Network Layer
네트워크 레이어의 기본적인 역할
- sending host로 부터 receiving host까지 세그먼트를 전달해 준다.
- sending side에서는 세그먼트를 트랜스포트 레이어로 부터 받아서 ip 헤더를 붙여서 datagram으로 만든다.
- receiving side에서는 전달받은 datagram에서 ip 헤더를 제거한 후 트랜스포트 레이어로 올려보내준다.
- 네트워크 레이어는 모든 host, 라우터 들에 구현되어 있다.(트랜스포트 레이어는 end host에만 존재)
- 패킷이 전달될 때 라우터를 거치게 되는데, 이 때 항상 네트워크 레이어까지 올라가서 ip 헤더를 검사한다. 그리고 필요한 처리를 한 후 다음 라우터로 전달해 준다.
Network Layer Functions
-
Forwarding : 라우터의 input으로 들어온 패킷을 적절한 output으로 내보낸다.
-> 어떤 아웃풋으로 보낼지 택하는것
-> 데이터 영역(data plane) -
Routing : source 부터 destination 까지 패킷을 어떤 경로로 보낼지 결정한다.
-> 목적지를 향해 가기 위해 어떤 경로로 갈 것인가(경로 설정, 네비게이션 역할)
-> 컨트롤 영역(control plane)
Network Layer : Data plane
- local, per-router function이다.
- 패킷이 들어 오면 ip 헤더의 내용을 바탕으로 어느 쪽으로 내보낼지 판단한다.
- Forwarding function
Network Layer : Control plane
- network-wide logic이다.
-> 라우터 하나만 가지고 하는것이 아니라 라우터끼리 협력해야함. - datagram이 어떤 경로로 전달될 지 결정한다.
- two control-plane approaches
-> 전통적으로는 라우팅 알고리즘은 라우터에 구현되어 있어서 라우터끼리 메세지를 주고받아서 경로를 결정했다.
-> 최근에는 software-defined networking(SDN) 을 사용하여 서버에서 경로를 계산하고, 라우터들은 서버의 지시에 따라 데이터를 forwading 해 주는 방식을 사용한다.
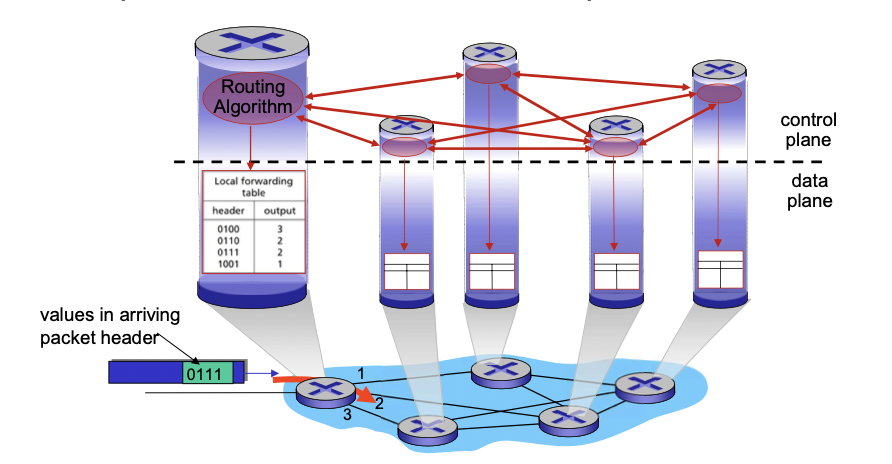
per-router Control plane
control plane에서 각각의 라우터에서의 라우팅 알고리즘을 통해 경로를 학습한 후 포워딩 테이블을 만들어서 data plane으로 넘겨주면, data plane에서는 이 테이블을 보고 아웃풋 방향을 선택한다.
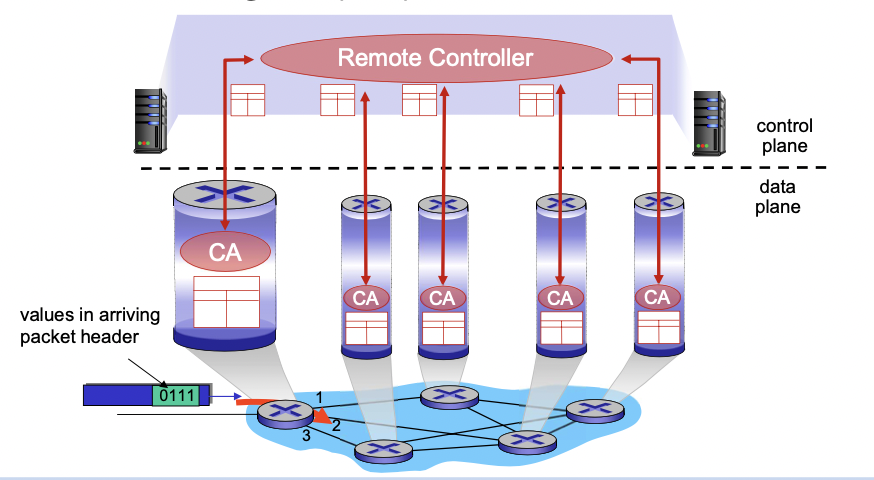
Logically Centralized Control plane -> SDN 형태
서버에 control plane이 있어서 라우터에서는 서버의 지시를 따라 데이터를 포워딩 해 준다.
CA : 서버와의 통신을 위해 존재
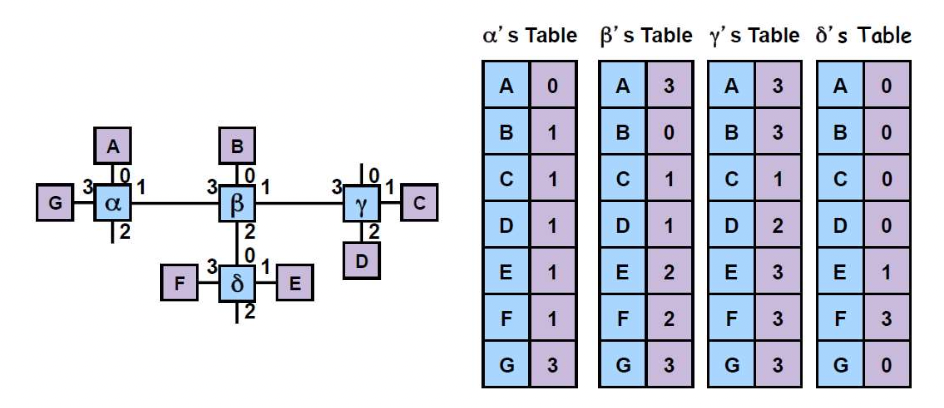
Routing
Routing
- 패킷이 어느쪽으로 가야 하는지 경로를 결정한다.
- forwading tble을 만들기 위한 방법이다.
-> 모든 라우터는 포워딩테이블이 있어야 한다.
-> 테이블에는 목적지와 아웃풋 포트가 적혀 있다.
-> 포워딩 테이블을 보고 데이터를 아웃풋 포트로 보내준다.
Routing Protocols taxonomy
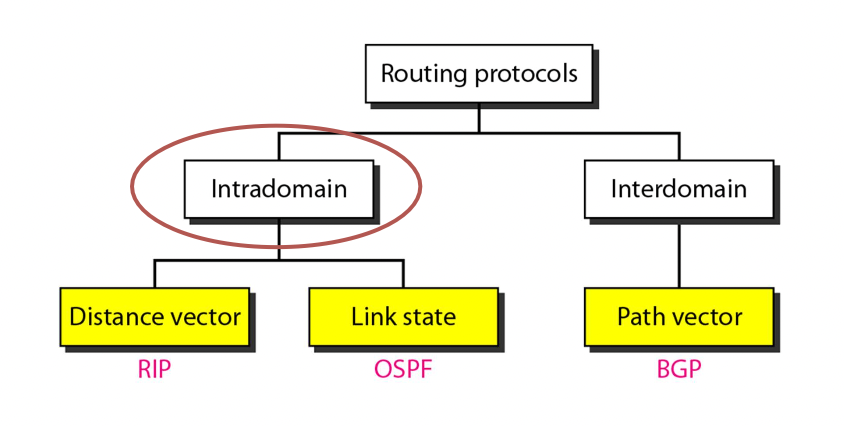
-> 인터넷에서 사용하는 가장 대표적인 세가지
- Intradomain(도메인 내부) : 시스템 내부 라우터 끼리 연결
- Interdomain(도메인 간(도메인 사이)) : 시스템 끼리의 연결
- 프로토콜 이름 : 라우팅 알고리즘 이름
-> RIP : distance vector
-> OSPF : Link state
-> BGP : Path vector
Autonoous System(AS)
- 공통된 라우팅 policy를 갖는 네트워크 집합
-> 한 autonomous systes에서는 공통된 라우팅 policy를 사용(라우팅 알고리즘, 경로 선택에 있어서의 방식 등을 포함한 정책들) - ISP, 기관 등에서 운영됨
- 각 as는 고유의 as number를 가지고 있음
intra vs inter-domain Routing
- Intra domain 라우팅
-> 같은 as 내의 호스트, 라우터 끼리의 라우팅
-> 하나의 as에 있는 모든 라우터들은 같은 intra domain의 라우팅 프로토콜을 사용함
-> 다른 as에 있으면 프로토콜이 달라질 수 있음
-> 다른 as의 라우터와 연결된 라우터 : gateway router - Inter 도메인 라우팅
-> 도메인 사이의 어떤 경로를 택해야 하는지
-> 게이트웨이 라우터들이 inter 도메인 라우팅 프로토콜을 돌리는거(as에 속해있기 때문에 intra도 돌려야함)
Routing Algorithms ans Protocols
1. Distance vector routing
- 목적지로 가기 위한 다음 노드를 기록한다.
-> 목적지가 f이면 f로 가기 위해 다음으로 b로 가라는 내용 담김 + 거리값(distance, cost등) 담김
-> 라우팅 테이블(컨트롤 플레인에 있음, 이거를 근거로 포워딩 테이블 만듬)에는 목적지, 거리, 다음 노드 저장되어 있음 - 이웃들(직접 연결된 라우터)과 테이블을 교환해서 자기 테이블을 업데이트 한다.
-> 모든 라우터들에 대해 동작하며 모든 업데이트가 일어나서 더이상 변화가 없으면 종료
동작 방식
각각의 링크에 있는 코스트들을 고려해서 minimum 코스트를 구하는 것이 목적
예시
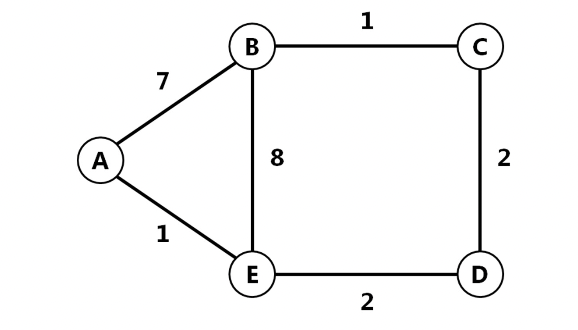
1. 우선 직접 연결된 노드 까지의 거리를 알아야 한다.
2. 각 노드들에 대해 초기상태를 구한다.
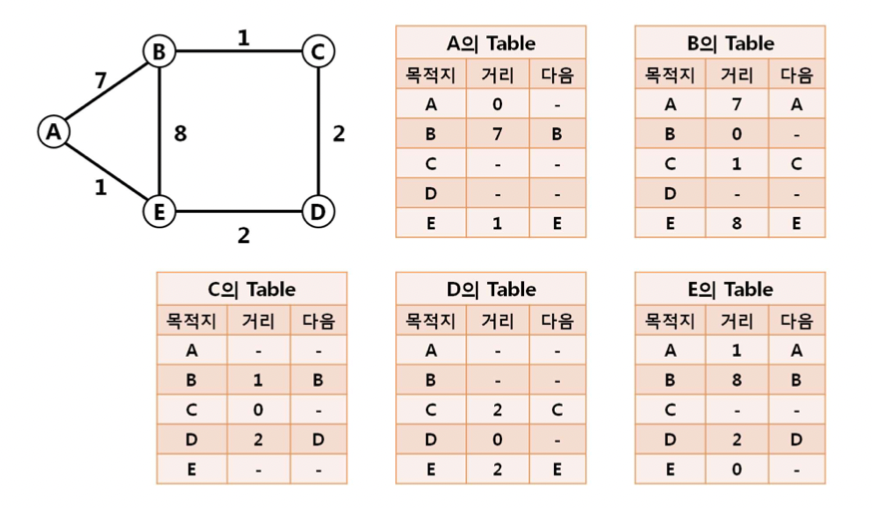
3. 이웃한 노드들과 테이블을 교환한다.
-> 노드끼리 독립적으로 하는 것이어서 누가 먼저하는지는 상관 없다.
-> 교환을 통해 테이블을 받은 노드는 거리를 업데이트 한다.
-> 새로운 루트와 가지고 있는 루트를 비교하여 새로운 루트가 더 짧으면 업데이트 한다.
-> 예를들어 D에서 E로 테이블을 보내는 상황이라면
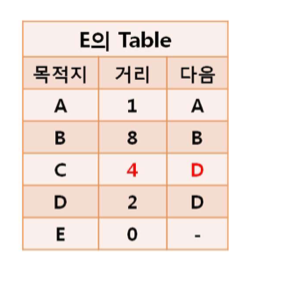
-> E에서 C로 가는 길 없었는데, D에서 C로 가는 경로 있으니까
E->D + D->C
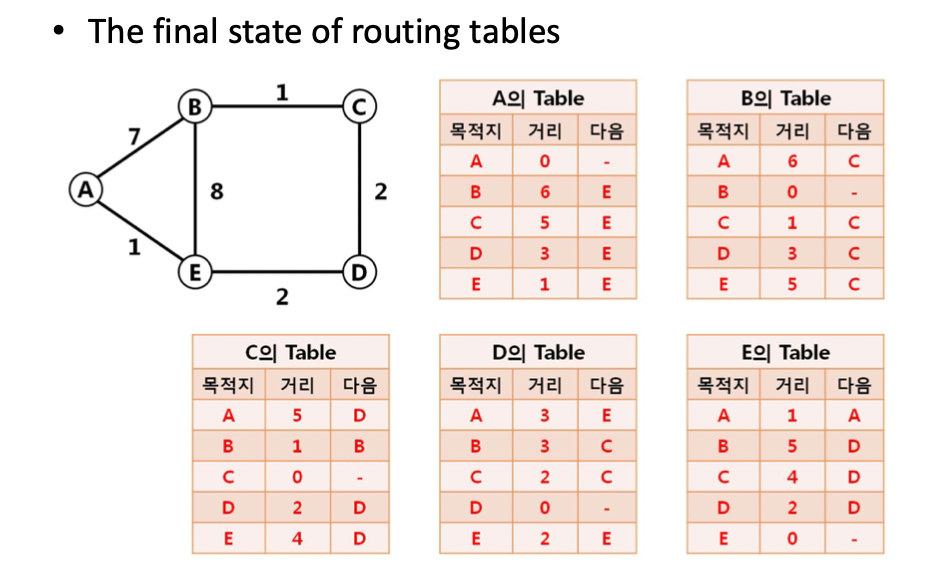
- 3번 과정을 계속 반복한다.
-> 주기적으로 라우팅 테이블을 이웃에게 보낸다.
-> 만약 내 테이블이 업데이트 되었으면 이웃에게 테이블을 보낸다.
-> 업데이트가 완료되어서 변화가 없다면 모든 노드들이 모든 목적지들에 대해 최단 경로로 갈 수 있는 길을 계산 완료한 것이다.
네트워크의 변화가 일어났을 때
경로가 사라졌을 때
1. 경로 포함하는 노드가 알아챔(사라진 경로의 양끝 노드)
2. 그 노드들이 인접 노드들에 내용 전달
3. 반복
4. 새로운 네트워크의 형태 대로 최적의 경로들이 저장됨
원래 새로운 경로랑 갖고 잇는 경로랑 비교해서 더 짧은걸 택하는데, 만약 네트워크가 바뀐 경우라면 업데이트 된 노드로 부터 온 경로(업데이트 된 노드가 다음 노드라면)에 대해서 재평가를 해 줘야한다.(그거에 맞게 업데이트 해 줘야함)
-> 만약 그저 짧은 경로만 선택한다면 끊어지기 전 경로가 짧을 경우 업데이트가 안일어난다.
정리
- 노드들이 라우팅 테이블을 이웃한 노드들과 교환한다.
- 네트워크에 변화가 있으면 계속 교환하다보면 변화에 적응하여 최적의 경로를 결정하게 됨
- 네트워크의 변화를 어떻게 알 수 있느냐?
-> 타이머를 두고 일정 시간동안 해당 노드로 부터 테이블이 안오면 경로가 끊어졌나 보구나 하고 해당 엔트리를 날려버림
1.1 count-to-infinity problem
-> Distance vector의 문제점
-> 네트워크에 변화가 생겼을 때 모든 테이블을 네트워크게 맞게 업데이트 하는데 오래 걸릴 수 있음
예시
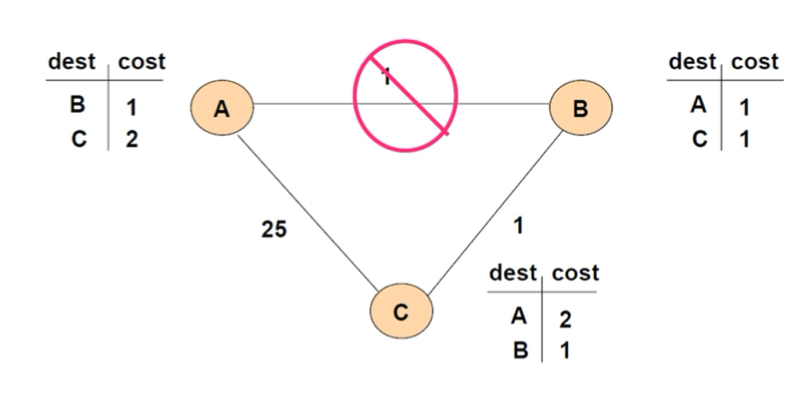
-> A-B가 끊어진 경우, 타이밍이나 운이 나쁘게 C에서 B로 테이블을 전달
-> B 입장에서는 현재 A까지 거리 invalid 니까 C의 테이블 보고 업데이트함(A에 대한 next는 C로 업데이트)
-> B에서 C로 테이블 전달
-> 그럼 C는 B에서 준 테이블 보고 다시 업데이트함(A에 대한 next가 B이기 때문)
-> B와 C 왔다갔다 하며 C-A가 25보다 커질때 까지 반복
-> 25보다 커지면 next를 A로 업데이트함
-> 그때 되서야 B에서도 업데이트함
-> 결국 업데이트 되긴 하는데, 그때까지 계속 왔다갔다 하니까 시간, 오버헤드가 많음
-> 경로가 변경되거나 없어지면 결국 있는 길로 바꾸긴 하는데, 이렇게 되기까지 시간이 많이 걸림 + 교환 되는 정보 역시 많아짐
-> 네트워크 자원의 낭비
문제가 왜 발생하는가?
-> C가 B로 자신의 라우팅 테이블을 보내는데, B는 C가 알려주는 정보가 어디를 거쳐서 가는지 모르니까 그저 받아들일 수 밖에 없다.
-> 그니까 테이블 상 C가 A로 갈 때 B를 통한다는 사실을 B는 모른다.
-> 더 근본적인 문제 : 다음의 다음을 모름
즉, 각 라우터들이 어떤 목적지까지 가는 길에 대해 다음 라우터가 뭔지는 알지만 그 다음을 모르니까, 그 사이에 자기자신으로 돌아오는것이 생긴다면(라우팅 루프 발생) 문제가 된다.
-> 오래 걸리더라도 결국 루트 찾아내긴 한다.
문제 해결 법
- split horizon
- split horizon with poison reverse
- path vector routing
split horizon
라우터 C가 자기의 라우팅 테이블을 B로 전달할 때, 자기 테이블의 엔트리 중 B를 거쳐 가는 라우트들은 B쪽으로 전달하지 않는다.
-> B에서 C에서 보낸 엔트리를 사용하면 B로 갔다가 다시 C로 오게 되니까(루프 방지)
-> 즉, 라우팅 정보가 들어온 곳으로 향하는 엔트리에 대한 정보를 보내지 않는거
split horizon with poison reverse
C가 B쪽으로 테이블을 보낼 때 B를 거쳐서 가는 라우터들을 B쪽으로 알려는 주는데, 거리를 infinity로 해서 알려준다.
-> split horizon에 비해 좋은점은 C를 거쳐가는 라우트가 있다면 빨리 없애줌
-> split horizon은 해당 라우트를 안보내니까 상태가 유지가 될 수 있는데, poison 방법은 유지되는것 마저 없애줌
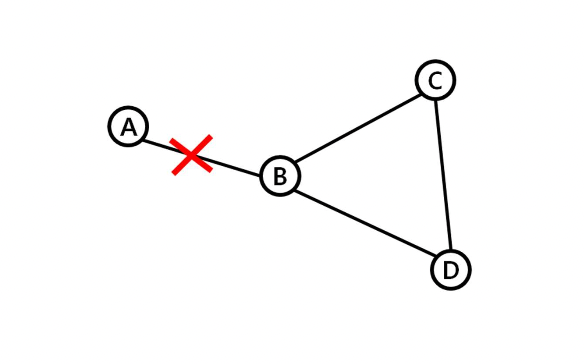
-> 이런 경우 C에서 A로 가는 방법이 B를 통해 가는 것이 아니라 D를 통해 가는 경우 위의 두가지 방법으로는 count-to-infinity problem을 해결하지 못한다.
-> 두 방법 모두 근본적으로 count to infinity 문제를 해결하는 방법은 아님
path vector routing
-> 근본적인 count to infinity 해결법
-> 중간 루트를 모르는게 근본적 문제이기 때문에 다음 노드 대신 경로 전체 저장
-> 전체 경로를 가지고 있기 때문에 중간에 루프가 생기면 바로 알 수 있음
-> 경로를 다 저장해야 해서 양이 많아짐
-> 라우팅 테이블 교환 할 때도 패스 전체를 교환하니까 교환하는 양도 많아짐
-> BGP(Border Gateway Protocol)에서 사용하는 방법임
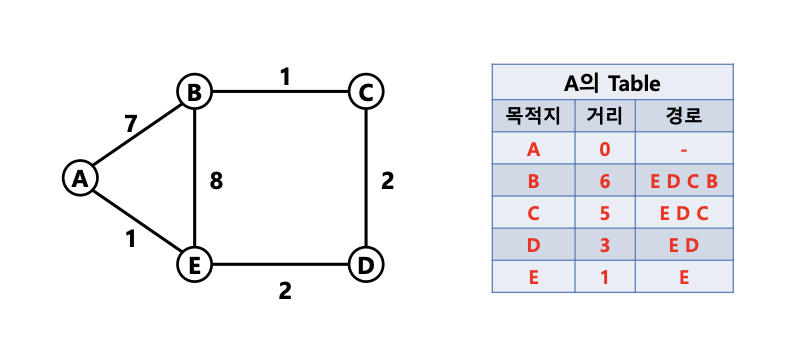
1.2 RIP(Routing Information Protocol)
- distance vertor를 이용한 라우팅 프로토콜
- route advertisement(라우팅 테이블)을 30초마다 기본적으로 전달, 라우팅 테이블이 업데이트 될 때도 전달함
2. Link-state routing
- 망에 있는 모든 노드들에게 나의 링크 상태를 전달한다.
-> 나와 이웃까지의 정보를 모든 노드들에게 전달
-> Link state packet(LSP) - Link state packet
-> sender의 ID
-> sender의 이웃에 대한 (목적지, 거리)
-> sequence number를 통해 어떤게 최신 정보인지 알려줌
-> 전체 망에대한 정보를 알게 되면 다익스트라 알고리즘을 통해 최단 거리를 구할 수 있음 - Link-state packet forwarding
-> 각 노드가 다익스트라 알고리즘을 이용해 shortest path를 계산하고 next hop을 결정함
-> 각 노드가 링크 스테이트 정보를 다른 모든 노드들에게 전달함(distance는 이웃에게만 보냄)
-> flooding(또는 broadcasting)
2.1 Flooding
받은 쪽에서는 시퀀스 넘버를 보고 최신 정보인지 봐서 최신 정보라면 라우팅 테이블을 업데이트 하고 이웃들에게 정보를 포워딩 해줌, 최신 정보가 아니면 그냥 버리면 됨
-> 똑같은 lsp를 여러개 받을 수도 있음
2.3 OSPF
- open shortest path first
- link state 라우팅 알고리즘을 사용하는 프로토콜
- LSA(link state advertisement) 패킷이라는 컨트롤 패킷을 주기적으로, 업데이트가 일어났을 때 모든 노드들에게 보내줌
Link state vs Distance vector
- 링크 스테이트
-> 교환되는 정보 : 자기의 링크 정보(이웃의 ID, 이웃까지의 distance)
-> 교환되는 범위 : 모든 네트워크의 노드들에게 전달
-> 프로토콜 : ospf - 디스턴트 벡터
-> 교환되는 정보 : 이웃 뿐만 아니라 이웃이 아닌 모든 목적지에 대한 정보(목적지, 목적지까지의 distance)
-> 교환되는 범위 : 이웃에게만 전달
-> 프로토콜 : rip
출처 및 참고
Computer Networking A Top-Down Approach 7-th Edition / Kurose, Ross / Pearson
서강대학교 기초컴퓨터네트워크 강의자료 (소정민 교수님)
