BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
paper review
Background
transeformer
- attention is all you need(2017, google) 논문을 통해 공개
- encoder, decoder 구조를 이용
GPT-1
- GPT-1(2018, openAI)논문을 통해 공개
- transformer의 decoder 구조를 이용하여 만든 자연어처리 모델
- 별도의 labeling이 필요없는 unsupervised learning
Motivation
- GPT-1은 디코더 구조만을 사용함으로써, 효율적으로 대량의 텍스트 데이터에서 언어 패턴을 학습하여 생성적인 작업에 강점을 보임
- 하지만 단방향 인코딩 구조로 인해 문맥에 따른 의미파악에는 한계가 있다고 지적
- 인코더를 이용하여 입력 시퀸스의 양방향 문맥을 인코딩, 자연어 이해 작업에서 뛰어난 성능 향상
Introduction
- BERT는 기존 언어 모델과 달리 양방향 (bidirectional) 학습을 통해 문맥을 더욱 효과적으로 이해하고 활용할 수 있다는 장점을 제시
주요 특징
- 양방향 학습: BERT는 Transformer 아키텍처를 기반으로 양방향 학습을 수행한다. 이를 통해 문장의 앞뒤 정보를 모두 고려하여 단어의 의미를 더욱 정확하게 파악할 수 있다.
- Masked Language Modeling (MLM): BERT는 MLM이라는 새로운 사전 학습 방법을 사용한다. MLM은 문장의 일부 단어를 마스킹하고, 모델이 마스킹된 단어를 정확하게 예측하도록 학습시키는 방법이다. 이를 통해 모델은 단어의 의미뿐 아니라 문맥과의 관계까지 학습하게 된다.
- 다양한 NLP 작업에 대한 높은 성능: BERT는 다양한 NLP 작업에 적용되었으며, 기존 모델들보다 높은 성능을 달성했다. 특히, 질의응답, 감정분석, 자연어 추론, 기계번역 등의 작업에서 뛰어난 성능을 보여주었다.
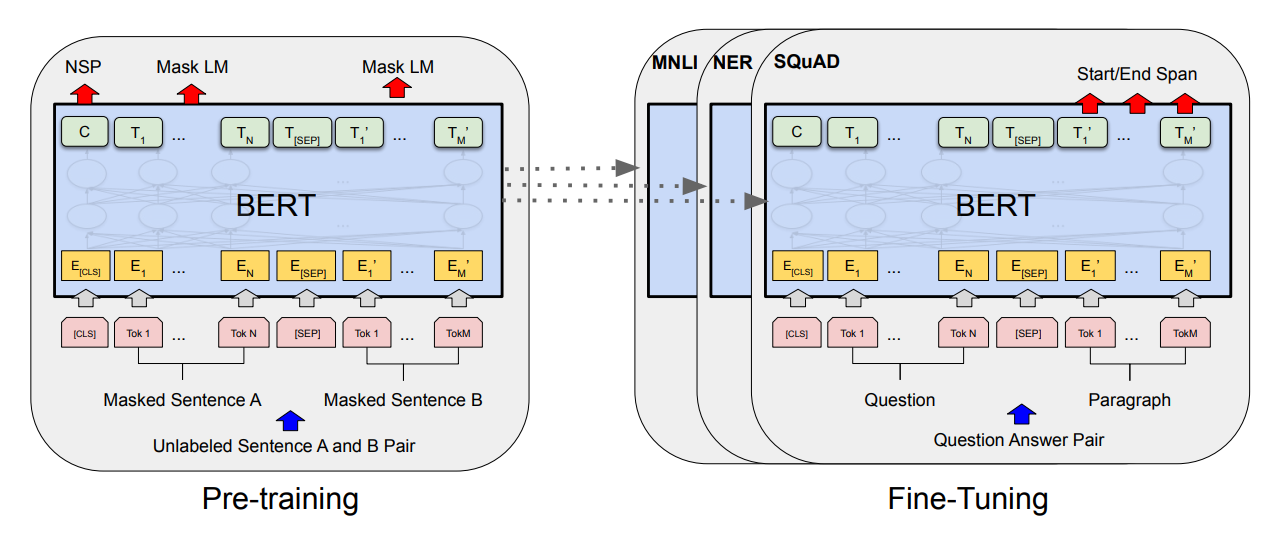
BERT
model
- 양방향 Transformer 인코더를 사용
- GPT와 달리 BERT는 multi-layer bidirectional self-attention을 사용하여 단어의 의미를 학습할 때 좌우 맥락을 모두 고려할 수 있다.
- BERTBASE (L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M) 두가지 모델을 사용.
- BERTBASE은 GPT와의 비교를 위해 파라미터 수를 동일하게 만들어 진행
- [CLS] : 분류 task에 사용되기 위한 토큰
- [SEP] : 두 문장 이상 입력될경우 구분하기 위한 토큰
- WordPiece Embedding을 이용하여 문장을 토큰 단위로 분류(eg. Texting->Text, ##ing)
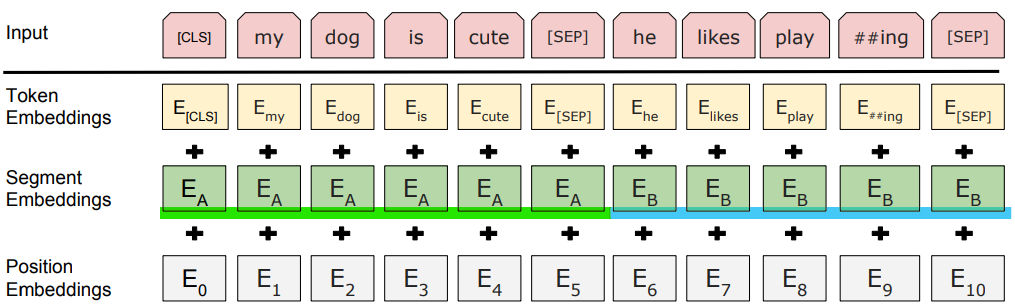
WordPiece Embedding
- 단어를 단순히 원핫 인코딩하는 대신 WordPiece Embeddings를 사용하여 단어를 표현
- WordPiece Embeddings는 단어를 자음과 모음 조합과 같은 작은 단위로 분해하고, 각 단위에 고유한 임베딩 벡터를 할당
- 희소성 문제를 줄이고, 새로운 단어를 표현하는데 유연성을 제공
eg. unsigned이 단어사전에 없더라도, un+sign+##ed로 나누어 이해
Segment Embedding
- 두개이상의 문장이 입력될 경우에 각각의 문장에 서로 다른 숫자를 더해주는 것
Potitional Embeeding
-
각 단어의 위치에 고유한 임베딩 벡터를 할당하여 문장 내 단어의 순서를 표현
-
짝수 인덱스 에 대해:
-
홀수 인덱스 에 대해:
Pre-training BERT
Masked LM (MLM)
입력 문장에서 임의로 단어를 마스킹하고 모델이 원래 마스킹된 단어를 예측하도록 학습한다. 이를 통해 모델은 양방향으로 단어 간의 관계를 학습하는데 도움이 된다.
(많은 실험을 해봤을때, 바꾸어주는 비율이 15% 일때 가장 성능이 좋았다고 한다.
또한 이 [MASK] token은 pre-training에만 사용되고, fine-tuning 과정에서는 사용되지 않는다.)
Next Sentence Prediction (NSP)
많은 NLP의 downstream task(QA, NLI 등)는 두 문장 사이의 관계를 이해하는 것이 중요하다. 이러한 문장 사이의 관계는 language modeling으로는 알아 낼 수 없는데, 이를 학습하기 위해 BERT모델은 binarized next sentence prediction(NSP)을 이용한다.
pre-training example로 문장A와 B를 선택할때, 50퍼센트는 실제 A의 다음 문장인 B를(IsNext), 나머지 50퍼센트는 랜덤 문장 B를(NotNext) 고른다.
eg.
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
BERT는 이 토큰 C를 이용하여 input으로 들어온 두 문장이 원래 corpus에서 이어 붙여져 있던 문장인지(IsNext) 아닌지(NotNext)를 맞춰가며 학습한다.
Fine-tuning BERT
Experiments
11가지 NLP 태스크에 대한 BERT 모델의 파인튜닝 결과를 제시한다.
GLUE
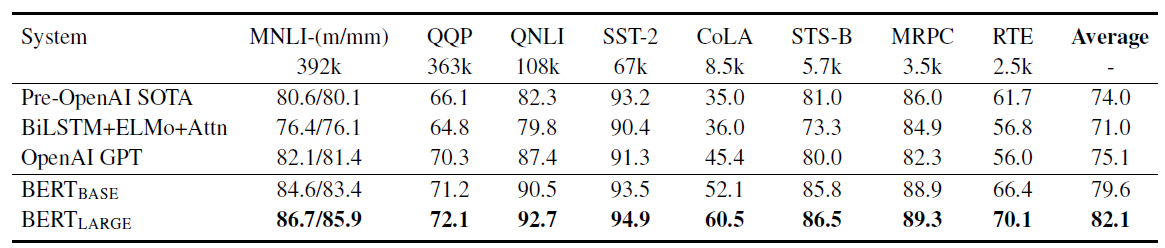
MNLI (Multi-Genre Natural Language Inference)
- 크라우드소싱을 통해 만들어진 대규모의 함의 분류 태스크이다. 문장 한 쌍이 주어졌을 때, 두 번째 문장이 첫 번째 문장에 대해 함의(entailment), 대조(contradiction), 중립(neutral) 중 어떤 관계인지를 예측하는 것이 목표입니다.
QQP (Quora Question Pairs)
- 두 질문이 의미적으로 동등한지를 판별하는 이진 분류 태스크입니다.
QNLI (Question Natural Language Inference)
- Stanford Question Answering Dataset의 한 버전으로 변경된 이진 분류 태스크입니다. 올바른 답을 포함한 (질문, 문장) 쌍이 긍정적인 예시이며, 답을 포함하지 않는 동일 문단의 (질문, 문장) 쌍이 부정적인 예시입니다.
SST-2 (The Stanford Sentiment Treebank)
- 영화 리뷰에서 추출된 문장들로 구성되며, 인간의 감정에 대한 어노테이션이 포함된 단일 문장 이진 분류 태스크입니다.
CoLA (The Corpus of Linguistic Acceptability)
- 영어 문장이 언어적으로 수용 가능한지 아닌지를 예측하는 단일 문장 이진 분류 태스크입니다.
STS-B (The Semantic Textual Similarity Benchmark)
- 뉴스 헤드라인 등에서 가져온 문장 쌍의 모음으로, 문장 쌍은 1~5점으로 주석처리 되어 있어 두 문장의 의미론적 유사도를 나타냅니다.
MRPC (Microsoft Research Paraphrase Corpus)
- 온라인 뉴스 자료에서 자동으로 추출된 문장 쌍으로, 의미론적으로 동등한지에 대한 어노테이션과 함께 구성됩니다.
RTE (Recognizing Textual Entailment)
- MNLI와 유사한 이진 함의 태스크로, 학습 데이터가 훨씬 적습니다.
WNLI (Winograd NLI)
- 작은 자연어 추론 데이터셋입니다. GLUE 웹 페이지는 이 데이터셋의 구성 문제를 지적했으며, 모든 학습된 시스템이 기준 정확도 65.1보다 낮은 성능을 내므로 BERT에서는 이 데이터셋을 제외합니다.
BERT는 GLUE 태스크에 대해 32의 배치 크기와 3 epoch로 fine tunning되었으며, Dev 세트에서 최적의 파인튜닝 학습률을 선택했다. 평가 결과, BERT BASE와 BERT LARGE 모두 기존 상태의 예술보다 각각 평균 정확도를 4.5%, 7.5% 향상시키며 모든 태스크에서 뛰어난 성능을 보였다. 특히, 학습 데이터가 매우 적은 태스크에서 BERT LARGE가 BERT BASE를 크게 능가했다.
BERT는 32 batch size, 3 epochs로 파인튜닝 되었고, Dev set에서 최적의 파인튜닝 학습율을 선택했다(5e-5, 4e-5, 3e-5, 2e-5 중 선택). 파인튜닝이 가끔 적은 데이터셋에서 불안정하여, BERT LARGE의 경우 임의의 재시작을 몇 번 실행한다.
BERT BASE와 BERT LARGE 모두 각각 4.5%, 7.5%로 기존 SOTA의 평균 정확도를 향상시키며 모든 태스크 시스템을 능가한다. BERT LARGE는 모든 태스크, 특히 학습 데이터가 매우 적은 태스크에서 BERT BASE를 크게 능가한다.
SQuAD v1.1
TBA
SQuAD v2.0
TBA
SWAG
TBA
Conclusion
언어 모델을 사용한 사전 훈련(pre-training)이 언어 이해 태스크에서 큰 성공을 거두고 있으며, 특히 BERT와 같은 양방향 아키텍처가 자연어 이해 태스크를 포함한 다양한 NLP 문제에 효과적으로 적용될 수 있음을 제시
정리
- GPT, BERT는 각각 Transformer 모델을 기반으로 Downstream Task에 최적화한 예시이다.
- Transformer 아키텍처의 유연성과 확장성을 활용하여, 각각의 모델은 특정 자연어 처리(NLP) 태스크에 대해 최적화된 방식으로 설계되었다.
GPT
- 목적: GPT(Generative Pre-training Transformer) 시리즈는 주로 생성적 태스크에 초점을 맞춘다. 이는 글을 쓰거나, 대화를 생성하거나, 문장을 완성하는 것과 같은 작업을 말한다.
- 구조: GPT는 Transformer의 디코더 구조만을 사용한다. 한 번에 하나의 단어를 예측하며, 이전에 생성된 단어들을 기반으로 다음 단어를 생성한다.
- pre-training과 fine tunning: 대규모 텍스트 데이터셋으로 pre-training, Downstream Task에 fine tunning하여 성능 최적화
BERT
- 목적: BERT(Bidirectional Encoder Representations from Transformers)는 주로 자연어 이해 태스크에 적용. 이는 질문 응답(QA), 이름이 지정된 엔티티 인식(NER), 감성 분석과 같은 작업을 포함한다.
- 구조: BERT는 Transformer의 인코더 구조만을 사용한다. 입력 텍스트의 양방향 문맥을 고려하여 단어의 표현을 생성한다.
- 사전 훈련과 미세 조정: BERT는 Masked Language Modeling과 Next Sentence Prediction과 같은 pre-training Task를 통해 사전 훈련되며, Downstream Task에 fine tunning하여 성능 최적화
GPT와 BERT는 Transformer 아키텍처를 적용함으로써, NLP 분야에서 각기 중요한 위치에 있다.
각각의 모델이 특정 태스크에 최적화되어 있음에도 불구하고, 근본에는 변하지 않는 Transformer의 기본 원리가 있다.
