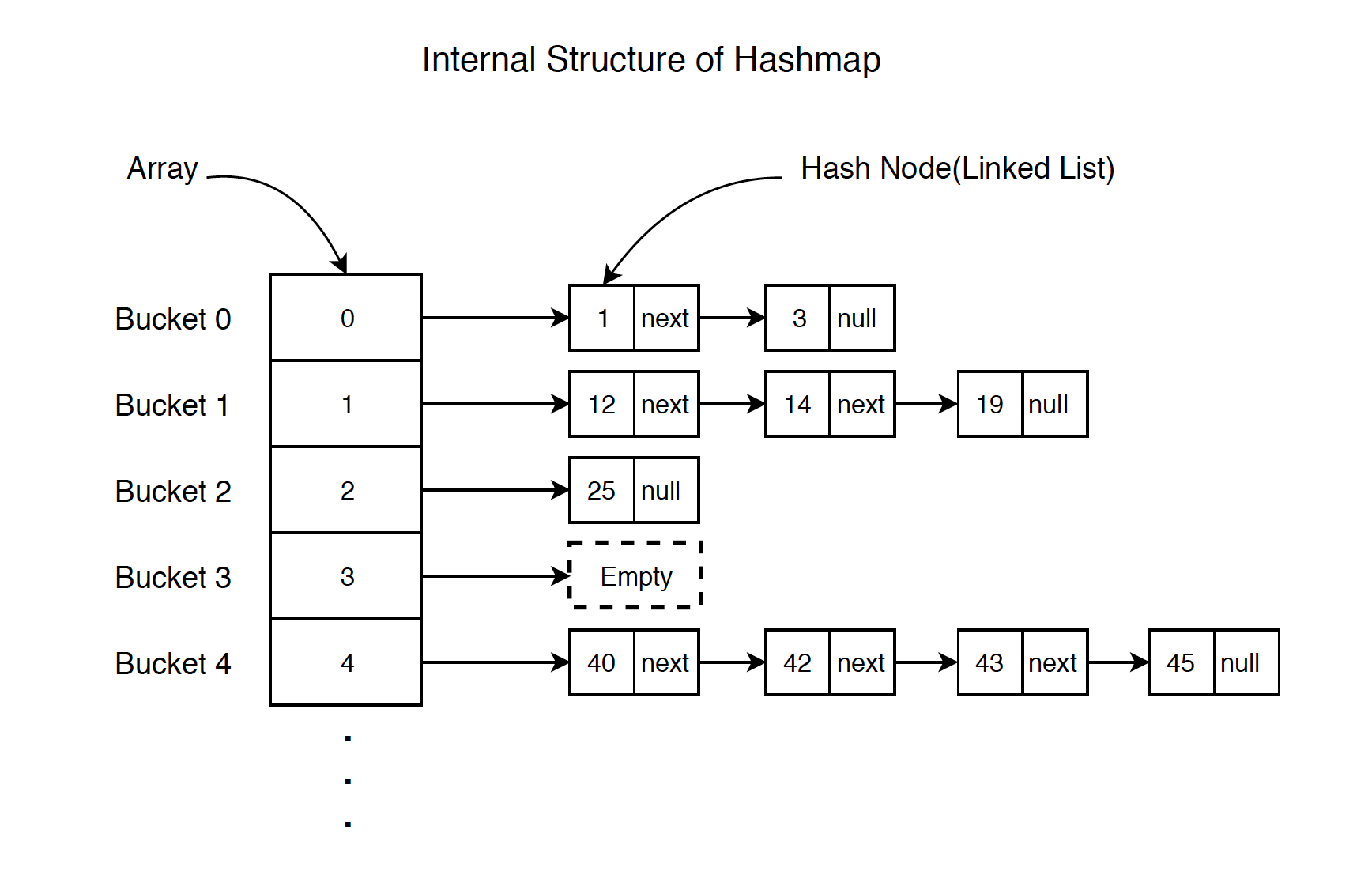
📚 HashMap
Map의 구현체로, 데이터를 저장할 때 키(Key)와 값(Value)이 짝을 이루어 저장된다.
데이터를 저장할 때는 key로 해시함수를 실행한 결과를 통해 저장 위치를 결정하기 때문에, HashMap은 특정 데이터의 저장 위치를 해시함수를 통해 바로 알 수 있다. 따라서 데이터의 추가, 삭제, 특히 검색이 빠르다는 장점이 있다.
- key : 중복 불가능, null도 하나만 들어간다면 가능
- value : 중복 가능, 여러개의 null 가능
transient Node<K,V>[] table;
...
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
Java의 HashMap은 Node<K,V>[] table에 데이터를 저장하며, 각 노드는 hash, key, value, next의 필드를 가진다.
📌 put(K key, V value)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
-
hash()를 통해key를 해싱한 후putVal()메서드를 통해 데이터를 저장함 -
(n - 1) & hash연산을 통해 버킷(배열의 각 칸) 인덱스를 결정함-
해당 버킷이 비어있으면 새 노드 생성
-
비어있지 않다면
equals()를 통해 기존 키 확인- 일치한다면 값 덮어쓰기 / 일치하지 않는다면 LinkedList 체이닝 추가
-
-
사이즈가
threshold를 넘으면 resize -
Java 8 이상부터 버킷이 트리화되어 있을 경우 TreeNode로 데이터 입력하며, 체이닝 길이가
treeifyThreshold이상이라면 트리로 변환
📌 get(Object key)
public V get(Object key) {
Node<K,V> e;
return (e = getNode(key)) == null ? null : e.value;
}
final Node<K,V> getNode(Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}-
hash()로 해시 값을 계산하여, 어떤 버킷의 인덱스를 검사할지 정함 -
해당 버킷에 연결된 노드들을
hash값과equals()로 비교하며 탐색 -
Java 8 이상부터는 버킷이 트리화되어 있을 경우 TreeNode로 탐색
해시(Hash)란?
-
입력 데이터를 고정된 길이의 데이터로 변환한 값
-
보통 int형으로 반환되며, 이 값을 해시코드(HashCode)라고 함
-
데이터를 저장하거나 검색, 삭제할 때 주소를 계산하는 데 사용
Hash Collection에서 해시 충돌(Hash Collision)을 대처하는 방법
💡 Hash Collision이란?
서로 다른 키들이 같은 해시 값을 가질 때 발생하는 것
1. Separate Chaining
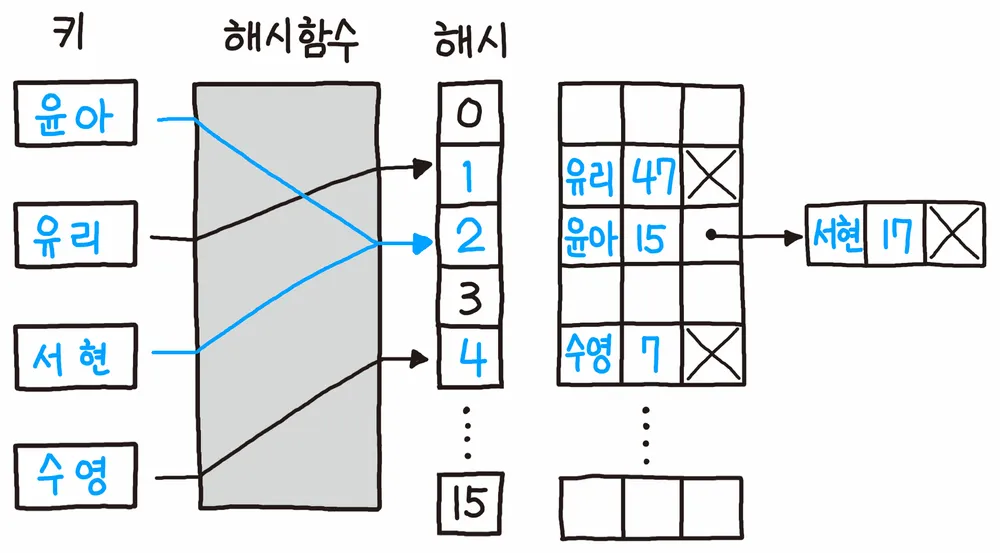
윤아와 서현의 해시 값이 같음 -> 연결 리스트로 연결
-
각 버킷이 LinkedList나 Tree 등을 가지고 충돌된 요소들을 그 안에 저장
-
Java의 HashMap이 기본적으로 사용하는 방식
2. Open Addressing
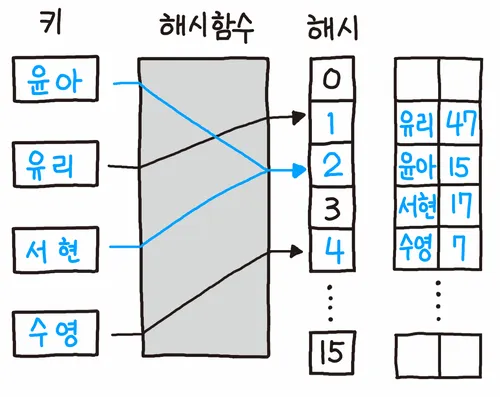
윤아와 서현의 해시 값이 같음 -> 비어 있는 3번 버킷에 데이터 저장
-
데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식
-
(단점) 전체 슬롯의 개수 이상을 저장할 수 없으며, 체이닝 방식과 달리 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장이 없음
-
Java의 Hashtable, ConcurrentHashMap 일부 구현에서 사용
1. 선형 조사(Linear Probing)
- 충돌이 발생할 경우 해당 위치부터 순차적으로 탐사 진행
hi(k) = (h(k) + i) mod m-
h(k): 기본 해시 함수,i: 충돌 횟수(0부터 시작),m: 테이블 크기 -
(장점) 구현 단순 / (단점) 충돌이 많을수록 연속된 빈 칸이 줄어들어 성능 급격히 저하 -> 1차 클러스터링 발생
2. 이차 조사(Quadratic Probing)
- 충돌이 발생할 경우 제곱 간격(i²)으로 탐사 진행
hi(k) = (h(k) + c1·i + c2·i²) mod m-
보통
c1 = 0,c2 = 1로 단순화 -
(장점) 1차 클러스터링 현상이 줄어듦 / (단점) 2차 클러스터링 발생 가능(해시 값이 같은 키들은 같은 순서로 이동), 모든 슬롯을 탐색하지 못할 수도 있음
3. 이중 해싱 (Double Hashing)
- 두 개의 서로 다른 해시 함수를 사용하여 다음 버킷 계산
hi(k) = (h1(k) + i·h2(k)) mod m-
h1(k): 기본 해시 함수,h2(k): 두 번째 해시 함수,i: 충돌 횟수 -
(장점) 충돌이 잘 분산되어 클러스터링 현상이 거의 없음, 탐색 효율이 가장 뛰어남 / (단점) 두 개의 좋은 해시 함수가 필요하며 구현이 가장 복잡함
Open Addressing vs Separate Chaining
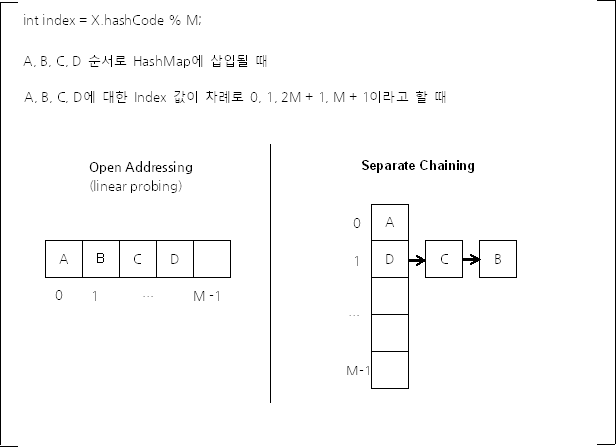
🤔 그럼 Java의 HashMap은 Hash Collision을 어떻게 처리할까?
💡 Java의 HashMap에서는 Separate Chaining을 사용한다!
Open Addressing은 데이터를 삭제할 때 효율적으로 처리하기 어려운데, HashMap에서 remove() 메서드는 빈번하게 호출될 수 있다. 또한 HashMap에 저장된 키-값 쌍 개수가 일정 개수 이상으로 많아지면, 일반적으로 Open Addressing은 Separate Chaining보다 느리다. Open Addressing의 경우 해시 버킷을 채운 밀도가 높아질수록 Worst Case 발생 빈도가 더 높아지기 때문이다.
Java 7까지는 내부적으로 배열 + 연결 리스트 방식으로 데이터를 저장했지만
Java 8부터는 충돌이 많이 발생해 동일한 버킷에 저장된 요소 수가 treeifyThreshold 이상이 되면, 해당 연결 리스트를 Red-Black Tree로 변환하여 성능 저하를 방지한다.
- 연결 리스트의 시간 복잡도 : O(N)
- 트리의 시간 복잡도 : O(log N)
🤔 Map에서 enhanced for문을 사용할 수 있을까?
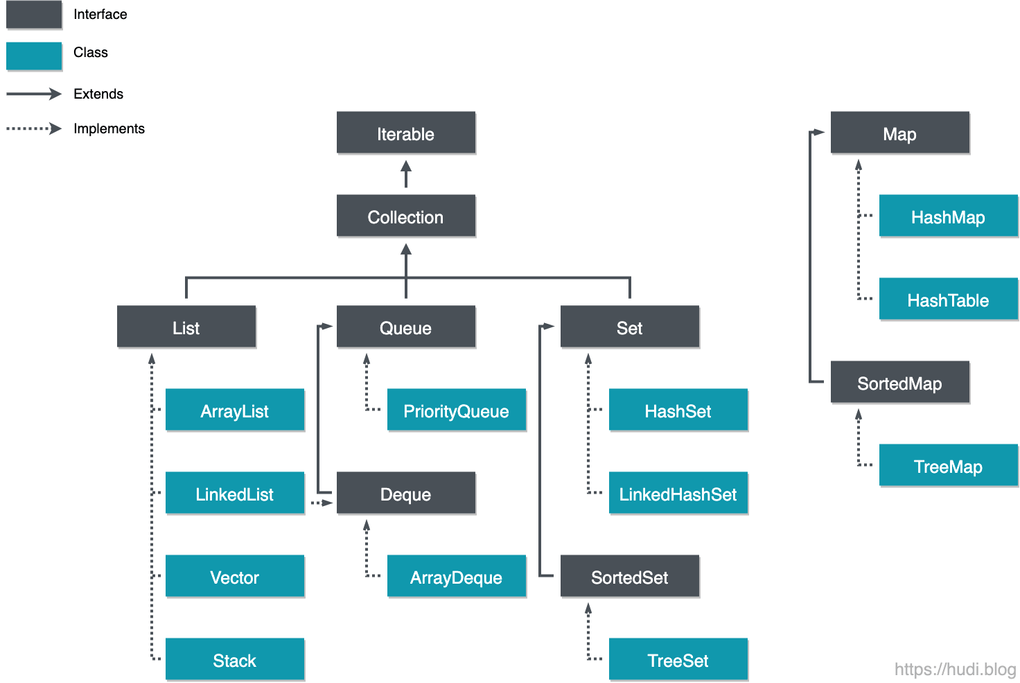
위와 같이 Map은 Iterable을 구현하고 있지 않기 때문에 Map 자체에서 enhanced for문을 사용할 수 없다.
즉, Map 자체는 순회 대상이 아니기 때문에 순회할 수 있는 view 객체를 꺼내야 한다.
Map<String, Integer> map = new HashMap<>();
// entrySet() 사용
for (Map.Entry<String, Integer> entry : map.entrySet())
// keySet() 사용
for (String key : map.keySet())
// values() 사용
for (Integer value : map.values()) entrySet()
- Map의 모든 (key, value) 쌍을 Map.Entry 객체로 반환하는 Set
- 가장 일반적이며 key와 value 모두 사용할 수 있음
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}- Set<Map.Entry<K, V>> 타입의 컬렉션 반환
- Map.Entry는 key와 value에 접근 가능한 인터페이스
keySet()
- Map의 모든 key 값만 모아 놓은 Set을 반환
for (String key : map.keySet()) {
System.out.println(key + " " + map.get(key));
}map.get(key)호출이 별도로 필요하기 때문에entrySet()보다 느릴 수 있음
values()
- Map의 모든 value 값만 모은 Collection을 반환
for (Integer value : map.values()) {
System.out.println(value);
}- key 정보가 없어 value만 필요할 때만 사용
HashMap의 treeify threshold
📌 putVal()
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}위에서 잠깐 보고 지나갔던 putVal() 메서드를 다시 봐보겠다.
해당 코드는 현재까지 연결된 노드 수 binCount가 TREEIFY_THRESHOLD - 1보다 크면 treeifyBin()을 호출해서 트리화를 시도한다.
static final int TREEIFY_THRESHOLD = 8;이때 기본적으로 TREEIFY_THRESHOLD는 8로 설정되어 있다.
📌 treeifyBin()
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 초기 MIN_TREEIFY_CAPACITY는 64로 설정
resize();
// 트리 변환 로직
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
// replacementTreeNode() : Node to TreeNode
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}-
tab.length < MIN_TREEIFY_CAPACITY라면 트리화하지 않고resize()를 먼저 진행한다. 테이블이 작을 때는 오히려 트리보다 배열 리사이징이 더 효율적이기 때문이다. -
현재 버킷
index에 연결된 노드들을 하나씩 TreeNode로 바꿔서 더블 링크드 리스트 형태로 구성한다. -
변환이 끝나면
hd.treeify(tab)호출 -> Red-Black Tree 구성
HashMap의 load factor와 resize()
💡 load factor란?
해시 테이블이 얼마나 차 있는지 나타내는 비율
즉, 현재 용량 대비 얼마나 찼을 때 resize할지 결정하는 기준이다.
static final float DEFAULT_LOAD_FACTOR = 0.75f;기본값은 위와 같이 0.75로 설정되어 있다.
이때, 값 0.75는 공간 효율성과 성능(충돌 최소화)의 균형을 맞춘 값으로, 해시 충돌을 너무 자주 일으키지 않으면서 너무 자주 리사이징 하지 않도록 조절한 값이다.
📌 putVal()
if (++size > threshold)
resize();size가 threshold보다 크게 되면 resize() 메서드를 호출한다.
📌 resize()
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 테이블 크기 2배 확장, threshold도 2배로 증가
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
...
}resize하는 과정에서 새 threshold를 capacity * loadFactor로 설정한다.
hashCode() vs equals()
hashCode()
- 객체를 해시 기반 자료구조에 저장할 때 어떤 버킷에 저장할지 결정하는 데 사용되는 해시값
equals()
- 두 객체의 논리적 동등성(객체의 실제 값이나 의미가 같다고 판단되는 상태)을 비교하는 것으로, 주소가 다르더라도 내용이 같다면 true 반환
Object에서의 equals()와 hashCode()
public boolean equals(Object obj) {
return (this == obj); // 동일성 비교
}
public int hashCode() {
return native hashCode(); // JVM 내부 주소 기반
}HashMap에서의 equals()와 hashCode()
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final boolean equals(Object o) {
if (o == this) // 동일성 비교
return true;
// 논리적 동등성 비교
return o instanceof Map.Entry<?, ?> e
&& Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue());
}HashMap에서는 equals()와 hashCode()를 오버라이딩 하여 논리적으로 같은 객체를 같은 것으로 간주하도록 만든다.
이때 동일성 (==)은 두 참조가 완전히 같은 객체를 가리키는지를 말하고, 동등성 (equals())은 두 객체의 내용이 같다고 판단하는지를 말한다.
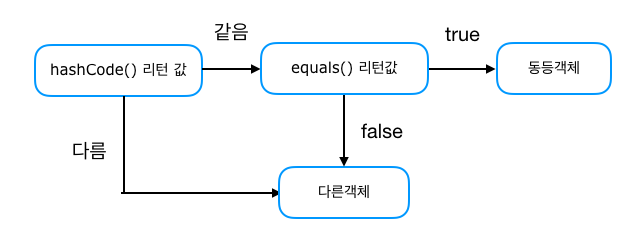
해시 값을 사용하는 Collection(HashMap, HashSet, Hashtable)은 객체가 논리적으로 같은지 비교할 때 위와 같은 과정을 거친다.
먼저 hashCode()로 버킷의 위치를 찾고, equals()로 같은 객체인지 확인한다.
두 객체가 equals()로 같다고 판단되면, 같은 해시 버킷에 있어야 하고 hashCode()도 같아야 하는 것이다.
이것은 Object의 hashcode()에도 아래와 같이 명시되어 있다.
If two objects are equal according to the equals method, then calling the hashCode method on each of the two objects must produce the same integer result.
결국 equals() 메서드만 오버라이딩 한다면, 해시 값을 사용하는 Collection에서 equals()로 비교하기도 전에 hashCode()로 값이 달라져 다르다고 판단하게 되는 것이다.
★ 따라서 꼭 hashCode()와 equals()를 같이 오버라이딩 해야한다.
여담이지만 나는 알고리즘 풀이에서만 String의 equals()를 사용해보았기 때문에 부끄럽게도 여태 equals()가 동등성만 비교하는줄 알았다.. String의 equals()는 오버라이딩을 해서 문자열이 같으면 true를 반환하도록 한 것!
Hashtable vs HashMap
1️⃣ Thread-safe 여부
Hashtable
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
}
...Hashtable의 주요 메서드는 위와 같이 synchronized 키워드로 동기화되어 있어 멀티스레드 환경에서 안전하다.
반면 HashMap은 기본적으로 동기화되지 않아 단일 스레드 환경에서는 빠르지만, 멀티스레드 환경에서는 ConcurrentHashMap을 사용해야 한다.
따라서 멀티스레드 환경이 아니라면 Hashtable은 HashMap 보다 성능이 떨어진다는 단점을 가지고 있다.
2️⃣ Null 값 허용 여부
- Hashtable : key, value 모두 null 불가
- HashMap : key 1개 null 가능, value는 null 여러 개 가능
3️⃣ Enumeration 제공 여부
Hashtable은 컬렉션 순회 방식인 Enumeration을 제공하여, 순회 도중 컬렉션이 수정되어도 예외가 발생하지 않는다. => fail-fast가 아니다
Hashtable<String, String> table = new Hashtable<>();
table.put("a", "1");
table.put("b", "2");
Enumeration<String> keys = table.keys();
while (keys.hasMoreElements()) {
String key = keys.nextElement();
table.remove(key); // 예외 안 터짐 (but 위험)
}
반면 HashMap은 Enumeration을 제공하지 않으며, fail-fast인 Iterator를 제공한다. 따라서 순회 도중 컬렉션이 수정되면 ConcurrentModificationException이 발생하게 된다.
HashMap<String, String> map = new HashMap<>();
map.put("a", "1");
map.put("b", "2");
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
map.remove(key); // ConcurrentModificationException 발생 (fail-fast)
}
안정성 측면에서는 순회 중 예기치 않은 컬렉션 변경이 일어났을 때 예외를 던져서 문제를 조기에 발견해야 하는 HashMap + Iterator를 사용하는 것이 좋다.
4️⃣ 보조 해시 함수 사용 여부
HashMap은 Java 8부터 보조 해시 함수 hash()를 사용한다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}이 메서드는 key.hashCode()의 값을 그대로 쓰는 것이 아니라, 상위 비트와 하위 비트를 XOR 연산으로 섞는다. (h ^ (h >>> 16))
Java 7 이전의 기존 방식은 hashCode()가 만든 해시값을 그대로 쓰면, 버킷 배열의 인덱스를 계산할 때 상위 비트는 거의 무시된다. (index = (n - 1) & hash에서 하위 비트만 사용되기 때문) 따라서 hashCode()의 상위 비트에만 차이가 있는 값들이 서로 같은 인덱스로 몰릴 수 있어 충돌이 많아진다.
이를 위해 보조 해시 hash()를 사용해서 상위 비트를 하위 비트로 섞어 충돌 가능성을 분산시킨다. 즉, 유사한 hashCode를 가진 key들이라도 서로 다른 버킷에 배치되도록 유도한다.
따라서 HashMap은 보조 해시 함수를 사용하지 않는 Hashtable에 비하여 해시 충돌이 덜 발생할 수 있어 상대적으로 성능상 이점이 있다.
5️⃣ 개선 여부
Hashtable은 Java에서 해시 테이블을 구현한 클래스 중 가장 오래된 클래스로 거의 개선이 이루어지지 않았지만, HashMap은 Java 1.2에 도입된 이후 지속적으로 성능 개선, 트리 구조 도입, 내부 구현 개선 등이 이루어지고 있다.
LinkedHashMap vs HashMap
| HashMap | LinkedHashMap | |
|---|---|---|
| 기본 구조 | 배열 + 연결리스트/트리 (충돌 일정 수준 이상 발생 시 TreeNode로 전환, TreeNode는 내부적으로 이중 연결 리스트 구조) | HashMap + 이중 연결 리스트 |
| 순서 보장 | X | key의 삽입 또는 접근 순서 보장 기본적으로는 삽입 순서를 보장하며 accessOrder를 true로 설정 시 접근 순서 보장으로 바뀜 |
| 정렬 방식 | X | 삽입 또는 접근 순으로 순회 가능 |
| LRU 구현 | X | LRU 캐시 구현 용이 |
| 성능 | 빠름 | 이중 연결 리스트 때문에 조금 더 느림 |
🤔 LinkedHashMap이 항상 접근 순서를 보장하는 것은 아니다?
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}LinkedHashMap의 생성자는 다음과 같이 이루어져 있으며, accessOrder는 접근 순서를 보장할지 결정하는 것이다.
LinkedHashMap을 선언할 때 명시적으로 accessOrder를 true로 설정하지 않는다면, 즉 비워둔다면 accessOrder는 기본적으로 false가 된다.
따라서 LinkedHashMap으로 LRU(Least Recently Used) 캐시를 구현하고 싶다면 accessOrder를 true로 설정해주자!
LinkedHashMap<K, V> cache = new LinkedHashMap<K, V>(capacity, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity; // 가장 오래된 항목 제거
}
};
ConcurrentHashMap vs HashMap
| HashMap | ConcurrentHashMap | |
|---|---|---|
| Thread-safe | 비동기 | 동기화 지원 |
| 사용 환경 | 단일 스레드 | 멀티스레드 |
| 잠금 방식 | 없음 | Segmented Lock (Java 7), Bucket-level CAS (Java 8) |
| null 허용 | key 1개, value 여러개 가능 | key, value 모두 불가능 |
| 성능 | 빠르지만 동기화 X | 동기화 + 성능 유지 |
참고로 ConcurrentHashMap의 putVal() 메서드를 살펴보면 메서드 자체에 synchronized가 붙어있는게 아니라 메서드 안에 synchronized 블록이 있다.
📌 putVal()
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) { // 락 걸기
...
}이는 성능 최적화와 락의 범위 최소화를 위한 것이다.
ConcurrentHashMap은 높은 동시성을 목표로 설계됐기 때문에, 메서드 전체에 synchronized를 걸면 모든 스레드가 put()할 때 전체 맵을 잠궈버린다. 이는 성능 저하로 이어지기 때문에 경쟁이 일어날 가능성이 있는 버킷(bin)에만 락을 걸고 나머지 버킷에는 락을 걸지 않음으로써 동시성을 최대화한다.
그럼 ConcurrentHashMap의 putVal()에서 락이 발생하는 경우는 어떤 것일까?
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null)위의 경우는 빈 버킷인 경우인데, 락이 발생하는 else로 내려온다는 것은 해당 버킷에 이미 값이 있다는 것으로 충돌이 발생한다. 따라서 충돌 해결을 위해 해당 버킷의 첫 노드 f에 synchronized를 건다.
📌 Node<K, V> 내부 필드
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}또한 ConcurrentHashMap은 Node의 val과 next에서 volatile 키워드를 사용한다.
💡 volatile이란?
변수가 스레드 간에 변경되었음을 항상 반영하도록 보장하는 키워드로, CPU 캐시가 아닌 메인 메모리에서 항상 값을 읽는다. 즉, 한 스레드가volatile변수를 수정하면 다른 스레드도 즉시 그 변경을 볼 수 있다.
val과 next가 volatile인 이유는 다른 스레드에서 이 Node를 읽었을 때 가장 최신 값이 보장되어야 하기 때문이다. 그래야 읽기 작업이 일관된 값을 가져올 수 있고, 해시 충돌 시 연결된 체인도 정확히 탐색할 수 있다. => 따라서 ConcurrentHashMap의 get()에서는 synchronized 없이도 값이 보장될 수 있다.
참고로 volatile은 락을 사용하는 것보다 훨씬 가볍고 빠르지만, 캐시 최적화가 제한될 수 있고 너무 자주 접근되거나 변경되는 필드에 volatile을 남용하면 오히려 성능 저하가 올 수 있다!