입사 후 카산드라에 대해 학습하면서 LSM Tree와 Bloom Filter에 대해 깔짝 알게 되었고, 이번주 알고리즘 스터디 문제 중 Skip List가 있었는데 이것들이 LSM Tree와 관련된 것이었다니 신기했다.
안 그래도 Bloom Filter에 대해 깊게 공부해보려 했는데 기왕 이렇게 된거 LSM Tree와 Skip List까지 깊게 공부해보려고 한다.
📚 LSM Tree (Log Structured Merge Tree)
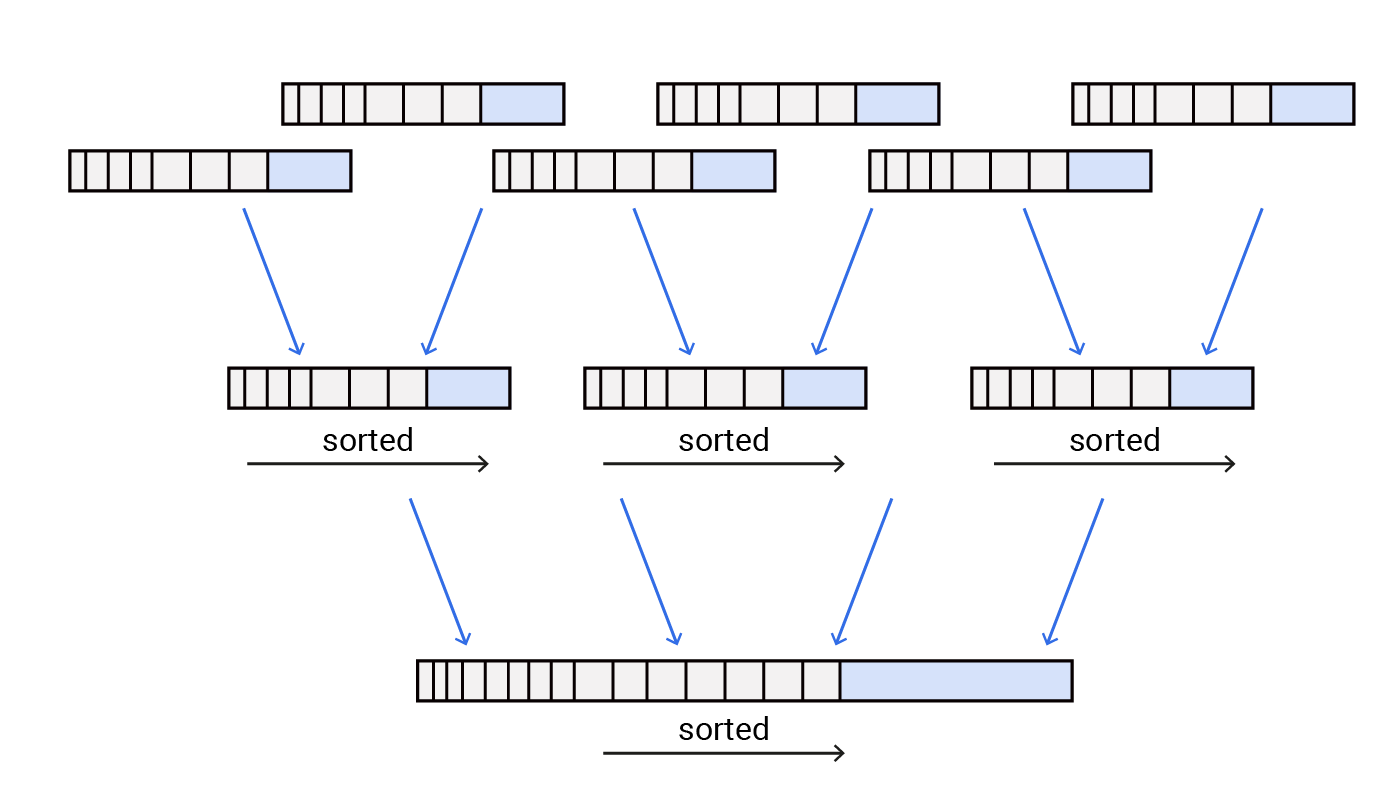
LSM Tree는 쓰기 작업의 처리량(Throughput)을 극대화하기 위해 설계된 디스크 저장 구조이다. Cassandra나 HBase, RocksDB 등의 NoSQL 데이터베이스에서 사용되는 스토리지 엔진 아키텍처이며, Log Structured Storage Engine 중 한 가지다.
기본적으로 삽입 작업이 매우 빈번한 환경에서 디스크 I/O를 줄이기 위한 구조이며, 이 구조는 여러 개의 계층적 트리로 구성되며 각 트리는 메모리 또는 디스크 상에 존재한다.
Append-only (순차 쓰기)
LSM Tree는 데이터를 수정하거나 삭제할 때 기존 데이터를 찾아 덮어쓰지 않고, 항상 새로운 로그 형태로 맨 뒤에 추가한다. 이로 인해 디스크의 Random I/O를 Sequential I/O로 변환하여 쓰기 성능을 비약적으로 높인다.
💡 Random I/O, Sequential I/O란?
- Random I/O(랜덤 I/O)란 데이터가 저장장치에 흩어져 있어, 필요한 조각을 찾기 위해 건너뛰며 읽거나 쓰는 방식이다.
HDD의 경우, 디스크 헤더가 물리적으로 계속 이동(seek time)해야 하므로 속도가 느리고 부하가 크다. 예를 들면 DB에서 인덱스를 통해 특정 사용자의 데이터를 조회할 때나 여러 사용자가 동시에 요청을 보낼 때 사용된다.- Sequential I/O(순차 I/O)란 데이터가 저장장치에 연속적으로 나열되어 있어, 시작점부터 끝까지 쭉 읽거나 쓰는 방식이다. HDD의 경우, 디스크 헤더(바늘)가 한 번 자리를 잡으면 움직임 없이 계속 읽기만 하면 되므로 속도가 빠르다. 예를 들면 로그 파일 기록, 대용량 데이터 백업 등을 순차 I/O로 처리한다.
- 백엔드 튜닝의 목표는 느린 Random I/O를 최대한 줄이고, 빠른 Sequential I/O로 처리하도록 유도하는 것이다. (예: 인덱스 최적화, 쓰기 버퍼링, 캐싱 등)
조금 더 알아보자면, 대부분의 RDBMS(MySQL, PostgreSQL, Oracle)는 데이터를 저장할 때 B-Tree(또는 B+Tree)라는 구조를 사용한다.
이는 새로운 데이터가 들어오거나 수정될 때 데이터가 저장될 정해진 위치를 찾기 때문에, 디스크 헤더를 움직이게 만든다. 이때 Random I/O가 발생하는데, 데이터가 많아질수록 쓰기 속도가 느려지는 단점이 있지만 읽기 속도는 매우 빠르고 안정적이라는 장점이 있다.
쓰기 성능을 극대화해야 하는 NoSQL(Cassandra, HBase) 등은 LSM Tree 구조를 주로 사용한다.
데이터가 들어오면 기존 위치를 찾지 않고, 맨 뒤에 추가만 한다. (Append-only) 기존 데이터를 수정할 때도 데이터를 찾아 고치는 것이 아니라, "이 데이터는 수정됐다"라는 내용을 맨 뒤에 새로 쓴다. 헤더가 움직일 필요 없이 계속 뒤에 붙이기만 하면 되어 Sequential I/O가 발생한다. 쓰기 속도가 매우 빠르다는 장점이 있지만, 읽을 때는 여러 곳에 흩어진 데이터 조각을 합쳐야 해서 상대적으로 느리다는 단점이 있다.
나는 무조건 RDBMS = Random I/O이고, NoSQL = Sequential I/O라고 생각했는데 모든 NoSQL이 LSM Tree를 사용하는 것은 아님을 알게 되었다.
MongoDB는 NoSQL이지만 기본적으로 B-Tree 기반이기 때문에, I/O 패턴이 RDBMS와 비슷하여 Random I/O가 많이 발생한다고 한다.
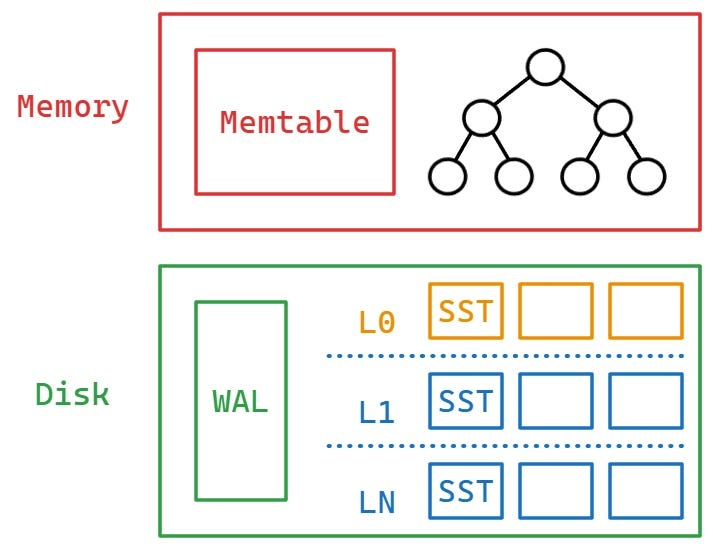
MemTable (Memory)
데이터가 유입되면 가장 먼저 저장되는 인메모리 버퍼로, 데이터가 들어오는 즉시 Key를 기준으로 정렬되어 저장된다. 이때 Skip List와 같은 자료구조가 사용된다.
메모리에서 미리 정렬을 해두어야 나중에 디스크(SSTable)로 플러시할 때 순서대로 쓰기만 하면 되기 때문이며, 전원이 꺼질 것을 대비하여 WAL(Write-Ahead Log)이라는 로그 파일(디스크)에 기록한다.
SSTable (Disk)
MemTable이 임계치에 도달하면 디스크로 Flush 되어 생성되는 불변의 파일로, 한 번 쓰면 절대 수정하지 않는다.
파일이 수정될 일이 없어 여러 스레드가 동시에 읽어도 동기화 문제가 거의 발생하지 않는다. 락이 필요 없고 읽기 성능에 유리하다.
또한 변하지 않기 때문에 OS의 파일 시스템 캐시나 DB 내부 캐시에 올려두고 재사용하기 좋아 캐시 친화적이다.
그림에서 L0, L1, LN은 데이터가 디스크에 저장되는 층이라고 생각하면 된다.
- L0 : 메모리에 있던 내용을 순차적으로 디스크에 방금 기록한 파일들
- L1 ~ LN : L0에 파일이 너무 많이 쌓이면, 시스템은 이를 정리해서 다음 단계(L1)으로 합침 (이를 계속 반복).
레벨이 내려갈수록 용량이 훨씬 크고 데이터가 오래되었으며, 깔끔하게 정렬되어 있음
그럼 디스크에 SSTable이 여러 개 쌓여 있으면, 데이터를 찾을 때 모든 파일을 다 뒤져야 할까? 그렇게 된다면 Random I/O가 폭발하게 될 것이다.
각 SSTable에는 데이터가 있을 수 있음/절대 없음을 빠르게 알려주는 메모리 기반의 확률적 자료구조인 Bloom Filter가 달려있다. 이를 통해 불필요한 디스크 접근을 획기적으로 줄인다. 더 자세한건 아래서 이야기하겠다.
Compaction
데이터가 계속 추가되면 SSTable 파일의 개수가 늘어나 읽기 성능이 저하된다. 이를 방지하기 위해 백그라운드에서 주기적으로 여러 SSTable을 병합하여 불필요한 데이터(삭제된 데이터나 구버전 데이터)를 정리한다.
NoSQL에서 DELETE 명령이 실행되더라도 데이터가 즉시 삭제되지 않는다. 대신 이 데이터는 "삭제 되었음"이라는 표시(Tombstone)를 새로운 데이터처럼 추가한다. (Sequential Write)
진짜 삭제는 Compaction 때 일어나며, 병합 과정은 다음과 같이 진행된다.
- 백그라운드에서 여러 SSTable을 열어 데이터를 병합함
- 최신 데이터 A와 구버전 데이터 A가 있으면 구버전은 버림
- 삭제 마커(Tombstone)가 있는 데이터는 이때 물리적으로 디스크에서 제거됨
Two Component 구조
Two Component LSM Tree는 가장 기본적인 형태로, 메모리에 위치한 트리(C₀ tree)와 디스크에 위치한 트리(C₁ tree)로 구성된다.
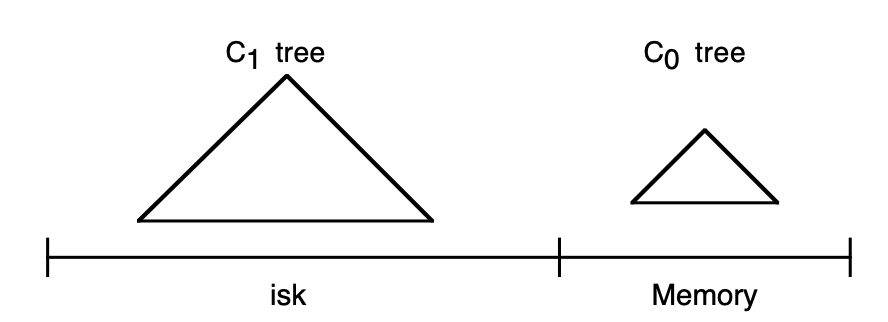
1️⃣ C₀ tree (Memory-resident)
메모리에 상주하며 빠른 삽입을 처리한다. AVL Tree나 2-3 트리와 같이 CPU 효율이 높은 자료구조를 사용할 수 있다.
2️⃣ C₁ tree (Disk-resident)
디스크에 저장되는 트리로, B-Tree처럼 디렉토리 구조를 가지지만 순차적 접근에 최적화되어 있다.
쓰기 요청 처리 방식
LSM Tree에서의 쓰기 작업은 다음과 같은 순서로 처리된다.
-
쓰기 요청이 들어온다.
-
복구(log recovery)를 위해 요청 내용을 별도의 순차 로그(sequential log)에 먼저 기록한다.
-
C₀ 트리에 요청을 반영한다. C₀는 메모리 전용 트리기 때문에 디스크 I/O가 발생하지 않는다.
-
C₀ 트리가 설정된 임계 크기(threshold)를 넘어서게 되면, 디스크에 위치한 C₁ 트리로 데이터를 옮기기 위한 Rolling Merge 작업이 시작된다.
💡 Rolling Merge란?
Rolling Merge는 C₀의 데이터를 디스크에 있는 C₁으로 점진적으로 병합하는 과정이다.
1. C₁ 트리의 leaf node들을 multi-page block 단위로 메모리에 읽어들인다.
- 일반적으로 256KB 정도의 블록 크기를 사용하여 디스크 arm 움직임을 줄인다.
2. C₁의 leaf node와 C₀의 정렬된 데이터 일부를 병합하여 새로운 leaf node를 생성한다.
- 이 병합은 보통 disk page 단위(예: 4KB)로 수행되며, 각 노드는 100% 채운다.
3. 새로운 leaf node들은 filling block에 기록되며, 일정 크기에 도달하면 디스크의 새로운 위치에 저장된다.
- 기존의 leaf node는 덮어쓰지 않고, 새로운 위치에 쓰인다. 이로써 복구 시 데이터를 잃지 않도록 한다.
4. 병합된 leaf node의 참조 정보는 C₁의 parent directory node에 반영된다.
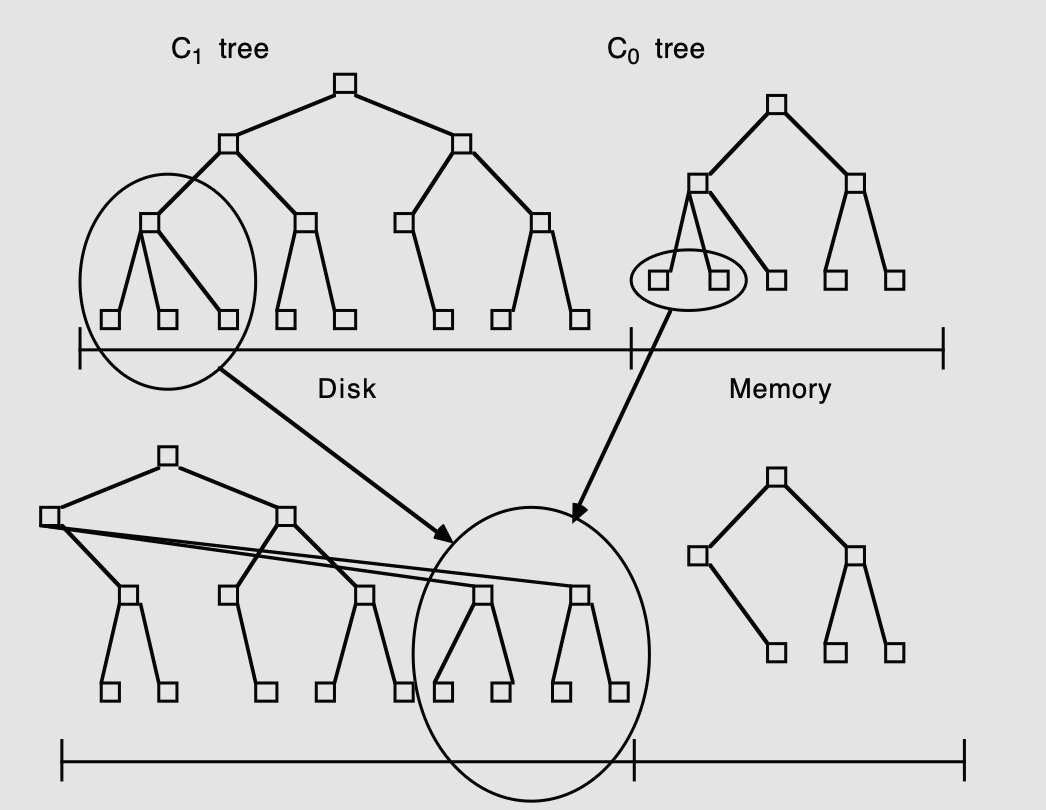
이러한 과정을 반복하면서 C₀ 트리의 크기를 줄이고, 디스크에 있는 C₁ 트리는 점차 새로운 데이터를 포함하게 된다.
그런데 왜 Overwrite하지 않을까? 🤔
Rolling Merge의 또 다른 중요한 특징은 디스크 상의 데이터를 기존 위치에 덮어쓰지 않는다는 점이다.
새로 병합된 데이터는 항상 새로운 위치에 저장되며, 기존 데이터는 무효화(invalidate) 처리만 된다.
이는 시스템이 예기치 않게 중단되었을 때에도 복구가 가능하도록 설계된 방식이다. 또한 이러한 설계를 통해 동시성 제어와 체크포인트 작성도 용이해진다.
LSM Tree가 커지는 과정
1️⃣ 쓰기 요청이 C₀ Tree에 저장됨
쓰기 요청은 가장 먼저 메모리에 있는 C₀ Tree에 반영된다. 이 구조는 디스크 I/O를 발생시키지 않으므로 매우 빠른 성능을 낸다. C₀ Tree는 B-Tree 구조일 필요도 없고, AVL Tree나 2-3 Tree와 같은 CPU 효율 중심의 메모리 트리를 자유롭게 사용할 수 있다.
시간이 지나고 쓰기 요청이 반복되면, C₀ Tree는 점점 커지게 되는데, 메모리는 한정되어 있기 때문에 일정 임계치를 초과하게 되면 데이터를 디스크로 넘겨야 한다.
2️⃣ C₀의 leftmost(가장 작은 키) 데이터를 C₁으로 병합
C₀ Tree의 크기가 임계치를 넘어서면, C₀의 leftmost leaf nodes 일부가 삭제되고 해당 데이터는 배치로 병합되어 C₁ Tree의 leaf node로 변환된다. 이 작업은 C₁ Tree의 leaf node 블록을 위한 메모리 내 multi-page buffer에서 수행된다.
논문에서는 이 과정을 Rolling Merge라고 부르며, merge는 다음과 같은 과정을 따른다.
- 디스크에 존재하는 C₁ Tree의 leaf level 블록들을 메모리로 로딩
- C₀ Tree의 leaf level 데이터와 병합
- 새롭게 병합된 leaf node들을 새로운 multi-page 블록에 저장
3️⃣ C₁ Tree의 메모리 버퍼가 가득 차면 디스크로 Flush
C₁ Tree의 leaf node들이 저장되는 filling block이 가득 차면, 해당 블록은 디스크로 플러시된다. 이때 주의할 점은 기존 데이터를 덮어쓰지 않고, 디스크의 새로운 위치에 블록 단위로 저장된다는 점이다.
이러한 방식은 디스크 seek나 rotational delay를 거의 유발하지 않으며, Random I/O가 주를 이루는 B-Tree와는 전혀 다른 방식이다.
- Filling Block : 새롭게 병합된 데이터가 저장되는 블록
- 병합이 끝나면 Filling Block이 디스크에 쓰이고, C₁ 디렉토리는 새 블록을 가리키도록 갱신됨
🤔 그럼 왜 이 방식이 빠를까?
LSM Tree의 핵심 설계는 디스크의 Random I/O를 피하는 데 있다.
B-Tree는 삽입 시마다 leaf 노드를 읽고 수정한 후 디스크에 다시 써야하므로, 디스크 arm이 무수히 움직이며 성능이 저하된다.
반면 LSM Tree는 일정량의 삽입을 모은 뒤, 한번에 병합하여 multi-page block 단위로 순차 쓰기를 수행한다.
- Random I/O 없이 순차적으로만 디스크를 쓰기 때문에 seek time이 거의 발생하지 않음
- C₁의 leaf level은 항상 100% 채워서 저장하므로 디스크 공간 활용률도 높음
LSM Tree vs B-Tree
데이터베이스에서 인덱스를 유지하려면 디스크에 지속적으로 데이터를 쓰고 읽는 작업이 필요하다. 기존의 대표적인 인덱스 구조인 B-Tree와 LSM Tree는 디스크 입출력 측면에서 어떤 차이를 보일까?
B-Tree
B-Tree에서 새로운 인덱스 항목을 삽입하려면 보통 다음의 작업이 필요하다.
- 디렉토리 노드를 따라 leaf node까지 탐색한다.
- leaf node를 수정하고 디스크에 다시 쓴다.
이때 디스크에 존재하는 node들을 읽고 쓰는 작업은 대부분 Random I/O를 발생시킨다. 특히 삽입할 위치가 무작위로 분포되어 있는 경우, 같은 leaf node가 다시 사용될 확률이 낮아 버퍼 히트율도 떨어진다.
평균적으로 한 번의 삽입당 3번의 Random I/O가 발생할 수 있다.
LSM Tree
LSM Tree는 쓰기 요청이 들어오면 메모리(C₀)에 우선 저장하고, 이후 일정량이 쌓이면 디스크(C₁)로 batch로 병합한다. 이때 디스크 접근은 multi-page block 단위로 순차 접근하므로, Random I/O에 비해 훨씬 효율적이다.
한 번의 삽입이 병합 시점에서 여러 엔트리와 함께 처리되므로 삽입당 I/O 비용이 매우 낮다.
LSM Tree에서의 동시성 처리
LSM Tree는 설계상 쓰기 성능을 극대화하기 위한 구조이지만, 다중 사용자 환경에서는 동시성 문제를 반드시 고려해야 한다.
LSM Tree에서 동시성 이슈가 발생하는 주요 지점은 다음과 같다.
1️⃣ 쓰기 요청이 들어와 C₀ Tree를 갱신할 때
2️⃣ Rolling Merge 중에 C₁ Tree의 leaf node를 읽거나 쓸 때
3️⃣ 조회 작업이 C₀, C₁ Tree를 순회할 때
이러한 상황에서 중요한 것은 데이터 정합성과 일관성을 유지하면서도 병렬 처리 성능을 확보하는 것이다.
쓰기 작업 중 동시성 처리
쓰기 작업은 메모리에 있는 C₀ Tree에만 반영되기 때문에 병목은 크지 않다. 다만 여러 쓰기 요청이 동시에 들어오면 다음과 같은 방법으로 처리할 수 있다.
- C₀ Tree 자체에 대해 Lock-based 접근 제어를 둠
- 병렬 쓰기를 허용하는 thread-safe 자료구조(concurrent AVL Tree)를 사용할 수 있음
Rolling Merge의 동시성
Rolling Merge는 C₀의 데이터를 C₁으로 병합하는 작업이다. 이 과정에서 주의할 점은 다음과 같다.
1️⃣ merge 대상인 C₁ Tree의 leaf node는 메모리로 불러와진 상태여야 함
2️⃣ 병합 결과는 디스크의 새로운 위치로 쓰여야 함
3️⃣ 기존의 leaf node는 무효화 되지만 바로 삭제되지는 않음
이 구조에서 동시성 처리는 다음과 같이 이뤄진다.
- merge가 진행 중인 C₁의 leaf node는 잠시 동안 lock이 걸림
- 그 외의 node들은 merge와 무관하므로 읽기/쓰기 작업이 병렬로 진행 가능
- 병합 결과는 항상 디스크의 새로운 위치에 저장되므로 overwrite가 발생하지 않고 읽기/쓰기 충돌을 회피할 수 있음
- merge는 점진적으로 진행되기 때문에, 전체 시스템의 latency에 미치는 영향은 작음
조회 작업 중 동시성 처리
조회 작업(find, range scan 등)은 C₀ Tree, C₁ Tree 두 컴포넌트를 순차적으로 조회한다.
조회 작업에서 중요한 것은 데이터가 아직 merge 되지 않았더라도 최신 결과를 반환해야 한다는 점이다. 이를 위해 LSM Tree는 다음과 같은 정책을 사용한다.
- 항상 C₀ → C₁ → C₂ (더 큰 저장소) 순으로 조회를 수행
- 더 앞선 컴포넌트에서 해당 key를 찾으면, 뒤에 있는 컴포넌트는 건너뜀
- C₀에는 삭제(tombstone) 정보도 포함되어 있으므로, 오래된 값이 C₁에 존재하더라도 걸러낼 수 있음
이 방식은 복잡한 동기화 없이도 조회 시 정확한 최신 결과를 보장할 수 있도록 도와준다.
📚 Skip List
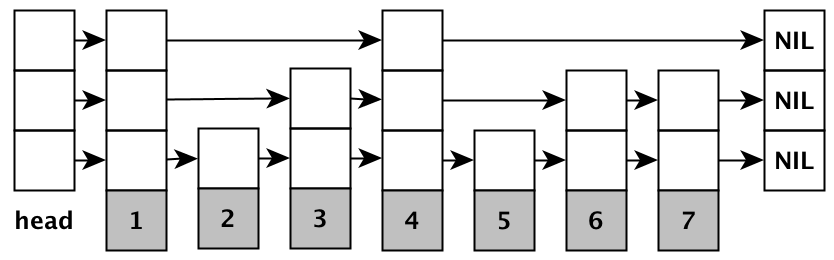
Skip List는 정렬된 연결 리스트에 다층의 인덱스를 추가하여, 탐색/삽입/삭제 시간을 O(log N)으로 단축시킨 확률적 자료구조이다. (최근 이 문제를 풀며 개념을 처음 접했다.)
key와 element 쌍으로 되어있는 리스트가 여러 레이어에 걸쳐져 있으며, 각 레이어는 + 무한대와 - 무한대를 항상 키 값으로 갖고 있다.
가장 하위 레이어인 S0은 오름차순으로 정렬되어 있으며, 하위 레이어가 상위 레이어를 포함하는 형태이다.
LSM Tree에서 데이터는 디스크(SSTable)로 내려가기 전, 메모리(MemTable)에 상주한다. 이때 데이터를 항상 정렬된 상태로 유지하기 위해 Skip List를 사용한다.
Red-Black Tree나 AVL Tree 같은 균형 이진 탐색 트리는 데이터 삽입 시 트리 전체의 균형을 맞추기 위해 회전과 재구조화가 필요하다. 이는 멀티 스레드 환경에서 넓은 범위의 잠금(Global Lock 또는 Coarse-grained Lock)을 유발한다.
반면, Skip List는 삽입/삭제 시 국소적인 노드의 포인터만 갱신하면 되므로, Lock-Free 알고리즘 구현이나 Fine-grained Lcok 적용이 용이하여 동시 쓰기 성능이 우수하다.
또한 복잡한 트리 균형 알고리즘 없이도 확률적인 레벨 할당을 통해 유사한 성능을 낸다.
자바의 Skip List
자바는 멀티스레드 환경에서 Thread safe하게 사용할 수 있는 Skip List 구현체 두 가지를 제공한다.
1️⃣ ConcurrentSkipListMap<K, V>
- Map 인터페이스 구현체 (Key-Value 쌍)
- 내부적으로 Skip List를 사용하여 Key를 기준으로 자동 정렬됨
- MemTable 구현에 적합함 (Key = PK, Value = 데이터)
2️⃣ ConcurrentSkipListSet< E >
- Set 인터페이스 구현체 (Value만 저장)
- 내부적으로 ConcurrentSkipListMap 사용
왜 HashMap이나 TreeMap 대신 ConcurrentSkipListMap을 사용할까?
| 자료구조 | 정렬 여부 | 동시성 | 용도 및 특징 |
|---|---|---|---|
| HashMap | X (무작위) | Not Safe(동기화) | 단순 캐시용. 정렬이 안 돼서 LSM Tree엔 부적합 |
| TreeMap | O | Not Safe(Lock 필요) | 정렬은 되지만, 멀티스레드 환경에서 쓰려면 synchronized를 걸어야 해서 성능이 떨어짐 |
| ConcurrentSkipListMap | O | Thread-Safe(Lock-Free) | Lock 없이(CAS 알고리즘 등) 동시성을 보장하므로, 여러 스레드가 데이터를 한번에 넣는 상황에서도 빠르고 정렬까지 유지됨 |
다음 코드는 ConcurrentSkipListMap을 사용해서 MemTable과 유사하게 구현한 것이다.
import java.util.concurrent.ConcurrentSkipListMap;
public class Main {
public static void main(String[] args) {
// 1. Skip List 기반의 Map 생성 = MemTable
// Key는 Integer(ID), Value는 String(데이터)
ConcurrentSkipListMap<Integer, String> memTable = new ConcurrentSkipListMap<>();
// 2. 데이터 삽입 (순서 뒤죽박죽으로 넣음 - Random Write)
// 멀티스레드 환경에서도 안전하게 동작함
memTable.put(3, "Data C");
memTable.put(1, "Data A");
memTable.put(5, "Data E");
memTable.put(2, "Data B");
memTable.put(4, "Data D");
// 3. 전체 조회 (결과는 Key 순서대로 정렬되어 나옴 - Sequential Read)
System.out.println("=== 전체 조회 (자동 정렬됨) ===");
memTable.forEach((key, value) -> {
System.out.println("Key: " + key + ", Value: " + value);
});
// 4. 범위 검색 (Range Scan) - DB의 핵심 기능
// Key가 2보다 크거나 같고 4보다 작은 것 조회
System.out.println("=== 범위 검색 ===");
memTable.subMap(2, 4).forEach((key, value) -> {
System.out.println("Key: " + key + ", Value: " + value);
});
// 5. 가장 작은/큰 키 조회 (Min/Max)
System.out.println("=== Min/Max 조회 ===");
System.out.println("First Key: " + memTable.firstKey()); // 1
System.out.println("Last Key: " + memTable.lastKey()); // 5
}
}
=== 전체 조회 (자동 정렬됨) ===
Key: 1, Value: Data A
Key: 2, Value: Data B
Key: 3, Value: Data C
Key: 4, Value: Data D
Key: 5, Value: Data E
=== 범위 검색 ===
Key: 2, Value: Data B
Key: 3, Value: Data C
=== Min/Max 조회 ===
First Key: 1
Last Key: 5
위와 같이 데이터를 무작위로 넣어도 Key의 순서대로 정렬되는 것을 볼 수 있다.
📌 Node<K, V>
static final class Node<K,V> {
final K key; // currently, never detached
V val;
Node<K,V> next;
Node(K key, V value, Node<K,V> next) {
this.key = key;
this.val = value;
this.next = next;
}
}
실제로 저장하려는 Key와 Value가 들어있는 객체로, 스킵 리스트의 가장 아래층(Level 0)에만 존재한다. 전형적인 단방향 연결 리스트(Singly Linked List) 형태이다.
📌 Index<K, V>
static final class Index<K,V> {
final Node<K,V> node; // 해당 위치 Node
final Index<K,V> down; // 바로 아래층의 Index
Index<K,V> right; // 같은 층의 다음 Index
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
}데이터는 없지만, 빠르게 건너뛰기 위한 정보만 가진 객체로, 밑바닥 층 위에 쌓여 있는 모든 상위 층을 구성한다. 아래로 내려가는 길 down과 오른쪽으로 이동하는 길 right를 가진다.
C++이나 다른 언어의 Skip List 구현체에서는 Index 객체 없이 Node 내부에 배열을 두어 여러 층을 관리하는 경우도 있다. 하지만 Java에서 굳이 Node와 Index를 분리한 설계를 선택한 것은 메모리 효율과 동시성 제어의 복잡도 때문이다.
1️⃣ 메모리 낭비
Skip List에서 전체 노드의 50%는 Level 0(바닥)에만 존재한다. 25%는 Level 1까지만, 12.5%는 Level 2까지만 존재한다. 만약 Node에 right, down을 다 넣게 되면, 바닥에만 있는 50%의 노드들은 null 값이 되는 필드들을 가지고 있어야 하는 것이다.
2️⃣ 동시성 제어의 어려움
Next 포인터 배열을 미리 10개까지 만들어 놓으면, 다른 스레드에서 노드의 비어있는 배열에 접근하여 NullPointerException이 발생할 수 있다. 이를 막으려면 복잡한 Lock이 필요하다.
Index 객체를 사용하면 먼저 Level 0에 Node를 넣고 그 위의 층에 Index 블록을 하나씩 CAS로 쌓는다. 그러면 다른 스레드는 현재 쌓여있는 만큼만 볼 수 있기 때문에 Lock이 없어도 된다.
또한 탐색(doGet())을 할 때는 key와 node 참조만 있으면 되는데, Index 객체는 데이터를 들고 있지 않아서 크기가 작다. CPU 캐시(L1/L2 Cache)에 Index 객체들이 더 많이 들어갈 수 있어서 탐색 속도가 빨라진다. (Cache Hit율 증가)
결국 단일 스레드거나 C++처럼 메모리 레이아웃을 직접 제어할 수 있다면 Index 객체가 없어도 된다. (실제로 Redis의 Skip List는 노드 안에 레벨 배열을 가진다.) 하지만 자바라는 언어 특성과 Concurrent 환경에서는 Node와 Index를 분리하는 방식이 메모리도 아끼고, 락 없이 구현하기에 훨씬 유리하다.
📌 findPredecessor()
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
Index<K,V> q; // 현재 내 위치 (head에서 출발)
VarHandle.acquireFence(); // 메모리 가시성 확보 (최신 데이터 읽기 보장)
if ((q = head) == null || key == null)
return null;
else {
for (Index<K,V> r, d;;) {
// 오른쪽(r)이 없을 때까지 계속 확인
while ((r = q.right) != null) {
Node<K,V> p; K k;
// r이 이미 삭제된 노드라면
if ((p = r.node) == null || (k = p.key) == null ||
p.val == null)
// CAS로 q의 오른쪽을 r에서 r.right로 바꿈
RIGHT.compareAndSet(q, r, r.right);
// 이동 로직
else if (cpr(cmp, key, k) > 0)
q = r;
else
break;
}
// 오른쪽 탐색이 끝난 후
if ((d = q.down) != null)
q = d; // 아래로 갈 수 있으면 이동
else
return q.node; // 더 내려갈 수 없으면 현재 위치 반환
}
}
}
ConcurrentSkipListMap의 핵심 메서드로, 데이터를 탐색할 때 오른쪽으로 갈 수 있을 때까지 이동하고 막히면 아래로 내려간다.
q: Skip List의 가장 높은 층, 가장 왼쪽인headVarHandle.acquireFence(): 멀티스레드 환경이므로 다른 스레드가 수정한 최신head정보를 내 CPU 캐시로 가져오라는 명령어로, Lock을 거는 것보다 훨씬 빠름p.val == null: 가려고 하는 오른쪽 노드(r)가 다른 스레드에 의해 이미 삭제된 상태라면,RIGHT.compareAndSet(q, r, r.right)를 실행해서 내비게이션 경로(index)에서r을 건너뜀cpr(cmp, key, k) > 0: 찾는key가 현재 오른쪽 노드의k보다 크면 계속 오른쪽으로 이동
📌 doGet()
private V doGet(Object key) {
Index<K,V> q;
VarHandle.acquireFence(); // 메모리 검색
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
V result = null;
if ((q = head) != null) { // head에서 시작
outer: for (Index<K,V> r, d;;) {
// 오른쪽으로 이동
while ((r = q.right) != null) {
Node<K,V> p; K k; V v; int c;
// 삭제된 노드 발견 시
if ((p = r.node) == null || (k = p.key) == null ||
(v = p.val) == null)
RIGHT.compareAndSet(q, r, r.right); // 인덱스에서 끊어버림
// 이동 로직
else if ((c = cpr(cmp, key, k)) > 0)
q = r; // 오른쪽으로 이동
// 발견 시 검색 끝
else if (c == 0) {
result = v;
break outer;
}
// 오른쪽 값이 더 클 경우 while문 탈출
else
break;
}
// 아래쪽으로 이동
if ((d = q.down) != null)
q = d;
// q.down이 null일 때(바닥일 경우)
else {
Node<K,V> b, n;
// q.node : 현재 인덱스가 가리키는 진짜 데이터 노드
if ((b = q.node) != null) {
// 옆으로 한 칸씩 이동
while ((n = b.next) != null) {
V v; int c;
K k = n.key;
// 값이 null(삭제됨)이거나, 아직 찾는 키보다 작으면
if ((v = n.val) == null || k == null ||
(c = cpr(cmp, key, k)) > 0)
b = n; // 계속 오른쪽으로 이동
// 찾는 키보다 크거나 같을 경우
else {
if (c == 0)
result = v;
break;
}
}
}
break;
}
}
}
return result;
}
doGet()은findPredecessor()와 달리 인덱스를 타다가 값을 찾으면(c==0) 즉시 리턴 => 검색 속도를 높여주는 최적화
📌 doPut()
private V doPut(K key, V value, boolean onlyIfAbsent) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
for (;;) {
Index<K,V> h; Node<K,V> b;
VarHandle.acquireFence();
int levels = 0;
if ((h = head) == null) { // head가 비어있으면 맵이 비어있는 것
Node<K,V> base = new Node<K,V>(null, null, null);
h = new Index<K,V>(base, null, null);
// CAS : head 생성
b = (HEAD.compareAndSet(this, null, h)) ? base : null;
}
else {
for (Index<K,V> q = h, r, d;;) {
while ((r = q.right) != null) {
Node<K,V> p; K k;
if ((p = r.node) == null || (k = p.key) == null ||
p.val == null)
RIGHT.compareAndSet(q, r, r.right);
else if (cpr(cmp, key, k) > 0)
q = r;
else
break;
}
if ((d = q.down) != null) {
++levels;
q = d;
}
else {
b = q.node; // 바닥 노드 도착
break;
}
}
}
if (b != null) {
Node<K,V> z = null;
for (;;) {
Node<K,V> n, p; K k; V v; int c;
if ((n = b.next) == null) {
if (b.key == null)
cpr(cmp, key, key);
c = -1;
}
else if ((k = n.key) == null)
break;
else if ((v = n.val) == null) {
unlinkNode(b, n);
c = 1;
}
else if ((c = cpr(cmp, key, k)) > 0)
b = n;
else if (c == 0 &&
(onlyIfAbsent || VAL.compareAndSet(n, v, value)))
return v;
if (c < 0 &&
// CAS : b의 다음이 n이라면 p로 바꾸기
// 여기서 CAS가 필요한 이유는 다른 스레드가 다른 노드를 먼저 넣었을 수 있기 때문
NEXT.compareAndSet(b, n,
p = new Node<K,V>(key, value, n))) {
z = p;
break;
}
}
if (z != null) {
// 랜덤 시드 생성
int lr = ThreadLocalRandom.nextSecondarySeed();
if ((lr & 0x3) == 0) { // 약 25%의 확률
int hr = ThreadLocalRandom.nextSecondarySeed();
long rnd = ((long)hr << 32) | ((long)lr & 0xffffffffL);
int skips = levels;
Index<K,V> x = null;
for (;;) {
x = new Index<K,V>(z, x, null);
if (rnd >= 0L || --skips < 0)
break;
else
rnd <<= 1;
}
if (addIndices(h, skips, x, cmp) && skips < 0 &&
head == h) {
Index<K,V> hx = new Index<K,V>(z, x, null);
Index<K,V> nh = new Index<K,V>(h.node, h, h);
// CAS : 생성한 인덱스 x를 기존 인덱스 h 옆이나 아래에 연결할 때 사용
HEAD.compareAndSet(this, h, nh);
}
if (z.val == null)
findPredecessor(key, cmp);
}
addCount(1L);
return null;
}
}
}
}📌 doRemove()
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
V result = null;
Node<K,V> b; // 타겟 바로 앞 노드
outer: while ((b = findPredecessor(key, cmp)) != null &&
result == null) {
for (;;) {
Node<K,V> n; K k; V v; int c;
if ((n = b.next) == null)
break outer;
else if ((k = n.key) == null)
break;
else if ((v = n.val) == null)
unlinkNode(b, n);
else if ((c = cpr(cmp, key, k)) > 0)
b = n;
else if (c < 0)
break outer;
else if (value != null && !value.equals(v))
break outer;
// CAS : n의 값이 현재값 v이라면 null로 변경
// 여기서도 다른 스레드가 값을 수정해버렸을 수 있기 때문에 확인
else if (VAL.compareAndSet(n, v, null)) {
result = v; // 삭제
unlinkNode(b, n); // 물리적 연결 끊기 요청
break;
}
}
}
if (result != null) {
tryReduceLevel(); // CAS : 필요한 경우 인덱스 층수 낮추기
addCount(-1L); // 개수 감소
}
return result;
}📚 Bloom Filter
Bloom Filter는 원소가 집합에 속하는지 여부를 검사하는 데 사용되는 확률적 자료구조이다. 적은 메모리 공간을 사용하여 값이 없음을 확실하게 판별할 수 있기 때문에 속도가 빠르다. 여러 해시 함수로 데이터를 비트 배열에 매핑하여 사용되며, 정확도보다는 속도와 메모리 효율성이 중요한 상황에서 유용하다.
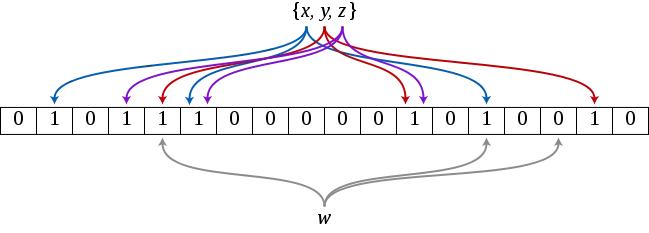
값을 테이블에 추가하는 삽입과 특정 값이 테이블 안에 존재하는지 확인하는 확인, 두 가지 동작이 가능하다. (제거는 불가능하다.)
데이터를 실제로 디스크에서 읽기 전에 Bloom Filter를 먼저 조회한다.
-
Bloom Filter가 절대 없다고 판단하면 해당 SSTable은 절대 열어보지 않음
-
Bloom Filter가 있을지도 모른다고 판단하면 그때 SSTable을 디스크에서 읽음
LSM Tree 구조상 읽기 요청 시 여러 개의 SSTable 파일을 탐색해야 할 수 있는데, 이는 디스크 I/O 비용을 발생시키기 때문에 Bloom Filter를 사용하면 디스크 접근을 최소화 할 수 있는 것이다.
False Positive (거짓 양성)
Bloom Filter는 특정 값을 여러 해시 함수에 넣어 결과값들을 임의의 테이블에 인덱싱하여 해당되는 모든 값이 1인지 확인한다.
이 과정에서 해시 함수는 기본적으로 충돌의 가능성이 있기 때문에 Bloom Filter에는 False Positive의 가능성이 있다. 다만 반대로 False Negative의 가능성은 없다.
해시 함수들은 기본적으로 여러 개를 가지는데 임의의 테이블 크기, 넣어야 하는 자료의 크기, 해시 함수의 수에 따라 거짓의 확률이 정해진다. 그래서 요구하는 거짓 양성률이 있다면 넣어야 하는 자료의 크기를 고려해서 테이블의 크기와 해시 함수의 수를 정하는 편이다.
fp를 낮추면 정확도가 올라가는 대신 메모리를 많이 차지하게 되며, fp를 높이면 정확도는 떨어질 수 있지만 메모리를 아낄 수 있다.
Space Efficiency (공간 효율성)
해시 함수와 비트 배열만을 사용하므로 메모리 사용량이 매우 적다.
튜닝 포인트
비트 배열의 크기를 늘리고 해시 함수의 개수를 조정하여 False Positive 비율을 낮출 수 있다.
HDD와 같이 Random Read 비용이 비싼 환경에서는 메모리 사용량을 늘리더라도 False Positive 비율을 낮게(예: 0.01) 설정하여 디스크 접근을 최소화하는 것이 유리하다.
📌 출처