1.4 Delay, loss, throuput in networks
-> 성능 측정 지표들
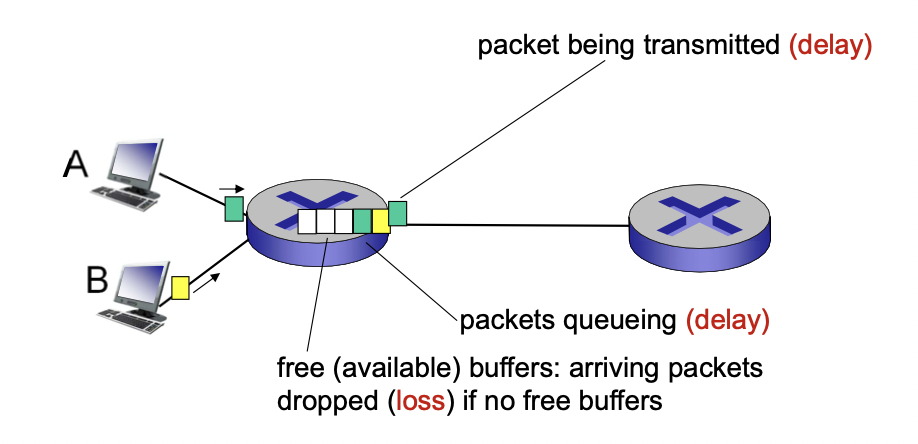
패킷의 도착 속도가 나가는 속도보다 커지면 패킷들은 큐에 쌓이게 되고 자신의 턴을 기다리게 된다.
-> 딜레이 발생(queueing delay)
-> 버퍼가 꽉차게 되면 패킷의 손실(loss)이 일어난다.
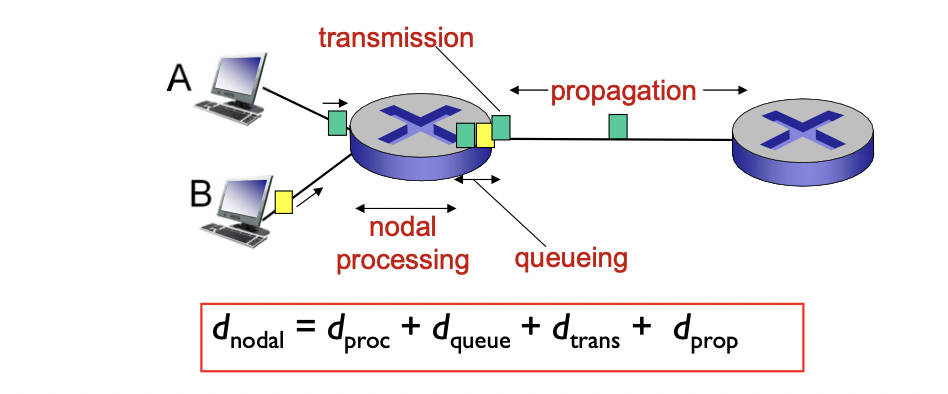
딜레이는 총 네가지의 구성 요소로 나누어 생각해 볼 수 있다.
1. processing delay(nodal processing)
- 패킷 전송 전에 프로세싱 하는 딜레이(비트 에러 체크, output link 결정) -> 데이터 처리에 걸리는 시간
- 보통 1 msec 보다 적게 걸린다.(굉장히 작음)
- queueing delay
- 전송을 위해 output link를 기다리는 시간(나가기 위해 걸리는 시간 -> 큐 안에서 나가기 까지 걸리는 시간)
- 라우터에서 얼마나 밀리는 지에 따라 달라진다.
- transmission delay
- dtrans = L/R
- 패킷의 모든 비트들을 회선에 올리는 시간 -> 큐에서 link로 모든 비트를 내보내는데 걸리는 시간
- propagation delay
- 한 비트가 목적지 까지 회선을 따라 이동하는데 걸리는 시간
- d: physical link의 길이, s: propagation 속도 -> dprop = d/s
예시 1
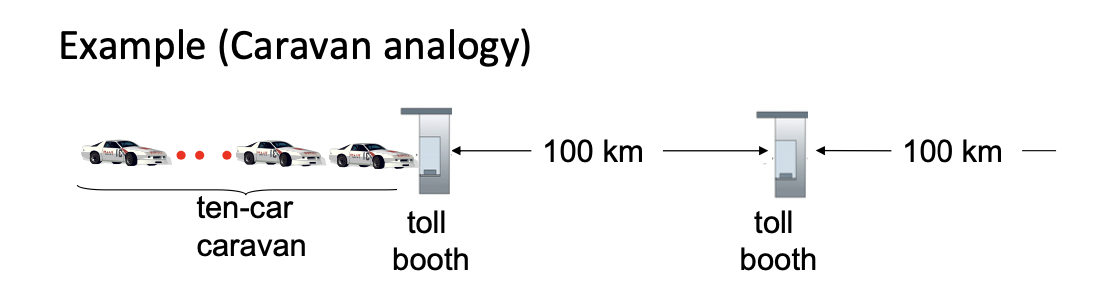
자동차의 속도 : 프로파게이션 딜레이와 관련 있음 -> 100km/h 로 가정
톨 부스 : 라우터 역할 -> 트랜스미션 딜레이와 관련 -> 서비스 하는데 12 sec이 걸린다고 가정
자동차 : 비트역할
carvan : 패킷 역할
carvan이 두번째 톨 부스에 줄 서기까지 얼마나 걸릴까(첫 차가 톨부스에 도착하면 마지막 차도 올때까지 대기한다고 가정)
-> 전체 carvan이 톨부스를 통과하는데 걸리는 시간 : 한 대당 12초 걸리니까 총 10대 이므로 120초
-> 마지막 차가 첫번째 톨부스에서 두번째 톨부스까지 가는 시간 : 100km를 100km/h로 달리니까 1시간
-> 전체 걸리는 시간 : 1시간 + 2분 = 62분
예시 2
자동차의 속도 : 1000km/h 로 가정
톨부스 : 서비스 하는데 1분이 걸린다고 가정
모든 차가 첫번째 톨부스에서 서비스 되기 전에 차가 두번째 톨부스에 도달 할까?
-> 차 한대가 다음 톨까지 가는데 걸리는 시간 : 1000km를 60분에 가니까 100km는 6분에 감(propagation delay = 6분)
-> 전체 carvan이 톨부스를 통과하는데 걸리는 시간 : 1분 x 10대 = 10분
1시에 출발한다고 했을 때
-> 첫차가 두번째 톨까지 가는데 걸리는 시간 : 1분 + 6분 = 7분 -> 1시 7분 도착
-> 두번째 차가 두번째 톨까지 걸리는 시간 : 7분 -> 1시 1분 출발, 1시 8분 도착(첫 차가 달리기 시작할 때 두번째 차는 톨부스에서 처리중이니까 1시 1분에 톨부스에 진입하는거)
-> 세번째 차가 두번째 톨까지 절리는 시간 : 7분 -> 1시 2분 출발, 1시 9분 도착
...
-> 첫 차가 도착했을 때(1시 7분) 8번째 차가 톨부스에서 처리중이고, 9,10번째 차는 대기상태
-> 차 한대가 2번째 톨에 도달하는 동안 맨 뒤 세대는 아직 첫번째 톨도 통과 못한 상태
-> 전체 걸리는 시간 : 프로파게이션 딜레이 6분 + 트랜스미션 딜레이(1분 x 10대) = 16분
1.4.1 queueing delay
R : 회선의 전송 속도 -> 단위시간 동안 보낼 수 있는 데이터의 양(bps)
L : 패킷의 길이(크기)
a : 단위시간 당 도착하는 패킷의 개수 -> 1초에 몇개의 패킷이 라우터에 들어오는가
(모든 패킷이 L로 같다고 가정)
La : 1초에 몇비트의 데이터가 라우터에 들어오는가 -> traffic이 들어오는 속도
R : traffic이 나가는 속도
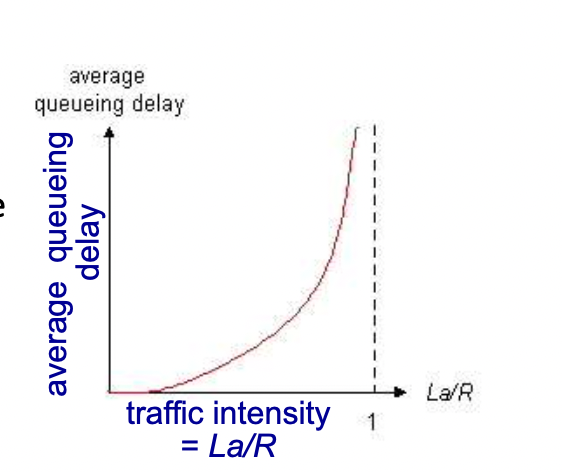
-> La/R = traffic intensity(트래픽 밀도) = 들어오는 속도와 나가는 속도의 비율
-> La/R = 0 : queueing delay가 적다
-> La/R = 1 : 비율은 같아서 들어오는 속도가 일정하다면 딜레이가 없을 수 있지만, 라우터로 들어올 때 일정하게 들어오는 것이 아니라 어느 때는 많이, 어느 때는 적게 들어오기 때문에(들어오는 패턴이 랜덤) 한꺼번에 트래픽이 몰리게 되면 그 순간에 queueing이 생기게 되어 delay가 커진다.
-> La/R > 1 : 들어오는 속도가 더 크기 떄문에 queue는 끝없이 증가하고, drop이 없다고 가정하면 기다리는 시간이 무한해 진다.
1.4.2 packet loss
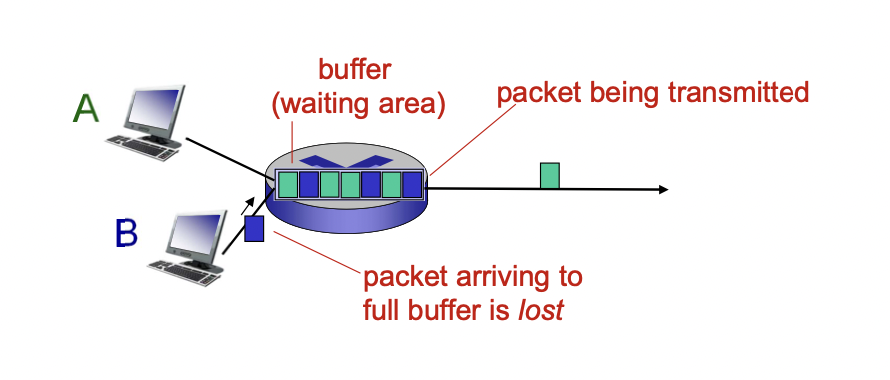
큐는 유한한 용량을 가지고 있다.
큐가 가득 차게 되면 더이상 패킷 못받으니까 패킷이 드랍된다.
-> 재전송을 통해 다시 보내야 한다.
1.4.3 Throughput
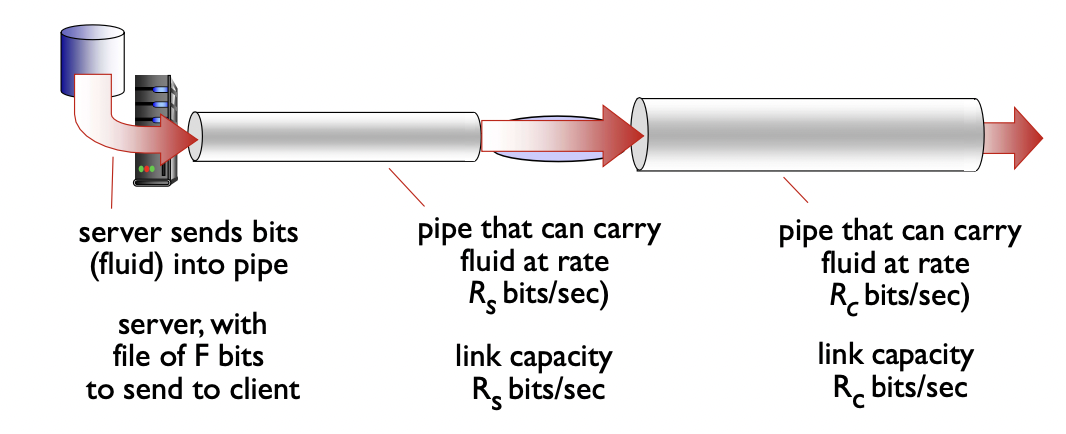
throughput : sender와 receiver 사이에 비트가 전송되는 속도를 의미한다.
- instantaneous : 순간적 -> 특정 지점에서의 속도
- average : 평균적 -> 전체적인 속도
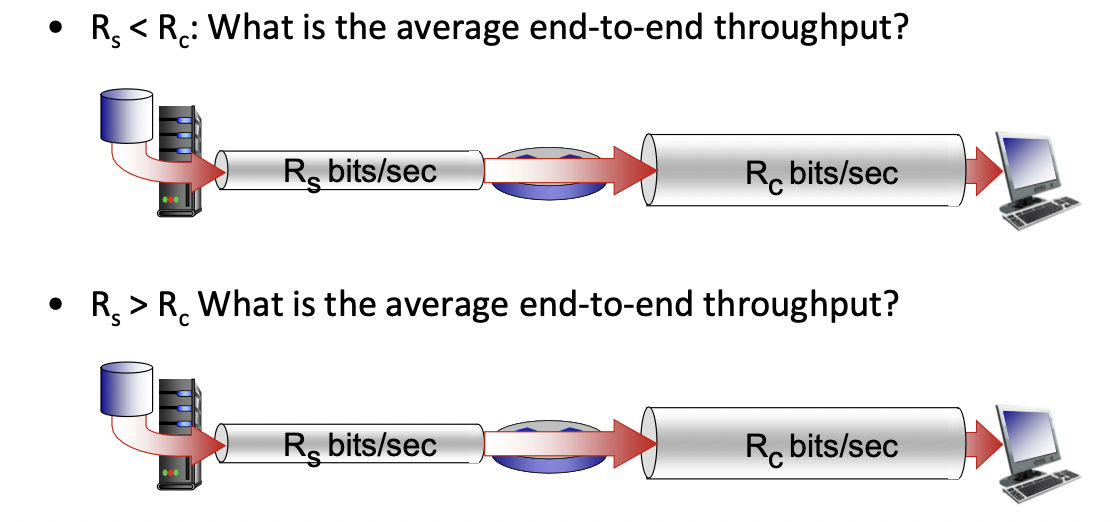
Rs < Rc : Rc가 더 빠르지만 라우터에 도달하는 Rs에서 오는 데이터들 만큼만 전송할 수 있다. -> 속도는 Rs에 따라 결정된다.
Rs > Rc : Rs가 더 빠르기 때문에 라우터에 패킷이 도달 하더라도 Rc의 속도로 패킷을 전달하게 된다. -> 속도는 Rc에 따라 결정된다.
-> bottleneck link : 앞에 있는 것의 전송 속도가 느리다면 뒤에 있는 파이프가 속도가 빠르더라도 앞의 속도에 맞춰야 한다. 마찬가지로 뒤의 것이 속도가 더 느리다면 앞에서 빨리 보내주더라도 늦게 보낼 수 밖에 없다 -> end to end의 전송속도가 결정된다.
throuput : internet scenario
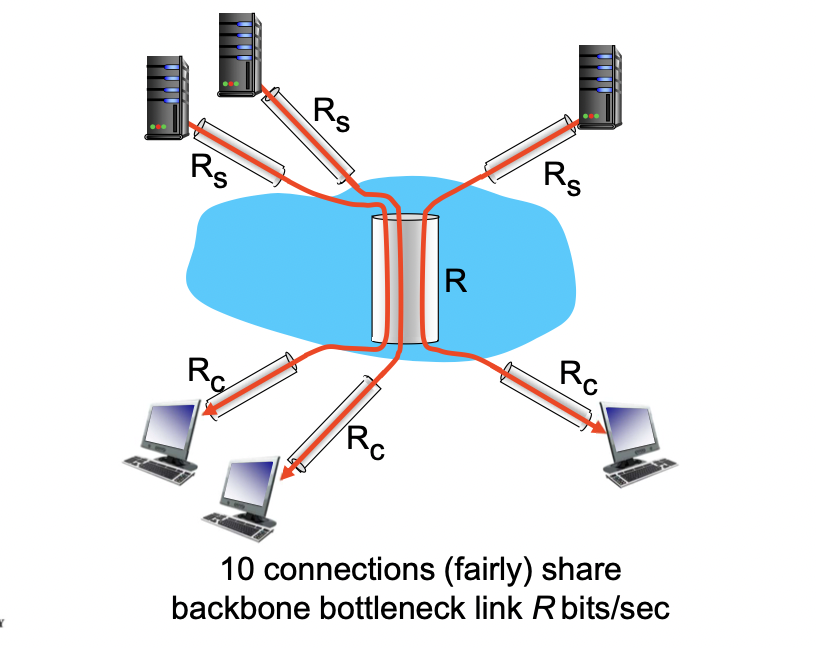
출발지가 10개, 목적지가 10개 있고, 한 파이프를 통해 보낼 때 end to end throughput은 Rs,Rc,R/10(공유 네트워크를 여러명이 나눠 사용) 중 가장 작은 것에 따라 결정된다. 그리고 그것이 bottleneck link가 된다.
-> 보통 core는 좋은 것을 쓰기 때문에 Rs나 Rc가 bottleneckdl ehlsek.
1.5 protocol layers, service models
네트워크의 구성 요서는 매우 다양하다.
-> hosts, routers, links of various media 등
-> 어떻게 network의 구조를 구성할 것인가? : layer 구조를 통해 각 layer는 다른 기능을 수행한다.
-> 각각의 layer는 하는일이 정해져 있다.(각 layer가 서비스를 정의, 구현하고 있다.)
-> 다른(이후의) layer에서 일처리가 잘된다고 가정(신경안씀)하고 해당 layer를 구성한다.
layering 모델을 사용하는 이유
복잡한 시스템을 간단하게 만들 수 있기 때문이다.
- 각 레이어끼리의 영향을 최소화 하도록 해서 한 레이어를 수정하더라도 다른 레이어를 건드릴 필요가 없다.
- 모듈화를 통해 유지, 업데이트가 쉽다.
Internet protocol stack
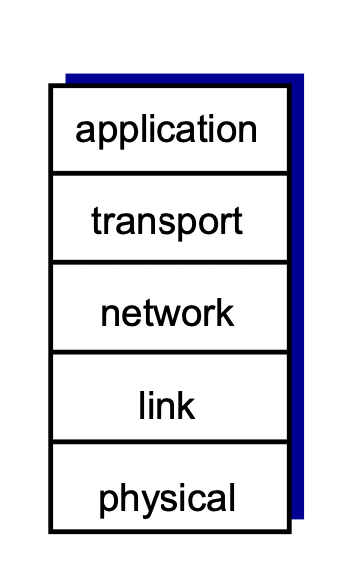
5가지 layer로 구성되어 있다.(layer마다 기능이 있음)
- application : 네트워크 application을 지원해 준다.(메세지 주고받도록 해줌)
-> protocol : FTP, SMTP, HTTP등 - transport : 프로세스 간 데이터 전달. 목적지까지 잘 전달하도록 해 준다.
-> protocol : TCP, UDP 등 - network : source부터 destination까지 패킷을 어느 경로를 통해 전달할지 결정한다.
-> protocol : ip, routing protocols - link : 한 홉에 대해 source에서 다음 destination까지 어떻게 데이터를 잘 보낼 것인가.
-> protocol : Ethernet, wifi 등 - physical : 한 홉 사이의 데이터 전달과 관련해서 어떤 식으로 전달할지.(물리 매체)
-> wire, wireless 등
ISO/OSI referenece model
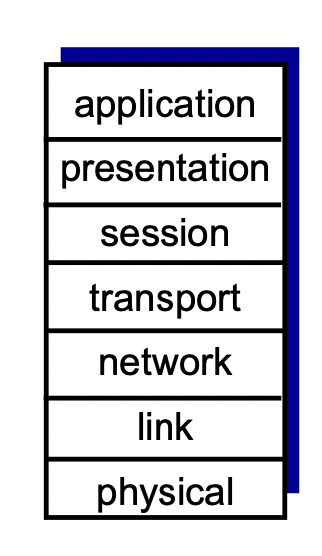
위의 5 레이어 중 application을 세가지로 세분화 하여 7 레이어로 만든것 -> OSI 7-layer model
- presentation : 보안, 데이터 압축, 기계 특화 등
- session : 동기화, 체크포인트 만들기, 데이터 복구 등
-> 5레이어에서는 이런 기능들이 필요하면 application에서 구현되어야 한다.
Encapsulation
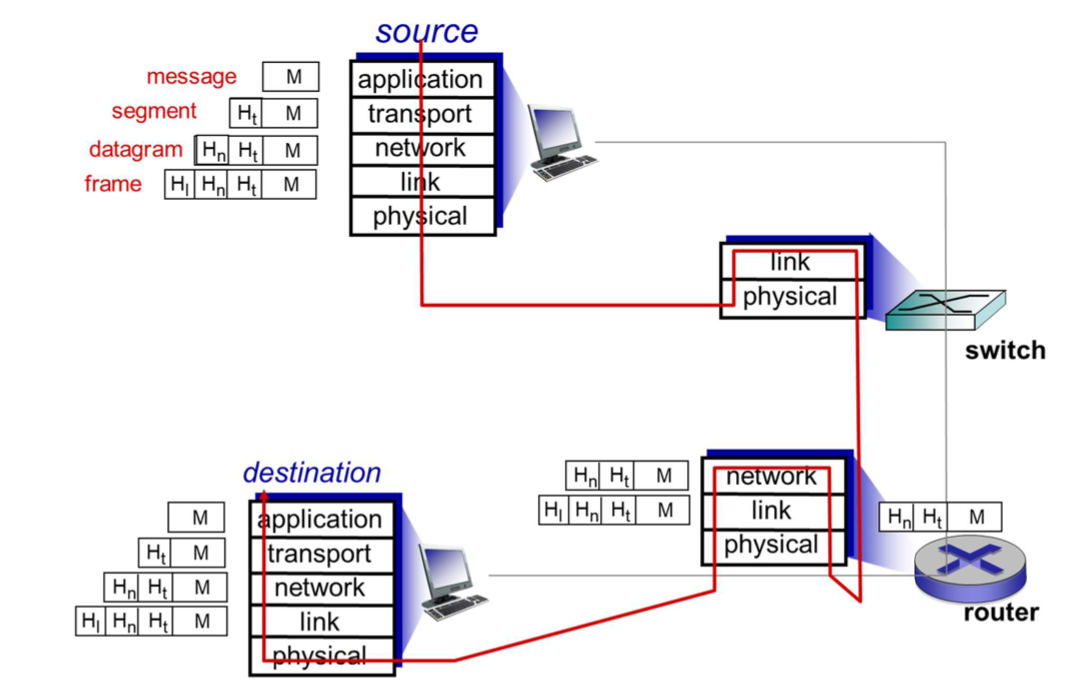
store and forward 방식을 통해 데이터가 전달된다.
각 레이어를 통과하며 헤더를 붙인다.
목적지에 있는 같은 레이어에서 헤더를 보고 해석한 후 적절한 대응을 하도록 한다.
중간에 여러 디바이스를 거친다.
- L2 스위치 : link와 physical 레이어(두개의 레이어)만 구현되어 있는 디바이스. 경로 결정
- 라우터 : network, link, physical 레이어(세개의 레이어)만 구현되어 있는 디바이스. 경로 결정
-> application, transport는 source랑 destinatino에서만 필요하다.(end host에서만 구현되어 있따.) -> 중간과정에서는 프로세싱 할 필요가 없기 때문에 해당 레이어가 없다.
받은 패킷 중 자기가 필요한 부분만 프로세싱 해서 보내는 것이다.
캡슐화 : 상위 레이어로 부터 온 데이터에 자기 헤더 붙이는거, 목적지에서는 레이어 올라가면서 자기 헤더 떼버리는거
1.6 networks under attack : security
원래 인터넷을 설계할 때는 보안에 중점을 두는 것이 아니라 순기능(어떻게 데이터를 전달할까 등)에 중점을 두고 만든다.
-> 모든 레이어에서 보안이 중요하게 여겨진다.
maleware를 인터넷을 통해 host에 집어 넣는다.
virus : 스스로 증식한다. 유저에 의해 퍼진다.
worm : 스스로 증식한다. 스스로 동작할 수 있다.
-> 목적 : 방문기록, 업로드 등의 정보를 빼오는 것이다. -> spyware male ware
-> 여러 컴퓨터에 worm을 심어서 스팸이나 디도스 어택을 하도록 한다.
서버, 네트워크 인프라를 공격한다
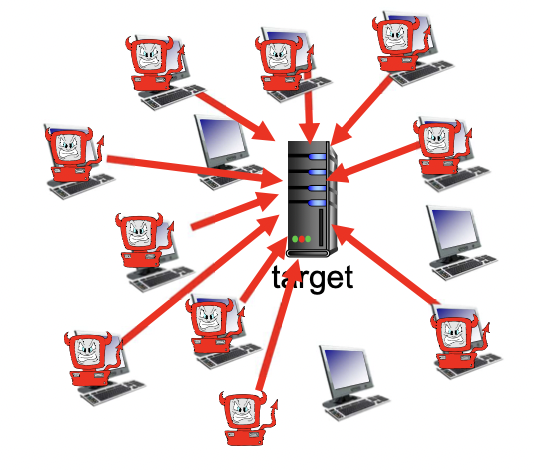
Dos : 한 컴퓨터에서 bogus traffic을 생성해서 타깃을 공격한다.
-> D Dos(distribute dos) : 여러 컴퓨터에서 일정한 시간에 타겟에 데이터 트래픽을 마구 보내서 서버를 다운시킨다.
snuff packets
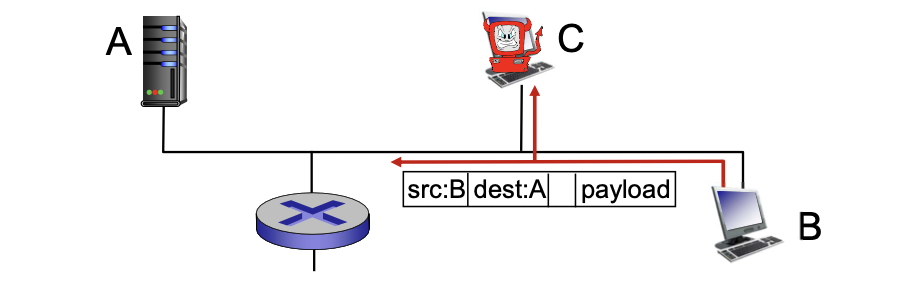
sniffing : 정보를 가로채는거(무선에서 자주 일어남 - ethernet, wifi 등)
-> 같은 주파수 대역의 와이파이 같은거 설정해서 주고받는 데이터 중간에서 빼오는거
가짜 주소 사용
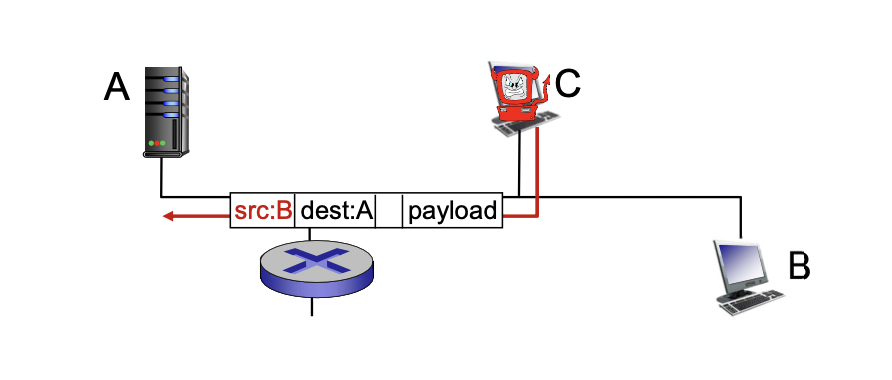
Ip spoofing : 메세지를 보내는데 중간에서 source address를 바꿀 수 있음(추적 회피)
-> B에서 보낸 데이터를 스니핑으로 가로채고 이상하게 만들어서(메일웨어나 디도스 등) A로 보내는데, 이 때 스푸핑을 이용하여 B에서 보낸것처럼 주소를 바꿔서 보낸다.
출처 및 참고
https://wonder-j.tistory.com/34?category=819863
https://inyongs.tistory.com/48?category=761968
https://wogh8732.tistory.com/14
Computer Networking A Top-Down Approach 7-th Edition / Kurose, Ross / Pearson
서강대학교 기초컴퓨터네트워크 강의자료
