영속성 컨텍스트.. 그게 뭔데..
영속성 컨텍스트는 간단하게 말해서 어플리케이션과 데이터베이스의 중간다리 역할을 하는 논리적 가상 공간이라고 생각하면 된다.
간단히 말하면, 영속성 컨텍스트는 어플리케이션과 데이터베이스 간의 데이터 교환을 관리하며, 데이터를 영구적으로 저장하는(persisting) 역할을 한다.
왜 굳이 영속성 컨텍스트를 사용하는거야?
영속성 컨텍스트를 왜 사용하고, 배워야하는지 궁금해서 그에 대해서 알아 봤다.
- 캐싱처리
- 트랜잭션 관리
- 지연로딩
위와 같은 형태때문에 주로 영속성 컨텍스트를 가용하게 된다.
영속성 컨텍스트는 개념에서부터 "응용프로그램과 데이터베이스 사이의 가상의 저장 공간"이다.
즉 flush 처리가 되지않는다면, 데이터베이스 내에 반영하기 않고, 메모리 내에서만 처리하게 할 수 있다는 것이다.
플러시(Flush):
영속성 컨텍스트에서의 변경사항을 데이터베이스에 동기화하는 것이 플러시이다.
트랜잭션을 커밋할 때 자동으로 플러시가 발생하거나, 명시적으로 flush() 메서드를 호출할 수 있다.
플러시는 데이터베이스에 변경사항을 반영하는 중요한 단계이며, 트랜잭션이 롤백될 때도 발생할 수 있다.
이를 통해서 하나의 트랜잭션 단위로 관리를 할 수 있게 되며, 데이터베이스에 지속적인 참조를 하는 것이 아닌 메모리 내에 저장된 정보를 통한 빠른 접근을 가능하게 한다.
이 외에도 많은 이유에서 영속성 컨텍스트를 사용하지만, 보통 이러한 이유로 인해서 사용하여 보다 안정적인 데이터 관리를 할 수 있도록 유도한다.
엔티티 생명주기
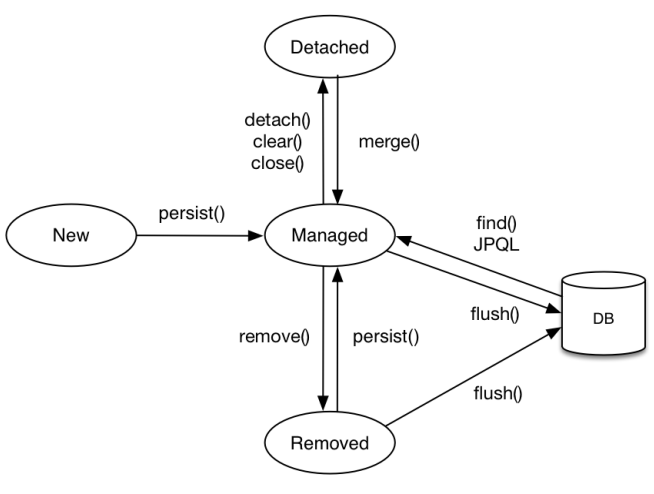
엔티티 생명주기에서는 아래와 같이 총 4가지의 상태를 가진다.
-
비영속(new/transient)
이는 말그대로 영속성 컨텍스트에 포함되지않은 상태이다. -
영속(managed)
이는 영속성 컨텍스트에 저장된 상태이다. -
준영속(detached)
이는 영속성 컨텍스트에 저장되어있다가 분리된 상태이다. -
삭제(remove)
이는 영속성 컨텍스트에서 삭제된 상태이다.
엔티티의 4가지 상태
@Entity
class User{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Setter
private String userName;
@Setter
private String nickName;
//constructor(shouldn't include PK in constructor)
}위와 같은 Entity가 있다고 가정하고 설명을 하겠다.
비영속
User user = new User("a","b"); 이는 영속성 컨텍스트에 포함되지않은 상태이다.
영속
User user = new User("a","b");
em.persist(user);이는 영속성 컨텍스트에 저장되어, 영속성 컨텍스트 내에서 관리가 되는 상태이다.
준영속
User user = new User("a","b");
em.detach(user);
em.clear();
em.close();이는 영속성 컨텍스트에서 분리된 상태이다.
삭제
User user = new User("a","b");
em.remove(user);이는 영속성 컨텍스트에서 삭제되는 상태이다.
em 이 뭐야?
위에서 쓰여진 em은 entityManger로써, 영속성 컨텍스트에 따른 상태를 관리할 수 있게 도와준다.
@PersistenceContext
private EntityManager em;위의 형태로 선언해 놓으면 간단하게 사용할 수 있다.
영속성 컨텍스트의 기능
1차 캐시
영속성 컨텍스트는 데이터베이스로부터 읽어온 엔티티들을 메모리에 캐싱한다.
이를 통해 동일한 엔티티에 대한 반복된 조회를 최소화하고 성능을 향상시킨다.
간단히 말하면 n번의 데이터 요청이 있다 가정하게 된다면,
데이터베이스에서의 요청은 1번, 이후에는 해당 요청 데이터를 1차 캐시 내에서 저장되며 요청에 대한 처리를 한다는 의미이다.
이는 영속성 컨텍스트내에서만 존재한다.
reference locality의 개념이 적용된 예시이다.
지연로딩
연관된 엔티티를 실제로 사용할 때까지 데이터베이스에서 로딩을 지연시키는 전략이다. 필요한 시점에 연관된 엔티티를 로딩하여 성능을 최적화할 수 있다.
이를 확인하기 위해서는 쿼리 로그를 확인하면 편하다.
한번만에 데이터를 가지고 오는지, 아니면 필요 시에 쿼리를 통해 가지고 오는지에 따라서 지연로딩과 즉시로딩을 구분한다.
지연 로딩은 성능에 부하를 줄일 수는 있지만, 오히려 데이터 접근 시 N+1 오류가 발생해서 부하가 더 발생 할 수도 있다.
이이는 trade-off 가 되는 경우라서 필요에 따라 좋은 선택을 할 수 있어야한다.
쓰기지연
엔티티의 상태 변경이나 쿼리를 데이터베이스에 즉시 반영하지 않고, 트랜잭션이 커밋(flush)될 때 변경 사항을 일괄적으로 적용하는 전략이다. 꼭 필요한 부분만을 반영하면서, 성능을 향상시킬 수 있다.
트랜잭션 범위 캐시
트랜잭션 내에서만 존재하는 캐시를 의미한다.
동일한 트랜잭션 내에서 여러 번 조회되는 엔티티를 캐시하여 중복 조회를 방지한다.
1차 캐시와 유사하지만, 이는 트랜잭션 내에서만 유효하며 트랜잭션이 종료되면 해당 캐시도 비워진다.
동일성 보장
같은 식별자를 가진 엔티티는 동일한 인스턴스로 관리됨을 의미한다.
나는 이를 알아보면서, 싱글톤 개념이 떠올랐다.
객체 1개당 인스턴스 한개만을 가질 수 있고 이를 통해서 자원을 아낄 수 있다는 맥락이 동일성 보장과 매우 유사하다고 생각했다.
간단하게 말하자면 싱글톤과 비슷하게 한 번 로딩된 엔티티는 두 번째 로딩 시에는 캐시된 인스턴스를 반환하여 동일성(동일 인스턴스)을 보장합니다.
dirty checking
엔티티의 상태 변경 여부를 감지하는 메커니즘이다.
트랜잭션이 커밋될 때 엔티티의 변경 사항이 자동으로 데이터베이스에 반영된다.
개념이 이런식으로 나와있는데, 원래는 자동으로 반영이 안되었나? 하는 생각이 들 것이다.
이는 그런 차원의 문제가 아니라, commit 작업을 거치게 되면 별다른 query 필요없이 변경 사항이 DB내에 적용된다는 의미로 받아들이면된다. 이는 ORM적인 특성을 띄고있는 기능이다.
commit 과 flush의 차이점
이 부분을 개발자들이 가장 어렴풋이 넘어가는 부분이 아닐까 생각이 든다. ( 개인적으로 나는 그냥 어렴풋이 알고 넘어갔다.. 하하)
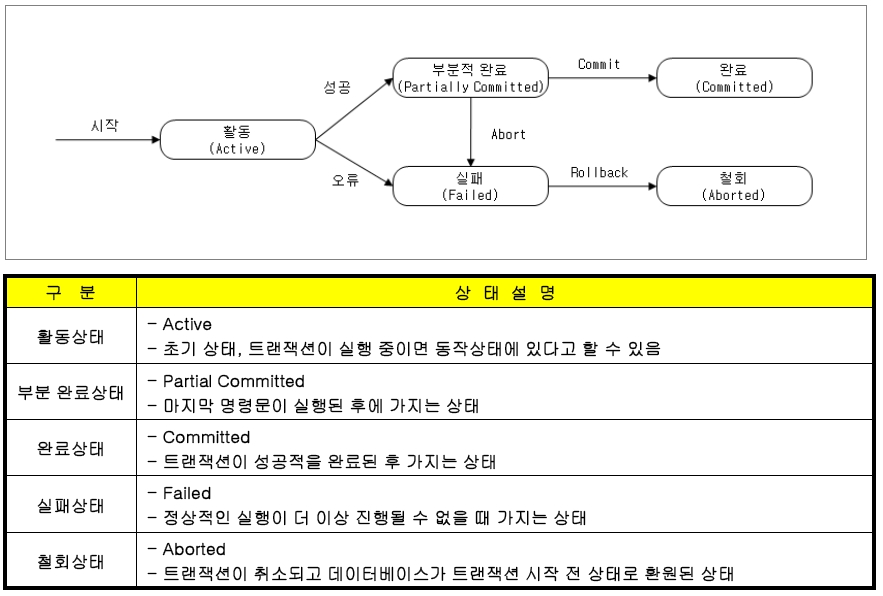
이는 해맥의 IT기술정보의 트랜잭션 상태도 이미지를 인용하였다.
위에서 보는 것처럼 commit은 하나의 트랜잭션이 끝나서 트랜잭션이 데이터베이스에 영구적으로 반영되는 작업이다.
flush는 commit과 다르게 트랜잭션이 끝났기 때문이 아닌, 데이터의 최신성 때문에 최신의 데이터를 통해 변경하고자 flush를 통해 업데이트를 진행하게 된다. 또한 데이터 오류 발생시에 rollback이 가능하다. flush 자체가 트랜잭션을 종료하지않았기 때문에, flush를 포함한 트랜잭션 내에서 오류 발생 시에 flush작업을 취소할 수 있다는 것이다.
commit 은 rollback이 불가하지만, flush는 rollback이 가능하다.
