📚 Stack
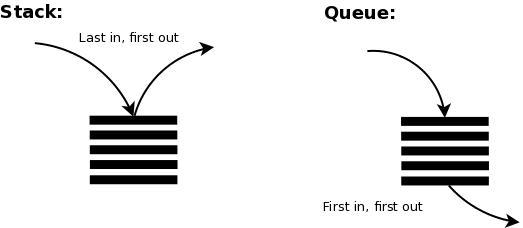
Stack은 Last In First Out(LIFO) 방식으로 동작하는 선형 구조로, 나중에 들어온 데이터가 먼저 나간다.
이러한 특징으로 웹 브라우저에서 뒤로 가기나, 실행 취소(undo), 괄호 유효성 검사 등에 쓰인다.
🤔 근데 Java 공식 문서에서는 왜 Stack을 쓰지 말라고 할까?
Stack의 문서에서는 Deque 인터페이스(ArrayDeque)를 Stack 클래스 대신 사용하는 것을 권장하고 있다.
A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class. For example:
Deque<Integer> stack = new ArrayDeque<Integer>();
public class Stack<E> extends Vector<E> {
public Stack() {}
public E push(E item) {}
public synchronized E pop() {}
public synchronized E peek() {}
public boolean empty() {}
public synchronized int search(Object o) {}
}Java의 Stack은 Vector를 상속하고 있다.
Vector는 ArrayList처럼 List 인터페이스를 구현한 컬렉션 프레임워크이며, synchronized를 제외하고는 ArrayList와 거의 동일하다.
synchronized
스레드를 안전하게 사용하기 위해 제공하는 자바의 예약어로, 메서드에 선언하거나 블록 형태로 사용할 수 있다. 여러 스레드가 동시에 접근하는 경우, 먼저 접근한 스레드의 처리가 끝날 때까지 다른 스레드의 접근을 제한한다.
synchronized로 인한 성능 저하?
public synchronized E get(int index) {}
public synchronized void addElement(E obj) {}
public synchronized void removeElementAt(int index) {}Vector는 거의 모든 메서드에 synchronized를 사용하기 때문에 간단하게 조회만 하는 경우에도 동기화로 인해 성능 저하가 발생한다.
위의 Stack 클래스를 확인해보면 알듯이 Stack도 synchronized를 사용해서 동기화 처리를 하는데, 이때 내부적으로 Vector가 제공하는 메서드를 사용함으로써 이중으로 동기화 처리가 된다.
| Stack 메서드 | 내부적으로 사용되는 Vector 메서드 |
|---|---|
| push(E item) | addElement(E obj) |
| E pop() | removeElementAt(int index) |
| E peek() | elementAt(int index) |
때문에 단일 스레드 환경에서 Stack을 사용하게 되면, 불필요한 동기화 작업으로 인해 성능 저하를 피할 수 없게 된다.
Java의 Stack은 사실 LIFO가 아니다?
Stack은 후입선출 구조로 이루어져 있어 최상단을 통해서 요소가 저장되고 나가야 한다.
하지만 Stack은 Vector가 제공하는 메서드를 통해 특정 인덱스에 데이터를 추가하거나 제거할 수도 있다.
| Type | Method Description |
|---|---|
| void | add(int index, E element) |
| void | removeElementAt(int index) |
for (int i = 1; i <= 10; i++) {
stack.push(i);
}
stack.add(3, 0);
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
}결과를 보면 3번째 인덱스에 0이 저장된 것을 볼 수 있다.
10 9 8 7 6 5 4 0 3 2 1
📚 Deque
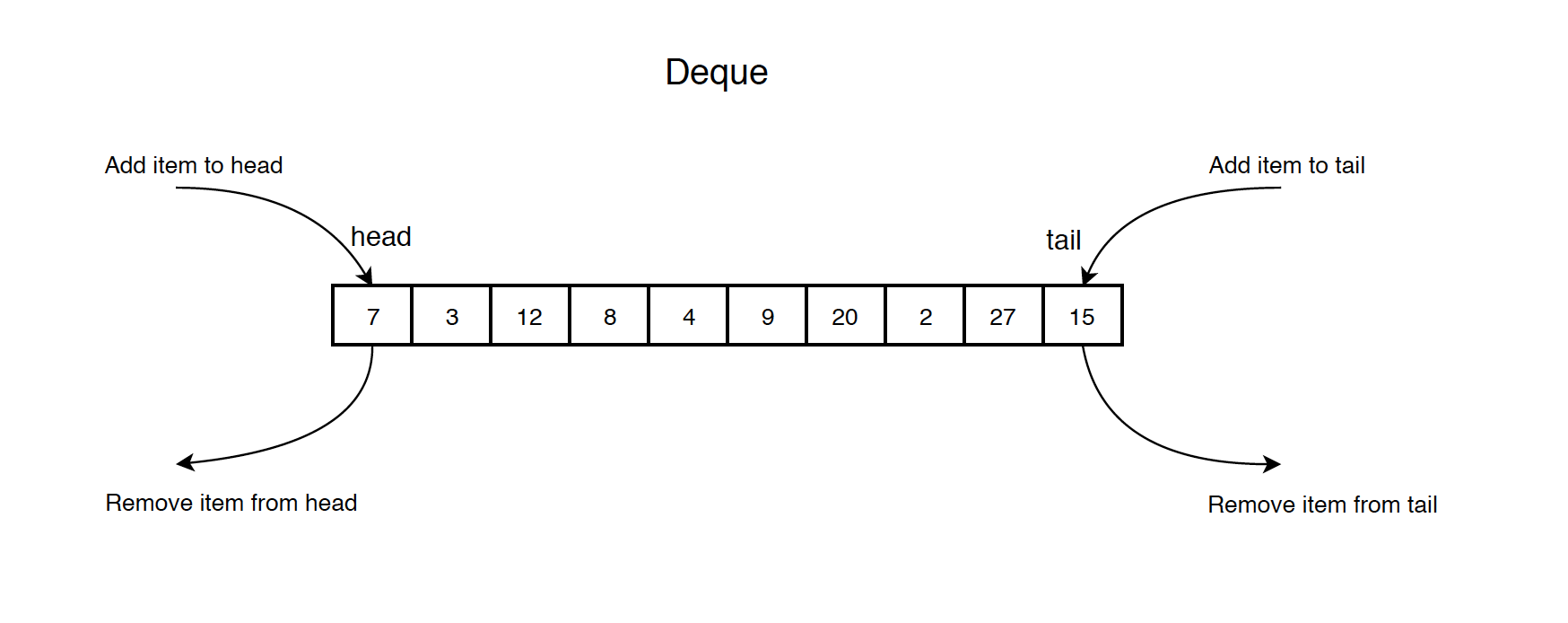
Deque는 양쪽 끝에서 요소를 저장하거나 제거할 수 있는 인터페이스로, Double-Ended Queue의 줄임말이다.
Deque의 문서에서도 Stack 대신 Deque를 사용할 것을 권장한다.
Deques can also be used as LIFO (Last-In-First-Out) stacks. This interface should be used in preference to the legacy Stack class.
Deque는 시작 지점에서 요소를 저장하고 제거하는 방식으로 Stack처럼 사용할 수 있으며, 당연히 Queue로도 사용될 수 있다.
Stack 메서드와 동등한 Deque 메서드
| Stack Method | Equivalent Deque Method |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | getFirst() |
Queue 메서드와 동등한 Deque 메서드
| Queue Method | Equivalent Deque Method |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
List 인터페이스와는 달리 요소의 인덱스 접근을 지원하지 않아 특정 위치에 데이터를 저장하거나 제거할 수 없다.
📚 Queue
Queue는 Stack과 반대로 First In First Out(FIFO) 방식으로 동작하며, 가장 먼저 들어온 데이터가 먼저 나간다.
따라서 프린터의 작업 대기열이나 BFS 탐색 시 사용된다.
Stack 구현은 ArrayList vs LinkedList?
📌 Stack 주요 메서드
push()pop()peek()
이러한 메서드들은 리스트의 끝에서 작동하기 때문에 ArrayList가 LinkedList에 비해 더 빠르고 효율적이다.
ArrayList와 LinkedList 모두 push(addLast), pop(removeLast) 연산에 걸리는 시간복잡도는 같지만, (참고로 ArrayList의 LikedList는 노드마다 데이터 + next + prev 포인터를 가지고 있어 메모리의 낭비가 크다.push는 Amortized O(1)이다)
또한 ArrayList는 연속된 메모리지만 LinkedList는 비연속 메모리, 즉 요소들이 메모리에 여기저기 흩어져 있다.
CPU는 메모리 접근 속도를 빠르게 하기 위해 캐시를 사용하며, 이때 중요한 개념은 공간 지역성(spatial locality)이다.
💡 공간 지역성
프로그램이 어떤 메모리 주소를 참조하면, 그 주소와 가까운 메모리도 곧 접근할 가능성이 높다는 성질
CPU 캐시는 연속된 메모리를 한 번에 블록 단위로 로드하는데, 비연속 메모리 구조일 경우 요소들이 메모리에 여기저기 흩어져 있어 CPU 캐시가 예측할 수 없어 매번 메모리를 새로 로딩해야 한다. 이는 캐시 미스를 발생시키고 결국 성능 저하를 불러온다.
또한 비연속 메모리 구조는 객체 하나하나가 따로 생성되기 때문에 많은 수의 객체의 포인터가 필요하며, 이는 GC가 힙에 있는 객체를 모두 추적해야 하기 때문에 GC의 부담이 커질 수 있다.
✔️ 따라서 Stack 구현에는 ArrayList를 권장!
Queue 구현은 ArrayList vs LinkedList?
📌 Queue 주요 메서드
offer()poll()peek()
ArrayList와 LinkedList 모두 뒤에 요소를 추가하는 시간복잡도는 같지만, ArrayList는 앞 요소를 제거할 때 O(N)이기 때문에 O(1)인 LinkedList가 더 효율적이다.
ArrayList로 Queue를 구현한다면, poll() 연산 시 가장 앞의 요소를 제거하고 나머지 요소들을 모두 한 칸씩 앞으로 복사해야 한다. 이는 요소 수가 많아질수록 성능이 급격히 감소할 것이다.
반면 LinkedList는 맨 앞이나 뒤에 삽입하거나 삭제하는 연산의 시간복잡도가 모두 O(1)이기 때문에 (포인터만 수정하면 된다) Queue를 구현하기에 최적화되어 있다!
✔️ 따라서 Queue 구현에는 LinkedList를 권장!
(참고로 LinkedList 보다는 ArrayDeque를 사용하는 것이 더 좋다. ArrayDeque는 LinkedList보다 더 빠르고 메모리 효율 측면에서 좋다.)
Deque의 구현체는 ArrayDeque vs LinkedList?
📌 Deque 주요 메서드
addFirst(e),removeFirst(): 맨 앞 삽입/삭제addLast(e),removeLast(): 맨 뒤 삽입/삭제peekFirst(),peekLast(): 맨 앞/뒤 값 반환
📚 ArrayDeque
비교하기 전에 먼저 ArrayDeque에 대해 알아보자.
ArrayDeque의 문서에도 Stack으로 사용하면 Stack 클래스보다 빠르며, Queue로 사용하면 LinkedList 클래스보다 빠르다고 나와있다.
This class is likely to be faster than Stack when used as a stack, and faster than LinkedList when used as a queue.
transient Object[] elements; // 데이터 저장 배열
transient int head; // 첫번째 요소의 인덱스
transient int tail; // 마지막 요소의 다음 인덱스ArrayDeque은 위와 같이 구성되어 있으며, ArrayList와는 head, tail처럼 포인터가 있다는게 다른 점이다.
삽입 연산 (addLast)
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[tail] = e;
if (head == (tail = inc(tail, es.length)))
grow(1);
}
static final int inc(int i, int modulus) {
if (++i >= modulus) i = 0; // tail이 배열 끝에 도달하면 0으로 돌아감
return i;
} 마지막 요소의 다음 인덱스에 삽입을 한 후, inc() 메서드에서 tail을 하나 증가한다. 이때 tail이 배열 끝에 도달했으면, 0으로 돌아간다.
이후 head와 tail이 같다면, 즉 배열이 가득 찼다면 grow() 메서드로 내부 배열을 확장시킨다.
삭제 연산 (removeFirst)
public E removeFirst() {
E e = pollFirst();
if (e == null)
throw new NoSuchElementException();
return e;
}
public E pollFirst() {
final Object[] es;
final int h;
E e = elementAt(es = elements, h = head);
if (e != null) {
es[h] = null;
head = inc(h, es.length); // head 한 칸 이동 (가장 앞의 요소를 삭제했기 때문)
}
return e;
}pollFirst() 메서드를 통해 가장 앞에 있는 요소가 null이 아니라면 null로 설정하고, inc() 메서드로 head를 한 칸 이동한다.
내부 배열 확장 (grow)
private void grow(int needed) {
final int oldCapacity = elements.length;
int newCapacity;
// 현재 크기가 64 미만이면 2만 더하고 64 이상이면 1.5배 확장
int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);
// jump가 needed보다 작거나 새 용량이 MAX_ARRAY_SIZE를 초과하는 경우 newCapacity() 호출
if (jump < needed
|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)
newCapacity = newCapacity(needed, jump);
final Object[] es = elements = Arrays.copyOf(elements, newCapacity);
// 원형 배열이 꼬여있는(wrapped-around) 상태거나 배열이 가득 찬 상태인지 확인
if (tail < head || (tail == head && es[head] != null)) {
int newSpace = newCapacity - oldCapacity;
/**
* 확장된 배열에 복사하면서 뒤쪽으로 옮김
* 예) [C] [D] [ ] [ ] [ ] [ ] [A] [B]
* 상태에서 배열을 확장하면
* [C] [D] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [A] [B]
*/
System.arraycopy(es, head,
es, head + newSpace,
oldCapacity - head);
for (int i = head, to = (head += newSpace); i < to; i++) // head 이동
es[i] = null; // 빈 자리 null 처리
}
}
private int newCapacity(int needed, int jump) {
final int oldCapacity = elements.length, minCapacity;
if ((minCapacity = oldCapacity + needed) - MAX_ARRAY_SIZE > 0) { // 설정한 배열 최대 크기를 초과하면
if (minCapacity < 0) // 오버플로우 발생
throw new IllegalStateException("Sorry, deque too big");
return Integer.MAX_VALUE; // Integer.MAX_VALUE 리턴
}
// 넣으려는 요소 수가 jump를 초과하면 (oldCapacity + needed) 리턴
if (needed > jump)
return minCapacity;
// (oldCapacity + jump)가 MAX_ARRAY_SIZE보다 작다면
return (oldCapacity + jump - MAX_ARRAY_SIZE < 0)
? oldCapacity + jump // (oldCapacity + jump) 리턴
: MAX_ARRAY_SIZE; // 아니라면 MAX_ARRAY_SIZE 리턴리턴
}★ grow() 메서드에서 넘겨주는 needed는 항상 1이기 때문에 1. oldCapacity가 너무 커서 jump가 0이 되거나 2. needed보다 jump가 큰 상황에서도 배열 크기가 MAX_ARRAY_SIZE에 가까울 경우에만 newCapacity를 호출한다.
이러한 과정을 거쳐서 ArrayDeque는 내부 배열을 원형으로 유지하는 것이다!
ArrayDeque
- 내부적으로 원형 배열 사용 : 데이터 접근이 캐시 친화적으로 삽입/삭제 연산이 빠름 (배열 확장 시에만 O(N))
- 원형 큐(circular buffer) 구현 : 포인터를 회전시키는 방식으로 배열 재활용하여 메모리 효율성 좋음
LinkedList
- 삽입/삭제는 항상 O(1)이지만, 메모리 낭비가 심하고 GC 부담이 큼
- 노드 기반으로 캐시 지역성이 낮음
✔️ 따라서 Deque 구현에는 ArrayDeque를 사용하는 것이 좋다!
그리고 알고 있으면 좋은 것들!
1. for(int num : stack) { System.out.print(num); }이 LIFO가 보장될까?
결론부터 말하면, 보장되지 않는다.
Stack은 Vector를 상속하며, Vector의 iterator()는 다음과 같이 정의되어 있다.
public synchronized Iterator<E> iterator() {
return new Itr();
}Itr는 내부적으로 index 0부터 순차적으로 순회하기 때문에 (Itr의 cursor가 0으로 초기화 됨) Stack의 iterator()는 스택의 순서인 LIFO를 반영하지 않는다.
💡 LIFO로 순회하고 싶다면 while(!stack.isEmpty())(권장)와 pop()을 사용하거나, 역순으로 순회하면 된다.
while (!stack.isEmpty()) {
System.out.print(stack.pop() + " ");
} for (int i = stack.size() - 1; i >= 0; i--) {
System.out.print(stack.get(i) + " ");
}
2. for(int num : queue) { System.out.print(num); }이 FIFO가 보장될까?
결론부터 말하자면, Queue는 인터페이스이기 때문에, Queue 구현체가 무엇이냐에 따라 달라진다.
일반적으로 사용하는 LinkedList, ArrayDeque, ConcurrentLinkedQueue는 iterator()가 FIFO 순서를 따르도록 구현되어 있기 때문에 for-each문에서 FIFO가 보장된다.
3. for(int num : deque) { System.out.print(num); }는 어떤 순서로 출력될까?
이 경우에도 Deque는 인터페이스이기 때문에, Deque 구현체가 무엇이냐에 따라 달라진다.
대부분의 상황에서 쓰는 ArrayDeque이나 LinkedList를 Deque로 선언한다면, FIFO 순서대로 출력된다.
★ 역순으로 출력하고 싶다면 descendingIterator()를 사용하면 된다!
📖 더 알아보면 좋을 것들
- ConcurrentLinkedQueue에 대해서