1) 연산자 활용 조회
- age<8 경우
db.cols.find({age : { $lt : 8 }})- age<= 8 경우
db.cols.find({age : { $lte : 8 }}) //less than equal
- age =/ 8 경우
db.cols.find({age : { $ne : 8 }}) //not equal- db.cols.find({age : { $nin : [8] }}) //배열로
- 15 <= age <=20
db.cols.find({
$and: [ //둘다 만족, 둘중 하나만 만족시 $or 사용
{ age: { $gte: 15 } },
{ age: { $lte: 20 } }
]
});
//배열로
- name에 어디든 "김" 들어가는 경우
db.cols.find({name: {$regex : "김"} })
//문자열을 정규 표현식(Regex)- name 맨 처음에 "김"
db.cols.find({ name: { $regex: "^김" } })- name 맨 마지막에 "김"
db.cols.find({ name: { $regex: "김 $" } })
2) 텍스트 연산자
- index 설정 -> 조회
db.cols.createIndex({name: "text"})
db.cols.find({$ text: {$search: "김이박"}})- 대소문자 구분 시
db.cols.find.({$ text: {$search: "mike",
$ caseSensitive : true }})- 새로운 index만들때 기존 index는 삭제하고
db.cols.dropIndexes()
* Q) 왜 index을 만들, 텍스트 연산자를 사용?
-> 단순한 $regex 검색과 다르게, 텍스트 인덱스를 사용하면 검색 속도가 훨씬 빨라짐.
3) 집계함수 맵리듀스
: 병렬 분산 처리 기법으로, 데이터를 작은 조각으로 나누어(Map) 개별적으로 처리한 후(Reduce) 다시 합치는 방식
- 복잡한 데이터 처리나 분산 환경에서만 필요함,
통계, 데이터 집계에는 Aggregation Framework 사용이 가장 좋음!

4) Aggregation Framework (집계 프레임워크)
성능: Aggregation Framework는 내부적으로 최적화되어 있어 MapReduce보다 빠름
참조: https://67crystalk.tistory.com/141
-
파이프라인 개념을 기반 (데이터 처리 과정을 여러 개의 단계로 나누어 순차적으로 처리)
-
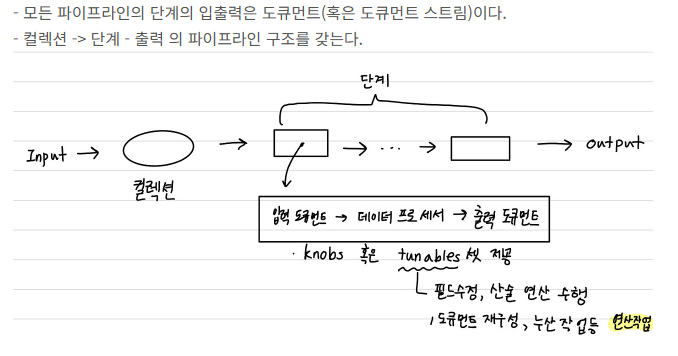
-
파이프라인 순서:
$match (필터링) , $project (필드 선택 및 변경), $sort (정렬), $skip (건너뛰기), $limit (제한)
- 4-1) 일치(match)
: 주어진 조건에 맞는 문서만 필터링 (find 와 비슷 )
db.collection.aggregate([
{ $match: { field: value } } // field 값이 value인 문서만 추출
])
ex) db.orders.aggregate([
{ $match: { status: "completed" } } // 상태가 "completed"인 주문만 조회
])
- 4-2) 선출(projection)
: 필요한 field만 남기고 필드를 변경, 추가
1은 필드 포함 0은 필드 미포함
db.orders.aggregate([
{ $project: { order_id: 1, customer_name: 1, _id: 0 } }, // 필드 선택
)
- 4-3) 정렬(sort)
: 내림차순, 오름차순
db.collection.aggregate([
{ $sort: { field: 1 } } // 오름차순, -1: 내림차순
])
ex) db.orders.aggregate([
{ $sort: { order_date: -1 } } // order_date를 기준으로 내림차순 정렬
])
- 4-4) 건너뛰기(skip)
: 문서를 건너뛰고 반환 , 주로 페이징? 처리시 사용
db.collection.aggregate([
{ $skip: 5 } // 처음 5개의 문서를 건너뛰기
])
ex) db.orders.aggregate([
{ $skip: 10 } // 처음 10개 문서를 건너뛰고 결과 반환
])
- 4-5) 제한(limit)
: 결과의 개수를 제한
db.collection.aggregate([
{ $limit: 5 } // 결과에서 처음 5개의 문서만 출력
])
ex) db.orders.aggregate([
{ $limit: 10 } // 처음 10개의 주문만 조회
])
파이프라인 활용 할때 순서 지켜서
예시)
-
필터링, 정렬, 제한
db.orders.aggregate([
{ $match: { status: "completed" } }, // 필터링: 상태가 "completed"인 주문만
{ $sort: { order_date: -1 } }, // 정렬: 주문 날짜 내림차순
{ $limit: 5 } // 제한: 상위 5개 주문만 조회
]) -
필터링, 필드 선택, 정렬
db.orders.aggregate([
{ $match: { status: "completed" } }, // 상태가 "completed"인 주문만
{ $project: { order_id: 1, customer_name: 1, _id: 0 } }, // 필드 선택
{ $sort: { order_date: -1 } } // 정렬: 주문 날짜 내림차순
])
