1. 개요
얼마 전, 구독플랫폼에서 Virtual Thread가 자바19에 추가된다는 내용의 글을 보았다.
Virtual Thread는 Project Loom의 일부로서, 기존 Java Thread의 무거운 패러다임을 경량하려는 노력의 일환이다.
이번 포스팅에서는 추후 Virtual Thread와 Project Loom에 대해 다루기전에, 자바의 기존 Thread 사용방식은 어떠했는지 알아보고 기록하려고 한다. Thread가 무엇인지에서는 자세히 다루지않고, 현재 Platform Thread의 이해도를 높일 수 있는 내용을 담아 볼 계획이다.
2. 무거운 Thread?
앞선 1. 개요에서 기존 Java Platform Thread가 무거운 패러다임을 가진다는 표현을 사용했다. 또한 Virtual Thread와 Project Loom의 궁극적 목적이 이를 경량화하는 것이라고 했다.
이는 어떤 의미일까?? 이를 이해하기위해 Platform Thread에 대한 내용을 정리해보자.
2.1 Green, Native
Platform Thread를 나누라고 한다면, Green Thread와 Native Thread로 나눌 수 있다.
이 둘의 차이를 이해하는 것은 매우 간단하다. Thread라는 개념이 자원을 효율적으로 쓰기위한 개념이라는 것을 이해하고, 직접적으로 CPU를 사용하는(CPU와 1:1) Thread를 Native Thread라는 것을 인지하기만 하면 된다.
각각의 Thread는 그런 이유로 User-level Thread, Kernel-level Thread로도 불리게 된다.
그렇다면 Green Thread는 어떤 역할을 하는지 의문이 생길 것이다. Green Thread는 VM과 라이브러리에서 관리하며, 개발자가 직접 통제할 수 있는 논리적 Thread이다. 때문에 그림 1과 같이 Native Thread와 N:1의 관계를 가진다.
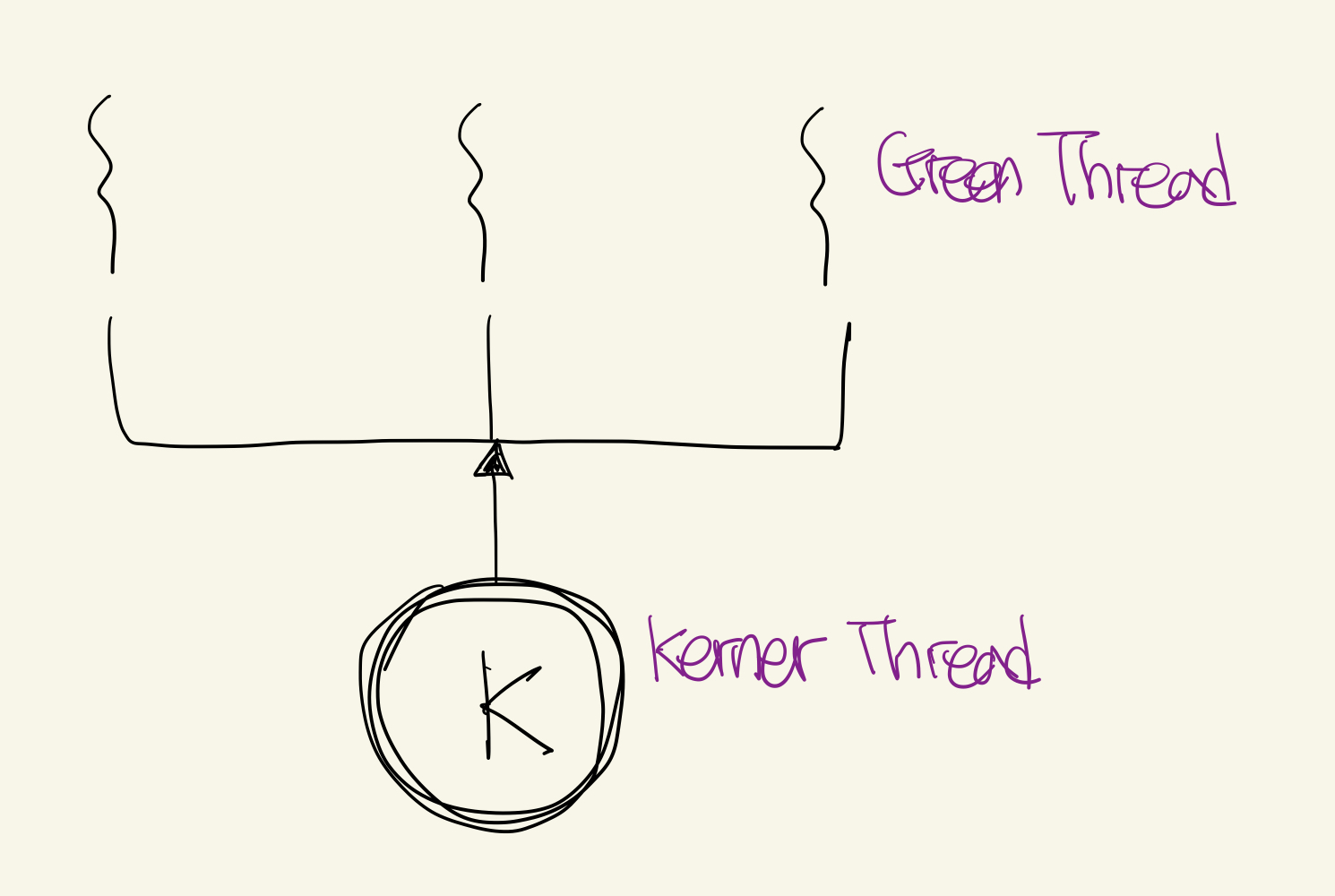 그림 1. Native Thread(Kerner)과 Green Thread의 관계
그림 1. Native Thread(Kerner)과 Green Thread의 관계
2.1.1 Green Thread의 필요성
결국 Thread는 자원을 사용하는 방식이기때문에, Native Thread가 하나라면 동일 시간대에 하나의 CPU만 사용할 수 있다. 그렇다면 Green Thread는 왜 필요할까??
이유는 Native Thread가 비교적 무겁기 때문이다. Multi Thread환경에서는 여러 Thread가 특정 작업을 나눠서 수행하므로, 공유 자원의 동기화 문제가 가장 중요한 이슈이다.
Green Thread는 이 부분에서 이점을 가진다. Kerner단에서의 동기화가 필요하지 않기때문에(이로인해 비교적 가볍다), 동기화로 인한 병목이 없이 작업을 수행 할 수 있기 때문이다.(물론 인터럽트가 원할하게 이루어져야 높은 효율을 가져갈 수 있다)
2.1.2 Green Thread deprecated되다
"As a result, this multithreading model provides limited concurrency and does not exploit multiprocessors" -Green Thread에 대한 JDK 1.1 for Solaris Developer's Guide > Chapter 2 Multithreading에서의 설명-
다만 2.1.1 Green Thread의 필요성의 내용은 Single Core, Multi Thread에 국한되는 것으로 하드웨어가 발전하고 Multi Core가 고려됨에 따라 Green Thread의 설 자리가 없어지게 되었다.
결국 Kerner-level Thread와 User-level Thread가 1:1 혹은 N:M이 되는 구조가 JAVA에 자리매김하게 되었다.
위의 JDK 1.1문서를 보면, 세가지의 모델이 소개되는데 앞서 말한 1:1, N:M에 해당하는 모델이 바로 one-to-one, many-to-many model이다.
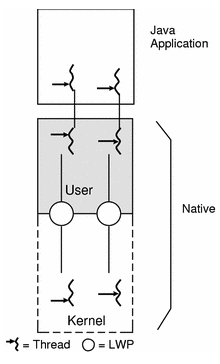 그림 2. one-to-one model의 구조
그림 2. one-to-one model의 구조
one-to-one model은 Kerner-level Thread와 User-level Thread가 1:1로 매핑되는 구조로서, 어플리케이션에 의해 생성된 모든 Thread는 커널에서 인지할 수 있고 모든 Thread가 동시에 커널에 접근할 수 있다.
해당 모델은 Thread가 추가됨에 따라 프로세스에 더 많은 가중치를 추가하기 때문에 User-level Thread임에도 불구하고 쉽게 다루기 어렵다.
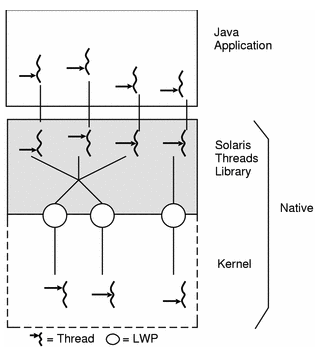 그림 3. many-to-many model의 구조
그림 3. many-to-many model의 구조
many-to-many model은 위의 one-to-one model의 한계를 극복하기 위한 모델로, two-level model이라고도 불린다.
이런 이름으로 불리우는 이유는 어플리케이션 라이브러리에서 User-level Thread의 스케쥴링을 제공하는 User-level과 활성화된 Thread를 Kerner단에서 관리하는 Kerner-level로 나뉘어 책임을 가지기 때문이다.
위의 두 가지 계층이 생기면서, 위에 얹어지는 어플리케이션에서는 Thread의 생성과 관리에 대한 책임이 크게 줄어들게 된다. 또한 User-level계층에서의 라이브러리의 도움으로, Thread 추가에 대한 가중치가 낮아져 비교적 가벼운 Thread를 사용할 수 있다.
이런 장점으로 인해 현재의 JAVA JDK는 many-to-many model을 채택하고 있다.
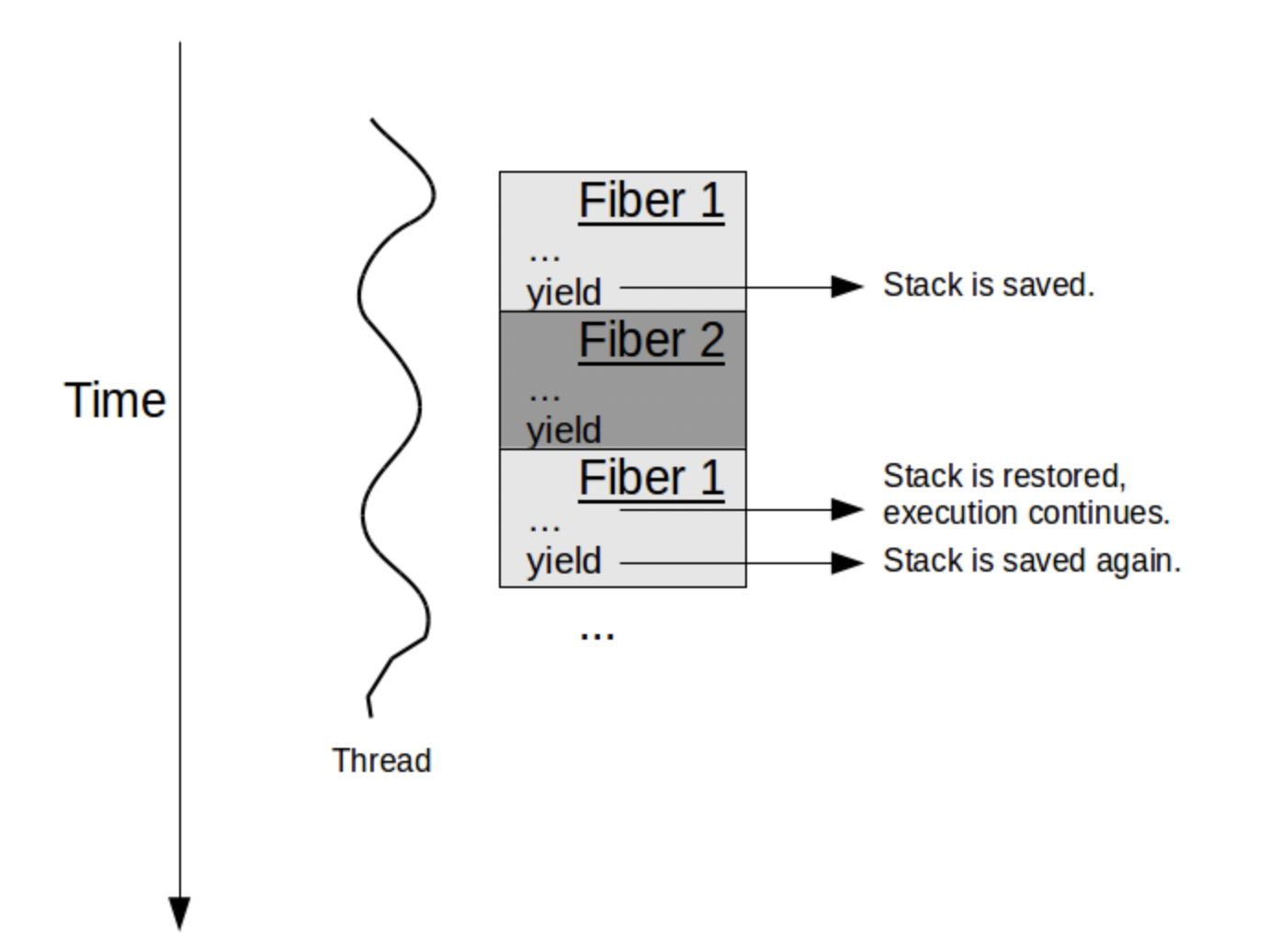
3. fiber
위와 같은 다소 무거운 쓰레드들을 중량 쓰레드라고 한다면, 파이버(fiber)는 경량 쓰레드이다. 경량 쓰레드가 대두된 이유는 중량 쓰레드의 단점을 알아본다면 파악하기 쉬울 것 이다.
3.1 중량 쓰레드의 단점
- 상당한 리소스를 소비한다: 쓰레드와 소켓을 비교해보면 얼마나 큰 리소스를 소비하는지 알 수 있다. 쓰레드의 경우, 서버에서 수천개를 사용할 수 있는 반면에 소켓은 수백만개를 생성하여 사용할 수 있다. 리소스를 많이 소비하기 때문에 매번 생성하지않고 pool등을 사용하여 관리하며, 작은 작업에 사용하기 어렵다.
- 문맥전환(Context Switch)가 OS로부터 이루어진다: 커널 쓰레드는 선점형 스케쥴러에 의해 처리되는데, 때문에 문맥의 전환이 어플리케이션 레벨이 아닌 낮은 수준의 레벨에서 이루어진다. 프로그래머의 입장에서는 가시성이 떨어지는 영역이기때문에 예측이 어렵고 구현의 복잡성이 높아진다.
중량 쓰레드의 단점을 보면, 어플리케이션 레벨에서 구성하기가 쉽지않은 또는 꺼려지는 형태라는 것을 느끼게 될 것이다. 이러한 단점 때문에 경량 쓰레드인 파이버가 대두되었다.
3.2 경량 쓰레드는 무엇이 다를까?
다음으로는 파이버의 특징에 대해 알아보자.
- 리소스를 적게 소비한다: 하나의 JVM에서 수백만개를 생성하여 쓸 정도로 작은 리소스를 소비한다.
- 문맥전환이 어플리케이션 레벨에서 이루어진다: 문맥전환을 OS수준에서 진행하지 않기때문에 오버헤드가 매우 작다.
이전의 중량 쓰레드의 단점을 보완하는 특징들을 가지는 것을 볼 수 있다.
파이버는 하나의 쓰레드 위에 여러 파이버가 올라가는 형태로 구성된다. 어떻게보면 쓰레드의 쓰레드 같은 느낌이다. 하지만 쓰레드와는 멀티태스킹 방식에서 차이점을 가진다.
파이버는 협력적 멀티태스킹방식, 쓰레드는 선점형 멀티태스킹 방식을 채택한 개념이다. 쓰레드는 커널의 스케쥴러의 지시에 따라 작업여부와 상관없이 다른 쓰레드로 전환을 해야하지만, 파이버는 스스로 작업을 멈추고 양도해야 전환이 가능하다. (따라서 어떤 파이버 하나가 CPU를 점유하고 있다면, 다른 파이버는 휴지상태일 수 밖에없다)
이러한 문맥전환이 어플리케이션 레벨에서 이루어지기 때문에, 오버헤드가 적고 비동기 IO연산등을 진행할 때 엄청난 강점을 가지게 된다.
3.3 코루틴
앞선 3.2 경량 쓰레드는 무엇이 다를까?에서 파이버는 양도를 통한 전환을 한다고 언급했다. 파이버의 전환에서는 이 개념이 중요한데, 이런 제어흐름을 코루틴이라고 한다.
코루틴 supspend와 resume을 더한 흐름기법으로, 다음의 친숙한 예시를 보면 쉽게 이해가 가능하다.
async function asyncFunction() {
let promise = new Promise((resolve, reject) => {
setTimeout(() => resolve("완료!"), 1000)
});
let result = await promise; // 프라미스가 이행될 때까지 기다림 (*)
alert(result); // "완료!"
}바로 async/await이다. async와 await은 일반적인 함수의 call/return과는 다른 제어흐름을 가지고 있다. Promise들을 반환하는 비동기 함수가 존재하며, await를 통해 값을 기다리고 실행을 이어가는 형태이다.
코루틴의 특징이라고 말한 supspend와 resume이 여기에 녹아있다. Async함수는 await으로인해 suspend되고, promise가 이행되면 resume되는 흐름을 가진다.
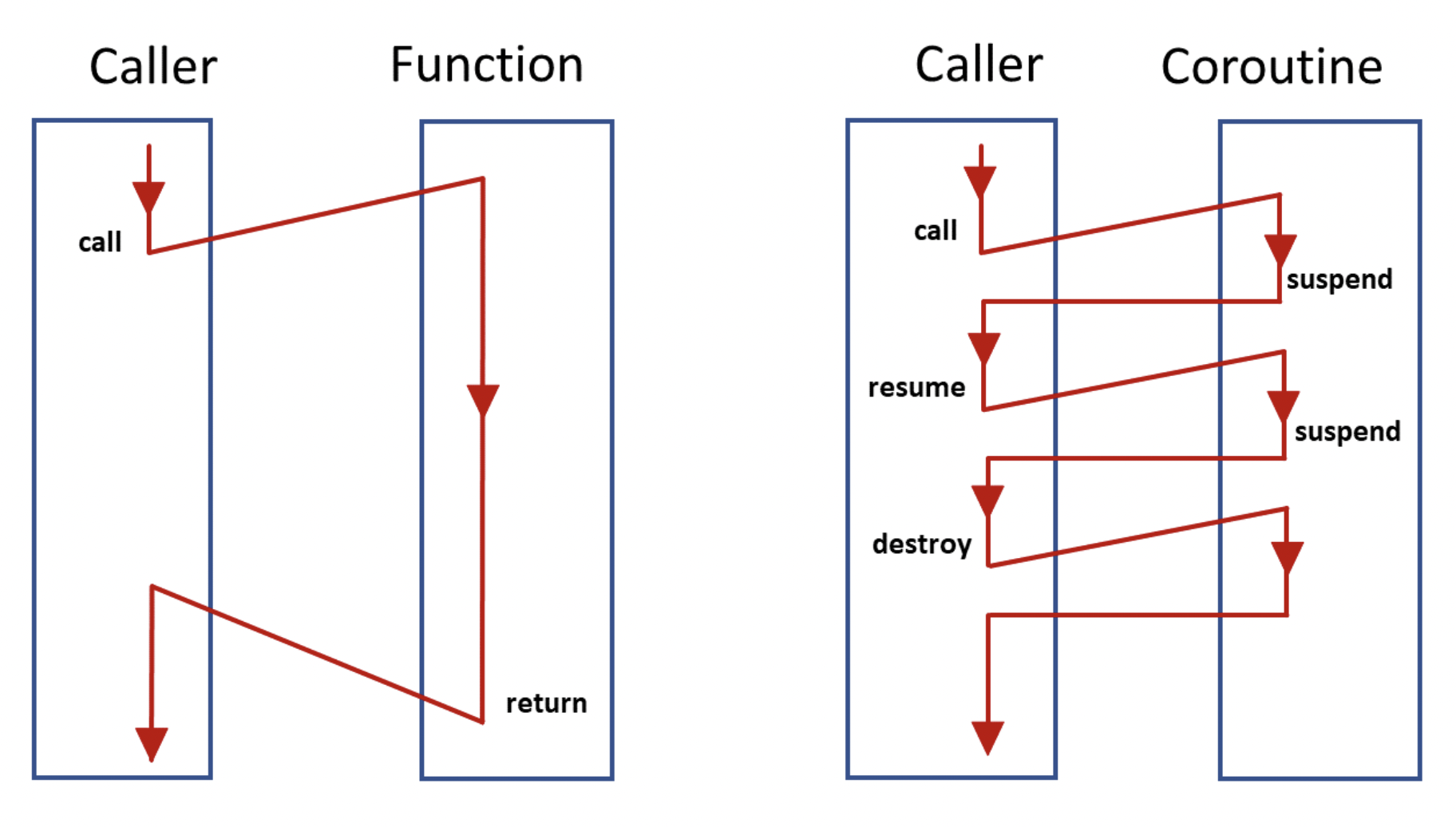
그림 4. 호출에 따른 Function과 Coroutine의 동작차이를 보여주는 그림
4. 경량쓰레드를 위한 자바진영의 노력
위와 같은 이유로 자바 진영에서도 경량쓰레드를 적용하기 위한 노력을 하기 시작했다.
이번 목차에서는 자바진영에서 어떤 방식으로 경량쓰레드를 개발해가고 있는지 간단하게 알아보자.
4.1 Quasar
"Quasar is a library that provides high-performance lightweight threads, Go-like channels, Erlang-like actors, and other asynchronous programming tools for Java and Kotlin." -Quasar docs내 소개글-
Quasar는 경량쓰레드 개념인 "fiber"를 JVM에 적용시키기 위한 라이브러리이다. docs의 설명에는 Go의 channels, Erlang의 actors 그리고 다른 비동기 고성능 경량쓰레드 도구와 같은 기능을 JAVA와 Kotlin에 제공하기 위한 도구라는 설명이 써져있다.
그렇다면 Quasar에는 어떤 개념이 있을지 알아보도록 하자.
4.1.1 fiber의 구현
Quasar에서는 자바의 Thread 클래스 대신 Fiber라는 클래스를 사용한다.
Quasar에서 "fiber"는 협력적으로 예약되는 가볍고 실행 스레드로, 블로킹이 발생할 가능성이 있는 작업을 만나면 자발적으로 제어를 양도한다. Fiber는 전통적인 스레드와 많은 면에서 유사하지만 더 적은 메모리를 사용하고 더 효율적으로 스케줄링될 수 있어 고성능 동시성 애플리케이션을 구축하는 데 적합하다.
다음은 fiber를 만들고 실행하는 예시이다.
public class MyFiber implements SuspendableRunnable {
public void run() throws SuspendExecution {
// Your fiber code here
}
public static void main(String[] args) throws Exception {
Fiber<Void> fiber = new Fiber<Void>(new MyFiber());
fiber.start();
fiber.join();
}
}위와 같이 SuspendableRunnable 인터페이스를 구현하는 클래스를 정의하여 실행하거나, 아래와 같은 방식으로 실행시킬 수 있다.
new Fiber<V>() {
@Override
protected V run() throws SuspendExecution, InterruptedException {
// your code
}
}.start();Fiber의 특징은 반환값을 가지며, 이 반환값이 Generic으로 정의되어 있다는 것이다. 반환값이 없는 경우 Generic V에 Void를 넣어 정의하면 된다.
그렇다면 Fiber를 사용해 간단한 Producer-Consumer 패턴을 구현해보자.
import co.paralleluniverse.fibers.*;
import co.paralleluniverse.strands.channels.*;
public class FiberExample {
public static void main(String[] args) throws Exception {
Channel<String> channel = Channels.newChannel(10, Channels.OverflowPolicy.BLOCK);
Fiber<Void> producer = new Fiber<Void>("producer") {
@Override
protected Void run() throws InterruptedException, SuspendExecution {
for (int i = 0; i < 10; i++) {
String message = "Message " + i;
System.out.println("Producing: " + message);
channel.send(message);
Fiber.sleep(100);
}
channel.close();
return null;
}
};
Fiber<Void> consumer = new Fiber<Void>("consumer") {
@Override
protected Void run() throws InterruptedException, SuspendExecution {
while (!channel.isClosed()) {
String message = channel.receive();
System.out.println("Consuming: " + message);
Fiber.sleep(500);
}
return null;
}
};
producer.start();
consumer.start();
producer.join();
consumer.join();
}
}위의 예시에서는 용량이 10인 채널을 만들어 Producer와 Consumer가 메세지의 전달 수단으로 사용한다.
Producer는 채널에 10개의 메시지를 보내며 각 메시지 전송 사이에 100밀리초 동안 일시 중지한다. 모든 메시지를 보낸 후에는 채널을 닫게된다.
Consumer는 채널이 닫히기 전까지 채널에서 메시지를 받으며, 각 메시지 수신 사이에는 500밀리초 동안 일시 중지한다.
Producer와 Consumer는 동시에 실행되며 채널을 통해 통신하게 된다. Fiber의 사용으로 전통적인 스레드의 오버헤드 없이 효율적이고 확장 가능한 동시성이 가능합니다.
예시에서 Fiber.sleep()은 특정 Fiber의 lock을 양도하기 위해 쓰인 것은 아니며, 기본적으로 Fiber는 백그라운드에서 실행되고 자체적인 스케쥴러에 의해 합동적으로 스케쥴링 된다. (물론 특정 Fiber를 사용하지 않고 다른 Fiber에게 기회를 주는 것을 강제적으로 하기위해 사용할수는 있다.)
4.1.2 어플리케이션 레벨 스케쥴러
앞서 말했던 경량쓰레드와 중량쓰레드의 가장 큰 차이는 스케쥴링의 주체였다. Thread클래스를 사용하는 자바의 native Thread는 OS에 의해 스케쥴링 되지만, Quasar의 Fiber들은 FiberScheduler라는 인터페이스의 구현체들에 의해 스케쥴링 된다.
FiberScheduler는 Fiber의 우선 순위를 기반으로 스케줄링하고, 각 Fiber가 선점되기 전에 일정한 시간 동안 실행되도록 보장한다.
Quasar는 FiberScheduler인터페이스의 다양한 콘크리트 클래스를 제공하는데, 이는 다음과 같다.
- ThreadPoolFiberScheduler: 기본 구현체로, Fiber를 실행하기 위해 스레드 풀을 사용한다.
- StrandBasedScheduler: 이 구현체는 Quasar의 Strand API를 기반으로 하며, Fiber를 생성하는 대신 Strand를 생성하는 대체 방법을 제공한다. Strand는 Fiber와 유사하지만 약간 다른 API를 가지며, 스레드 풀을 사용하여 Strand를 실행한다.
- CooperativeFiberScheduler: 이 구현체는 임베디드 시스템 또는 실시간 애플리케이션과 같은 단일 스레드 환경에서 사용하기 위해 설계되었으며, Fiber가 스케줄러에 의해 선점되는 대신 자발적으로 제어 권한을 양도할 수 있는 협력 스케줄링 메커니즘을 제공한다.
FiberScheduler는 Quasar 동시성 모델의 핵심 요소로서, Fiber의 실행을 효율적이고 충돌없이 관리하는 것을 목표로 한다.
자발적으로 lock을 양도하는 "fiber"의 특성에 따라, 과도하게 CPU를 점유하는 Fiber가 생겨날 수 있다. (이를 Runaway Fiber라고 한다.) FiberScheduler에서는 이를 모니터링하고 추적할 수 있는 정보를 제공한다고 한다.
