NPU(Neural Processing Unit)란 무엇인가
- 이름부터 AI 최적화이다. Neural Net
– CPU에서 출발해 NPU까지, 사고방식의 전환으로 이해하는 AI 반도체
1. 왜 지금 NPU인가
AI 모델은 더 이상 연구실에만 머무르지 않는다.
모바일, 엣지 디바이스, 데이터센터 전반에서 실시간 추론이 요구되고 있다.
이 변화는 자연스럽게 질문으로 이어진다.
CPU와 GPU로 충분하지 않은가?
왜 NPU라는 새로운 프로세서가 필요한가?
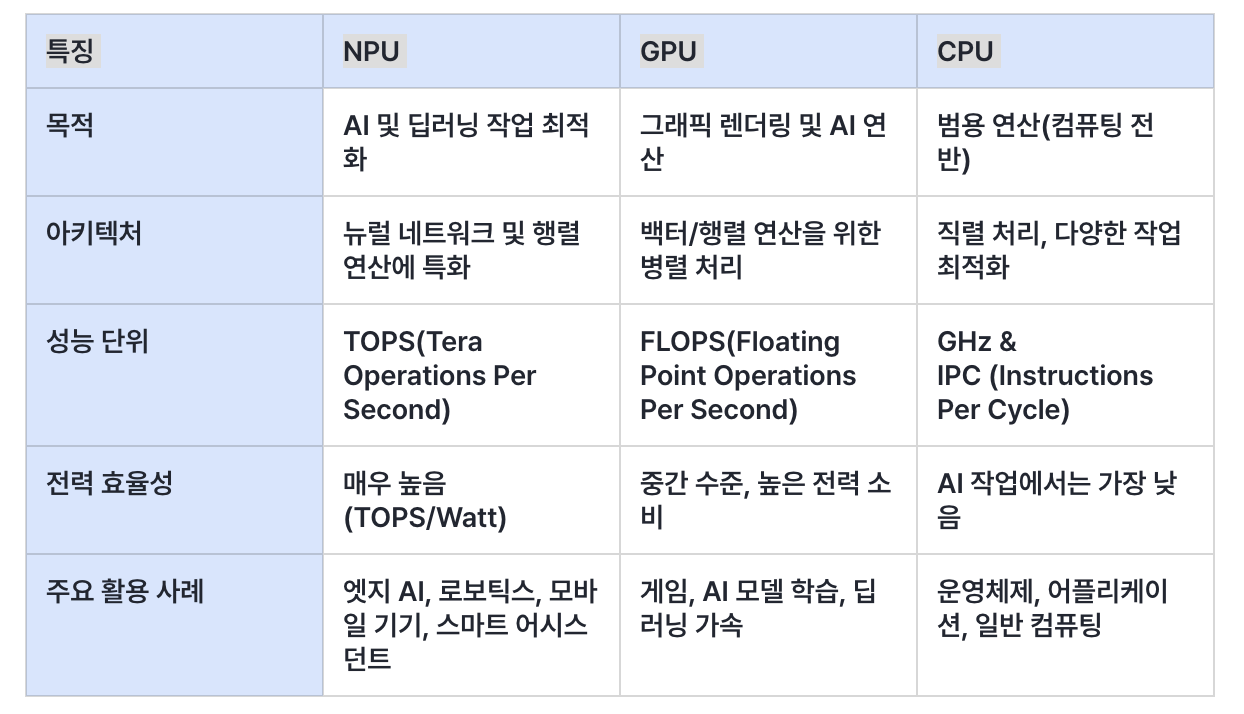
NPU는 AI 모델을 효율적으로 실행하도록 설계되었습니다. GPU에 비해 전력 소모가 훨씬 적고, CPU보다 AI 작업에 특화되어 있어 독립적인 AI 솔루션에 대한 수요를 충족할 수 있습니다.
즉, 인터넷이나 클라우드에 의존하지 않고도 AI 모델을 실행할 수 있습니다. 이러한 이유로 스마트폰, 노트북 등 모바일 기기에 NPU가 탑재되기 시작했습니다.
특정 연산 AI 연산에 특화되어 있어 더 빠르고 효율적인 처리가 가능
출처 : 모빌린트 테크 블로그
NPU는 셀 수없이 많은 신경세포와 시냅스로 연결되어 신호를 주고받으며 동시에 작업을 진행하는 인간의 뇌 신경세포와 유사한 작업을 진행합니다. 스스로 학습하고 판단할 수 있는 인공지능 (AI) 등이 접목되어 일명 AI 칩이라고 불리기도 하죠.
출처 : 삼성 테크 블로그
NPU에는 곱셈과 덧셈, 활성화 기능, 2D 데이터 연산 및 압축 해제를 위한 특정 모듈이 포함되어 있습니다. 특수 곱셈 및 덧셈 모듈은 행렬 곱셈 및 덧셈, 컨볼루션, 도트 곱셈 및 기타 기능 계산과 같은 신경망 애플리케이션 처리와 관련된 연산을 수행하는 데 사용됩니다.
기존 프로세서는 이러한 유형의 뉴런 처리를 완료하는 데 수천 개의 명령어가 필요하지만, NPU는 단 하나의 명령어로 유사한 연산을 완료할 수 있습니다. 또한 NPU는 네트워크 노드에 할당된 유동적인 계산 변수인 시냅스 가중치를 통해 스토리지와 계산을 통합하여 시간이 지남에 따라 조정되거나 '학습'될 수 있는 '올바른' 또는 '원하는' 결과의 확률을 나타내므로 운영 효율성이 향상됩니다.
신경 처리 장치(NPU)는 기존의 CPU와 GPU를 대체하도록 설계되지도 않았고, 대체할 것으로 예상되지도 않습니다.
출처 : IBM 블로그
이 질문에 답하려면, 연산 대상과 실행 방식의 변화를 먼저 이해해야 함.
2. CPU → GPU → NPU 사고 전환 가이드
2.1 CPU: 제어 흐름 중심 사고
CPU는 본질적으로 범용 계산기다.
- 명령어 기반 실행
- 분기와 예외 처리
- 제어 흐름(Control Flow)이 핵심
- 캐시와 분기 예측이 성능의 중심
CPU 관점의 사고는 다음 질문으로 요약된다.
다음에 어떤 명령을 실행해야 하는가?
이 사고는 운영체제, 컴파일러, 범용 애플리케이션에는 최적이지만
대규모 동일 연산 반복에는 비효율적이다.
2.2 GPU: 병렬화 사고
GPU는 CPU의 한계를 병렬성으로 돌파한다.
- 수천 개의 스레드
- 동일 명령을 다른 데이터에 적용 (SIMT)
- 대규모 벡터/행렬 연산에 강점
GPU 관점의 사고는 이렇게 바뀐다.
이 연산을 얼마나 많이, 동시에 수행할 수 있는가?
GPU는 딥러닝 학습과 추론을 가능하게 만들었지만,
여전히 한계가 있다.
- 높은 전력 소모
- 범용성 유지로 인한 구조적 오버헤드
- 엣지 환경에 부적합
2.3 NPU: 데이터 흐름 사고
NPU는 사고 방식이 완전히 다르다.
- 연산은 거의 항상 Tensor
- 연산 그래프는 대부분 정적
- 분기 없음
- 데이터 재사용이 극대화됨
NPU의 핵심 질문은 이것이다.
데이터는 어떤 경로로 흘러야 가장 효율적인가?
즉, Control Flow → Parallelism → Data Flow로의 사고 전환이다.
3. NPU 기술 구조 상세 분석 (컴퓨터 구조 관점)
3.1 전체 구조 요약
일반적인 NPU 아키텍처는 다음 흐름을 따른다.
Host CPU
→ Command Processor
→ DMA / Memory Controller
→ On-chip SRAM (Scratchpad)
→ Compute Array (MAC)
→ Activation / Post-processingCPU와 달리 Instruction Pipeline보다 Data Pipeline이 중심이다.
3.2 Control Logic의 최소화
CPU:
- 복잡한 명령어 디코딩
- 분기 예측
- 인터럽트 처리
NPU:
- 단순한 명령 집합
- 레이어 단위 실행
- FSM 수준 제어
이유는 명확하다.
- AI 추론 그래프는 실행 순서가 고정되어 있기 때문이다.
3.3 Cache 없는 메모리 구조
CPU:
- Cache Hierarchy (L1/L2/L3)
- 하드웨어가 메모리 관리
NPU:
- Cache 거의 없음
- Scratchpad SRAM 사용
- DMA 기반 명시적 데이터 이동
- 컴파일러가 메모리 배치 결정
NPU에서 메모리는 “자동 최적화 대상”이 아니라
컴파일 타임에 계획되는 자원이다.
3.4 Compute Array와 Systolic 구조
NPU의 핵심은 MAC Unit의 집합이다.
- Multiply-Accumulate 중심
- 행렬 곱과 합성곱에 최적화
- Systolic Array 구조 채택
Systolic 구조의 핵심은:
- 데이터 이동과 연산이 동시에 발생
- 동일 데이터의 재사용 극대화
- 메모리 접근 최소화
3.5 정밀도 설계
CPU/GPU:
- FP32, FP64 중심
NPU:
- INT8, INT4, FP16, BF16, FP8
정밀도를 낮추는 이유:
- AI 추론은 정확도 여유가 큼
- 정밀도 감소 → 연산 밀도 증가 → 전력 감소
4. NPU에서 Attention 연산이 어려운 이유
Attention은 NPU가 가장 어려워하는 연산 중 하나다.
4.1 Attention 연산의 특성
Self-Attention은 다음을 포함한다.
- QKᵀ 연산
- Softmax (지수, 정규화)
- 긴 시퀀스 의존성
- 동적 메모리 접근
4.2 NPU와의 구조적 충돌
NPU에 불리한 이유:
- Softmax는 MAC 중심 구조에 비효율적
- 시퀀스 길이에 따라 연산 패턴 변화
- 데이터 재사용률 낮음
- 온칩 SRAM 초과 가능성
즉, Attention은
- 정적 그래프
- 높은 데이터 재사용
- 규칙적인 연산
이라는 NPU의 전제를 깨뜨린다.
5. LLM 추론에서 NPU가 불리한 지점
5.1 메모리 병목
LLM은:
- 파라미터 수가 매우 큼
- Weight를 지속적으로 DRAM에서 로드
NPU의 제한:
- 온칩 메모리 작음
- 외부 메모리 대역폭이 병목
5.2 Autoregressive 특성
LLM 추론은:
- 토큰 단위 순차 실행
- 병렬성 제한
이는 NPU의 강점인:
- 대량 병렬
- 정적 실행
과 상충된다.
5.3 정밀도와 정확도 균형
- INT8/INT4 양자화는 쉽지 않음
- LLM은 미세한 수치 오차에 민감
결과적으로:
- GPU는 FP16/BF16으로 안정적
- NPU는 추가적인 최적화 비용 필요
6. 국내 NPU 사례 분석
6.1 FuriosaAI
- 데이터센터용 NPU 설계
- 대규모 MAC Array 기반
- 컴파일러 중심 구조
- CNN + Transformer 추론에 초점
특징:
- GPU 대체보다는 추론 특화 가속기
- 소프트웨어 스택에 큰 비중
6.2 Rebellions
- 서버급 AI 가속기 지향
- 전력 대비 성능 최적화
- 클라우드/엔터프라이즈 추론 타겟
특징:
- GPU 보완재 포지션
- 실제 서비스 워크로드 중심 설계
6.3 공통점
두 회사 모두:
- “학습용 GPU 대체”가 목표가 아님
- 추론 특화
- 컴파일러와 런타임 최적화가 핵심 경쟁력
7. 정리: NPU를 이해하는 핵심 관점
NPU는 CPU나 GPU의 상위 호환이 아니다.
- 더 범용적이지 않다
- 더 유연하지도 않다
대신:
- 더 빠르다 (특정 연산에서)
- 더 효율적이다
- 더 목적 지향적이다
한 문장 요약
CPU는 명령을 실행하고, GPU는 연산을 병렬화하며,
NPU는 데이터가 흐르도록 설계된 프로세서다.
