2.2 Web and HTTP
Web and HTTP
웹 브라우저 - 클라이언트 / 웹 서버 - 서버
브라우저랑 서버간 통신을 할때 사용하는 프로토콜이 http 이다.
-> 구체적으로 보면 웹 페이지를 서버로부터 다운받아서 브라우저에 표현해 주는 것.
-> 하나의 웹 페이지는 오브젝트(html 파일, 이미지, applet, 오디오 등)로 구성됨.
-> 웹 페이지는 기본적으로 html파일과 그 내에서 다른 오브젝트 들이 참조가 되어 있다.
-> 각각의 오브젝트들은 url이라는 주소에 의해 addressing 될 수 있다.
(Uniform resource locator = wed address = url)
-> Url : Host name(웹 서버의 주소(도메인 네임/ip 주소)) + path name(어느 디렉토리의 어느 파일인가)
HTTP overview
HTTP : hypertext transfer protocol
-> hypertext : 링크 달려 있어서 누르면 바로 링크로 옮겨지게 되는것.
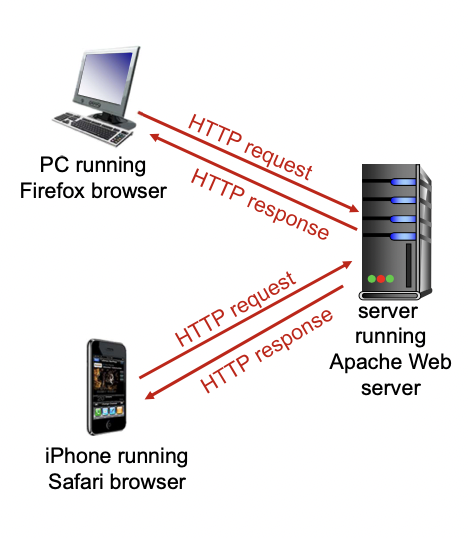
- 웹에서 사용되는 어플리케이션 레이어 프로토콜이다.
- 클라이언트 / 서버 모델을 따른다.
-> 클라이언트 : HTTP프로토콜을 이용하여 요청하고, 응답받고, 화면에 출력해 주는 브라우저
-> 서버 : HTTP 프로토콜을 이용하여 요청에 대한 응답으로 오브젝트를 보내주는 서버
특징
- TCP 사용 : 웹 페이지의 내용을 손실 없이 전달해 줘야 하기 때문에 TCP를 사용한다.
-> 클라이언트는 소켓을 만들고 TCP connection을 요청한다.
-> 서버가 TCP connection을 클라이언트로 부터 받으면 HTTP message가 connection을 따라 전달된다.(브라우저(http client) <-> 웹 서버(HTTP server))
-> TCP connection을 close한다.(통신 마무리) - stateless 하다
-> 서버는 클라이언트의 정보를 기록하지 않는다. (기록이 필요하면 쿠키를 사용하여 state를 관리함, http는 기본적으로 stateless)
-> 만약 state를 유지하게 되면 수많은 정보를 관리하기가 복잡하고 유지보수가 어려워 진다. - stateful protocol vs stateless protocol
-> stateful protocol은 과거의 history(state)를 기록한다. (state에 따라 행동을 취해야 할 때 기억한다.)
-> 상태를 저장하기 때문에 만약 서버나 클라이언트에 문제가 생기면 state 불일치가 발생할 수 있고 조정 되어야 한다. -> 관리가 복잡해 진다.
HTTP connections
- non-persistent HTTP(~ 1.0 버전)
-> 최대 하나의 오브젝트가 TCP connection을 통해 전달된 후 connection을 close한다.
-> 여러개의 오브젝트가 있으면 여러개의 connection을 만들어야 한다.
-> 비효율적 - persistent HTTP(1.1 버전 ~)
-> 하나의 TCP connection을 통해 여러개의 오브젝트들이 전달될 수 있다.
-> 현대 대부분의 웹 브라우저들이 persistent HTTP connection을 사용한다.
Non-persistent HTTP
유저가 URL을 들어간다고 가정해 보자. (파일이 텍스트와 10개의 이미지를 참조하는 상황)
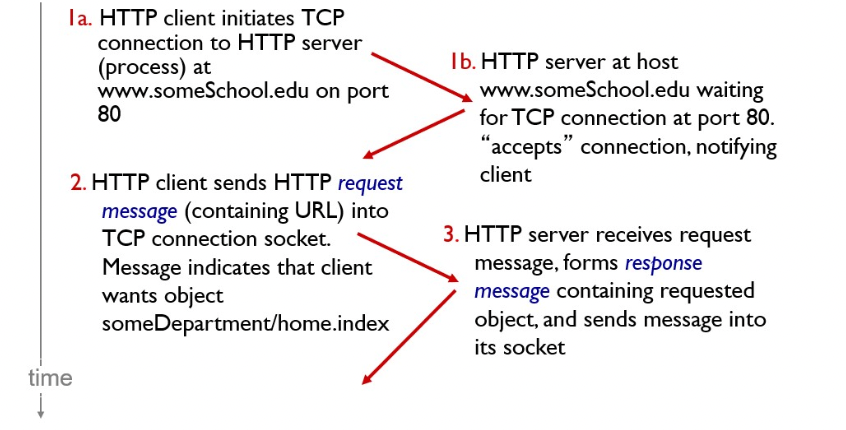

- 1a. HTTP 클라이언트가 HTTP 서버(url 서버, 기본 포트 80번)에게 TCP connection을 요청한다.
- 1b. 서버는 기다리다가 connection을 받아들이고 받아들였다는 내용을 클라이언트에 알려준다.(서로 연결됨)
- HTTP 클라이언트는 클라이언트가 원하는 오브젝트를 포함하는 request message를 TCP connection socket을 통해 보낸다.
- HTTP 서버는 request message 내용을 받고 원하는 내용을 포함하는 response messag를 만들어서 소켓을 통해 보낸다.
- TCP 커넥션을 끊는다.
- HTTP client는 response message를 받고 화면에 표시한다. -> html을 parsing 하는 과정에서 10개의 참조된 이미지를 발견한다
- 10개의 이미지에 대해 1~5의 과정을 반복한다.
-> 이런 과정을 handshake 라고 부른다.(서로 요청, 응답 하는거)
- 10개의 이미지에 대해 1~5의 과정을 반복한다.
response time
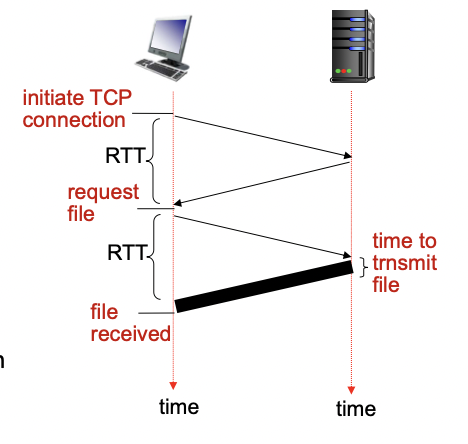
- RTT(round-trip time) : 작은 패킷이 클라이언트를 떠나 서버에 갔다가 다시 돌아오는 시간
-> 메세지가 갔다 오는데 걸리는 시간 - HTTP response time
-> TCP connection 맺는데 1 RTT가 걸린다.
-> HTTP request를 보내고 첫 몇 바이트의 HTTP response가 돌아오는데 1 RTT가 걸린다.
-> 보내는 오브젝트의 파일이 크면 파일 전송 시간도 포함된다.(transmission time)(이미지의 굵은 선)
-> non-persistent의 HTTP response time = 2 x RTT + transmission time
persistent HTTP
- non-persistent HTTP issues
-> 오브젝트 당 2RTT가 요구된다.
-> 커넥션을 만드는데 오버헤드가 발생한다.
-> parallel TCP connection을 할 수 있다.
-> 예를들어 이미지 10개가 필요하면 사용자가 지정한 개수만큼 커넥션을 만들어 동시게 요청을 보내고 받을 수 있다. - persistent HTTP
-> 서버가 response를 보내도 connection을 열어둔다.(유지)
-> 이후의 같은 클라이언트와 서버는 열려있는 connection을 사용한다.
-> 필요한 오브젝트가 있으면 connection을 통해 바로 request를 보낸다.
-> 예를들어 http를 받아서 화면에 출력하다가 이미지 같은 오브젝트가 필요하다는 것을 알게 되면 바로 connection을 통해 요청메세지를 보낸다.
-> 요청에 대한 응답을 기다리지 않고 한 커넥션으로 한번에 연속하여 요청을 할 수 있다.(파이프 라이닝)
-> 예를들어 이미지 10개가 필요하면 하나 요청하고 하나 받고 다음꺼 요청하고 ... 이런게 아니라 한번에 여러개의 요청을 보내고 여러개의 응답을 받는다.
-> 모든 referenced object를 보내는데 1RTT 정도 걸린다.
-> 우선 http connection 연결하는데 1RTT, 그 이후로 오브젝트 파일들에 대해 파일 당 1RTT(connection은 필요 없음) -> 총 1 + n RTT
HTTP request message
HTTP message에는 두 종류가 있다 : request, response
- request : 클라이언트가 만들어서 서버로 보내는거
- response : 서버가 만들어서 클라이언트로 보내는거
HTTP request message는 ASCII 형태로 메세지를 구성한다.
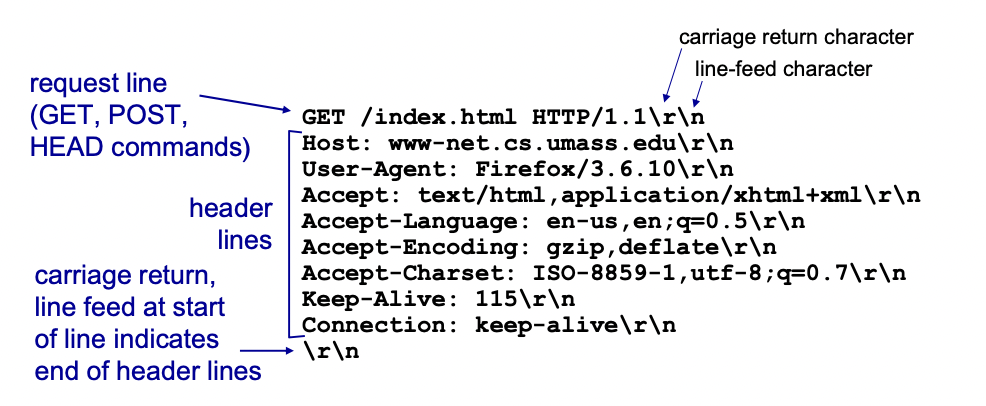
-> \r\n으로 줄바꿈
-> keep-alive : 115 -> 115초 동안 커넥션을 유지해라(반응 없으면 닫아라)
-> connection : keep-alive -> 커넥션을 유지해라(persistent)
일반적인 format
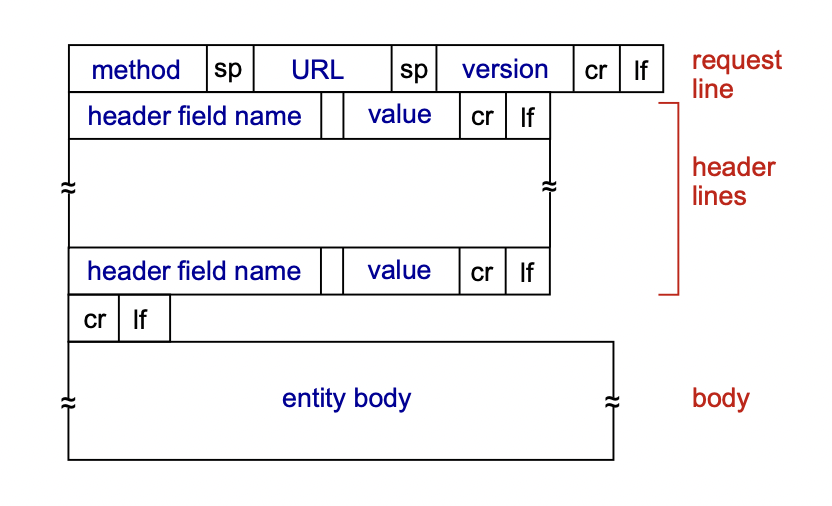
header : body를 전달하는데 필요한 값.
body : 진짜 전달하는 내용물
Uploading form input
- POST method
-> 웹 페이지는 보통 인풋을 포함한다.(클라이언트에서 인풋 주는거 -> 체크박스 등)
-> 메세지를 통해 전달한다.(entity body에 값을 넣어서 보내준다.)

- URL method
-> GET method를 사용한다.
-> 클라이언트가 서버로 url을 통해 값을 전달해 준다.

HTTP request message: GET vs POST
- HTTP POST request는 클라이언트로 부터 서버로 추가적인 데이터를 보내는데, 인풋으로 주는 값이 메세지의 body에 들어간다.
- HTTP GET request는 모든 데이터를 URL에 포함시킨다.
Method types
- HTTP/1.0
-> GET, POST, HEAD
-> HEAD : 오브젝트 요청하면 response는 오는데 오브젝트는 안오는거(테스트용) - HTTP/1.1
-> GET, POST, HEAD
-> PUT : 파일 업로드
-> DELETE : 파일 삭제
HTTP response message
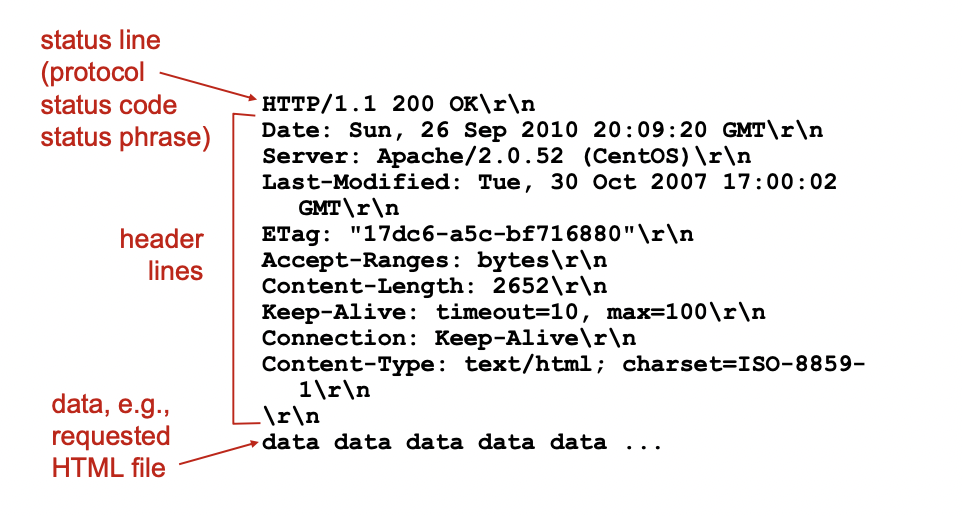
메세지 중 Last-Modified -> 마지막 바뀐 날짜 저장 -> 캐쉬 사용할 때 웹 서버에서 last modified를 보고 캐쉬에 저장된것 보다 최신인 것이 있으면 그것을 사용하고 없으면 캐쉬 그대로 사용

User-server state : cookies
- HTTP 서버는 stateless로 상태를 기록하지 않지만, 기록이 필요한 경우가 있다.
-> 이럴 경우 Cookie가 사용된다. - Cookie : 작은 데이터 조각으로 사용자의 컴퓨터(클라이언트)에 저장된다.
-> 서버가 클라이언트를 기록하기 위한 서비스에 사용된다.
-> 로그인, 장바구니, 게임 점수, 방문 기록 등
동작 과정
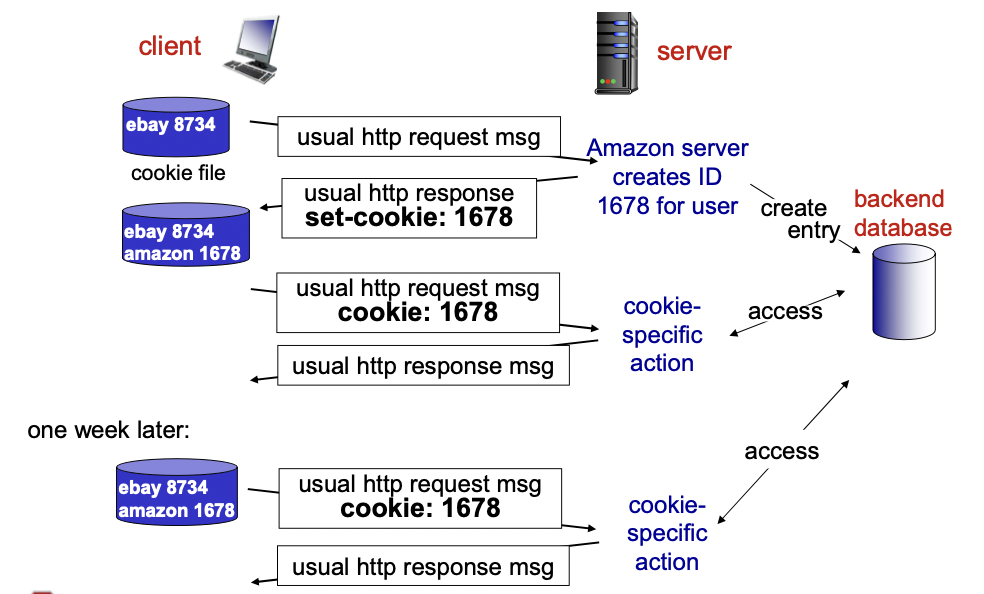
1. 클라이언트가 서버로 request 메세지를 보낸다.
2. 서버에서는 ID를 하나 만들어서 쿠키로 세팅하고 클라이언트로 response 해 준다. 동시에 관련 정보들을 데이터베이스에 저장한다.
3. 다시 접속할 때 쿠키 번호를 request 메세지에 담아서 함께 보낸다.
4. 서버에서는 해당 쿠키에 맞는 것을 데이터베이스에서 찾아서 response 해 준다.
정리하자면
- 클라이언트에 쿠키 파일이 없으면 서버에서 ID를 생성하고 response msg에 쿠키를 포함하여 보내준다. 그리고 ID를 데이터베이스에 저장한다.
- 클라이언트에 쿠키 파일이 있으면 request msg에 쿠키 파일을 함께 보내고, 서버의 데이터베이스에서 사용자의 state에 해당하는 response msg를 보내준다.
- 이 때 HTTP가 state를 저장하는 것이 아니라 쿠키가 state를 저장하고 있는 것이고, HTTP는 쿠키를 전달만 해 주는 것이다.
Web caches(proxy server)
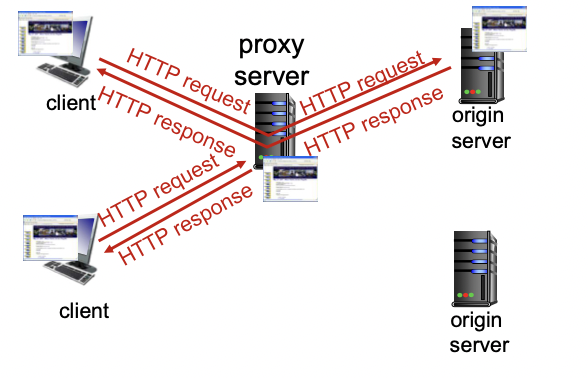
데이터 제공 서버는 origin server이고, proxy server는 클라이언트와 origin 서버 사이에 있는 개체이다.
용도 : origin 서버로부터 데이터를 자주 가져오는데, 자주 가져오는 오브젝트들을 proxy에 저장하면 origin 까지 갈 필요 없이 proxy로 부터 받아오면 된다. 실제 서버에 비해 사용자에 가깝게 위치한다.
과정
- 브라우저에 setting 되어 있어야 한다.
- proxy의 cache에 오브젝트가 존재하면 오브젝트를 바로 반환받는다.
- proxy의 cache에 오브젝트가 없다면, origin 서버에 오브젝트를 request해서 reponse 받아서 클라이언트에 전달해 준다. 그리고 새 데이터를 cache에 저장한다.
More about web caching
1. 캐쉬는 클라이언트와 서버의 역할 모두 수행한다.
-> 클라이언트로 부터 오는 request에 대해서는 서버 역할
-> origin 서버에게 요청할 때는 클라이언트 역할
2. 특정 ISP에서 캐쉬를 운영한다.
-> 대학교, 회사 등
3. web caching을 사용하는 이유
-> 클라이언트 입장에서 데이터를 빠르게 가져올 수 있다.(response time을 줄일 수 있다.)
-> 트래픽을 줄일 수 있다.(캐쉬를 사용하지 않으면 클라이언트의 모든 request가 origin 서버로 가기 때문에 bottleneck이 걸릴 수 있는데, 캐쉬를 사용하면 proxy 서버로 request가 분산되기 때문에 트래픽이 줄어든다.)
-> 인터넷 상에 많이 존재한다.
예시
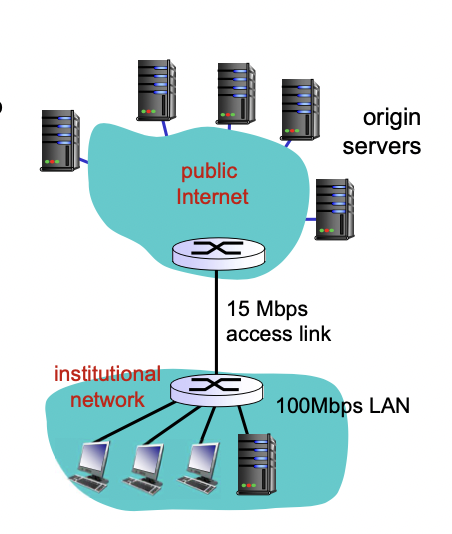
가정상황
- 오브젝트의 사이즈 : 1Mbits
- 브라우저가 origin 서버에 요청하는 평균 횟수 : 15/sec -> 초당 15번
- origin 서버로부터 라우터까지 걸리는 시간 : 2초
- access link에서의 딜레이 : 0.01초
- access link rate : 15Mbps
결과
- 초당 15번 요청하는데 오브젝트의 사이즈가 1Mbits이므로 초당 15Mbits -> 15Mbps의 요청
-> LAN 활용도 : 15Mbps/100Mbps -> 15%
-> access link 활용도 : 100%
-> access link utilization이 100%면 queueing delay가 발생한다.(congestion at access link)(La/R = 1)
해결법 1
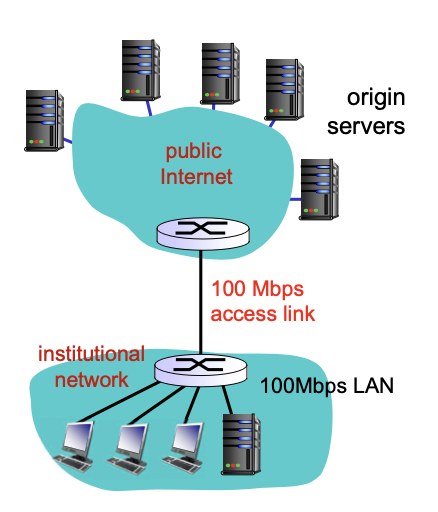
access link를 늘린다. -> 기존의 15Mbps를 100Mbps로 늘림
-> access link 활용도 15/100 -> 15%
-> queueing delay 해결(딜레이는 origin 서버에서 받아오는 시간 2초 + access link에서 딜레이 0.01초 = 2.01초 정도밖에 안걸림)
-> 비싸다는 단점이 있다.
해결법 2
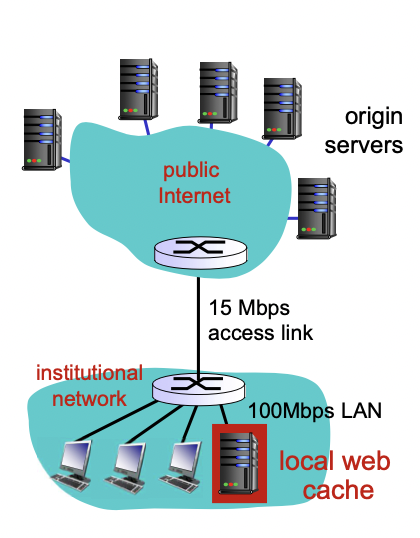
웹 캐쉬 설치 -> 캐쉬에 있을 확률(web cache hit rate) : 0.4로 가정
-> 40%의 requeset는 캐쉬에서 가져오기 때문에 0.01초 걸림
-> 60%만 origin 서버에 요청하기 때문에 access link 활용도 0.6(엑세스링크에 걸리는 부하 줄어듬)
-> 60%의 request는 2.01초 걸림
-> 가격이 싸다.
Conditional GET
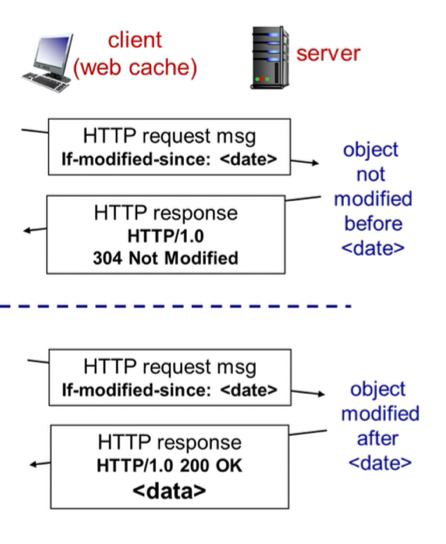
웹 캐쉬의 문제점 : origin 서버의 파일의 오브젝트가 바꼈을 수 있다.(업데이트 됐을 수 있다.), 실시간으로 보여주는 것(뉴스, 주식 등)을 캐쉬에서 가져오는 것은 의미가 없다.
-> 오브젝트가 변했는지 확인하는 방법 : conditional-get -> GET method의 옵션에 if문을 달아준다
-> If-modified-since: <날짜>
-> 만약 날짜 기준으로 안바꼈으면 웹 캐쉬 에서 받는다.
-> 만약 날짜 기준으로 바꼈으면 origin 서버에서 받는다.
동작 방식
-> 클라이언트가 웹 캐쉬에 요청
-> 웹 캐쉬가 서버에 요청
-> 데이터가 안바꼈으면 서버에서 웹 캐쉬로 304 Not Modified 메세지 response
-> 캐쉬의 데이터 클라이언트에 전송
-> 데이터바 바꼈으면 서버에서 웹 캐쉬로 200 메세지랑 데이터 reponse
-> 캐쉬 업데이트 하고 클라이언트에 데이터 전송
출처 및 참고
https://inyongs.tistory.com/59?category=761968
https://wogh8732.tistory.com/23?category=670138
Computer Networking A Top-Down Approach 7-th Edition / Kurose, Ross / Pearson
서강대학교 기초컴퓨터네트워크 강의자료
