Densely Connected Convolutional Networks
https://arxiv.org/pdf/1608.06993v5
Author:
Gao Huang∗, Zhuang Liu∗, Laurens van der Maaten, Kilian Q. Weinberger

최근 연구 결과에 따르면 입력에 가까운 층과 출력에 가까운 층간의 짧은 연결이 포홤될 경우, Convolution network가 훨씬 더 깊고, 정확하며, 훈련에 효율적일 수 있다고 한다.
본 논문의 저자들은 Dense Net을 소개하며, 이는 각각의 층을 모든 다른 층에 feed forward fashion 형태로 연결한 것을 설명한다.
전통적인 합성곱 신경망은 L개의 층이 있으면 L개의 연결이 있지만, 이 Network는
개의 직접 연결이 있다. 각각의 층에 대해 이전 층의 특성맵은 입력으로 사용되며 자체 특성맵은 이후의 모든 층에 대한 입력으로 사용된다고 한다.
DenseNet은 Vanishing-gradient 문제를 완화시키고, feature 전파를 강화, 특성 재사용을 장려하며, 파라미터 수를 크게 줄인다.
Introduction
CNN의 깊이가 더 깊어지면서 새로운 연구 문제 발생했다. 이는 input이나 gradient가 많은 층을 통과하면서 이들이 사라질 수 있다는 문제이며, 최근 많은 연구들이 이 문제를 다루었다. 대표적으로 ResNet과 FractalNet은 이러한 문제를 다루었고 이 두 논문의 공통점은 이전층과 이후 층을 연결하는 short paths를 만들었다는 점이라고 한다.
이 논문에서는 네트워크 층 간의 정보 흐름을 극대화하기 위해 모든층을 서로 직접 연결하는 단순한 연결 패턴에 대한 insight를 제공하는 구조를 제안했다.
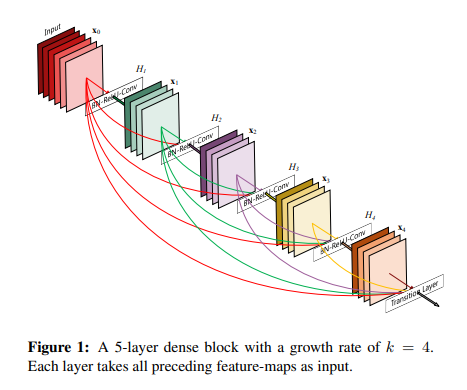
본 논문에서는 ResNet처럼 특징들을 다음 계층으로 전달하기 전에 더해주지 않는다는 것을 말하며 이 그림처럼 단순히 연결해준다고 말한다.
다시말해, L 계층 네트워크에 대해 기존 네트워크들처럼 L개가 아닌 개의 연결을 가진다고 한다.
이를 본 논문에서는 밀집 합성곤 네트워크(DenseNet)이라고 부른다.
이러한 DenseNet은 중복되는 특징맵을 재학습할 필요가 없다고 하여 Covolutional network에 비해 매개변수가 덜 필요하다고 말한다.
[정리]
DenseNet장점
1)매개변수 효율
2)정보와 경사의 흐림이 개선되어 훈련이 편하다.
3)작은 크기의 훈련 집합에 대해 과적합을 방지
DenseNet
컨볼루션 네트워크를 통해 전달되는 단일 이미지x0이 있다고 가정하면, 네트워크는 L 개의 계층으로 구성되며, 각 계층은 계층의 순서 l에 대해 비선형 변환 는 배치 정규화, ReLU, Pooling 또는 Convolution과 같은 연산의 복합 함수일 수 있다고한다.
이때 l번째 계층의 출력을 이라고 표기한다고 한다.
ResNet은 이 식에서 Identity function 과 output이 합해지기 때문에 network의 정보 흐름을 방해할 수 있다고 말했다.
본 논문에서는 Dense connectivity을 소개한다.
층 사이의 정보 흐름을 향상시키기 임의의 계층에서 그 이후의 모든 계층 간의 직접 연결을 제안한다.
수식으로 나타낸다.
이때 은 계층 0, …. l - 1에서 생성한 특징맵들을 연결한 것을 의미한다.
composite function
을 세개의 연속된 수행을 하는 합성함수로 정의를 하는데 이는 BN(Batch normalization) ReLU, 3X3Conv이다.
Pooling 계층
이 식에서 사용되는 연결작업은 특성맵의 크기가 변경되면 사용할 수가 없다고 한다. 그러나 Convolutional networks의 필수적인 부분은 down sampling 층이며, 이는 특성맵의 크기를 변환 시켜준다.
본 논문에서는 multiple densely connected dense blocks로 network를 나누었고 실험에서 사용한 transition층은 batch normalization 층과 1x1 convolutional layer 이후에 따라오는 2x2 average pooling 층으로 구성되어 있다.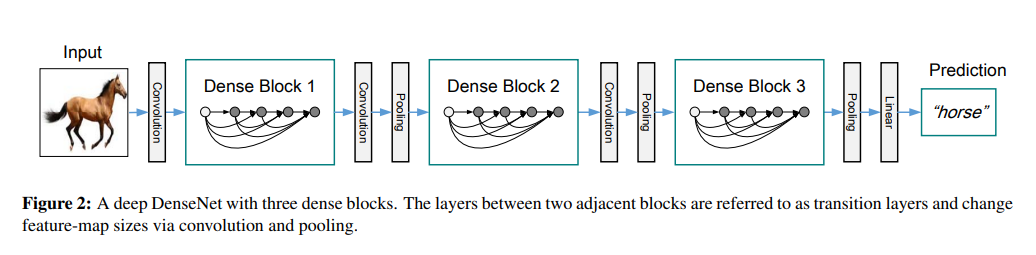
Growth rate
만약 이 k개의 특성맵을 생성한다면 번재 계층은 개의 입력 특징맵을 가지고 는 input층의 채널의 수라고 한다.
DenseNet과 다른 네트워크의 차이라면 DenseNet은 와 같이 매우 좁은 계층이 가능하다는 것이라고 한다.
Bottleneck layer
1×1 합성곱은 입력 특징맵의 개수를 줄이기 위해 각 3×3 합성곱 이전에 추가될 시 Bottleneck layer가 될 수도 있으므로 연산 효율성을 개선할 수 있다고 한다.
논문에서는 이 설계가 DenseNet에 상당히 효과적임을 발견해 이러한 병목 계층을 추가한 이는 DenseNet-B라 부른다고 한다.
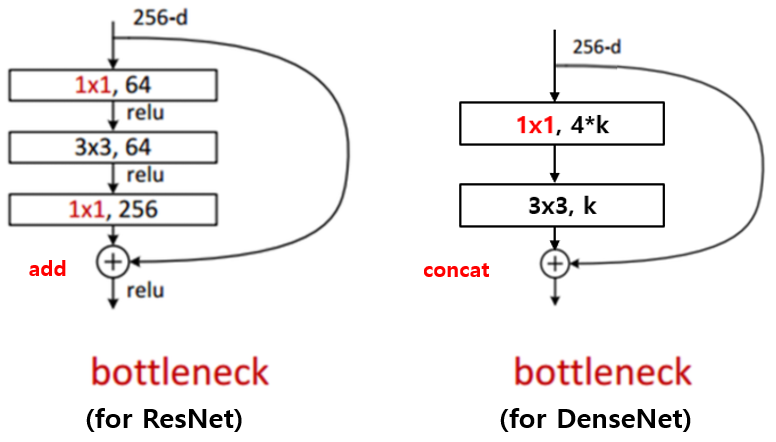
또한, DensNet의 Bottleneck layer는 1x1 convolution 연산을 통해 4 x growth rate 개의 feature map을 만들고 그 뒤에 3x3 convolution을 통해 growth rate개의 feature map으로 줄여준다. (4 x growth rate의 4배라는 수치는 hyper-parameter이고 이에대한 자세한 설명은 논문에서 하지 않았다.)
Compression
Bottleneck Layer와 마찬가지로 모델의 Compactness를 위해 Transition Layer에서 전달되는 feature map의 개수를 줄일 수 있다고 한다.
만약 Dense block이 개의 특징맵을 갖는다면 다음 전환 계층은 개의 출력 특징맵을 생성하게 한다. 이때 이며, 을 압축계수라 부른다. 만약 라면 전환 계층에서 특징맵의 개수는 변하지 않는다. 저자들은 인 DenseNet을 DenseNet-C라 부르며, 실험 때는 로 설정해주었다. 병목과 전환 계층이 둘 다 인 모델을 저자들은 DenseNet-BC라 부른다.
Implementation Details
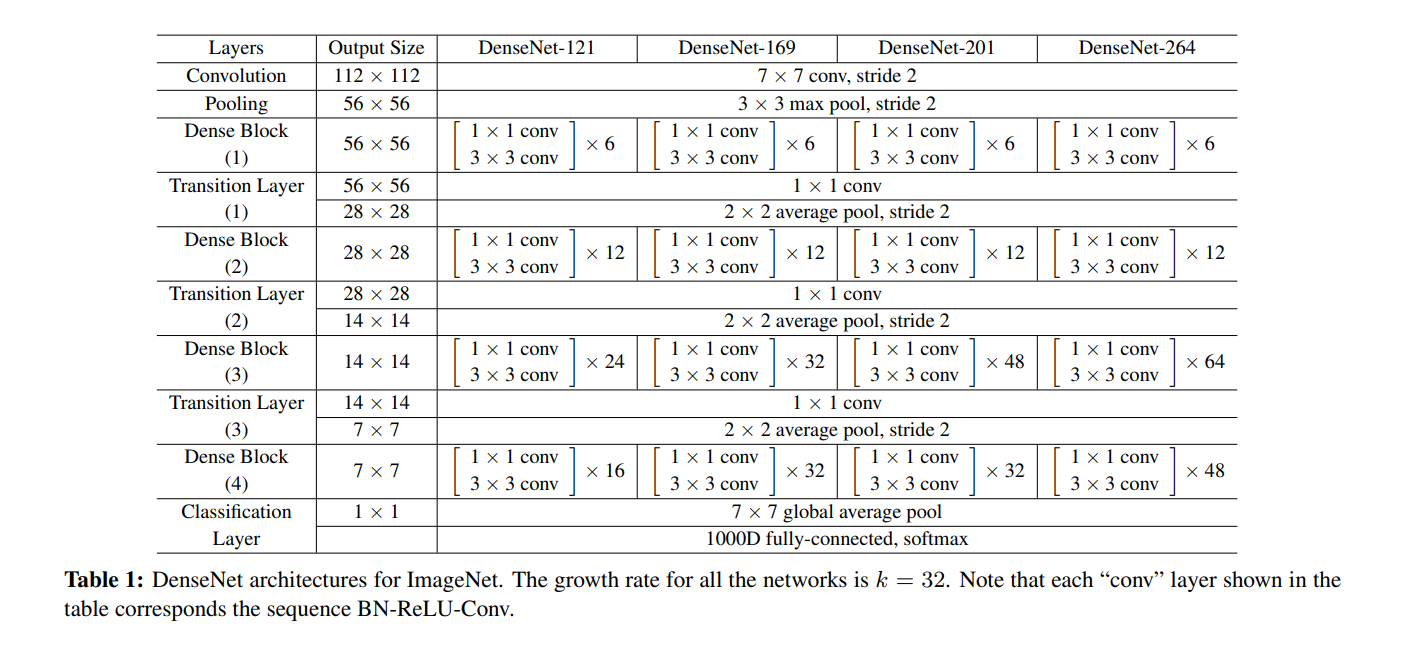
다음 표는 Dense Block을 포함하여 DenseNet의 전체 구조를 나타낸 것입니다. 네트워크를 Dense Block으로 쪼갠 목적은 Pooling 연산이 필요한 곳에 Pooling Layer, Transition Layer1, Transition Layer2, Transition Layer3, Classification Layer가 존재하게 하기 위함이라고 한다.
Pytorch 코드구현: https://github.com/namduhus/DenseNet
Pytorch: 2.5.1
IDE: VSCode, Pycharm
GPU: CUDA 12.1
