📚 Index
인덱스란 데이터베이스에서 검색 성능을 향상시키기 위한 자료 구조로, 특정 열(=컬럼)에 대한 정렬된 구조를 생성하여 빠른 검색이 가능하다.
인덱스 설정 기준
1️⃣ 자주 검색되는 컬럼 : WHERE, JOIN, ORDER BY, GROUP BY에 사용되는 컬럼
2️⃣ 고유한 값이 많은 컬럼 = 카디널리티가 높은 컬럼 = 중복도가 낮은 컬럼
3️⃣ 읽기 성능이 중요한 경우 (쓰기 성능은 약간 저하될 수 있음)
4️⃣ 불필요한 인덱스 최소화 : 과도한 인덱스는 INSERT, UPDATE, DELETE 성능 저하
분류 기준
1️⃣ 클러스터형 인덱스 (Clustered Index)
- 테이블의 데이터 행 자체를 인덱스가 지정한 순서대로 물리적으로 정렬함
- 테이블 당 하나만 존재할 수 있음
- 보통 프라이머리 키(PK)가 클러스터형 인덱스로 생성됨 (예 : 식별키)
- 책의 목차처럼 목차 순서가 곧 책의 실제 페이지 순서인 것과 같음
2️⃣ 논클러스터형 인덱스 (Non-clustered Index)
- 데이터 행의 물리적 순서는 그대로 둔 채, 인덱스 페이지만 따로 만들어 관리
- 실제 내용의 순서와는 상관없이 '가나다' 순으로 정렬된 키워드와 해당 키워드가 있는 페이지 번호(데이터의 주소)를 알려줌
- 테이블에 여러 개를 만들 수 있음
- 예) PK가 따로 있는 회원 테이블에서 이메일을 인덱스 설정한다면 논클러스터형 인덱스임
- 책의 색인과 비슷한 역할을 함
📚 B-Tree와 B+Tree
B-Tree
인덱스를 이루고 있는 자료구조의 일종으로, 데이터가 정렬된 상태로 유지되어 있다.
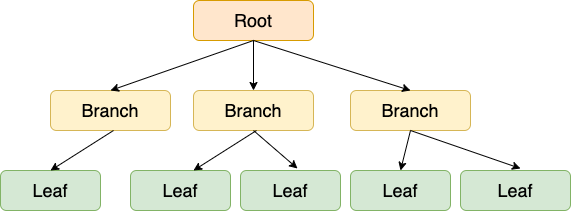
그림과 같이 가장 상단의 노드는 루트(Root) 노드, 중간 노드는 브랜치(Branch = Internal) 노드, 가장 아래에 있는 노드는 리프(Leaf) 노드라고 한다.
B-Tree는 Binary Search Tree와 비슷하지만, 한 노드 당 2개 이상의 자식 노드를 가질 수도 있다.
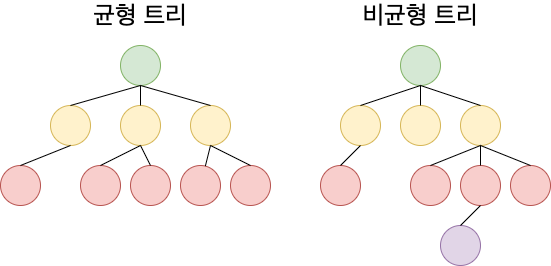
균형 트리란 루트로부터 리프까지의 거리가 일정한 트리 구조로, 트리 중에서 특히 성능이 안정화 되어있다.
B-tree는 처음 생성 당시엔 균형 트리이지만, 테이블 갱신(INSERT/UPDATE/DELETE)의 반복을 통해 균형이 깨지고 성능도 악화된다.
B+Tree
MySQL의 DB engine인 InnoDB는 B+tree로 이루어져 있는데, B+Tree는 B-Tree의 확장된 개념이다.
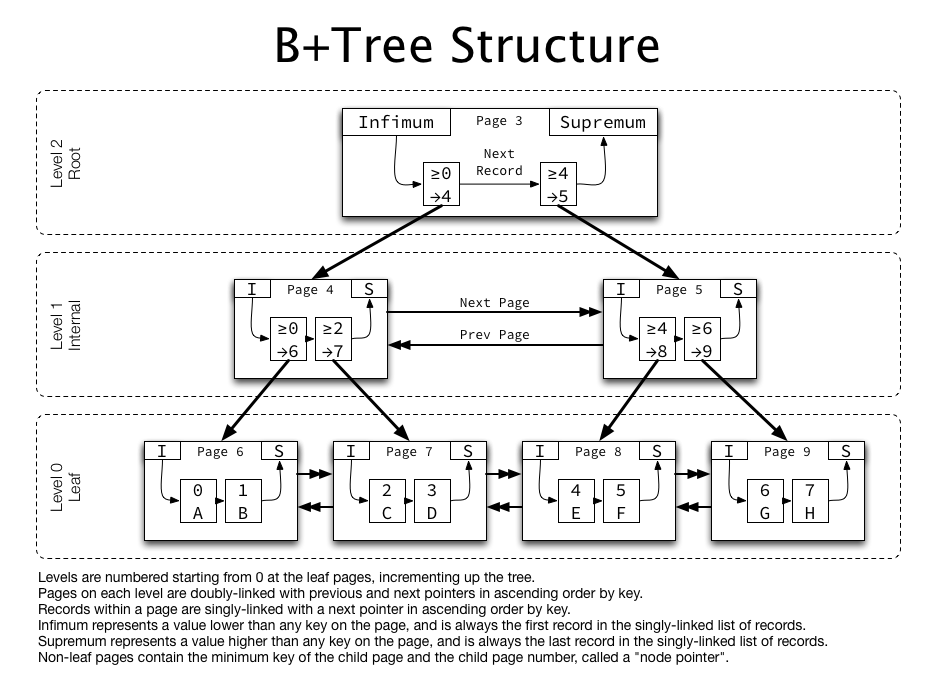
B+Tree의 리프 노드는 서로 연결 리스트로 연결되어 형제 노드끼리도 옮겨가며 조회할 수 있다. 연결된 리프 노드의 리스트를 따라가면서 범위 쿼리를 할 수 있어 범위 검색 성능도 좋다.
이때 같은 레벨의 노드들끼리는 Doubly Linked List로 연결되어 있으며, 자식 노드들은 Single Linked List로 연결되어 있다.
내부 노드(=브랜치 노드)에는 키만 저장되며, 이 키를 사용해서 자식 노드의 메모리 상 위치를 판단한다. 데이터를 찾기 위한 포인터는 리프 노드에만 있어, 내부 노드의 크기를 줄여 메모리 사용이 효율적이다.
B-Tree와 B+Tree의 차이
| 구조 | B-Tree | B+Tree |
|---|---|---|
| 데이터 저장 | 내부 노드 + 리프 노드 | 리프 노드에만 데이터 저장 (내부 노드는 인덱스 역할) |
| 순차 탐색 | 비효율적 (모든 노드를 탐색해야 함) | 리프 노드가 연결 리스트 형태 → 순차 탐색 최적화 |
| 검색 성능 | 탐색 시 비교 연산이 많음 | 탐색 시 내부 노드를 따라가고 리프 노드에서 데이터 탐색 가능 → 빠름 |
| 사용 사례 | 일반적인 트리 구조의 인덱스 | 대부분의 RDBMS에서 인덱스 기본 구조 (MySQL, PostgreSQL 등) |
B+Tree가 순차 탐색과 범위 검색에서 효율적이기 때문에 인덱스에서 더 많이 사용된다.
📚 Page
인덱스에 대해 공부하려면 페이지의 개념에 대해서도 아는 것이 중요하다. 데이터베이스가 실제로 디스크와 어떻게 소통하는지 알아야하기 때문이다.
페이지는 데이터베이스에서 데이터를 읽고 쓰는 가장 기본적인 단위다. 하드 디스크나 SSD 같은 저장 장치에서 데이터를 한 글자씩 읽어오는 것은 매우 비효율적이다. 따라서 데이터베이스는 데이터를 '페이지'라는 정해진 크기의 묶음(블록)으로 묶어서 한 번에 읽고 쓴다.
구성 요소
하나의 페이지 안에는 여러 개의 데이터 행이 쌓이고, 이 행들을 관리하기 위한 정보들이 함께 들어간다.
- 페이지 헤더 (Page Header) : 페이지 자체에 대한 정보(페이지 정보, 이 페이지에 저장된 데이터의 양 등)를 담고 있는 관리 구역
- 데이터 행 (Data Rows) : 실제 우리가 저장한 INSERT된 데이터들이 들어가는 공간으로, 무작위로 쌓이는 것이 아니라 보통 프라이머리 키 순서대로 정렬되어 저장됨
- 페이지 푸터/슬롯 : 페이지의 무결성을 검사하거나, 페이지 내의 데이터에 빠르게 접근하기 위한 보조 정보를 담음
🤔 그래서 페이지랑 인덱스랑 무슨 관계인데?
인덱스는 내가 원하는 데이터가 몇 번 페이지에 있는지를 빠르고 효율적으로 알려주는 역할을 한다. 위에서 말한 B-Tree의 각 Node가 하나의 페이지로 구성되는 것이다.
📌 프라이머리 인덱스
프라이머리 인덱스는 데이터의 실제 저장 위치와 순서를 결정한다.
B-Tree의 가장 마지막 단계인 리프 노드가 실제 데이터 페이지 그 자체이다. 즉, 리프 페이지 안에는 인덱스 키(PK)와 함께 테이블의 모든 데이터가 들어있다.
반면, 루트 노드와 브랜치 노드는 리프 노드까지 찾아가기 위한 이정표 페이지다. 이 페이지들에는 (키 값, 자식 노드(페이지)의 주소) 정보가 들어있다.
탐색 과정
id = 100인 데이터를 찾기 위해 루트 페이지를 읽음- 루트 페이지의 정보에 따라 100이 포함된 범위의 브랜치 페이지 주소를 찾아 이동
- 브랜치 페이지에서 다시 범위를 좁혀 100번 데이터가 저장된 리프 페이지의 주소를 찾아 이동
- 마침내 도착한 리프 페이지에
id = 100의 모든 데이터가 들어있으므로, 디스크를 더 읽지 않고 결과 반환
📌 세컨더리 인덱스
세컨더리 인덱스는 별도의 인덱스 페이지를 만든다.
세컨더리 인덱스의 리프 페이지에는 실제 모든 데이터가 들어있지 않다. 대신 인덱스 키와 해당 데이터의 주소 역할을 하는 프라이머리 키 값이 들어있다.
루트 노드와 브랜치 노드에는 프라이머리 인덱스와 마찬가지로 리프 노드까지 찾아가기 위한 이정표 페이지 역할을 한다.
탐색 과정
email = 'kn9012@naver.com인 데이터를 찾고 PK가 100이라고 가정한다.
email인덱스의 루트 페이지에서kn9012@naver.com이 속한 범위의 브랜치 페이지를 찾아 이동- 브랜치 페이지를 거쳐,
kn9012@naver.com이 저장된 리프 페이지에 도달 - 리프 페이지를 읽어보니,
kn9012@naver.com에 매칭되는 프라이머리 키 값인 100을 얻음 - 데이터베이스는 다시 프라이머리 인덱스를 통해 PK 값이 100인 실제 데이터가 어디 있는지, 프라이머리 인덱스 탐색 과정을 한 번 더 수행하여 최종 데이터를 가져옴
따라서 인덱스를 사용한다는 것은, 수백만 개의 데이터 페이지를 모두 뒤지는 것이 아니라 잘 정돈된 몇 개의 인덱스 페이지만 읽어서 원하는 데이터가 담긴 데이터 페이지로 이동하는 것과 같다. 이 때문에 검색 속도가 빨라지는 것이다.
📚 테이블 인덱스의 장단점
장점
- 검색 속도 향상 -> 데이터 접근 최소화
ORDER BY,GROUP BY성능 향상- JOIN 최적화
단점
- 쓰기(
INSERT,UPDATE,DELETE) 성능 저하 -> 인덱스 갱신 필요 - 공간 차지로 인한 데이터 크기 증가
- 너무 많은 인덱스는 오히려 성능 저하를 가져옴
📚 다중 컬럼 인덱스와 커버링 인덱스
다중 컬럼 인덱스 (Composite Index)
여러 개의 컬럼을 조합하여 하나의 인덱스로 설정하는 경우
CREATE INDEX idx_name ON users (age, city);사용 조건
WHERE age = 30 AND city = 'Seoul': 사용 가능WHERE city = 'Seoul': 단독 사용 불가 (age가 먼저 조회되어야 함)
커버링 인덱스 (Covering Index)
인덱스만으로 조회가 가능한 경우로 데이터 테이블 접근이 불필요함
CREATE INDEX idx_user ON users (name, age);
-- name, age 컬럼이 모두 인덱스에 포함되었기 때문에 테이블 조회 불필요
SELECT name, age FROM users WHERE name = 'Alice';📚 실행 계획과 쿼리 힌트 활용법
실행 계획(EXPLAIN)이란?
SQL 쿼리 실행 시 어떤 인덱스를 사용할지, 어떻게 실행될지 확인하는 방법
사용 목적
- 실행될 쿼리가 효율적인지 평가함
- 사용된 인덱스 확인 및 인덱스 적용 여부를 판단함
- 불필요한 Full Table Scan(전체 검색) 방지
사용 방법
EXPLAIN SELECT * FROM users WHERE age = 30;위 쿼리를 실행하면 쿼리의 실행 방식과 예상 성능이 출력된다.
주요 항목
| 컬럼 | 설명 |
|---|---|
| id | 쿼리의 실행 순서 (큰 값일수록 먼저 실행) |
| select_type | SIMPLE, DERIVED, SUBQUERY, UNION 등의 쿼리 유형 |
| table | 조회 대상 테이블 이름 |
| type | 쿼리 실행 방식 |
| possible_keys | 사용 가능한 인덱스 목록 |
| key | 실제로 사용된 인덱스 이름 |
| key_len | 사용된 인덱스의 바이트 크기 (짧을수록 효율적) |
| ref | 인덱스와 비교한 값 (상수, 컬럼, NULL 등) |
| rows | 예상 조회 건수 (작을수록 좋음) |
| filtered | 조건을 만족하는 행의 비율(%) |
| extra | 추가 정보 (Using index, Using filesort, Using temporary 등) |
쿼리 실행 방식(type)
ALL > INDEX > RANGE > REF > EQ_REF > CONST > SYSTEM
(오른쪽으로 갈수록 성능이 좋음)
| type 값 | 설명 |
|---|---|
| ALL | Full Table Scan (전체 검색) → 가장 비효율적 |
| INDEX | 인덱스 전체 검색 (WHERE 조건 없이 인덱스만 탐색) |
| RANGE | 범위 검색 (BETWEEN, <, >, IN 등) |
| REF | 동일한 값을 가진 행 여러 개 검색 (WHERE age = 30 등) |
| EQ_REF | 유니크한 값(=1개의 행) 검색 (WHERE id = 10 같은 PK 검색) |
| CONST | 상수 값으로 변환 가능 (최적화 가능) (WHERE id = 1) |
| SYSTEM | 테이블이 한 개의 행만 가진 경우 → 가장 빠름 |
실행 예제
-- 인덱스가 없는 경우 (Full Table Scan 발생)
EXPLAIN SELECT * FROM users WHERE age = 30;| id | select_type | table | type | possible_keys | key | rows | extra |
|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | users | ALL | NULL | NULL | 100000 | Using where |
type = ALL: Full Table Scan 발생possible_keys = NULL: 사용 가능한 인덱스 없음
-- age 컬럼에 인덱스를 추가
CREATE INDEX idx_age ON users (age);-- 인덱스 추가 후 실행
EXPLAIN SELECT * FROM users WHERE age = 30;| id | select_type | table | type | possible_keys | key | rows | extra |
|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | users | RANGE | idx_age | idx_age | 100 | Using where |
type = RANGE: 인덱스를 사용하여 일부만 검색rows = 100: 조회해야 할 행 개수가 대폭 감소
쿼리 힌트(Query Hint)란?
SQL 실행 시 강제로 특정 인덱스를 사용하도록 지정하는 기능
EXPLAIN 결과를 보고, 인덱스가 비효율적으로 사용될 때 적용
주요 쿼리 힌트
| 힌트 | 설명 |
|---|---|
| USE INDEX (idx_name) | 특정 인덱스를 사용하도록 강제 지정 |
| IGNORE INDEX (idx_name) | 특정 인덱스를 사용하지 않도록 강제 지정 |
| FORCE INDEX (idx_name) | 강제로 특정 인덱스를 사용 (필수 적용) |
1️⃣ 특정 인덱스 강제 사용 (USE INDEX)
-- idx_name 인덱스를 강제 사용하여 검색
SELECT * FROM users USE INDEX (idx_name) WHERE name = 'Alice';2️⃣ 특정 인덱스 제외 (IGNORE INDEX)
-- idx_age 인덱스를 사용하지 않고 검색
SELECT * FROM users IGNORE INDEX (idx_age) WHERE age = 30;3️⃣ 강제 인덱스 사용 (FORCE INDEX)
-- idx_name 인덱스를 반드시 사용
-- USE INDEX보다 더 강제적인 설정
SELECT * FROM users FORCE INDEX (idx_name) WHERE name = 'Alice';쿼리 힌트 적용 성능 비교
✔️ 쿼리 힌트 적용 전
EXPLAIN SELECT * FROM users WHERE name = 'Alice';| id | select_type | table | type | possible_keys | key | rows | extra |
|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | users | ALL | NULL | NULL | 100000 | Using where |
- Full Table Scan (type = ALL) 발생 → 성능 저하
✔️ USE INDEX 적용 후
EXPLAIN SELECT * FROM users USE INDEX (idx_name) WHERE name = 'Alice';| id | select_type | table | type | possible_keys | key | rows | extra |
|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | users | REF | idx_name | idx_name | 10 | Using index |
- 인덱스 적용 성공 (type = REF) → 성능 개선
실행 계획 최적화 체크리스트
✔️ EXPLAIN 실행 후, 아래 사항 확인
type = ALL인 경우 : 인덱스 추가 고려rows값이 너무 크면 : 인덱스 최적화 필요possible_keys가NULL이면 : 해당 컬럼에 인덱스 추가Using filesort,Using temporary→ORDER BY,GROUP BY최적화 고려
✔️ 쿼리 힌트 활용
- 잘못된 인덱스가 선택될 경우 →
USE INDEX,IGNORE INDEX활용 - 강제 적용이 필요할 경우 →
FORCE INDEX사용
📚 인덱스 최적화와 주의사항
1️⃣ 불필요한 인덱스 제거
- 너무 많은 인덱스는 성능 저하를 불러올 수 있음
2️⃣ 선택도가 높은(중복이 적은) 컬럼을 인덱스로 설정
3️⃣ 읽기/쓰기 비율 고려
- 쓰기 작업이 많다면 인덱스 최소화 하기
4️⃣ EXPLAIN으로 실행 계획 확인 후 인덱스 최적화
5️⃣ 다중 컬럼 인덱스의 컬럼 순서 고려
- WHERE 절에서 자주 사용하는 순서대로