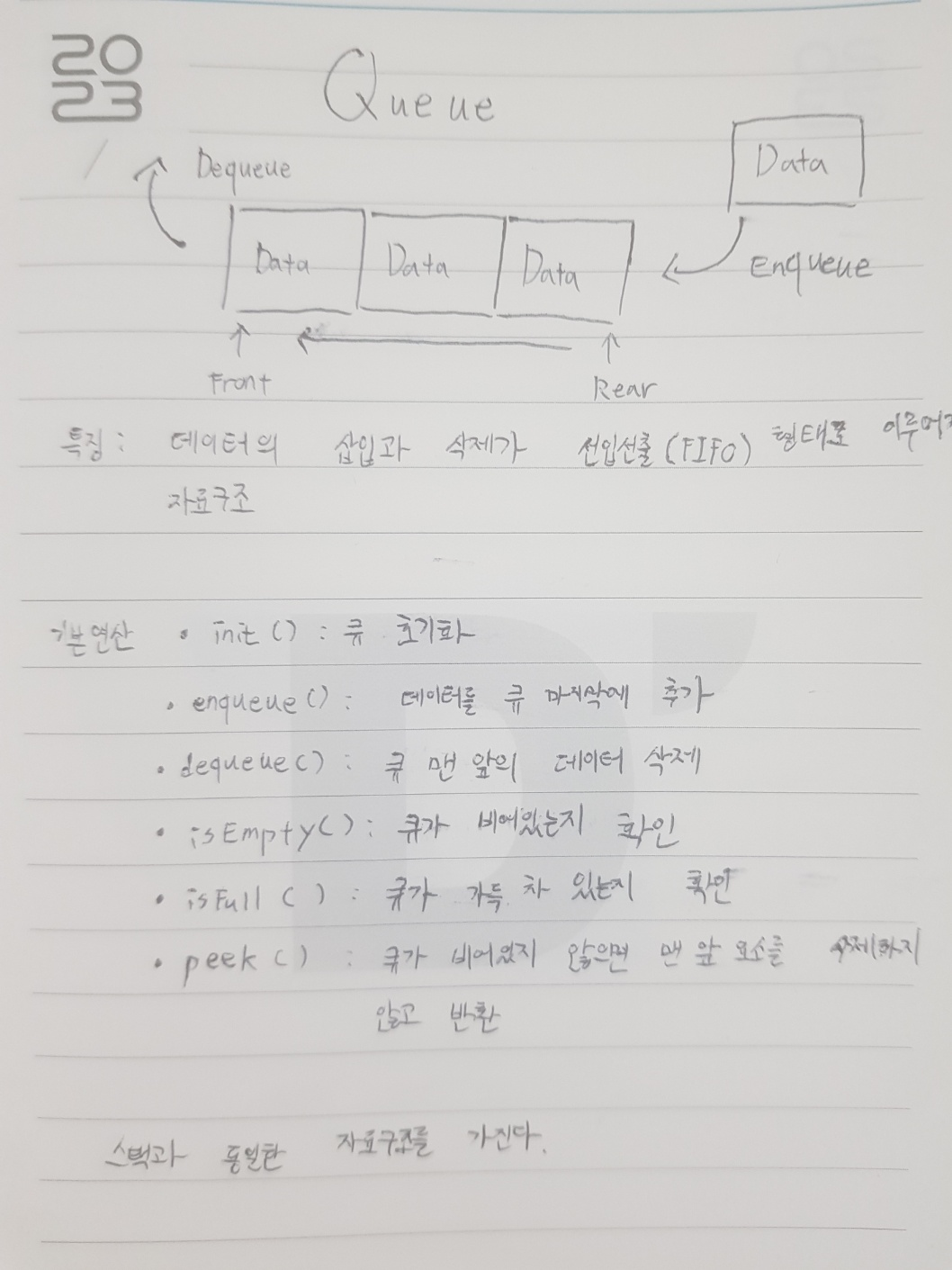
큐(Queue)란?
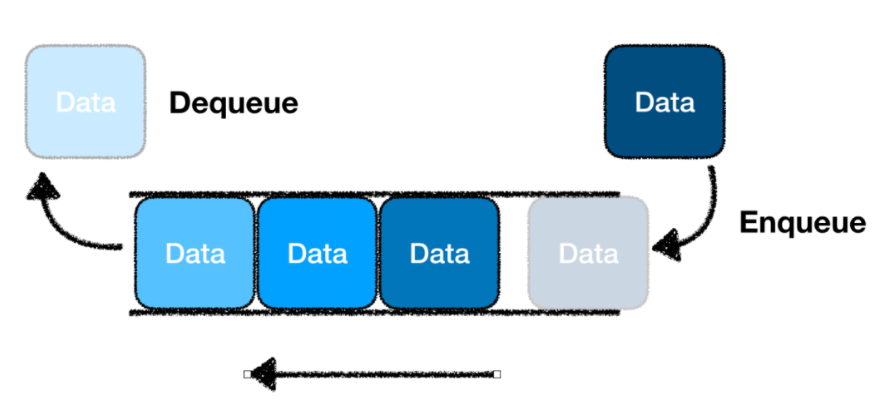
- 일상생활에서 은행에 들어온 순서대로 번호표를 뽑고 번호표 순서대로 먼저 온 고객부터 처리해 주는 것과 같이 선입선출(FIFO) 형태의 구조를 큐(Queue)라고 부른다.
* FIFO(FIrst In First Out) - 큐는 스택과 마찬가지로 삽입과 삭제의 위치, 방법이 제한되어 있는 자료구조이지만 한쪽 끝에서는 삽입 작업이 이루어지고 반대쪽 끝에서는 삭제 작업이 이루어지는 자료구조이다.
큐(Queue) 특징
- 두 개의 입출력 방향을 가지고 있다. 입력, 출력 방향이 다르다.
- 큐는 한쪽 끝은 front로 정하여 삭제 연산만 수행
- 다른 한쪽 끝은 rear로 정하여 삽입 연산만 수행
- FIFO(First In First Out) 혹은 LILO(Last In Last Out)이라고 부른다.
- 데이터를 하나씩 넣고 뺄 수 있다.
- 그래프의 넓이 우선 탐색(BFS)에서 사용.
- 컴퓨터 버퍼에서 주로 사용, 마구 입력이 되었으나 처리를 하지 못할 때, 버퍼(큐)를 만들어 대기 시킴.
큐(Queue) 주요 메서드
- init() : 큐를 초기화
- enqueue() : 주어진 요소를 큐의 맨 뒤에 추가
- dequeue() : 큐가 비어있지 않으면 맨 앞 요소를 삭제하고 반환
- is_empty() : 큐가 비어있으면 true를 아니면 false를 반환
- peek() : 큐가 비어있지 않으면 맨 앞 요소를 삭제하지 않고 반환
- is_full() : 큐가 가득 차 있으면 true를 아니면 false를 반환
- size() : 큐의 모든 요소들의 개수를 반환
큐(Queue) 구현방법
- 배열 사용
- 장점 : 구현하기 쉬움.
- 단점 : 크기가 동적이 아님, 런타임 시 필요에 따라 늘어나거나 줄어들지 않음.
- 연결 리스트 사용
- 장점 : 크기가 동적임, 런타임 시 필요에 따라 크기가 확장 및 축소될 수 있음.
- 단점 : 포인터를 위한 추가 메모리 공간이 필요함.
큐(Queue) 종류
1. 선형 큐(Linear Queue)
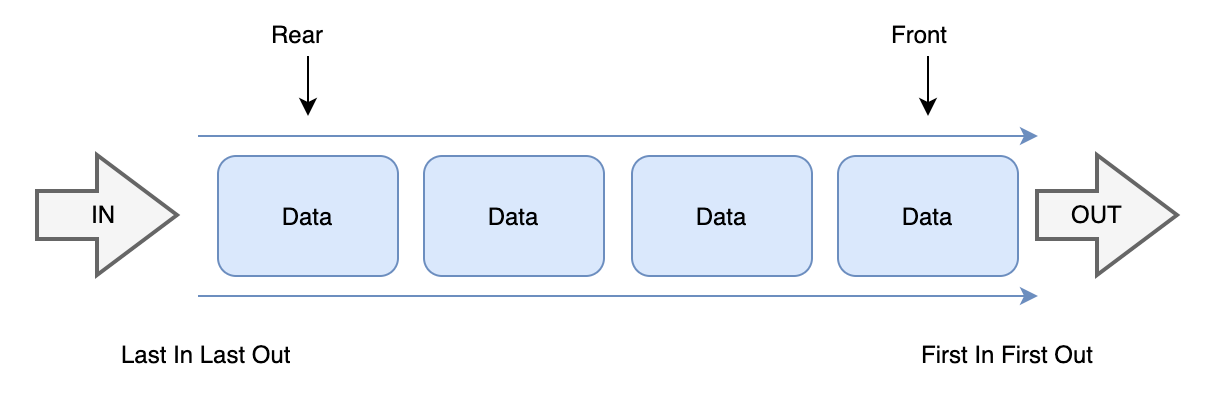
- 기본적인 큐의 형태
- 막대 모양으로 된 큐로, 크기가 제한되어 있고 빈 공간을 사용하려면 모든 자료를 꺼내거나 자료를 한칸 씩 옮겨야 한다는 단점이 있다.
선형 큐의 문제점
일반적인 선형 큐는 rear이 마지막 index를 가르키면서 데이터의 삽입이 이루어진다. 문제는 rear이 배열의 마지막 인덱스를 가르키게 되면 앞에 남아있는 (삽입 중간에 Dequeue 되어 비어있는 공간) 공간을 활용 할 수 없게 된다. 이 방식을 해결하기 위해서는 Dequeue를 할때 front를 고정 시킨 채 뒤에 남아있는 데이터를 앞으로 한 칸씩 당기는 수밖에 없다. 그래서 이를 보안하기 위해 나온 것이 원형 큐이다.
2. 원형 큐(Circular Queue)
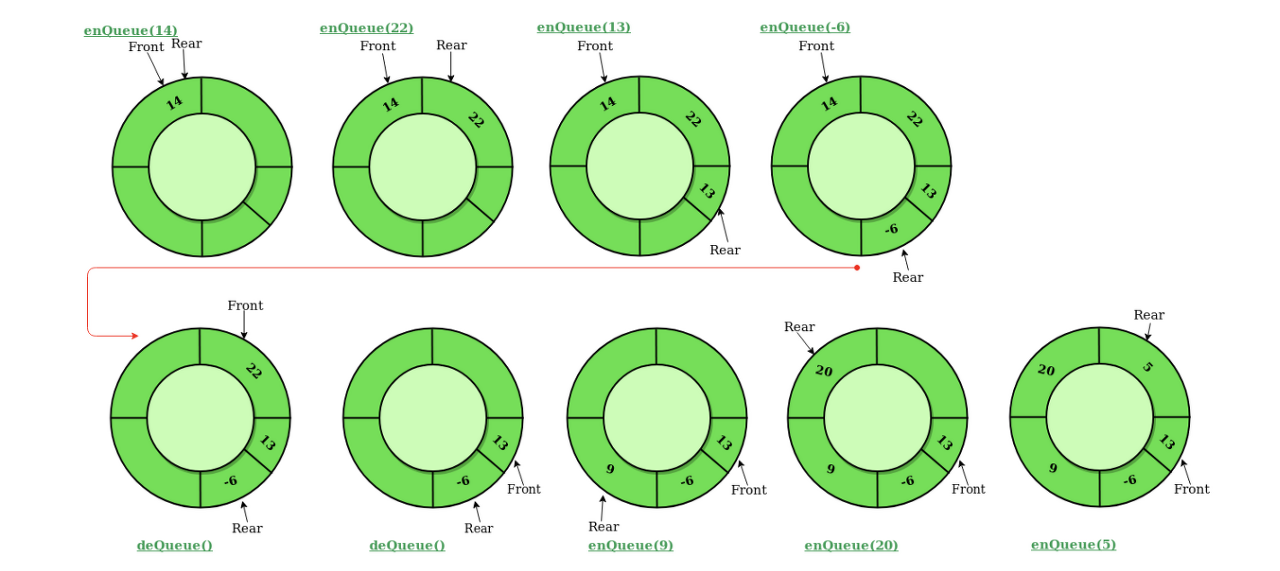
- 선형 큐의 문제점을 보완하고자 나왔다.
- 배열의 마지막 인덱스에서 다음 인덱스로 넘어갈 때
(index+1) % 배열의 사이즈를 이용하여 Out Of Bounds Exception이 일어나지 않고 인덱스 0으로 순환되는 구조를 가진다.
3. 우선순위 큐(Priority Queue)
- 우선순위 큐(Priority Queue)는 들어가는 순서에 관계없이 큐에서 dequque 될 때, 우선순위에 맞게 나간다.
- Ex) A, B, C가 있을 때, A가 우선순위가 1, B가 3, C가 2면 C, B, A순으로 넣어도 A, C, B순으로 나온다.
- 우선순위 큐의 logarithmic한 성능을 보장하기 위해 항상 이진 트리의 균형을 맞추어야 함.
- 완전 이진 트리(Complete Binary Tree)의 구조를 이용하여 트리의 균형을 맞춤
구현방법
배열 기반 구현 - 데이터를 삽입 및 삭제하는 과정에서 데이터를 한 칸씩 뒤로 밀거나 한 칸씩 당기는 연산을 수반해야 함 + 원소의 삽입 위치를 찾기 위해 배열의 저장된 모든 데이터와 우선순위의 비교를 진행해야 할 수도 있음
- 연결리스트 기반 구현 - 원소의 삽입 위치를 찾기 위해 첫 번째 노드에서부터 마지막 노드까지에 저장된 데이터들과 우선순위의 비교를 진행해야 할 수도 있음.
- 힙(Heap)을 이용하여 구현 - 최소 힙 및 최대 힙의 삽입 삭제와 같음
배열과 연결리스트 기반으로 구현하면 성능이 저하되므로, 일반적으로 힙을 이용하여 많이 구현한다.
큐(Queue) 시간복잡도
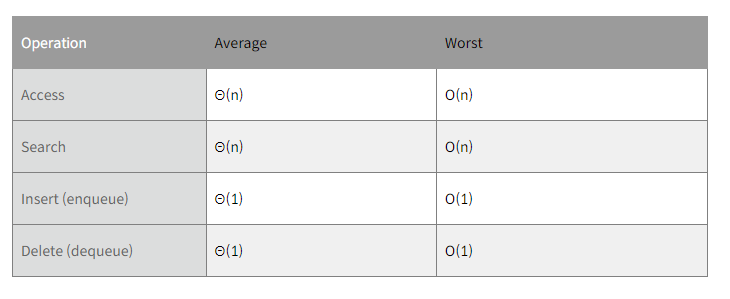
큐 역시 스택과 동일한 시간 복잡도를 가진다. 즉, 자료가 삽입될 때는 자료의 맨 뒤에 자료가 삽입되는 연산만 수행되므로 O(1)로 표기할 수 있다. 자료의 삭제 또한 맨 앞의 자료가 삭제되는 동일한 연산이 수행되므로 O(1)로 표기된다.
자료를 검색할 때는 맨 앞의 요소부터 맨 마지막 요소까지 차례대로 검색해야 하기 때문에 시간 복잡도는 O(n)이다.
복습해보기