2. The Families and Origins of SSL

SSL은 막대한 양의 데이터셋과 고용량 메모리를 갖춘 GPU 덕분에 2020년 이후로 급격한 발전을 이루었다. 그러나 그 기원은 딥러닝의 초창기로 거슬러 올라간다.
2.1 Origins of SSL
현대적인 방법론은 초기의 실험에서 얻은 지식을 기반으로 만들어졌다. 이 섹션에서 우리는 2020년 이전의 SSL에 대한 메인 아이디어에 대한 간단한 개론을 설명한다. 많은 구체적인 방법론들에도 불구하고 특정한 방법들 중 많은 것들이 더 이상 널리 사용되지 않는데, 이는 그것들이 벤치마크 문제에서 최첨단 성능을 제공하지 못하기 때문이다. 따라서 그것들은 자세히 다루지 않겠지만, 이러한 논문들의 아이디어는 현대적인 많은 방법들의 기초를 형성하고 있다. 예를 들어 입력에서 누락되거나 왜곡된 부분을 복원하거나 같은 이미지의 2개의 뷰를 대비시키는 핵심 목표가 현대 SSL 방법들의 기초를 형성한다. SSL의 초기 발전은 다음과 같은(때로는 겹치는) 범주에 속하는 방법들의 개발에 집중했다.
1. Information restoration
이미지에서 무언가를 마스킹하거나 제거한후, 누락된 정보를 복구하도록 하는 신경망을 훈련시키는 다양한 방법들이 개발되었다. Colorization 기반 SSL 방법은 이미지를 그레이 스케일로 변환후, 원본의 RGB 값을 예측하는 네트워크를 학습시킨다. 컬러화는 객체의 의미와 경계를 이해해야 하므로, object segmentation을 위한 초기 SSL 방법으로 입증되었다. information restoration의 가장 직관적인 응용은 이미지의 일부를 마스킹하거나 제거한 후, 네트워크를 훈련시켜 누락된 픽셀값을 채우는 것이다. 이 아이디어는 maksed auto-encoding 방법으로 발전하였으며, 여기서 마스킹된 영역은 transformer를 사용하여 예측할 수 있는 이미지 패치들의 결합체이다.
2. Using temporal relationships in video
이 리뷰의 초점은 이미지 처리에 맞춰져 있지만, 비디오에서 pre training을 통해 단일 이미지의 representation을 배우는 다양한 전문화된 방법들이 개발되었다. information restoration 방법들은 특히 비디오에서 유용한데, 비디오에는 마스킹할 수 있는 여러가지 정보가 포함되어 있기 때문이다. Wang과 Gupta et al.[2015]는 두개의 다른 프레임에서 동일 객체 표현간의 유사도를 가깝게 만드는 triplet loss를 사용하여 모델을 사전훈련 시켰다. 결과적으로 모델은 객체 탐지에서 좋은 성능을 보였다. Pathak et al. [2017]은 단일 프레임에서 객체의 움직임을 예측하는 모델을 훈련시키고, 그로 인해 생성된 특징을 사용하여 단일 프레임 탐지 문제를 해결했다. Agrawal et al. [2015]는 여러 프레임을 사용하여 카메라의 에고 모션을 예측합니다. Owens et al. [2016]은 비디오에서 오디오 트랙을 제거한 후, 누락된 소리를 예측하는 방법을 제안했다. 깊이 맵핑과 같은 특수 응용 프로그램을 위해, 라벨이 없는 이미지 쌍에서 단안 깊이 모델을 학습하는 자기 지도 학습 방법들이 제안되었다 [Eigen et al., 2014], 그리고 나중에는 단일 카메라 비디오에서 프레임을 사용한 방법들이 제안되었다 [Zhou et al., 2017]. 이러한 방법들은 여전히 활발한 연구 분야로 남아 있다.”
3. Learning spatial context
이 범주의 방법들은 모델이 장면 내에서 객체들의 상대적인 위치와 방향을 이해하도록 훈련시킨다. RotNet [Gidaris et al., 2018]은 임의로 회전을 적용한 후, 모델에게 회전을 예측하도록 요구한다. Doersch et al. [2015]는 이미지에서 두 개의 무작위 샘플링된 패치의 상대적 위치를 예측하는 최초의 SSL 방법 중 하나이다. 이 전략은 이미지를 여러 개의 불연속적인 패치로 분해하고 각 패치의 상대적 위치를 예측하는 "직소" 방법 [Pathak et al., 2016, Noroozi et al., 2018]으로 대체되었다. 또 다른 공간적 작업은 개수 세기 학습 [Noroozi et al., 2017]이다. 이 방법은 모델이 이미지 내 객체의 수를 자기 지도 학습 방식으로 출력하도록 훈련된다.”
RotNet
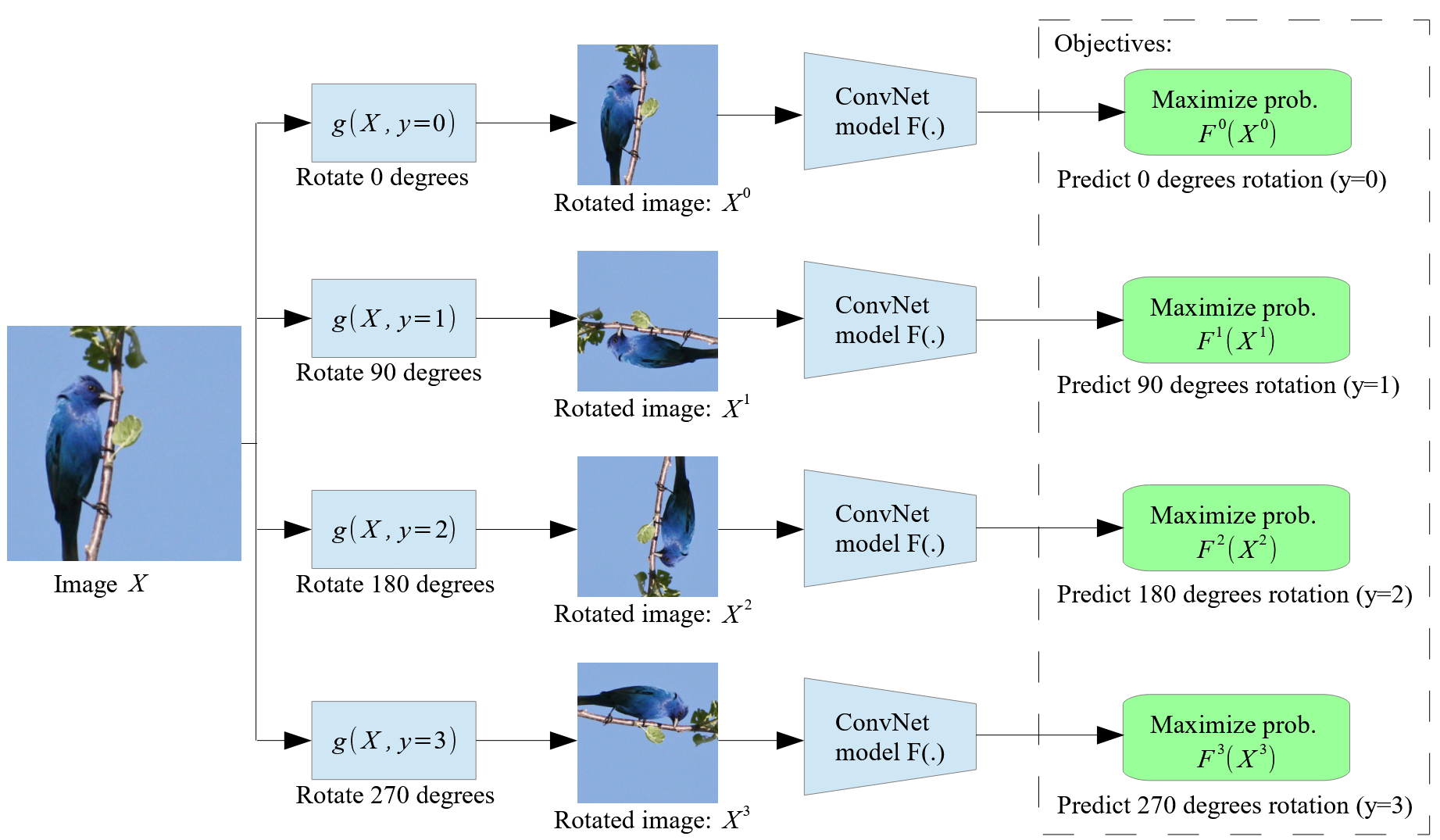
RotNet은 이미지의 회전 각도를 예측하는 모델로, 학습 과정에서 이미지의 전체적인 문맥(context)을 파악하도록 설계되었다. 구체적으로, 원본 이미지 x 에 0도, 90도, 180도, 270도 의 회전 변환을 각각 적용한 후, CNN을 이용해 해당 회전 각도를 분류하도록 학습한다.
Unsupervised Visual Representation Learning by Context Prediction
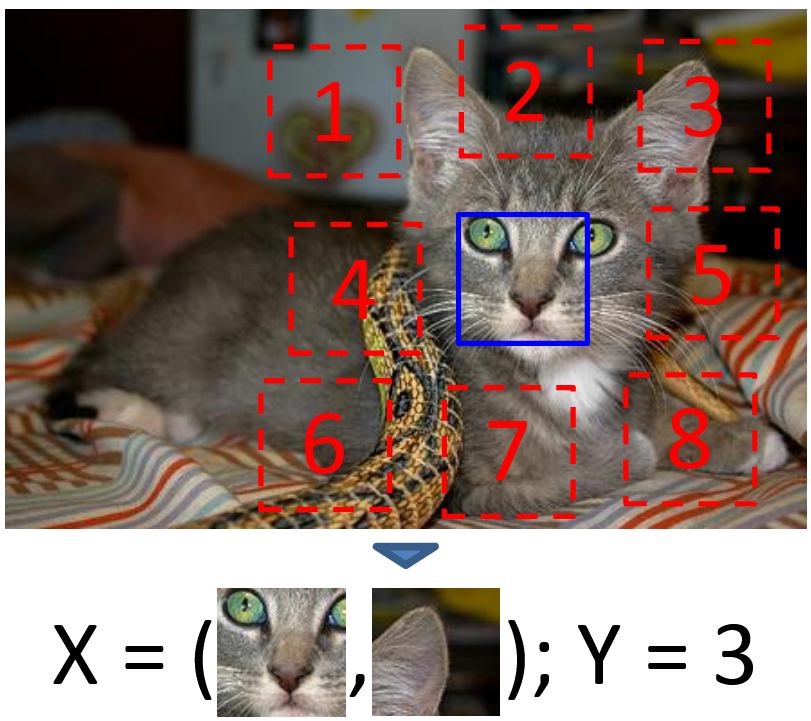
Context Prediction은 패치(Patch) 간의 상대적 위치를 예측하는 Pretext Task이다. 한 장의 이미지를 3×3 격자로 나눈 뒤, 중심 패치를 기준으로 나머지 패치의 위치를 분류하도록 학습한다. 예를 들어, 아래 그림에서 중심 패치(고양이 얼굴 중앙)를 기준으로, 오른쪽 귀가 포함된 패치가 3번 위치에 해당한다면, 네트워크가 3을 출력하도록 학습된다.
4. Grouping similar images together
의미적으로 유사한 이미지를 그룹화함으로써 풍부한 특징을 학습할 수 있다. K-means 군집화는 고전적인 기계 학습에서 가장 널리 사용되는 방법 중 하나다. 여러 연구들이 신경망 모델을 사용하여 k-means를 SSL에 적용했다. Deep clustering은 특징 공간에서 k-means를 수행하여 이미지를 레이블에 할당하고, 이 할당된 클래스 레이블을 Pseudo label로 사용하여 지도학습을 수행하는 방식으로 모델을 업데이트하는 과정을 반복한다 [Caron et al., 2018]. 이 방법의 최근 연구는 특징을 클러스터 중심으로 밀어주는 평균 이동(mean-shift) 업데이트를 사용하여 BYOL(두 네트워크를 기반으로 각 샘플에 대해 의사 레이블을 예측하는 방법)과 상호 보완적으로 작동하는 것으로 나타났다 [Koohpayegani et al., 2021] (2.3절에서 논의). Deep clustering의 다른 개선 사항으로는 특징 공간에서 최적 수송(optimal transport) 방법을 사용하여 더 유용한 클러스터를 생성하는 방법이 있다 [Asano et al., 2019].
Deep Cluster
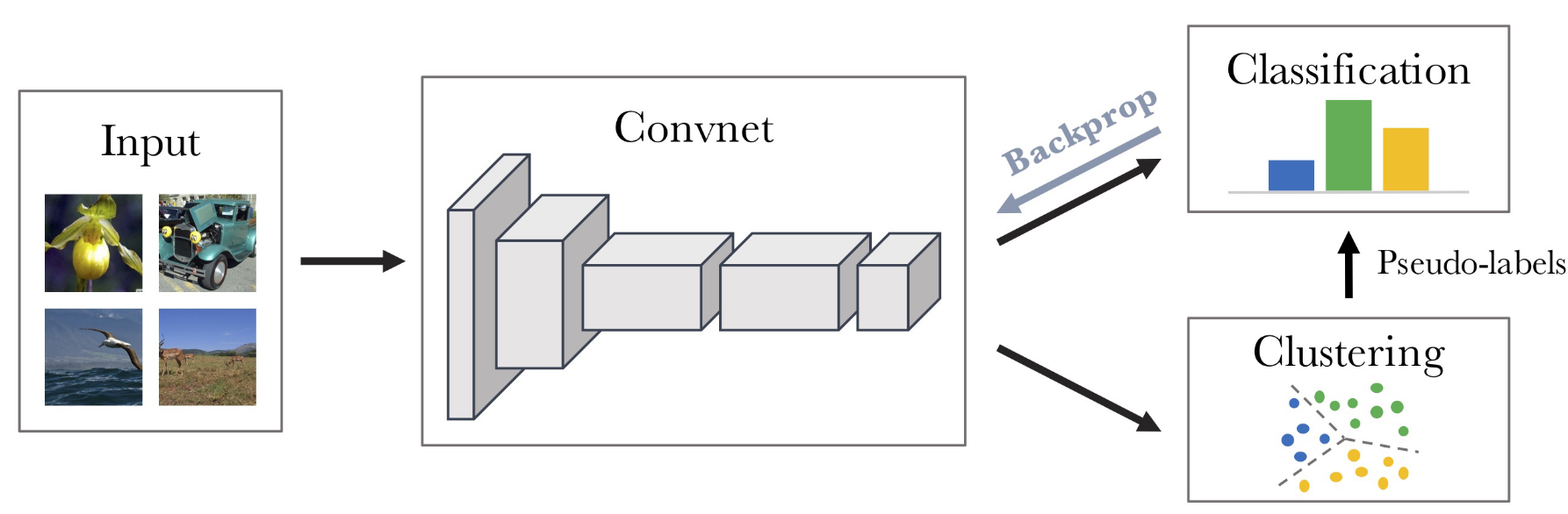
DeepCluster는 레이블 없이 대량의 이미지 데이터를 학습하기 위해 클러스터링과 딥러닝을 결합한 기법을 제안한다. CNN을 사용하여 특징(feature)을 추출한 후, 클러스터링을 수행하여 데이터를 그룹화하고, 각 클러스터를 가짜 라벨(Pseudo-label) 로 할당한다. 이후, 이 Pseudo-label을 이용해 지도학습 방식으로 CNN을 학습시킨다. 학습된 CNN을 사용해 다시 특징을 추출하고, 클러스터링을 반복 수행하며 점진적으로 더 나은 표현을 학습한다.
5. Generative models
초기의 영향력 있는 SSL 방법 중 하나는 탐욕적 계층별 사전 훈련(greedy layer-wise pretraining) [Bengio et al., 2006]이다. 이 방법에서는 딥 네트워크의 각 계층을 하나씩 훈련시키며, 오토인코더 손실(autoencoder loss)을 사용한다. 당시의 유사한 접근법은 제한된 볼츠만 머신(RBMs)을 사용했으며, 이는 계층별로 훈련하고 쌓아서 Deep belief nets을 만들 수 있었다 [Hinton et al., 2006]. 이러한 방법들은 더 간단한 초기화 전략과 더 긴 훈련 시간에 의해 대체되었지만, SSL의 역사적으로 영향력 있는 사용 사례로, 첫 번째 "딥" 네트워크의 훈련을 가능하게 했다. 이후 발전된 연구들은 오토인코더의 표현 학습 능력을 개선했으며, 여기에는 노이즈 제거 오토인코더 [Vincent et al., 2008], 채널 간 예측 [Zhang et al., 2017], 딥 표준 상관 오토인코더 [Wang et al., 2015] 등이 포함된다. 그럼에도 불구하고, 궁극적으로는 오토인코더가 입력에서 누락된 부분을 복원하는 방식이 더 나은 표현 전이 가능성을 보인다고 밝혀졌고, 이는 "정보 복원" SSL 방법 범주로 이어졌다. 생성적 적대 신경망(GANs) [Goodfellow et al., 2014]은 이미지 생성기와 생성된 이미지와 실제 이미지를 구별하는 판별자로 구성된다. 이 모델의 두 구성 요소는 모두 감독 없이 훈련할 수 있으며, 두 구성 요소 모두 전이 학습에 유용한 지식을 포함할 수 있다. 초기 GAN 논문 [Salimans et al., 2016]은 GAN 구성 요소를 사용한 이미지 분류 작업을 실험했다. 판별자를 수정 [Springenberg, 2015], 생성기를 추가 [Dai et al., 2017], 또는 이미지에서 잠재 공간으로의 추가적인 매핑을 학습 [Donahue et al., 2017]하여 전이 학습을 개선하는 특수한 특징 학습 루틴도 개발되었다.
Generative Adversarial Network
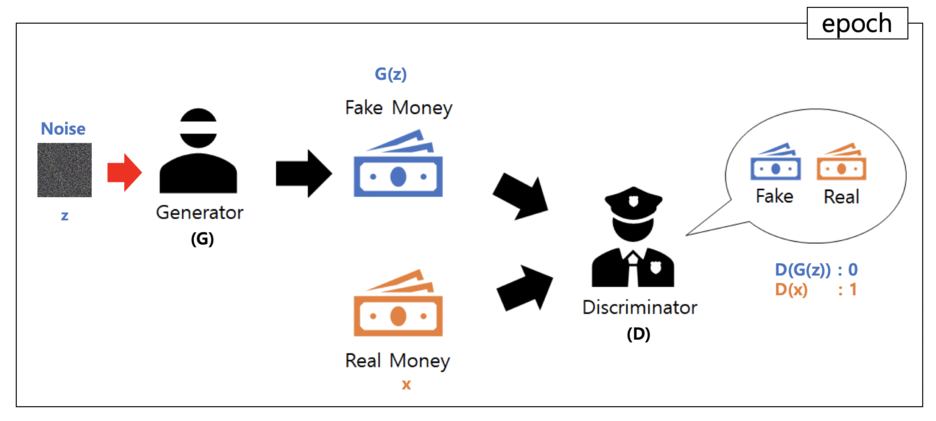
Generative Adversarial Network(GAN)는 생성자(Generator)와 판별자(Discriminator)가 경쟁하면서 데이터를 생성하는 모델이다. 생성자는 실제처럼 보이는 데이터를 만들고, 판별자는 진짜와 가짜를 구별하며, 두 네트워크가 서로 발전하면서 점점 더 현실적인 데이터를 생성할 수 있게 된다.
6. Multi-view invariance
특히 이 글에서 집중하는 방법들은 대조 학습(contrastive learning)을 사용하여 간단한 변환에 불변하는 특징 표현을 생성한다. 대조 학습의 아이디어는 모델이 입력의 두 가지 증강 버전을 유사하게 표현하도록 유도하는 것이다. 대조 학습이 널리 채택되기 전에, 여러 방법들이 다양한 방식으로 불변성을 강제로 적용하여 이 방향으로 나아갔다. 라벨이 없는 데이터에서 학습하는 가장 인기 있는 프레임워크 중 하나는 약하게 훈련된 네트워크를 사용하여 이미지에 의사 레이블을 적용하고, 그런 다음 이 레이블을 사용하여 표준 감독 방식으로 훈련하는 것이다 [Lee et al., 2013]. 이 접근법은 나중에 변환에 대한 불변성을 강제로 적용하여 개선되었다.
가상 적대적 훈련(Virtual Adversarial Training) [Miyato et al., 2018]은 의사 레이블을 사용하여 이미지에 대해 네트워크를 훈련시키고, 추가로 적대적 훈련을 수행하여 학습된 특징들이 입력 이미지에 대한 작은 교란에 대해 거의 불변하도록 만든다. 이후의 연구들은 데이터 증강 변환에 대한 불변성을 유지하는 데 집중했다. 이 범주에서 중요한 초기 방법 중 하나는 MixMatch [Berthelot et al., 2019]이다. 이 방법은 훈련 이미지의 여러 다른 무작위 증강에 대한 네트워크 출력을 평균하여 의사 레이블을 선택하고, 그 결과 증강 불변적인 레이블을 생성한다. 같은 시기에, 이미지의 서로 다른 뷰에 대한 표현 간의 상호 정보(mutual information)를 최대화하도록 네트워크를 훈련시켜 우수한 SSL 성능을 달성할 수 있다는 것이 발견되었다 [Bachman et al., 2019].
이러한 증강 기반 방법들은 위에서 설명한 기존 방법들과 이 논문에서 집중하는 현대 방법들 사이의 다리를 형성했다. 이러한 기원을 바탕으로, 이제 SSL을 네 가지 주요 범주로 분류할 수 있다
- The Deep Metric Learning Family
- The Self-Distillation Family
- The Canonical Correlation Analysis Family
- The Masked Image Modeling Family
