트라이 노드를 정의한다.

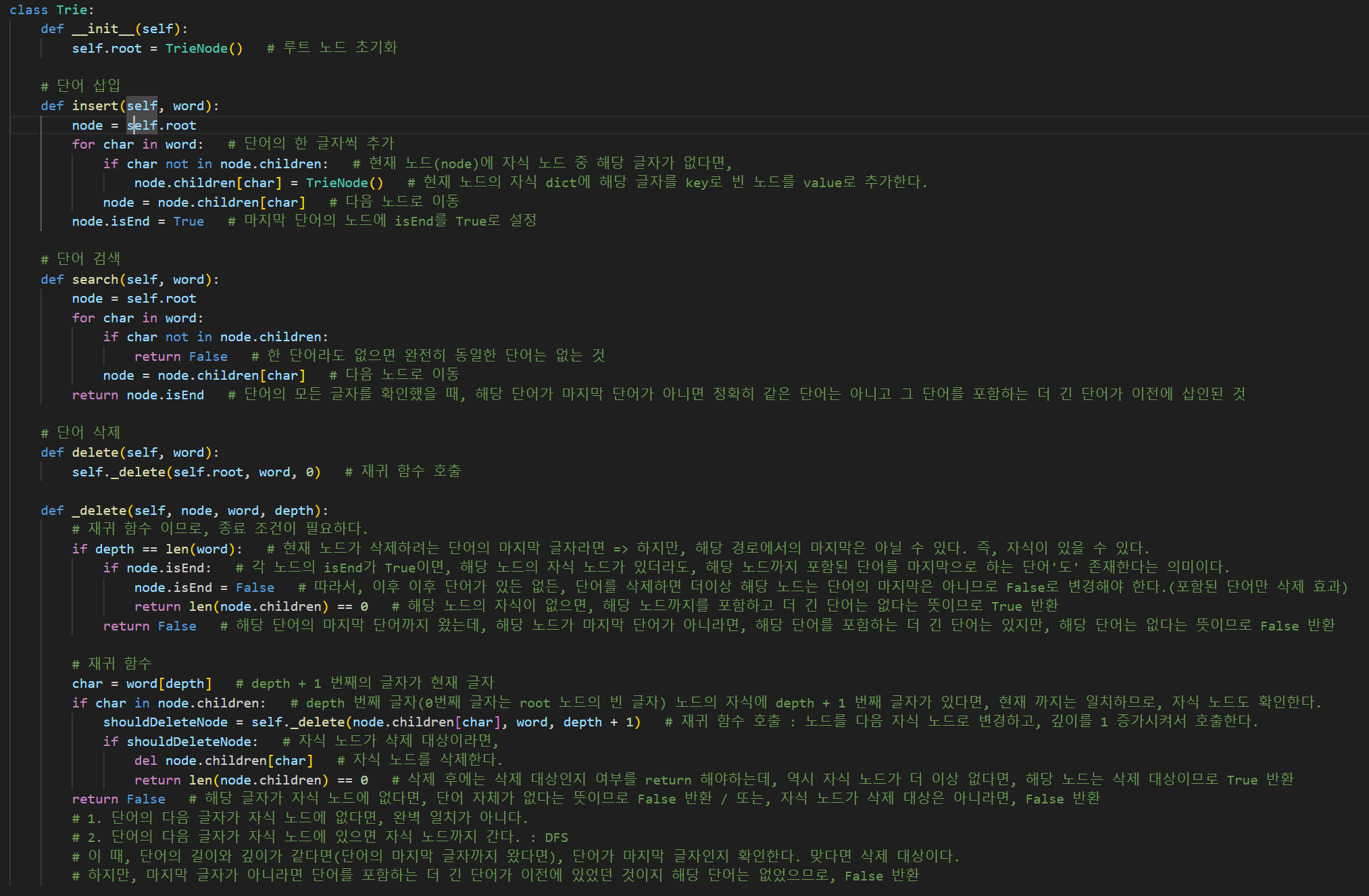
이후 트라이 자료구조를 정의한다.
그리고 삽입, 검색, 삭제 함수를 만든다.
삽입 함수는 해당 단어의 모든 글자를 확인하며, 글자의 자식 노드에 다음 글자가 없다면, 빈 노드를 만든다.
그리고 이제는 자식 노드는 무조건 있으므로, 자식 노드로 노드를 옮긴다.
그렇게 해당 단어의 모든 글자에 대해 각 글자를 가리키는 노드를 연결했으면, node 변수는 이제 마지막 단어를 가리키고 이는 마지막 단어이므로, 해당 노드의 isEnd 속성을 True로 바꿔준다.
검색 함수는 삽입 함수와 똑같이 작업을 하는데, 한 단어라도 순서가 같지 않으면 False를 return하고 모든 순서가 같다면, 마지막 노드가 단어의 마지막인지(해당 노드가 마지막이라면, 순서와 마지막이 같은 단어이므로 일치하는 단어이다.) 확인하여 True라면 True를 return한다. (즉, 노드가 단어의 마지막인지와 그 단어가 있는지는 bool 값이 같다.)
삭제 함수는 재귀 함수를 호출하는 방식이고, 재귀 함수는 모든 글자에 대해서 해당 노드가 삭제 대상 노드인지 return한다. (대상이면 삭제하는 함수.)
root 노드와 depth 0 을 시작으로 현재 노드의 자식 노드와 깊이 + 1 번째 글자를 비교해나간다.
마지막 글자부터 확인해서 삭제해야하는 구조이므로, 마지막 단어까지 DFS 방식으로 재귀함수가 호출된다.
이 때, 단어의 길이와 깊이가 같으면 단어를 구성하는 모든 글자가 순서대로 있었다는 뜻이다. 그러나 해당 단어를 포함하는 더 긴 단어가 있을수도 있기 때문에 해당 글자가 단어의 마지막이었는지를 확인해야한다.(즉, 정확하게 일치하는 단어가 삽입된 적이 있는지)
만약 맞다면 단어가 있었던 것은 맞다. 하지만, 삭제 대상인 지는 더 확인해봐야한다.
왜냐하면, 자식이 있을 수 있기 때문이다. 만약 자식이 있다면, 해당 단어를 포함하는 더 긴 단어가 있었다는 뜻이기 때문에 삭제는 할 수 없고, isEnd 속성만 False로 바꿔줘야한다.(완벽히 일치하는 단어만 삭제하는 효과)
그리고 자식 노드가 삭제 대상(그 자식 노드의 자식은 더 이상 없다는 뜻)이라면 자식 노드를 삭제한다. 그리고 현재 노드에게 다른 자식 노드가 있다면 현재 노드를 지울 수는 없다. 그리고 그렇다는건 이후 삭제 작업을 할 필요는 없다.
그렇지만 현재 노드에게 자식 노드가 없다면 현재 노드도 삭제 대상으로 바꿔줘야한다.
(이 코드가 돌았다는 건 삭제 대상인지 확인해서 지우겠다는 것이므로 다른 자식 노드가 없다면 현재 노드도 여전히 삭제 대상이기 때문)
프로그래머스 : 가사 검색(lv4)
-
트라이 구성 노드

value와 isEnd는 사용하진 않지만, 만들어놨다. -
트라이 구조
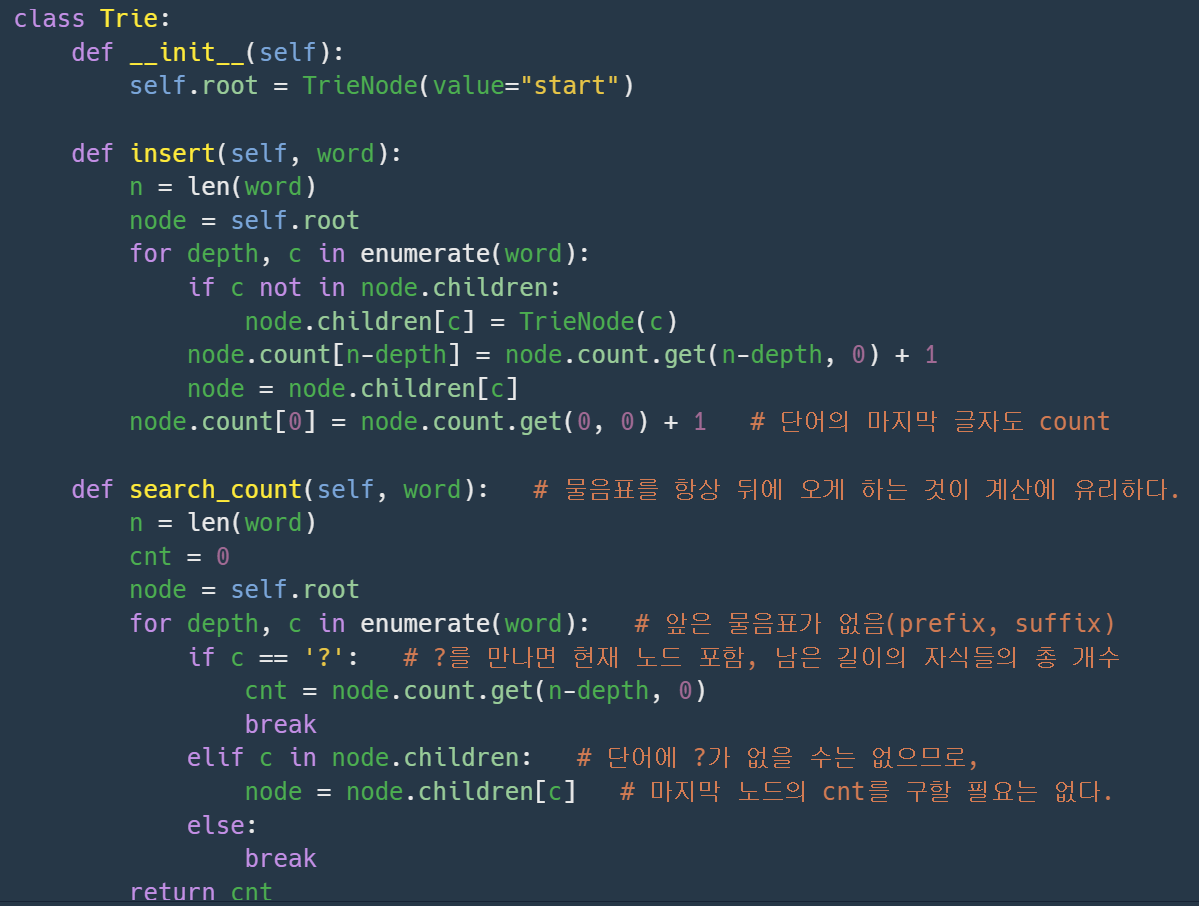
이 때 ?를 뒤로 보내기 때문에, 각 노드 기준으로 해당 노드 뒤에 남은 단어 길이에 대응되는 단어가 몇 개 있는지를 저장해놓고 이를 이용하는 방식을 사용
이 때, 모든 노드는 단어의 길이 - 현재 깊이 기준에 해당 단어들의 개수를 저장
즉, 루트 노드는 count 속성에 단어의 길이 n을 key로 하는 value(개수)를,
마지막 노드는 count 속성에 n - depth(n) = 0을 key로 하는 value(개수)를 1개 가지고 있는 것.(마지막 단어 기준 남은 길이 0에 해당되는 단어는 본인 뿐)
노드와 관련해서 작동 원리와 순서를 정확히 이해하는 것이 매우 중요하다.
삽입 단계에서 마지막 노드의 count도 계산하는 작업을 추가해야한다.
?는 반드시 있고, 남은 길이에 대응되는 단어의 개수가 없을 수도 있으므로, 이 경우를 고려하여 node.count.get(n-depth, 0)을 해주는 것도 빼먹으면 안된다.
- 최종 코드

정방향 단어집 트라이와 역방향 단어 트라이를 같이 관리해서, ?가 언제나 뒤에 오게해서 검색하는 방식이 핵심이다.
이진 탐색 풀이도 있고, 이진 탐색 풀이가 더 빠르다. (이진 탐색 페이지에 기록했다.)
