장고 개발을 하려다 보면 테스트용 데이터는 필요한데 일일히 많이 만들기 어려울 때 활용 가능한 것이 바로 Django Seed와 Faker입니다.
또한 각 모델에 따라 OneToOneField냐, ManyToManyField냐, ForeignKeyField냐에 따라 작성하는 코드가 조금씩 달라집니다.
이하, django-admin startapp users를 통해 커스텀 users 모델을 작성하였다는 가정하에 설명하겠습니다.
1.인스톨
간단하게 아래 명령어를 터미널에 입력함으로써 인스톨 가능합니다.
pip install django-seed이 때 faker 패키지가 함께 설치됩니다.
설치 후, users/management/commands/seed-users.py를 작성합니다.
이 때, management와 commands 폴더 각각에 init.py 파일(아무 내용 없어도 됨)을 함께 작성해야 이 폴더들이 파이썬 모듈로 인식됩니다.
2.Users처럼 외부키가 전혀 없는 모델의 데이터 작성
seed_users.py
1 from django.core.management.base import BaseCommand
2 from django_seed import Seed
3 from users.models import User
4
5 class Command(BaseCommand):
6 help = "이 커맨드를 통해 랜덤한 테스트 유저 데이터를 만듭니다."
7
8 def add_arguments(self, parser):
9 parser.add_argument(
10 "--total",
11 default=2,
12 type=int,
13 help="몇 명의 유저를 만드나"
14 )
15
16 def handle(self, *args, **options):
17 total = options.get("total")
18 seeder = Seed.seeder()
19 seeder.add_entity(
20 User,
21 total,
22 {
23 "is_staff": False,
24 "nickname": lambda x: seeder.faker.name(),
25 "email": lambda x: seeder.faker.email(),
26 }
27 )
28 seeder.execute()
29 self.stdout.write(self.style.SUCCESS(f"{total}명의 유저가 작성되었습니다."))작성 후,
터미널에서 python manage.py seed_users 명령어를 실행하면 위 코드의 내용이 실행됩니다.
이 경우 데이터를 만드는 데에는 아무 바깥쪽에서의 제한은 없으나 모델 안의 각 필드, 특히 Username이나 Email 같은 경우 모든 유저가 다 달라야 하므로 lambda와 faker를 통해 랜덤값을 쥐어줍니다.
코드 설명
9~15 Lines
add_arguments를 통해 args를 추가합니다. 여기서는 --total이라는 args를 추가하며 그 뒤에 int형태의 숫자를 입력합니다. 입력되지 않을 경우 2개의 데이터를 만듭니다.
이처럼 아무런 args를 입력하지 않는 경우 default값에 따라 2개의 데이터를 만들었다고 알려줍니다.
--total 숫자를 추가하면 그만큼의 개수의 데이터가 생성됩니다.


19~29 Lines
seeder = Seed.seeder()여기서 Seeder를 만들어주는데 이것을 통해 씨를 뿌리는 준비를 한다고 보면 됩니다.
seeder.add_entity( User, total, { "is_staff": False, "nickname": lambda x: seeder.faker.name(), "email": lambda x: seeder.faker.email(), }, )add_entity에서는 엔티티를 추가하기 위한 설정을 넣어줍니다.
이름을 지정하지 않을 경우 첫번째 args는 model(모델클래스), 두번째 args는 number(int), 세번째는 customFieldFormatters(dict, default는 None)입니다.
즉, users모델의 User가 첫번째, 위에서 설정한 total이 두번째, 그 뒤로 dict 형태로 is_staff값, nickname, email을 설정했습니다."nickname": lambda x: seeder.faker.name(), "email": lambda x: seeder.faker.email(),위의 경우 nickname과 email이 lambda x를 통해 seeder.faker의 name()과 email()을 각각 설정합니다. 여기에서 임의의 이름이나 이메일주소가 자동적으로 랜덤으로 생성됩니다.
lambda x:를 빼고 seeder.faker를 사용하게 될 경우 모든 데이터가 랜덤이 아닌 똑같은 이름과 이메일을 가지게 되니 주의하시기 바랍니다.
seeder.execute()마지막으로 seeder.execute()를 실행하게 되면 여기에서 실제로 데이터 생성이 진행됩니다.

처음에 개인적으로 만들었던 superuser 하나와 위의 예에서 args 없이 만들었을 때 생성된 2 유저, 그리고 total에 30을 넣고 만들었던 users로 총 33명의 users 데이터가 존재하는 걸 볼 수 있습니다.
OneToOneField, ForeignKeyField를 가지는 모델의 데이터 생성
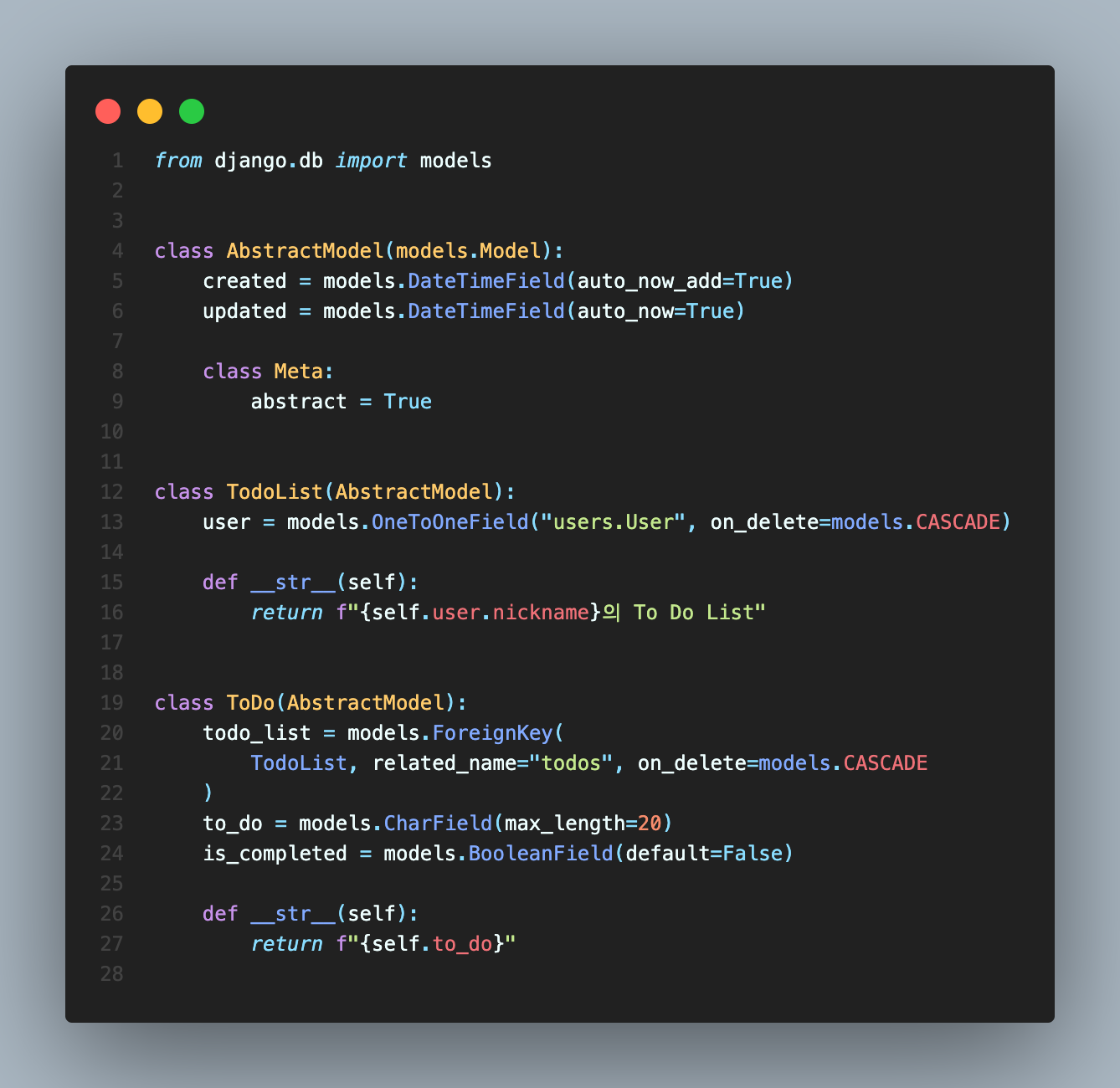
todos라는 앱 폴더의 models.py에 정의한 두 개의 모델이 있습니다.
TodoList 모델이 OneToOneField로 user 모델을 가지며, ToDo가 각 개별 To Do 하나로써 바로 위에서 정의한 TodoList를 ForeignKey로 가지면서 to_do 항목 하나, 완료가 되었는지를 체크하는 is_completed를 하나 가집니다.
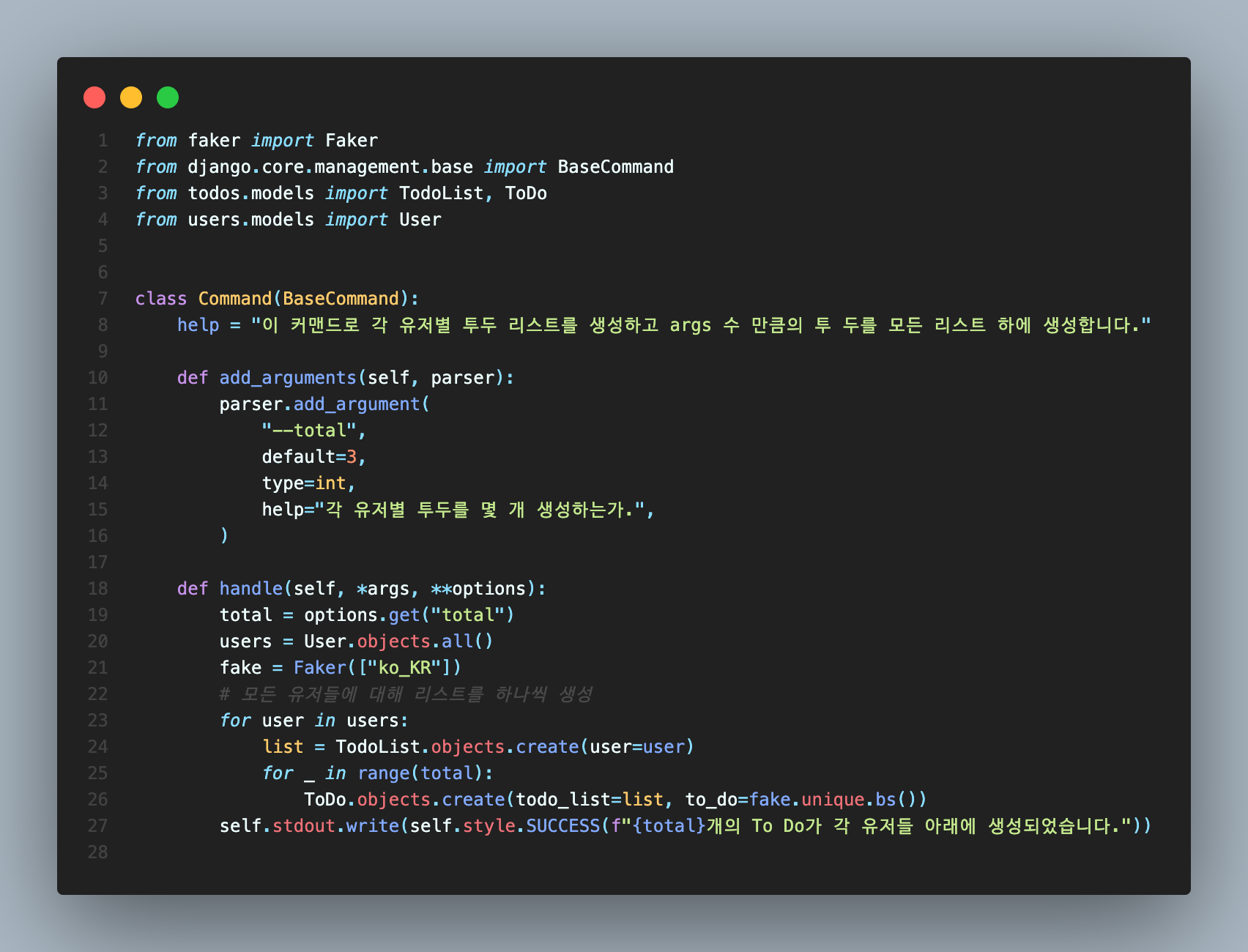
add_arguments는 위의 users에서와 같으므로 설명을 생략하고 바로 handle의 설명으로 가겠습니다.
여기에서 가장 큰 문제는 TodoList가 User와 1:1로 묶여있다는 점인데, 이 때는 users처럼 데이터를 랜덤으로 생성하게 되면 OneToOne의 Unique 설정으로 인해 에러가 나게 됩니다. 각 유저는 단 하나만의 리스트를 가져야 하기 때문입니다.
그리하여 여기에서는 seeder를 사용하지는 않으나, faker만을 따로 사용합니다.
1번째 줄과 21번째줄의
from faker import Faker fake = Faker(["ko_KR"])이렇게 해서 seeder 없이 faker를 단독으로 사용하기 위한 준비가 되었습니다.
Faker 안에 ["ko_KR"]을 넣은 것은 한국의 지역 설정입니다.
모든 유저 쿼리셋을 준비한 뒤 23번째줄에서 for문을 통해 모든 유저를 순회합니다.
(이 때 주의할 점은 OneToOne이므로 리스트가 하나라도 존재하면 모든 유저 순회 시에 에러가 나기 때문에 기존 데이터를 제거하고 작업해야 합니다.)
24번째 줄의list = TodoList.objects.create(user=user)는 각 유저에 대해 TodoList 모델의 오브젝트를 생성하고 각 오브젝트를 한 번씩 list 변수에 저장합니다.
여기에서 저는 각 유저별 TodoList 하에 한 리스트 당 몇 개의 투 두를 작성하느냐를 정하기 위해 total args를 입력 받았습니다.
그리고 그 유저별로 동등하게 total의 수만큼 for순회 하면서 ToDo 객체를 작성합니다.ToDo.objects.create(todo_list=list, to_do=fake.unique.bs())여기에서는 to_do가 랜덤이 되어야 하므로 위에서 준비했던 fake의 unique.bs()를 통해 랜덤의 약간 어색한 한국어 문장 생성이 가능합니다.
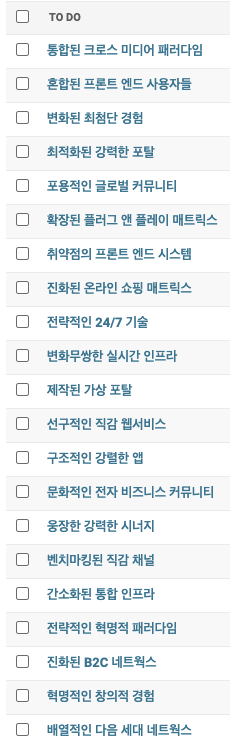
결과는 아래와 같습니다.
문장이라기 보다 광고 문구(?) 같습니다만 테스트 데이터로써는 훌륭한(?) 데이터들입니다.