해시맵(HashMap)이란?
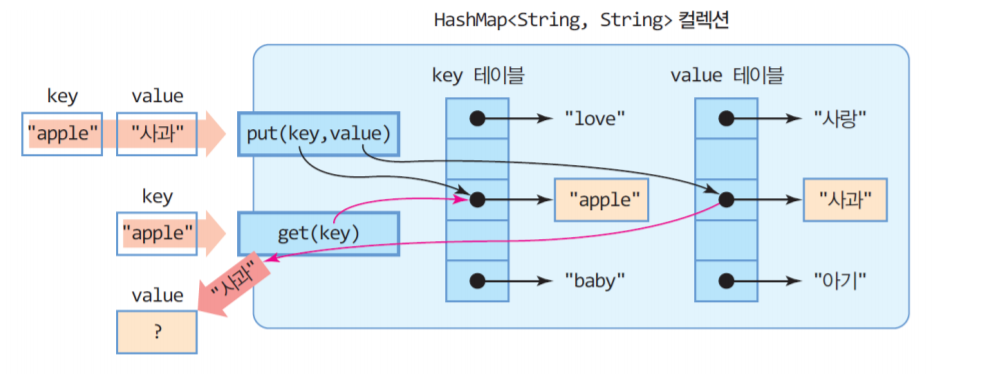
해시맵(HashMap)은 맵(Map) 인터페이스를 구현한 대표적인 맵(Map) 컬렉션이다. 맵(Map) 인터페이스를 상속하고 있기에 맵(Map)의 성질을 그대로 가지고 있다. 맵(Map)은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조이다. 여기서 키와 값은 모두 객체이다. 값은 중복 저장될 수 있지만 키는 중복 저장될 수 없다. 만약 기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다. 해시맵(HashMap)은 이름 그대로 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데 있어서 뛰어난 성능을 보인다.
해시맵(HashMap) 특징
- Key와 Value 쌍으로 데이터를 저장한다.
- Key는 중복되지 않는다. 중복된 Key 값을 put() 메서드로 추가할 경우, 이전의 값을 덮어쓴다.
- Value는 중복 가능
- HashMap은 순서를 보장하지 않는다. 즉, 저장된 순서와 꺼내온 순서가 동일하지 않을 수 있다.
- 다수의 스레드에서 접근할 경우 동기화 처리가 필요하다.
- null 값을 Key로, Value로 모두 사용할 수 있다.
해시맵(HashMap) 장단점
장점
- 검색, 추가, 삭제 연산을 평균적으로 O(1)의 상수 시간(computational time)에 처리할 수 있어 빠른 속도를 보여줍니다.
- 키-값(key-value) 쌍으로 데이터를 저장하므로, 탐색 속도가 빠릅니다.
- 해시맵 내부 구조는 배열과 연결 리스트로 구성되어 있어 메모리 공간을 효율적으로 사용합니다.
단점
- 해시맵 내부 구조는 연결 리스트에 대한 포인터를 유지하기 때문에, 메모리 사용량이 크게 증가할 수 있습니다.
- 해시 함수 충돌이 발생할 경우 성능이 저하됩니다. 이를 해결하기 위해 체이닝(Chaining)이나 오픈 어드레싱(Open Addressing) 등의 기법을 사용합니다.
* 해시 충동 => 해시 함수(hash function)를 사용하여 입력값을 해시값으로 변환할 때, 서로 다른 입력값이 같은 해시값을 반환하는 상황
해시맵(HashMap) 주요 메서드
- put(K key, V value) : Key-Value 쌍을 HashMap에 추가합니다. 만약 Key 값이 이미 존재할 경우, 해당 Key의 Value를 새로운 값으로 덮어씁니다.
- get(Object key) : Key에 해당하는 Value를 반환합니다. 만약 Key 값이 존재하지 않을 경우, null을 반환합니다.
- remove(Object key) : Key에 해당하는 Key-Value 쌍을 HashMap에서 삭제합니다. 삭제된 Value를 반환합니다.
- size() : HashMap에 저장된 Key-Value 쌍의 개수를 반환합니다.
- containsKey(Object key) : HashMap에 Key 값이 존재하는지 확인합니다. 존재하면 true를 반환합니다.
- containsValue(Object value) : HashMap에 Value 값이 존재하는지 확인합니다. 존재하면 true를 반환합니다.
- keySet() : HashMap에 저장된 Key 값을 Set으로 반환합니다.
- values() : HashMap에 저장된 Value 값을 Collection으로 반환합니다.
- entrySet() : HashMap에 저장된 Key-Value 쌍을 Entry 객체로 묶어서 Set으로 반환합니다.
해시맵(HashMap) 사용 경우
- 데이터 검색이 빈번한 경우
- 해시맵은 탐색 속도가 빠르므로, 데이터 검색이 빈번한 경우에 유용합니다. 예를 들어, 사용자가 검색어를 입력하면 해당 검색어를 포함하는 데이터를 빠르게 찾아서 보여줄 수 있습니다.
- 데이터의 중복을 피해야 하는 경우
- 해시맵은 각 키(Key) 값이 유일해야 한다는 제약 조건이 있어, 중복된 데이터를 저장하지 않습니다. 이러한 특징 때문에, 데이터의 중복을 피해야 하는 경우에 해시맵을 사용하는 것이 좋습니다.
- 다양한 데이터 타입을 다루어야 하는 경우
- 해시맵은 제네릭(Generic)을 이용하여 다양한 데이터 타입을 다룰 수 있습니다. 따라서, 다양한 데이터 타입을 다루어야 하는 경우에도 해시맵을 사용할 수 있습니다.
- 대용량 데이터 처리가 필요한 경우
- 해시맵은 대용량 데이터를 빠르게 처리할 수 있습니다. 이러한 특징 때문에, 대용량 데이터 처리가 필요한 경우에 해시맵을 사용하는 것이 좋습니다.
데이터 검색이 빈번하거나 데이터의 중복을 피해야 하며, 다양한 데이터 타입을 다루어야 하거나 대용량 데이터 처리가 필요한 경우에는 해시맵을 사용하는 것이 유용합니다.
해시맵(HashMap) 시간복잡도
- 탐색/검색 : O(1)
- 추가/삭제 : O(1)
해시맵은 데이터의 크기에 상관없이 빠른 속도를 보장하기 때문에, 대용량 데이터 처리가 필요한 경우나 데이터 검색이 빈번한 경우 등에 많이 사용됩니다.

안녕하세요! 글 잘 읽었습니다!
혹시 제가 공부한 것을 정리하는 깃헙 readme에 해당 블로그 출처를 표기하고 내용을 좀 정리해도 괜찮을까요??