Introduction
핵심 개념
On-device learning : 엣지 디바이스에서 새 데이터에 AI모델을 지속적으로 적응시키는 기술로, 메모리 및 에너지 제한이 주요 도전과제입니다.
문제점
- 메모리 제한
1. 엣지 디바이스는 제한된 메모리를 가지고 있으며 훈련시 , 활성화 메모리(Activation Memory)가 주요 병목입니다.
2.가벼운 모델(MobileNetV2)조차 배치 크기 16에서 1GB 메모리를 필요로 해 SRAM을 초과합니다.- 에너지 제한 문제
1. DRAM 액세스는 온칩 SRAM보다 100배 더 많은 에너지를 소비합니다. -> DRAM액세스를 최소화하고 가능한 SRAM에서 작업을 수행해야한다.TinyTL 접근법
- 가중치(Weights) 동결
사전 학습된 특징 추출기의 가중치를 동결하고, 바이어스(bias)만 업데이트해 메모리 사용을 절감합니다.- Lite Residual Module 도입
Lite Residual Module을 추가해 적은 메모리로 모델의 적응 능력을 보존합니다.Figure1
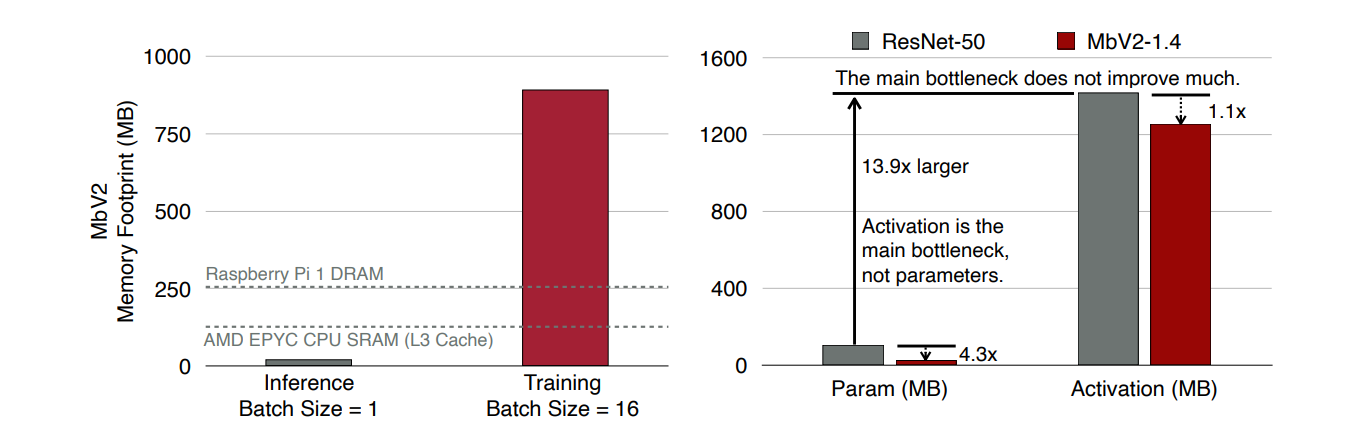
- 좌측 그래프를 통해 추론시 필요한 메모리는 적으며 훈련에서 메모리 사용량이 13.9배 많은 것을 알 수 있다. 이를 통해 Activation Memory가 주요 병목임을 알 수 있다.
- 우측 그래프에서는 MobileNetV2는 ResNet-50보다 파라미터 크기가 4.3배 작지만 활성화 메모리는 거의 동일한 것을 볼 수 있다. 즉 모델을 경량화하여도 활성화 메모리는 크게 줄지 않을 것임을 알 수 있다.
Related Work
1. 효율적인 추론 기법
- 사전 학습된 신경망을 압축하는 연구
1.Pruning
2.Quantization- 경량 신경망 아키텍처 설계
결론 : 이러한 경량 신경망은 높은 추론 효율성과 경쟁력 있는 정확도를 제공합니다. 하지만 훈련 메모리 효율성은 개선되지 않았습니다.
2. 메모리 사용량 감소 기법
i) 역전파 중 삭제된 활성화 값을 재계산하는 방법: 메모리 사용량은 줄어들지만, 계산 비용이 크기 때문에 엣지 디바이스에서는 선호되지 않습니다.
ii) 레이어별 학습 : 메모리 사용량이 감소하지만 엔드 투 엔드 학습만큼 정확도가 높지 않습니다.
iii)Activation pruning : 역동적인 희소 연산 그래프(dynamic sparse computation graph)를 생성해 훈련 중 활성화를 가지치기합니다.
iv)Activation quantization : 활성화 값을 낮은 비트로 표현하여 훈련 메모리를 줄입니다.
전이 학습(Transfer Learning)
i) 고정된 특징 추출기(feature extractor)를 사용하고, 마지막 레이어만 미세 조정합니다
ii) 전체 네트워크를 미세 조정(fine-tuning)하여 더 나은 정확도를 얻습니다
iii) Batch Normalization(BN) 레이어만 미세 조정하는 연구
3.1 Understanding the Memory Footprint of Back-propagation
- 기본 개념 : 가중치 업데이트를 위해서는 활성화 메모리가 저장되어야합니다.
- 문제점 : 활성화 메모리를 저장하려면 메모리 사용량이 커지고, 훈련속도가 느려집니다. 특히 , 배치 크기가 클수록 활성화 메모리가 차지하는 비중이 큽니다.
- 해결 방법: TinyTL은 가중치 대신 편향값만을 업데이트하는 방식으로 중간활성화 메모리를 저장할 필요가 없도록 합니다.
- 장점 : 메모리 사용량이 절감되며 훈련과정에서 활성화 메모리를 거의 사용하지 않습니다.
- 단점 : 고정된 레이어는 새로운 데이터에 대한 학습이 불가능하고 정확도가 낮을 수 있습니다.
3.2 Lite Residual Learning
- Lite Residual Learning : 가중치를 동결하고 편향값과 Lite Residual Module만을 학습합니다.
- Lite Residual Module은 기존의 특징 추출기를 수정하지 않고 추가적인 메모리 오버헤드 없이 레이어 출력을 보장하는 방식
- 채널 폭(Width) 최적화
Depthwise Convolution 대신 Group Convolution을 사용한다.
이로 인해 활성화 메모리를 기존의 12배에서 6.5배로 절감
기존 Depthwise Convolution = 6 x 2 + 1 (채널을 6배 늘리고 축소 , 잔차연결+1)
Group Convoilution = 1 + 1- Resolution에 의한 활성화 메모리 증가 및 최적화
해상도는 모델에서 활성화 메모리 사용량에 직접적인 영향을 미친다.
해상도가 높아질수록 메모리는 기하급수적으로 증가하며 이를 해결하기 위해 Lite Residual Module에서는 해상도를 낮추는 방식으로 메모리를 절감한다. 그러한 방법으로 2 x 2 평균 폴링을 통해 활성화 메모리가 4배 줄어든다. 이후에 다시 업샘플링을 통해 원래 해상도로 복원한다.- 결론 : 활성화 메모리는 총 6.5 x 4 =26배가 줄어든다
3.3.1 Normalization Layer
배치 정규화(Batch Normalization, BN)
- BN은 레이어의 출력값을 정규화해 학습 속도를 높이고, 과적합(overfitting)을 방지하는 기법입니다.
- 장점 : 학습이 안정적이며 대규모 데이터셋에서 성능이 뛰어나고 gradient vanishing을 방지하고 깊은 네트워크에서 효과적입니다.
- 단점 : 큰 배치 사이즈가 필요하고 배치 사이즈가 작을 경우 통계량 추정이 부정확해질 수 있다. (배치 크기가 작아지면 정규화 과정에서 표본수가 적어 평균과 분산 추정이 부정확하다.)
그룹 정규화(Group Normalization, GN)
- GN은 배치 크기와 관계없이 정규화를 수행하는 방법이며
데이터의 채널을 여러 그룹으로 나누어 각 그룹 내에서
독립적으로 정규화합니다.- 장점 : 작은 배치 크기에서도 안정적인 성능을 보장하여 온디바이스 학습 및 스트리밍 데이터에도 적합합니다.
- 단점 : BN보다는 약간의 성능저하가 발생할 수 있습니다.
결론
- 온디바이스 학습에서는 배치 크기를 1로 설정해야할 때가 많아 TinyYL에서는 GN을 사용한다.
3.3.2 Feature Extractor Adaptation
- Once-for-All : 한번의 사전학습으로 여러 서브 네트워크를 생성하는 구조로 가중치를 공유하여 새로운 학습이 필요하지 않다.
- TinyTL은 OFA를 사용하여 서브 네트워크를 활성화하고 각 전이 학습 데이터셋에 맞는 최적의 특징 추출기를 재학습 없이 선택하여 메모리 사용량을 줄이고, 학습 비용을 절감할 수 있다.
4. Experiments
- 백본 네트워크: ProxylessNAS-Mobile 사용
- 데이터셋:
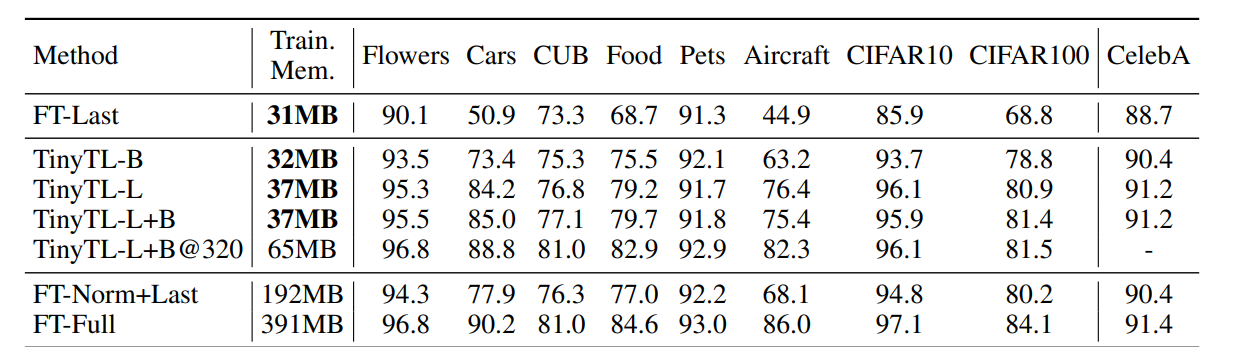
Flowers, Cars, CUB, Food, Pets, Aircraft, CIFAR10, CIFAR100, CelebA- 결론
TinyTL은 메모리 사용량을 크게 줄이면서도 기존 전이 학습 방식과 유사한 정확도를 달성합니다. 특히 해상도를 높인
TinyTL-L+B@320은 FT-Full에 가까운 성능을 보이면서도,
메모리 사용량은 FT-Full의 1/6 수준으로 효율적입니다.

안녕하세요