAG)
.scan(emptySet<UUID>() to emptyList<WorkInfo>()) { (prevIds, _), infos ->
val nowActive = infos
.filter { it.state == WorkInfo.State.ENQUEUED ||
it.state == WorkInfo.State.RUNNING }
.map { it.id }.toSet()
(prevIds + nowActive) to
infos.filter { it.id in prevIds + nowActive }
}
.drop(1)왜 이런 오해가 생기는가
위 패턴들은 모두 동일한 잘못된 가정을 공유합니다. Flow의 발행이 현재 세션에 범위가 지정된 이벤트라는 것입니다. 그렇지 않습니다. 모든 발행은 WorkManager가 해당 태그에 대해 지금껏 영속화한 모든 것을 포함하는 데이터베이스 스냅샷입니다. 현재 세션에서 관측한 Worker의 신원에 로직을 고정하지 않으면, 현재가 아닌 과거에 반응하게 됩니다.
처리 예시: 식별자 기반 세션 추적
앞서 살펴본 문제를 피하는 한 가지 접근법은 상태만으로 필터링하는 대신, Worker의 식별자를 추적하는 것입니다. 현재 세션에서 ENQUEUED 혹은 RUNNING으로 관측된 Worker의 ID에 대해서만 최종 상태를 평가합니다.
workManager.getWorkInfosByTagFlow(UPLOAD_WORK_TAG)
.scan(emptySet<UUID>() to emptyList<WorkInfo>()) { (prevActiveWorkIds, _), infos ->
val currentActiveWorkIds = infos
.filter {
it.state == WorkInfo.State.ENQUEUED ||
it.state == WorkInfo.State.RUNNING
}
.map { it.id }
.toSet()
val activeWorkIds = prevActiveWorkIds + currentActiveWorkIds
currentActiveWorkIds to infos.filter { it.id in activeWorkIds }
}
.drop(1)
.map { (_, infos) ->
when {
infos.isEmpty() -> null
infos.any { it.state == WorkInfo.State.SUCCEEDED } ->
Result.success(Unit)
infos.all { it.state == WorkInfo.State.FAILED } ->
Result.failure(Exception("all workers failed"))
else -> null
}
}
.filterNotNull()scan 누산기의 동작 방식
| 단계 | 발생하는 일 |
|---|---|
Cold start, DB에 stale SUCCEEDED Worker 존재 | currentActiveWorkIds가 비어 있음. activeWorkIds도 비어 있음. 필터된 infos → 비어 있음 → null emit |
| 새 Worker enqueue됨 | 해당 ID가 currentActiveWorkIds에 진입. activeWorkIds에 새 ID가 포함됨 |
Worker가 SUCCEEDED로 전환됨 | 해당 ID는 이전 iteration의 prevActiveWorkIds에 여전히 존재. activeWorkIds에 포함됨 → 평가됨 → Result.success(Unit) emit |
| 다음 emission | currentActiveWorkIds가 다시 비어 있음. prevActiveWorkIds는 앞으로 이어지지 않음 → 재평가되지 않음 |
prevActiveWorkIds는 하나의 emission 메모리로 동작합니다. 최종 상태까지 간 Worker가 정확히 한 번, 완료된 직후의 emission에서 평가되고, 이후 버려지도록 합니다.
대안 : SharedFlow 등 이벤트 버스 활용
WorkManager의 결과를 직접 관측하기보다 앱 내부 이벤트 버스 역할로 SharedFlow를 쓰는 패턴도 흔합니다.
이렇게 하면 ViewModel이나 UI에서는 WorkManager의 DB 스냅샷 특성을 전혀 몰라도 됩니다. WorkManager의 영속성은 보장하면서, 관측 레이어는 순수한 이벤트 스트림처럼 쓸 수 있습니다.
WorkManager의 stale 특성이 부담스럽다면 내부적으로 식별자 관측을 격리하고 외부에는 SharedFlow로 깔끔한 이벤트를 노출하는 패턴을 쓰는 것이 실용적입니다.
// Repository
private val _uploadResult = MutableSharedFlow<Result<Unit>>()
val uploadResult: SharedFlow<Result<Unit>> = _uploadResult
suspend fun upload() {
val request = OneTimeWorkRequestBuilder<UploadWorker>().build()
workManager.enqueue(request)
// Worker 완료를 UUID로 정확히 추적해 외부로 이벤트 발행
workManager.getWorkInfoByIdFlow(request.id)
.filter { it?.state?.isFinished == true }
.first()
.let { info ->
if (info?.state == WorkInfo.State.SUCCEEDED)
_uploadResult.emit(Result.success(Unit))
else
_uploadResult.emit(Result.failure(Exception("failed")))
}
}마치며
-
getWorkInfosByTagFlow()는 세션 범위가 아니다
첫 번째 emission을 실시간 이벤트가 아닌 과거의 스냅샷으로 다루는 것이 중요합니다. -
워커의 최종 상태만으로 필터링하지 말라
SUCCEEDED는 "어느 시점에 성공했음"을 의미합니다. "방금 성공했음"이 아닙니다. -
stateful한 Flow 변환에는 scan이 적합하다
emission을 가로질러 관측한 것을 추적해야 할 때,scan이 정확히 그 누산기 패턴을 제공합니다. -
pruneWork()에 의존하지 말라
가능하면 prune하되,pruneWork()없이도 안전하게 동작하도록 하는 것이 중요합니다. -
ExistingWorkPolicy도 중요하다
DB에 존재하는 행과 cold start 시 Flow가 emit하는 내용에 직접 영향을 줍니다.
참고 자료
