
📚 동시성 제어
여러 스레드가 공유 메모리에 접근할 때, 한 스레드의 작업이 다른 스레드에게 언제, 어떻게 보일까.
컴퓨터는 성능 최적화를 위해 CPU 캐시를 사용하고, 컴파일러는 코드 순서를 재배치한다. 이 때문에 여러 스레드가 동시에 작동하면 한 스레드가 수정한 값이 다른 스레드에게 즉시 보이지 않거나, 예상과 다른 순서로 실행될 수 있다.
📌 happens-before guarantee
메모리 모델의 핵심 개념으로, 여러 스레드가 동시에 작동할 때 A 작업이 B 작업보다 반드시 먼저 일어났다고 보장하는 순서의 규칙이다.
멀티 스레드 환경에서 스레드 간의 메모리 정합성을 보장하는 논리적 순서의 규칙이며, 대표적인 happens-before 관계는 다음과 같다.
1️⃣ 동일 스레드 내 코드 순서
int x = 1;
int y = x + 1;- 한 스레드 안에서는 위 코드는 순차적으로 실행되며, happens-before 관계 성립
2️⃣ synchronized의 unlock → lock
synchronized(lock) {
shared++;
}
synchronized(lock) {
System.out.println(shared);
}- 첫 블럭에서의 변경 사항은 두 번째 블럭에서 반드시 보임
3️⃣ volatile write → volatile read
volatile int flag = 0;
// Thread A
flag = 1;
// Thread B
if (flag == 1) {
// 반드시 flag == 1로 보인다
}volatile은 가시성(visibility)을 보장하기 때문에 메모리 정합성이 유지됨
4️⃣ Thread.start() 이전 작업 → run() 내부 작업
shared = 42;
Thread t = new Thread(() -> {
System.out.println(shared); // 42 보장
});
t.start();5️⃣ Thread.join() → 해당 스레드 종료 이전 작업
Thread t = new Thread(() -> {
shared = 42;
});
t.start();
t.join();
System.out.println(shared); // 42가 반드시 보임6️⃣ final 필드 초기화 → 참조 가능 시점
class Person {
final String name;
Person(String name) {
this.name = name;
}
}- 생성자에서 초기화된 final 필드는 해당 객체가 다른 스레드에서 참조 가능해진 이후에도 안전하게 읽을 수 있음(단, escape가 없는 경우에만 보장)
happens-before가 성립되어야만 A 스레드에서 변경한 값을 B 스레드가 안전하게 읽을 수 있음을 보장한다. 즉, 동기화가 이루어졌다고 말할 수 있는 이론적 기반인 것이다.
📌 volatile
Synchronized에서 잠깐 다뤘던 volatile은, 아래와 같이 변수 선언 시에 사용하는 키워드이다. 아래는 Double-Checked Locking 코드이다.
public class Singleton {
private static volatile Singleton instance; // volatile 키워드 필수
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) { // (1) 1차 검사 (락 없이)
synchronized (Singleton.class) { // (2) 락 획득
if (instance == null) { // (3) 2차 검사
instance = new Singleton(); // (4) 인스턴스 생성
}
}
}
return instance;
}
}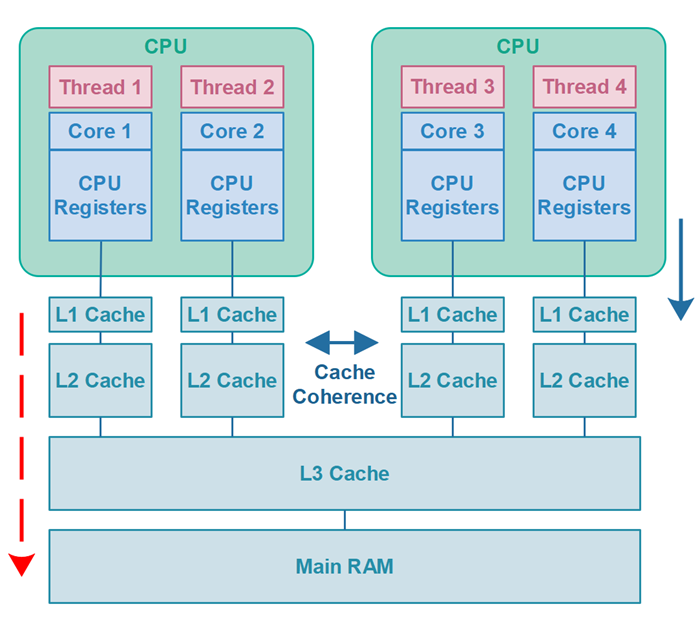
💡 volatile의 사용 이유를 이해하기 위해서 먼저 메모리 구조를 살펴보자.
CPU 내에는 성능 향상을 위해서 L1 Cache가 내장되어 있다. CPU 코어는 메모리에서 읽어온 값을 캐시에 저장하고, 캐시에서 값을 읽어서 작업한다.
따라서 값을 읽어올 때 우선 캐시에 해당 값이 있는지 확인하고 없는 경우에만 메인 메모리에서 읽어온다. 이 과정에서 메모리에 저장된 변수의 값이 변경되었는데도 캐시에 저장된 값이 갱신되지 않아, 메모리에 저장된 값과 달라지는 경우가 발생한다.
이와 같은 동기화 문제를 방지하는 것이 volatile 키워드인 것이다.
- volatile로 선언된 변수가 있는 코드는 최적화되지 않음
- volatile 키워드는 변수를 메인 메모리에 저장하겠다고 명시하는 것
- 변수의 값을 읽을 때마다 CPU 캐시에 저장된 값이 아닌, 메인 메모리에서 읽음
volatile에도 문제가 있는데, 멀티 스레드 환경에서 여러 스레드가 Write 작업을 하는 상황일 때 경쟁 상태(race condition)를 해결할 수 없다. 이 경우에는 synchronized를 사용해서 원자성을 보장해야 한다.
📌 CAS(Compare-And-Swap)과 Atomic
CAS 알고리즘은 멀티스레드 환경에서 동시성 제어를 위해 사용되는 원자적 연산이다. 여러 스레드가 동시에 값을 수정하려고 할 때 발생할 수 있는 경쟁 상태를 방지하는 데 효과적이다.
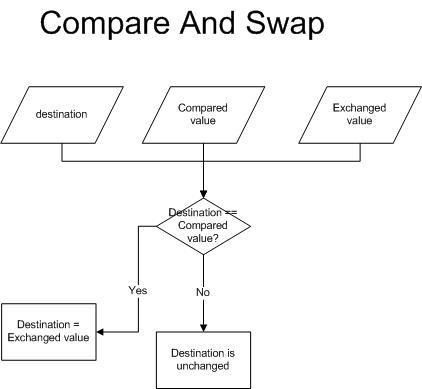
- 기존 값 Compared value와 변경할 값 Exchanged value 전달
- 기존 값이 현재 메모리가 가지고 있는 값 Destination과 같다면 변경할 값을 반영하고 true 반환
- 반대로 기존 값이 현재 메모리가 가지고 있는 값과 다르다면 값을 반영하지 않고 false 반환
AtomicInteger 같은 Atomic 자료형이 내부적으로 이 CAS를 사용한다.
AtomicInteger.compareAndSet()
public final boolean compareAndSet(int expectedValue, int newValue) {
return U.compareAndSetInt(this, VALUE, expectedValue, newValue);
}참고로 compareAndSetInt()는 Unsafe의 메서드로 다음과 같다.
@IntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset,
int expected,
int x);native 키워드가 붙은 compareAndSetInt()는 자바가 아닌 네이티브 코드를 호출한다. CAS는 1. 읽기 + 비교 + 쓰기 2. 단 한 CPU 명령으로 수행 3. 인터럽트/컨텍스트 스위치 중에도 깨지지 않아야 함과 같은 조건을 만족해야 하기 때문에, 자바 언어 차원에서 구현이 불가능하다. CPU의 지원이 필요하며 따라서 native여야 하는 것이다.
AtomicInteger.compareAndSet()의 실제 흐름
AtmoicInteger.compareAndSet()->VarHandle또는Unsafe호출 -> JVM native method -> CPU CAS instruction
CAS 알고리즘이 여러 스레드에서 올바르게 동작하려면, 현재 값을 비교하고 새 값을 쓰는 과정이 모든 스레드에게 일관되게 보여야 한다.
Atomic 자료형 내의 값은 private volatile int value와 같이 volatile로 선언되어 가시성을 확보하고, CAS 연산 자체는 CPU의 특별한 명령어를 통해 원자성을 보장받는다. 이 모든 과정이 happens-before 규칙을 만족하도록 설계되어, 락 없이도 안전한 값 변경을 보장한다.
🔎 출처
