1. 데이터 종속성(data dependency)에 대한 가장 적절한 설명은?
가) 응용 프로그램에 대한 변경 없이 접근 전략을 변경할 수 있다.
나) 데이터의 저장 방식과 접근 전략이 응용 프로그램의 내부 구조에 반영되어 있다.
다) 서로 다른 응용 프로그램이 같은 데이터에 대해 서로 다른 뷰를 필요로 한다.
라) 응용 프로그램에 영향을 미치지 않고 저장구조의 변경이 가능하다.
2. 고급 수준의 물리적 독립성을 갖는 시스템에서 안전하게 수행할 수 있는 물리적인 변경의 예로 적합하지 않는 것은?
가) 하나의 디스크 장치에서 다른 디스크 장치로 화일을 이동
나) 새로운 사용자 뷰들을 추가
다) 새로운 데이터 화일을 추가
라) 데이터 화일의 이름을 변경
3. 시스템 카탈로그에 대한 설명이 올바른 것은?
가) 시스템 카탈로그는 하나의 기본 테이블에 대해 하나씩 만들어 진다.
나) 사용자는 접근할 수 없고 시스템만 접근할 수 있다.
다) 카탈로그에 저장된 정보를 SQL의 UPDATE, DELETE, INSERT 문으로 사용자가 갱신할 수 있다.
라) 테이블 정보, 인덱스 정보, 뷰 정보 등을 저장하는 시스템 테이블로 구성된다.
4. SQL의 뷰(view)에 대한 설명으로 옳지 않는 것은?
가) 하나 이상의 테이블에서 유도되는 가상 테이블이다.
나) 뷰 정의문과 데이터가 물리적 구조로 생성된다.
다) 뷰에 기반한 또 다른 뷰의 생성이 가능하다.
라) 뷰의 활용은 기본 테이블과 동일하다.
5. 한 주문서(order)에 여러 개의 제품(product)을 포함할 수 있으며, 한 제품은 여러 개의 주문서에 포함될 수 있다고 가정한다. 이것은 어떤 형태의 관계(relationship)인가?
가) one-to-one
나) one-to-many
다) many-to-one
라) many-to-many
6. Weak entity의 설명으로 적합하지 않는 것은?
가) An entity set that does not have a primary key.
나) An entity set that depends on the existence of a identifying entity set.
다) The discriminator is the set of attributes that distinguishes among all the entities of a weak entity set.
라) We depict a weak entity set by rectangles in ERD.
7. Generalization의 design 제약사항으로 적합하지 않는 것은?
가) Condition-defined
나) Disjoint
다) Total
라) Role
8. 릴레이션의 모든 튜플들에 대해 유일성은 만족시키지만 최소성은 만족시키지 못하는 키를 무엇이라 하는가?
가) 후보키
나) 슈퍼키
다) 기본키
라) 외래키
9. 논리적 데이터 독립성(logical data independence)에 적합한 것은?
가) 기존의 데이터베이스 사용자와 프로세스를 방해하지 않고 물리적 데이터베이스로부터 데이터를 자유롭게 삭제할 수 있다.
나) ANSI/SPARC 모델의 논리적 계층과 물리적 계층의 분리를 통해서 성취된다.
다) ANSI/SPARC 모델의 논리적 계층과 외부(external) 계층의 분리를 통해서 성취된다.
라) 모든 컴퓨터 시스템이 어느 정도 갖는 특성이다.
10. ODBC(Open Database Connectivity)의 설명으로 적당하지 않는 것은?
가) A Standard API for connecting to DBMSs.
나) Independent of any particular language, operating system, or DBMS.
다) Used by java programs
라) Flexible in handling proprietary SQL
virtual vs transparency
virtual: 실제로 존재하지는 않지만 가상의 논리적 공간을 구현함으로써 사용자가 실제 존재하는 것처럼 사용할 수 있도록 하는 것transparency: 분산시스템에서 사용자는 마치 하나의 system을 사용하는 것처럼 사용하게 되는데 이러한 특성을 transparency라고 함- transparency에는 fragmentation transparency , replication transparency, local transparency 가 있음
total participation of ERD
ER Diagram에서 하나의 entity E가 어떤 relationship R의 participant라고 할 때, 만약 E의 모든 instance가 적어도 하나의 R의 instance에 참가하고 있으면 이를 total participation이라 한다. 이는 double line으로 나타냄
executable statements to operate on CURSOR
- OPEN, FETCH, CLOSE가 있음
OPEN statement: 결과 테이블로부터 행들을 fetch할 수 있도록 cursor를 openFETCH statement: 결과 테이블의 다음 행에 cursor를 위치시키며 target variables에 그 행의 값들을 할당CLOSE statement: cursor를 close하며, cursor가 open 되었을 때 결과 테이블이 생성되었다면 그 테이블을 삭제
데이터베이스에서 데이터에 대한 3단계 뷰(view)를 유지하는 근본적인 목적을 설명하고, 이것에 기초하여 특정 레코드의 검색과정을 단계별로 기술하라
-
3단계 뷰를 유지하는 목적
1.data의 독립성을 유지하기 위한 것
2 . 사용자가 보는 view와 data가 저장되는 방법 간에 flexibility와 adaptability를 높임 -
레코드 검색과정
1) 사용자가 외부적 뷰를 통해 특정 레코드를 검색하기 위한 질의 요청.2) External/Conceptual mapping을 통해 conceptual level의 질의로 변경됨.
3) Conceptual/Internal mapping을 통해 internal level의 질의로 변경됨.
4) Internal level에서 질의와 관련된 데이터를 찾아 반환함.
5) Conceptual/Internal mapping을 통해 conceptual schema에 맞는 형태로 변환.
6) External/Conceptual mapping을 통해 External level에 맞는 형태로 변환.
7) 질의 결과를 사용자에게 반환
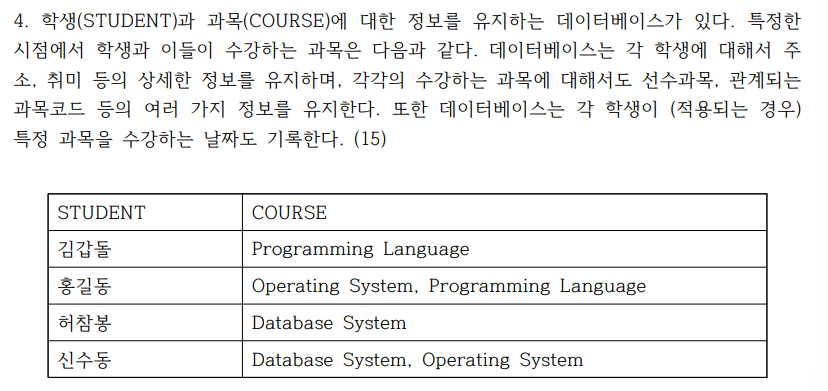
- 이러한 데이터에 대한 개체/관계(Entity/Relationship) 다이어그램을 작성하고, 적절한 관계형 구조(relational structure)를 스케치하라.
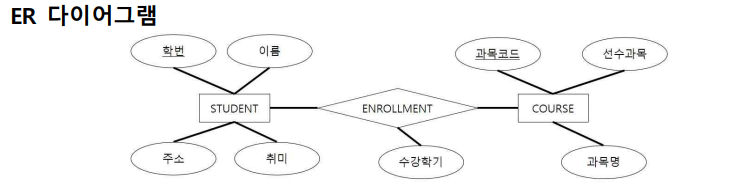
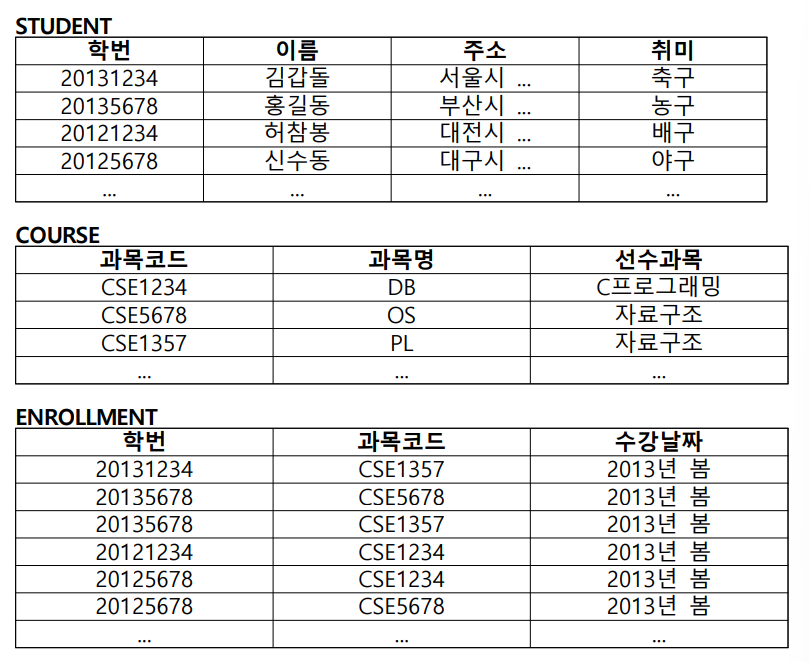
- 이러한 데이터의 두 가지 계층적 구조(hierarchical structure)를 스케치하고, 이 때 발생되는 이상(anomaly)를 설명하라.
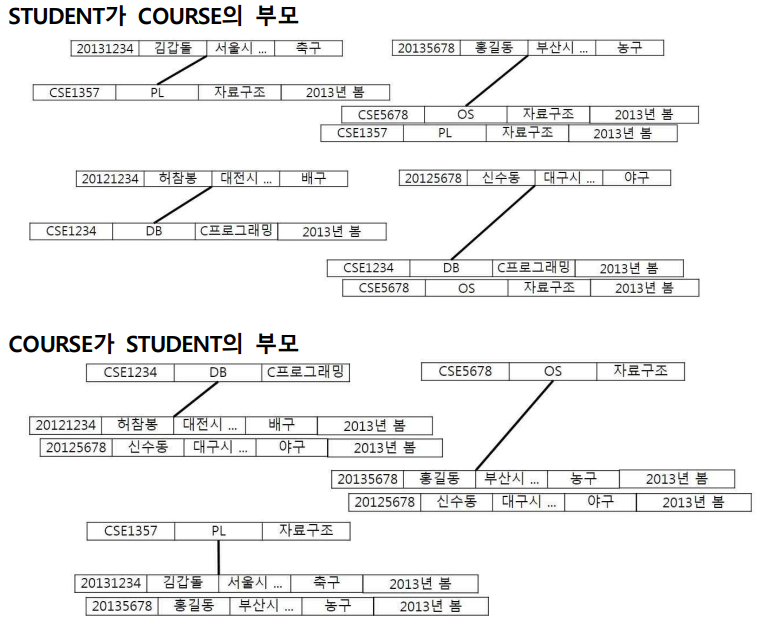
Anomaly
- 계층적 구조를 사용하는 경우 같은 데이터가 중복되어 저장
- 데이터를 삭제할 때 의도와는 상관없는 값들도 함께 삭제되는 연쇄 삭제 현상
(Deletion Anomaly)과 데이터의 속성 값을 갱신할 때 일부 데이터의 정보만 갱신되어 정보에 모순이 생기는 현상(Update Anomaly)이 발생
-
이러한 데이터의 네트워크 구조를 스케치하라
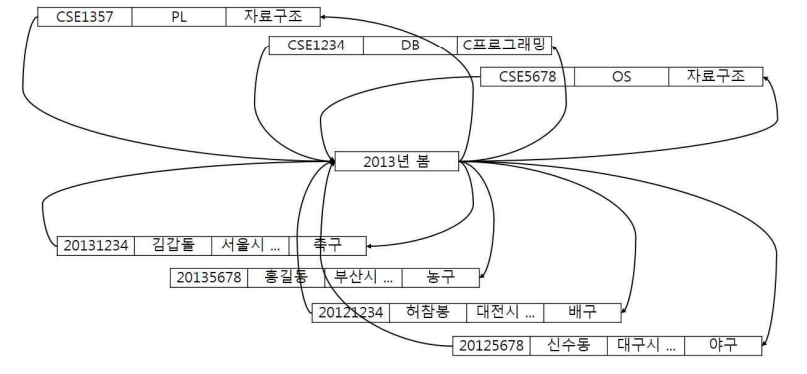
-
위의 세 가지 모델의 각 경우에 다음의 질의들의 처리과정에 대한 차이점을 설명하라.
Q1: “Database System을 수강하는 학생의 이름은?”
Q2: “홍길동이 수강하는 과목은?- 관계형 구조 : 하나의 relation에 함께 표현되어 있는 속성들을 이용해 Symmetric으로 질의처리가 가능
- 계층적 구조 :하위 계층에서 상위 계층으로 탐색이 사실상 불가능하기 때문에 Symmetric 질의 처리가 불가능
- 데이터베이스의 구조에 따라 Q1, Q2에 대한 질의 처리 형태가 달라짐
- 네트워크 구조 :Q1은 과목코드를 따라 포인터가 이동하며 Q2는 학생의 학번을 따라 포인터가 이동 (서로 다른 방향으로 포인터를 따라가며 탐색)
- Symmetric 질의 처리가 가능하나 효과적이지 못함
일반적인 Two-tier 클라 언트/서버 구조에서 발생하는 문제점을 기술하고, Three-tier 구조에서 이러한 문제들의 처리과정을 설명하라. 특히 웹 환경에 적합한 구조를 기술하고 그 이유를 설명하라. 클라이언트-데이터베이스 서버 구조를 설명하고 이것이 갖는 장점을 기술하시오.
(1) client-database server architecture 문제점
- security cost가 높아짐
- 동시에 다수의 client가 server에 접속을 할 경우 서버에 부하가 생기며 시스템 전체에 정
체 현상을 유발시킴 - fat client 문제 발생
(2)Three-tier architecture에서 client-database server architecture의 문제점 처리과정
- security를 위한 server를 따로 두어 관리
- application server를 배치하여 server의 load balancing이 쉬워짐
- fat client의 임무를 application server에 두어 client를 가볍게 함
(3)web 환경에 적합한 구조 기술
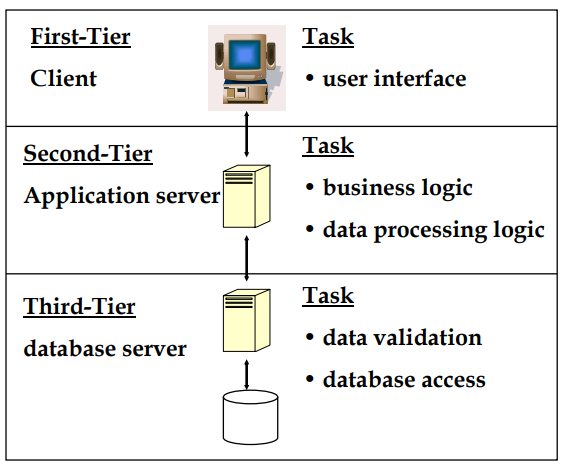
(4)web 환경에 적합한 구조의 이유 설명
-
server의 기능이 대폭 줄어 비용감소 및 관리가 쉬워짐
-
하나의 tier가 다른 tier에 영향을 끼치지 않으면서 대체되거나 수정될 수 있음
-
많은 user에 대한 business logic을 하나의 application server에 중앙 집중화 함으로써 application의 중앙집중화를 유도

가) 이 질의가 원하는 것이 무엇인가? 이 질의를 DBMS가 처리하는 과정을 설명하라.
- S릴레이션에서 STATUS > 15 인 조건을 만족하는 S#, STATUS , CITY 속성들로 이루어진 뷰 GOOD_SUPPLIER 으로부터 CITY명이 SEOUL 인 튜플들을 선택하여 속성값 S# 과 STATUS 로 이주어진 릴레이션을 구성한다.
<처리과정>
1) 뷰의 정의 sql이 시스템 카탈로그에 저장된다.
2) 실제적 질의 sql 문에서 참조된 뷰명은 시스템에서 시스템 카탈로그에 저장된 정의로 치환
된다.

3) 최적화 과정을 거쳐서다음과 같이 변환된다.
나) “Delete all shipments for suppliers whose city is given by the host variable CITY”를 Embedded SQL로 작성하라

다) 카타로그가 자술적(self-describing)이란 것은 무엇을 의미하는가? 다음의 질의는 무엇 을의미하는가?
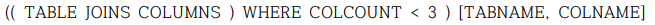
=> TABLES 와 COLUMNS를 JOIN한 후 COLCOUNT의 값이 3 미만인 table record를 가져와 그 중에 TABNAME 과 COLNAME을 출력하라는 질의
자술적(self-describing):카탈로그 안에 카탈로그 자신에 대한 정보도 포함됨을 의미
ERD에 적합한 릴레이션 스킴들을 만드는 경우를 고려한다.
가) ERD 상의 composite attribute와 multivalued attribute는 어떻게 처리하는 것이 적당한가?
-
Composite attribute는 각각의 composite attribute에 대해 separate attribute를 생성하여 나누어 처리할 수 있음
- 예) customer entity의 composite attribute인 name을 first_name과 last_name 의 separate attribute로 나누어 name.first_name과 name.last_name 으로 사용
-
Entity E의 multivalued attribute M은 separate scheme EM으로 처리된다. Scheme EM은 E의 primary key에 상응하는 attribute들을 가지며, 이 attribute은 multivalued attribute M과 상응한다.
나) ERD 상의 specialization을 어떻게 처리하는 것이 적당한가?
ISA 컴포넌트를 통해 specialization을 처리한다. 이 때, 하위 레벨의 엔티티 셋이 상위레벨의 엔티티 셋의 속성을 물려받도록 처리
- Primary 키만 상속 : 테이블의 크기가 작아져 유지관리가 쉽지만 join 연산을 통해 접근해야 하므로 검색 overhead가 큼
- 전체 속성을 상속: 검색 효율이 좋지만, 테이블의 크기가 커지므로 유지관리가 어려움
