출처
[Meta]The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
KeyPoint
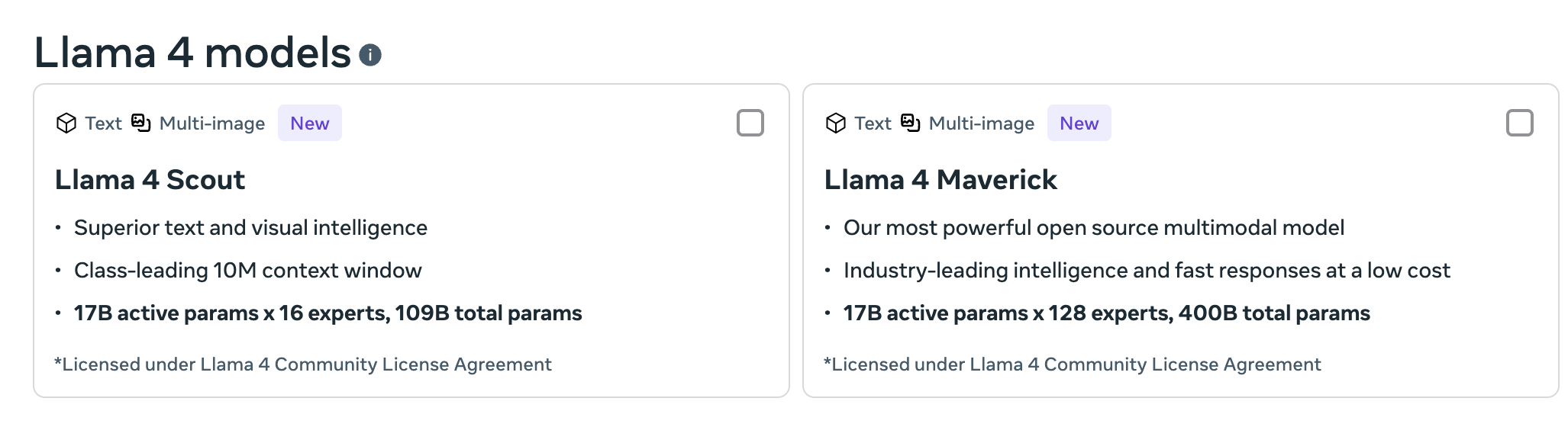
- Llama 4 Scout (16 experts MoE) and Maverick (128 experts MoE) 두가지 open weight 모델 공개(17B 규모)
- Maverick은 추론, 코딩, 비전 작업에서 GPT-4o를 능가, DeepSeek V3의 파라미터 수의 절반 수준
- Scout은 10M 크기의 컨텍스트(대규모 코드베이스 요약과 같은 장문 처리 작업에서 업계 최고 수준)
- 두 모델 모두 현재 학습 중인 2880억 파라미터 규모의 연구용 모델인 Llama 4 Behemoth에서 distilled된 모델이다
- Llama 4 Behemoth : 현재 학습 중인 연구용 초대형 모델로, STEM 분야 문제 해결 능력에서 경쟁 모델들을 뛰어넘는 성능을 목표로 하는 Meta의 새로운 모델
성능
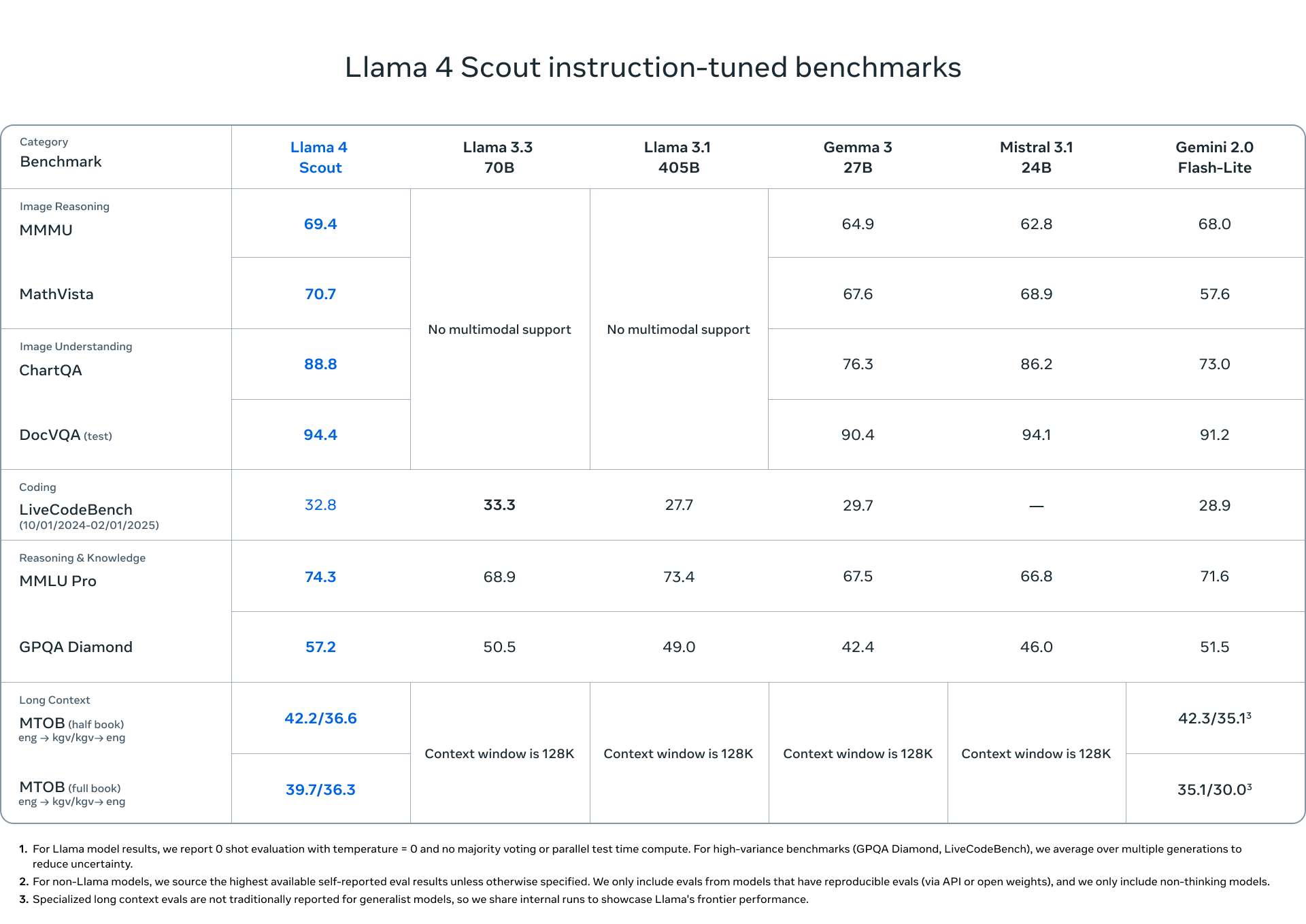
Llama 4 Scout 벤치마크
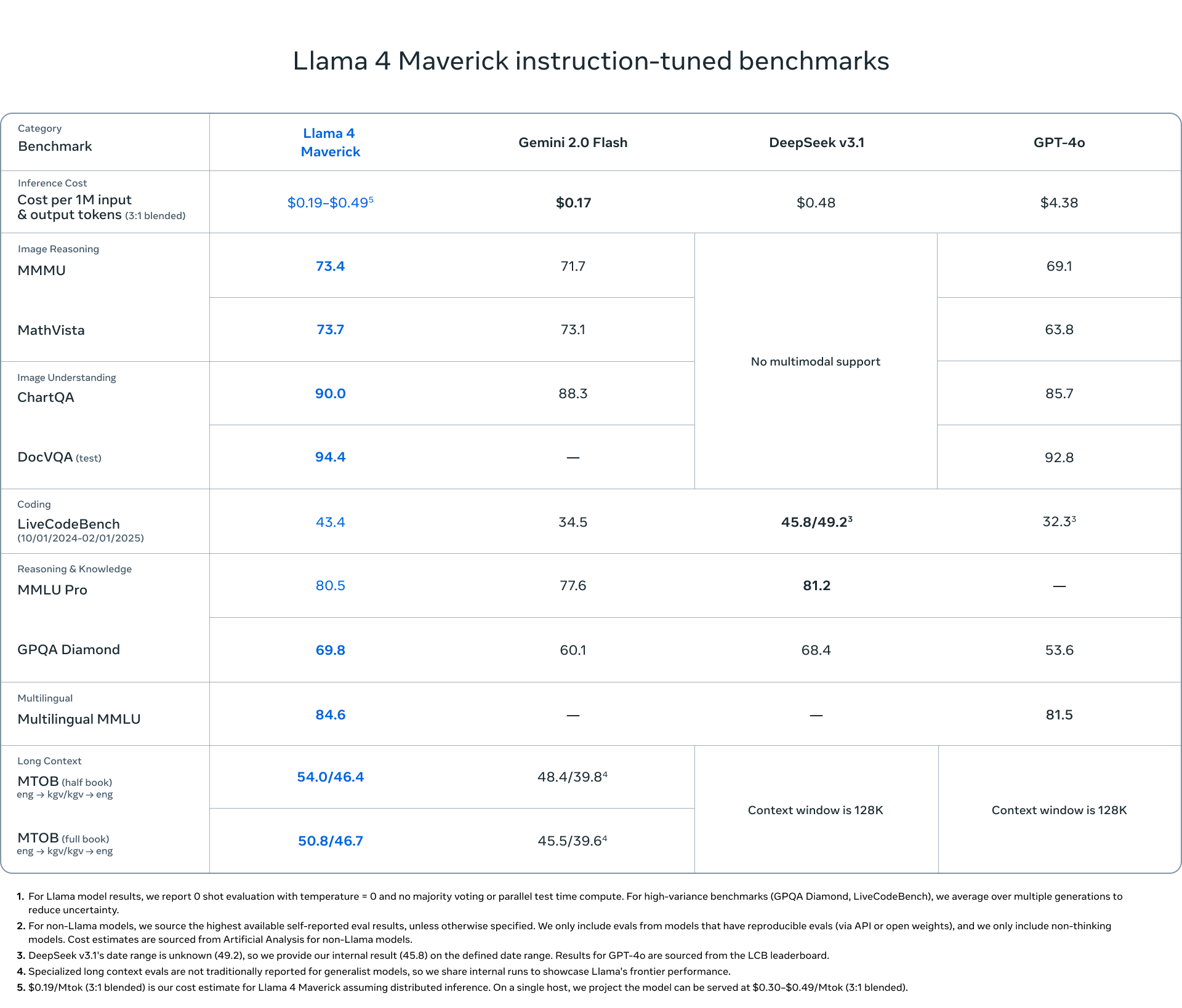
Llama 4 Maverick 벤치마크
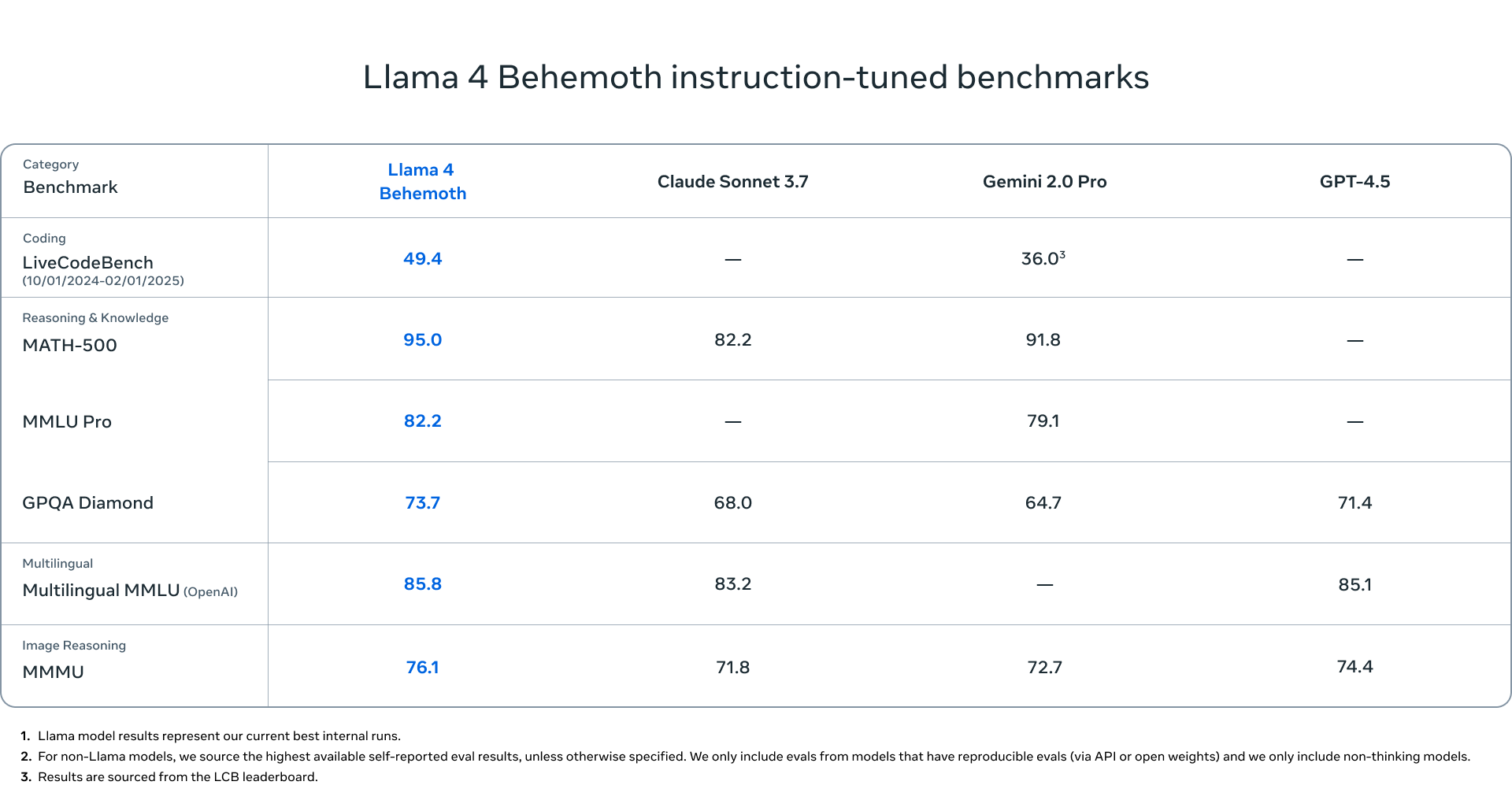
Llama 4 Behemoth 벤치마크
한국어 성능
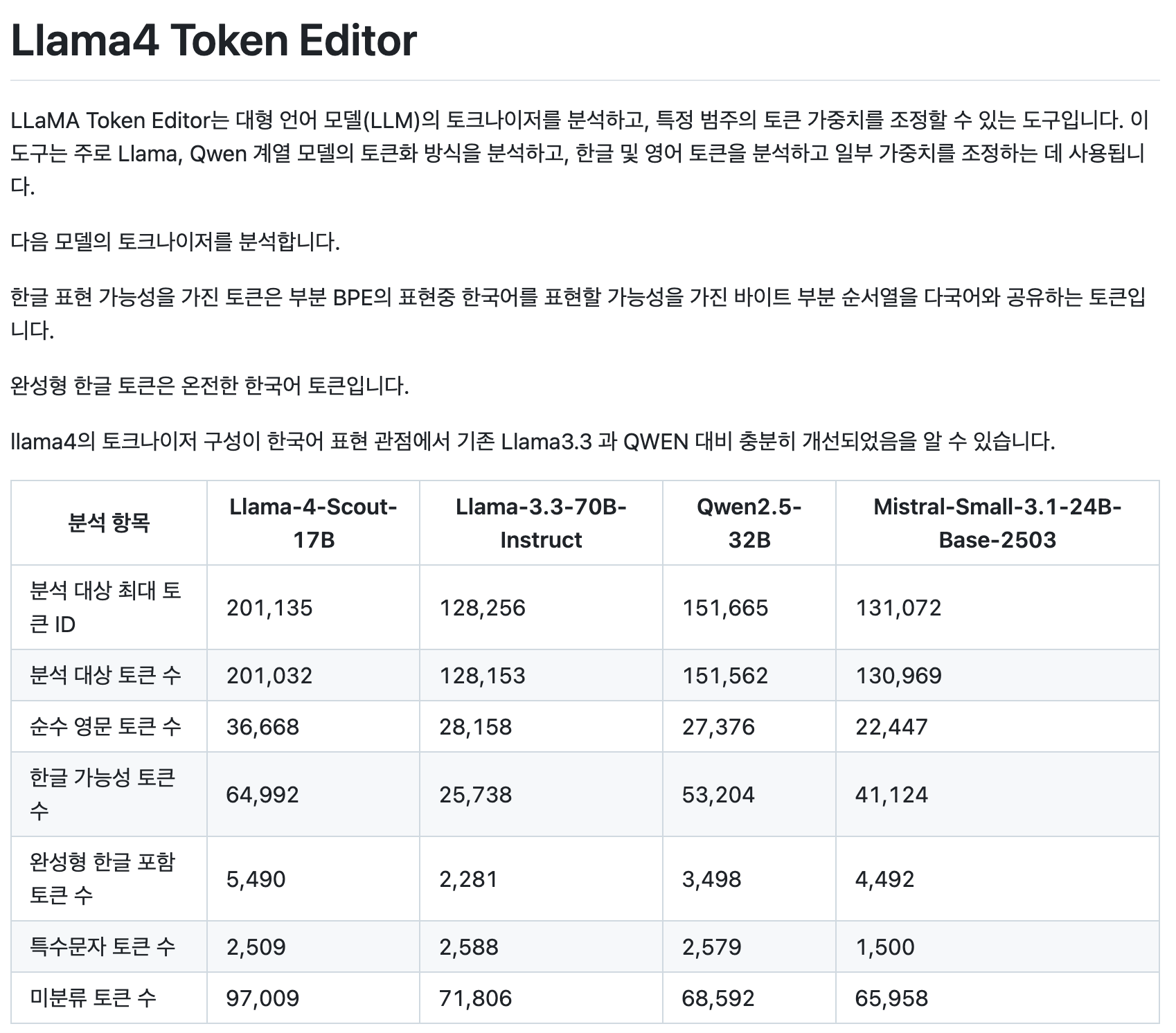
기존 llama 대비 5배 이상 llama3.3 대비 2.5배 이상 가장 한국어 지원비율이 높던 Qwen 대비도 높은 한국어 친화적 구성을 보인다고 한다.
한국어에 대한 성능이 다른 모델 대비 상당히 향상되었을 것으로 기대된다.
deepseek발 MoE 인기에 힘입어 10M 컨텍스트가 강조되는 모델이다.
MoE 109B시작으로 로컬에 올려보긴 힘들 듯 하다.

실패보다 사람을 더 미치게 하는게 후회더라구요 // 공부는 티스토리에, 생각은 벨로그에, 일상은 네이버에 기록합니다