
Stored Procedure [ 저장 프로시저 ]
Transact-SQL 문장의 집합
저장 프로시저는 쿼리문들의 집합으로, 어떤 동작을 여러 쿼리를 거쳐서 일괄적으로 처리할 때 사용한다.
SP를 사용하는 이유
1. SQL Server의 성능을 향상 시킬 수 있다.
SP를 처음 실행하면 최적화, 컴파일 단계를 거쳐 결과 값이 메모리에 저장되는데
이후 해당 SP를 실행하게 되면 메모리를 참조해 가져오기 때문에 실행속도가 빨라진다.2. 유지보수 및 재활용 측면에서 좋다.
SQL 수정사항이 생겼을 때 코드 내 SQL을 수정하는 것이 아닌 SP 파일만 수정하면 되기 때문에
유지보수 측면에서 유리해진다.3. 보안을 강화할 수 있다.
사용자 별로 테이블에 권한을 주는 것이 아닌 SP에만 접근 권하는 주는 방식으 로 보안을 강화할 수 있다.4. 네트워크의 부하를 줄일 수 있다.
클라이언트에서 서버로 쿼리의 모든 텍스트가 전송될 경우 네트워크에 큰 부하가 생긴다.
하지만 SP를 이용하면 SP의 이름, 매개변수 등 몇 글자만 전송하면 되기 때문에 부하를 크게 줄일 수 있다.일반적인 SQL과 SP의 동작 방식 비교
SP를 사용하면 일반적인 T-SQL보다 시스템 성능이 향상되는 이유를 비교해서 보자.
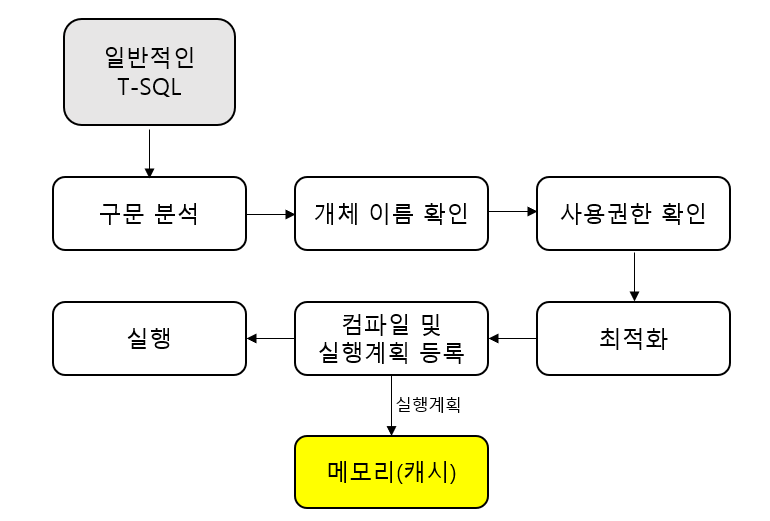
일반적인 T-SQL은 그림과 같은 프로세스로 동작한다.
SELECT name FROM user_tb;예시로 이 쿼리를 실행하게 되면
1. 구문 분석 단계에서 구문 자체에 오류가 없는지 분석을 한다.
만약 오타가 있다면 여기서 오류가 발생해 에러 메시지를 띄울 것이다.2. 다음 개체 확인 단계에서 userTable이라는 테이블이 현재 DB에 있는지 확인한다.
만약 userTable이 있으면 그 안에 name이라는 열이 있는지 확인을 한다. 3. 다음 사용권한 확인 단계에서 userTable에 접근중인 사용자가 사용자 권한이 있는지를 확인한다.
4. 다음 최적화 단계에서 해당 쿼리문이 가장 좋은 성능을 낼 수 있는 경로를 결정한다.
인덱스 사용 여부에 따라 경로가 결정된다.
해당 쿼리의 경우 전체 데이터를 가져오기 때문에 아마도 테이블 스캔이나 클러스터 인덱스 스캔이 된다.5. 다음은 최적화 된 결과를 바탕으로 컴파일 및 실행 계획 등록 단계에서 해당 실행 계획 결과를 메모리(캐시)에 등록한다.
6. 마무리로 컴파일된 결과를 실행한다.
만약 동일한 쿼리를 실행한다면 프로세스는 이렇게 바뀐다.
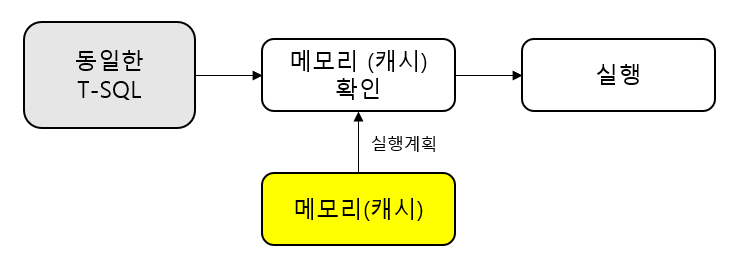
위와 같이 단순하게 동작한다.
이 경우 Library casche에 이전 실행했던 쿼리가 있는 것이기 때문에 *소프트 파싱 이라고 한다.
여기서 주의해야 할 점은 쿼리 전체가 한글자도 틀리지 않고 같아야 한다는 것이다.
다음은 SP의 동작 방식이다.
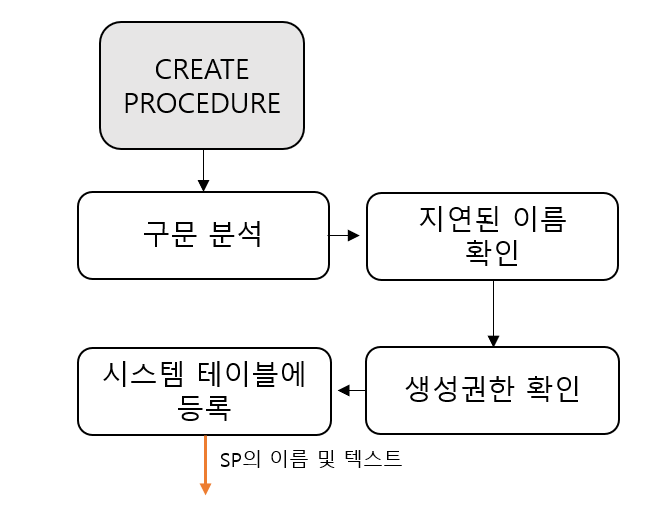
동작 방식은 아래와 같다.
-
해당 SP에 구문 오류가 있는지 파악한다.
-
다음은 지연된 이름 확인(deferred name resolution) 과정을 거친다. 이는 SP의 특징중 하나이다.
SP의 경우 프로시저를 정의하는 시점에 테이블과 같은 해당 개체의 존재 여부와 상관없이 정의가 가능하다.
그 이유는 해당 테이블의 존재 여부를 프로시저의 실행 시점에 확인하기 때문이다.
그렇기에 해당 테이블의 존재 여부와 상관없이 프로시저는 정의할 수 있다.
하지만 테이블의 열 이름이 틀리면 오류가 발생한다.
실무에서는 없는 테이블을 프로시저 정의에 사용하는 등의 실수가 발생할 수 있으니 주의를 요한다.
-
다음은 사용자가 SP를 생성할 권한이 있는지를 확인한다.
-
마지막으로 시스템 테이블 등록을 진행한다. SP의 이름과 코드가 관련 시스템 테이블에 등록되는 과정이다.
- SP를 처음 실행했을 때
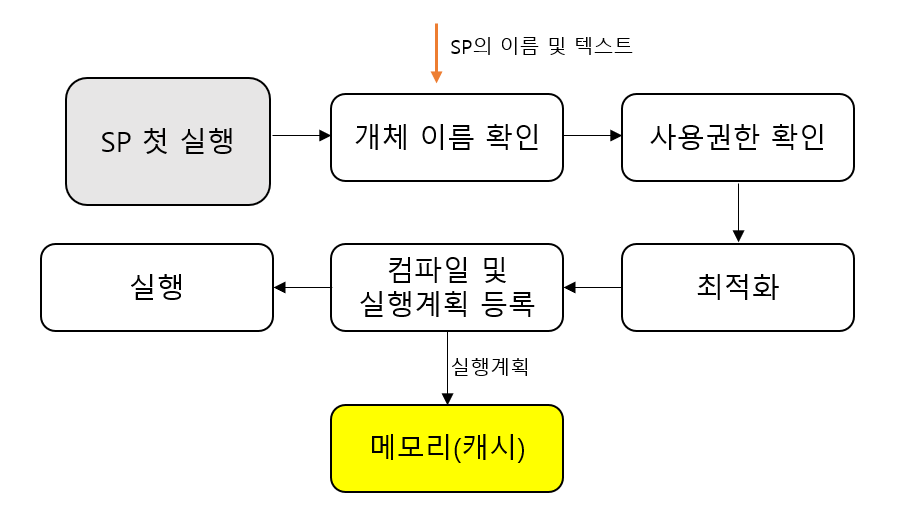
우선 정의단계에서 구문분석이 끝났기 때문에 따로 구문 분석은 하지 않는다.
그 다음 앞에서 정의한 지연된 이름 확인이라는게 있었는데, 실제로 해당 개체가 유효한지를 개체 이름 확인 단계에서 진행하게 된다.
즉, SP의 실행시에만 해당 개체가 존재하면 실행이 된다.
그 후, 사용 권한 확인, 최적화, 컴파일 및 실행 계획 등록 단계를 거쳐 실행된다.
- SP를 두번째 실행했을 때
두 번째 실행 부터는 메모리(캐시)에 있는 것을 그대로 가져와 재사용하게 되어 수행시간이 많이 단축된다.
일반적인 SQL문과 차이점을 코드 예시로 보자
SELECT * FROM USERTABLE WHERE NAME = '김민성';
SELECT * FROM USERTABLE WHERE NAME = '민성김';
SELECT * FROM USERTABLE WHERE NAME = '김성민';이렇듯 쿼리에 글자 하나만 달라도 다 다른 쿼리라고 인식한다.
하지만 이를 SP로 만들면
CREATE PROC SELECT_BY_NAME
@Name VARCHAR2(10)
AS
SELECT * FROM USERTABLE WHERE NAME =@NAME;
EXEC SELECT_BY_NAME '김민성';
EXEC SELECT_BY_NAME '민성김';
EXEC SELECT_BY_NAME '김성민';이렇게 하면 처음 김민성을 검색하는 과정에서만 최적화 및 컴파일을 진행하고, 나머지는 메모리(캐시)에 있는것을 사용하게 된다.
즉, 자주 쓰는 쿼리는 SP를 하나 만들어 쓰는게 성능적인 측면에서 효과적이다.
SP의 문제점
SP를 실행할 때 최적화 단계를 수행하는데, 이 단계에서 인덱스 사용 여부를 결정한다.
인덱스를 사용한다고 수행 결과가 항상 빠르지는 않는데, 만약 가져올 데이터가 다량일 때 인덱스를 사용하면 오히려 성능이 나빠진다.
만약 첫 번째 SP 수행 시 데이터를 조금만 가져오도록 파라미터가 설정되어 있다면, 인덱스를 사용하도록 최적화되어 컴파일 됐을 것이다.
그러나 두 번째 수행에서 많은 파라미터가 들어가 데이터를 가져오게 된다면 일반 쿼리문은 파라미터가 달라져 다시 최적화되어 컴파일 되겠지만
SP는 인덱스를 사용하는 프로시저를 실행시킬 것이다.
이렇게 되면 성능에 문제가 생길 것이다.
이를 방지하기 위해선 SP를 다시 컴파일 해야 한다.
다시 컴파일 하는 방법에는 여러가지가 있지만
실무에서는 보통 인덱스 사용 여부가 불분명하다면 SP를 생성하는 시점에서 아예 실행 시마다 다시 컴파일 되도록 설정해 버리기도 한다.
<ORACLE>
SELECT 'ALTER PROCEDURE' || OBJECT_NAME || 'COMPILE'; DSQL
FROM USER_PROCEDURE
WHERE OBJECT_TYPE = 'PROCEDURE'
ORDER BY OBJECT_NAME
.
.
.
ALTER PROCEDURE [PROCEDURE_NAME] COMPILE- 참조 블로그
https://goddaehee.tistory.com/163 -- SP
https://devkingdom.tistory.com/323 -- SP
https://stackoverflow.com/questions/2310445/what-is-the-difference-between-and-go-in-stored-procedure-in-sql-server -- GO
https://www.oreilly.com/library/view/oracle-database-administration/1565925165/re212.html -- RECOMPILE
