
이제 본격적으로 웹크롤러를 만들어 보겠습니다.
목표물은 교보문고의 분야 종합 주간 베스트셀러 리스트 입니다.
그 중에서도 책 이름과 저자 이름 두가지 데이터를 가져와 보겠습니다.
1. 브라우저를 생성해 줍니다.
const browser = await playwright.chromium.launch({ //크롬 브라우저 선택
headless: false //이 옵션을 통해 브라우저를 통해 직접 동작하는 것을 볼 수 있습니다.
})
const page = await browser.newPage() 2. 목표 사이트로 이동합니다.
await page.goto('http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf')3. 50개씩 보기 설정
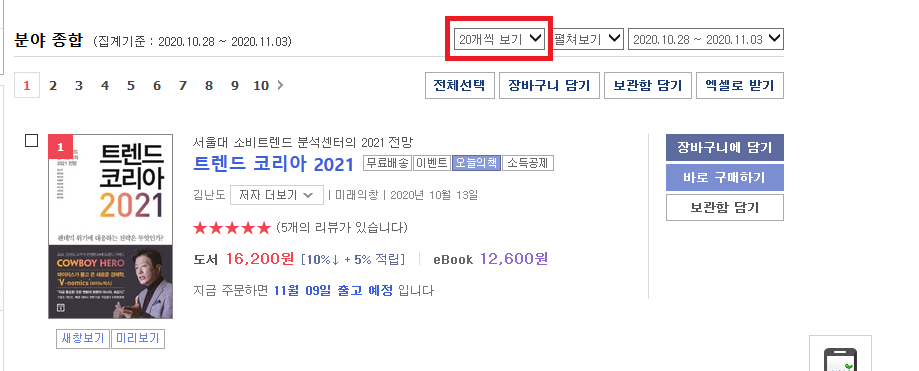
교보문고 종합 주간 베스트셀러 첫 페이지에 들어 가면 기본 20개씩 보기로 설정되어 있습니다.
저는 50위에 해당하는 데이터를 가져와야 하기 때문에 이곳을 50개씩 보기로 설정을 바꿔보겠습니다.
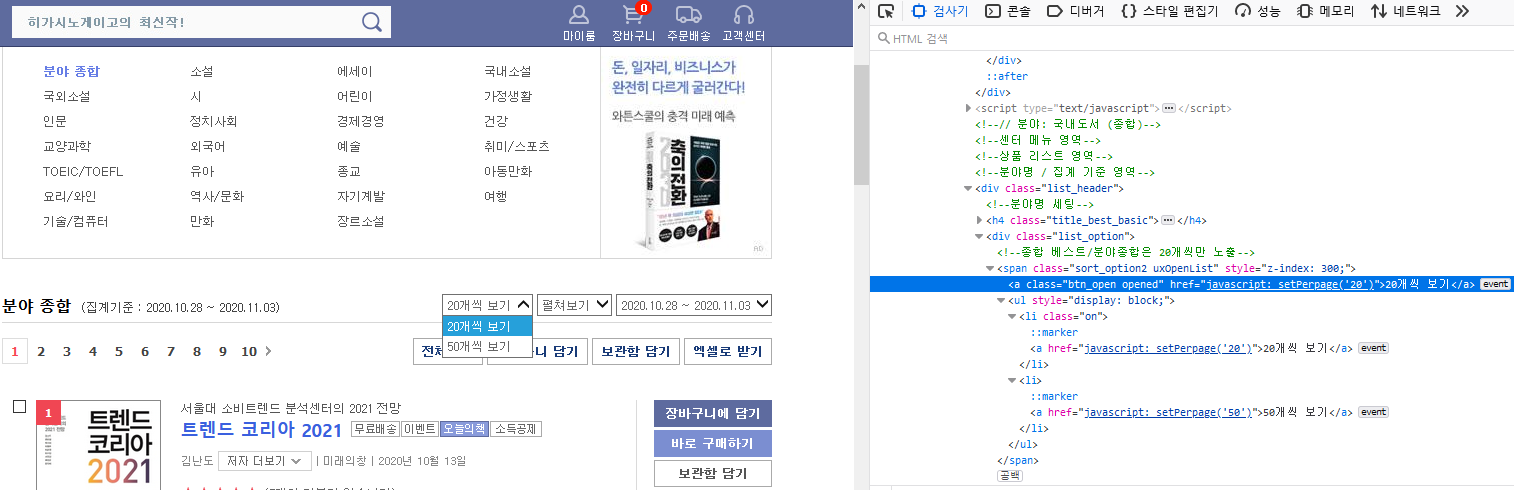
await page.click('#main_contents > div.list_header > div > span:nth-child(1) > a')
//select box 선택
await page.click('#main_contents > div.list_header > div > span:nth-child(1) > ul > li:nth-child(2) > a')
//50개씩 보기 선택page.click 기능을 통해 50개씩 보기로 바꿔줬습니다.
4. 본격적인 베스트셀러 리스트 가져오기
이제 본격적으로 베스트 셀러 리스트를 가져와 보겠습니다.
베스트셀러 DOM구조를 보면 Ul태그 밑 li태그에 베스트 셀러 정보들이 담겨져 있는 것을 볼 수 있습니다.
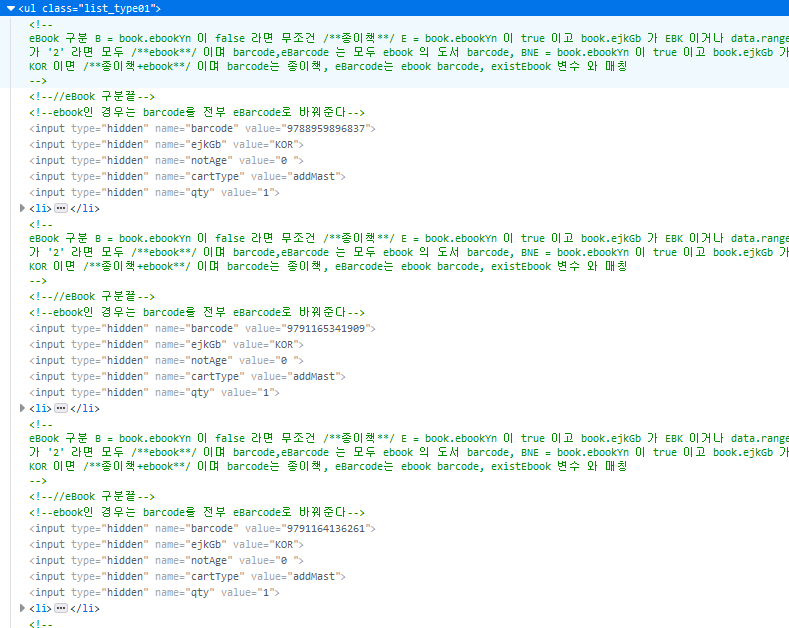
원하는 데이터가 있는 위치를 확인한 뒤 page.$$ 기능을 통해 리스트를 가져오고, 그 리스트를 $함수를 통해 1위부터 50위까지 추출하여 list배열에 담아줍니다.
const entries = await page.$$(`#main_contents > ul.list_type01 > li`) //li리스트를 가져옴
for (let entrie of entries) {//가져온 리스트를 차례대로 list배열에 담음
const obj = {}
const bookName = await entrie.$(`div.detail > div.title > a`)
const bookName1 = await bookName.innerText()
const writer = await entrie.$(`div.detail > div.author`)
const writer1 = await writer.innerText()
const writer2 = writer1.split(' ')
obj.bookName = bookName1
obj.writer = writer2[0]
list.push(obj)
}
await browser.close()
5. 결과
이제 완성된 코드를 실행시켜줍니다.
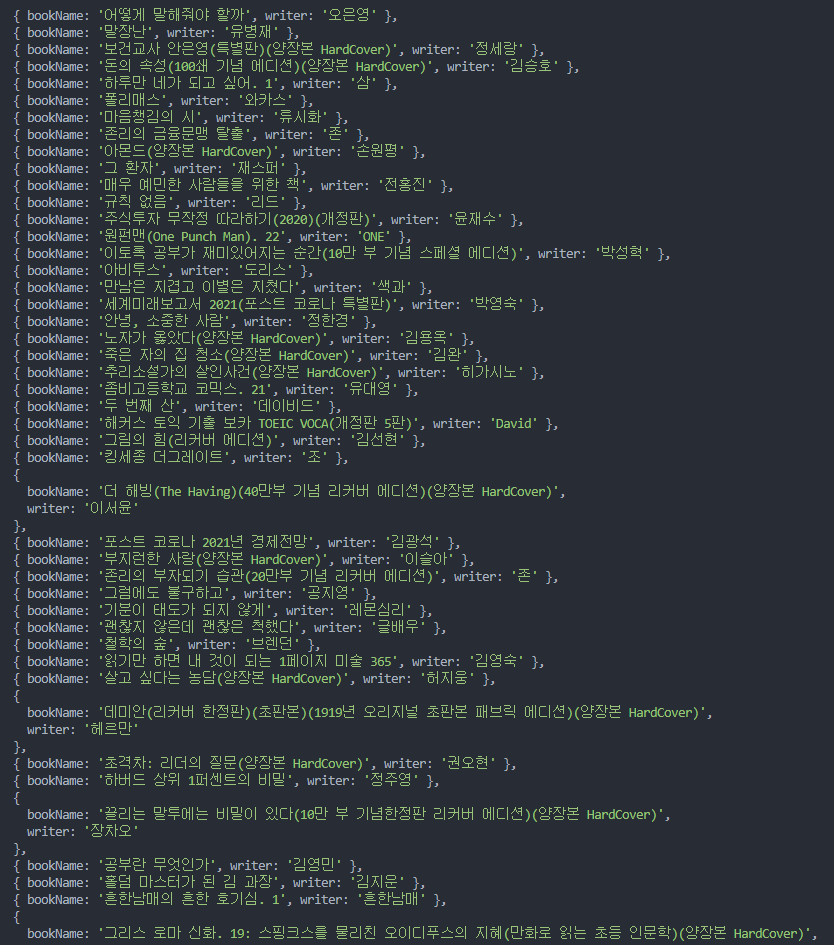
추가적으로 login이 필요한 곳이나 기타 다른 동작들을 필요로 하는 사이트에서도 충분히 활용할 수 있다는게 가장 큰 장점인 라이브러리 였습니다.
혹시 글 내용 중 잘못된 부분이 있다면 알려주시면 감사하겠습니다.(_ _)

주니어 개발자입니다!