운영 업무만 처리하고 있던 기간에 처리율 제한 장치 업무가 들어왔다.
팀에서 사용하지 않았던 기술이라 검토부터 적용까지 스스로 해나아간 과정들이 즐거워서 실수들이 있었지만 배포가 끝난 시점에 회고 겸, 사내 컨플루언스에 적었던 글에 보완해 다시 작성해본다.
(+ 24.04.22 코드 수정)
RateLimitFilter.class에서 ImplicitConfigurationReplacement 설정 추가
Rate Limiter
What
- 처리율 제한 장치는 클라이언트 또는 서비스가 보내는 트래픽의 처리율을 제거하기 위한 장치다.
- API 요청 횟수가 제한 장치에 의해 정의한 임계치를 넘으면, 추가로 도달한 모든 호출은 처리가 중단된다.
Why
처리율 제한 장치를 붙이는 이유는 다양하다.
- DoS 공격에 의한 자원 고갈 방지
- API 호출에 대한 과금의 위험에서 호출을 제한해 비용을 절감
- 서버의 과부하를 막는다.
팀에서 사용하게 된 이유는 마지막인 과부하 방지였다.
꼭 필요한 API도 있지만 필요 이상으로 호출을 많이 하는 특정 클라이언트들에게 제한을 걸기 위함이었다.
How
처리율 제한 알고리즘
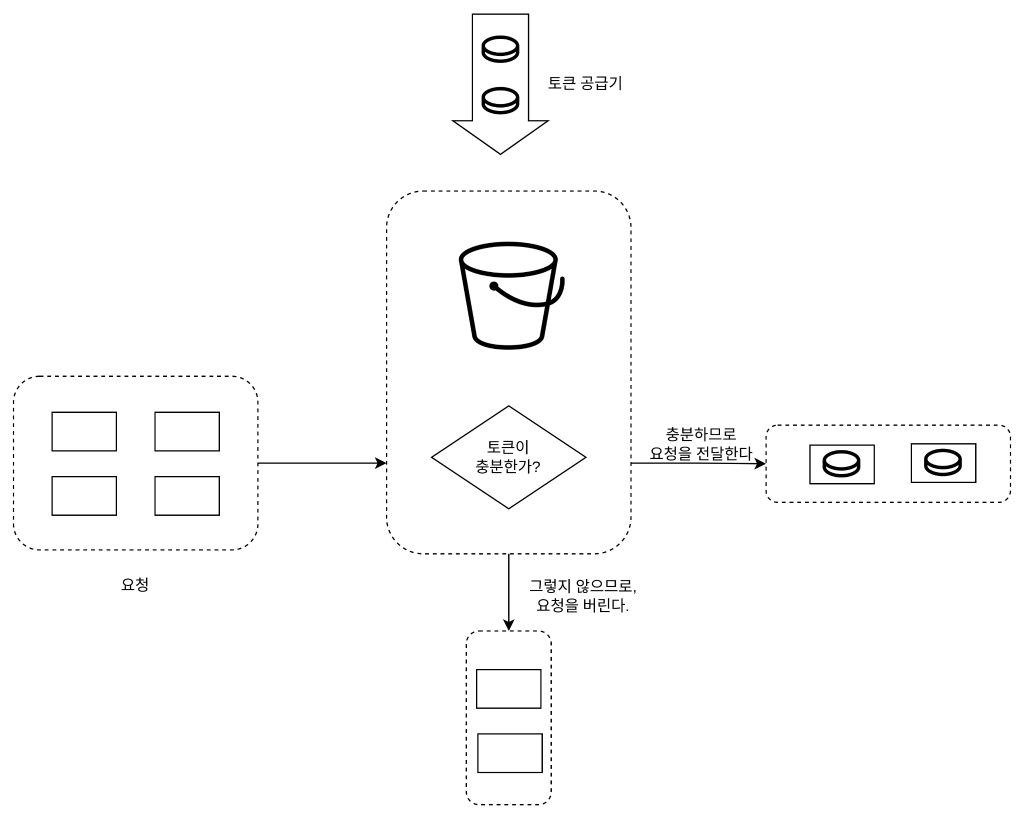
토큰 버킷
- AWS API Gateway, Bucket4J
- 일시적으로 많은 트래픽이 와도 토큰이 있다면 처리가 가능하면서 토큰 손실 처리를 통해 평균 처리 속도를 제한할 수 있다.
- 동작 원리
- 토큰 버킷은 지정된 용량을 갖는 컨테이너
- 이 버킷에는 사전 설정된 양의 토큰이 주기적으로 채워진다.
- 토큰이 꽉 찬 버킷에는 더 이상의 토큰은 추가되지 않는다.
- 버킷이 가득 차면 추가로 공급된 토큰은 버려진다.
- IP 주소별로 처리율 제한을 적용해야 한다면 IP 주소마다 버킷을 하나씩 할당
- 메모리 사용 측면에서 효율적
- 인자 값을 튜닝하는 것이 어렵다
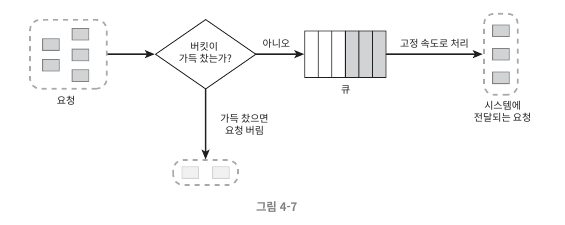
누출 버킷
- NGINX
- 네트워크에서 트래픽 체증을 일정하게 유지한다.
- 동작 원리
- FIFO 큐가 다 차면 새 요청은 에러를 반환하며 버려진다
- 처리율에 따라 큐에서 요청을 꺼내 처리
- 제한된 큐의 크기로 메모리 사용 측면에서 효율적
- 버킷 크기와 처리율 튜닝이 어렵다.
전략
| AWS API Gateway | NGINX Reverse Proxy | Opensource API Gateway | Application level Gateway | |
|---|---|---|---|---|
 |  | 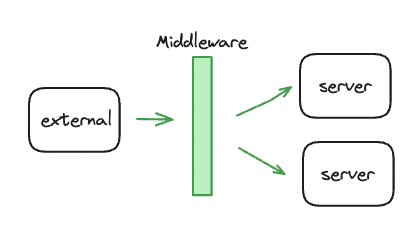 | 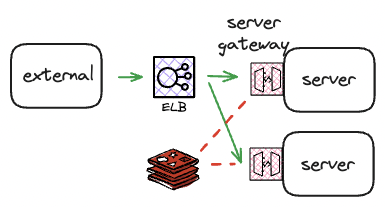 | |
| Feature | - Amazon에서 제공하는 완전 관리형 서비스 - 수신한 API 호출과 전송한 데이터 양에 대해 과금 - token bucket algorithm | - NGINX conf 파일 설정을 통해 가능 - leaky bucket algorithm | - Open source API gateway - Ratelimit 외에도 MSA 관리 서비스 제공 | - Spring boot에서 처리율 제한 구현 라이브러리 활용 - token bucket algorithm |
| Extra charge | O | X | △ (추가 인스턴스 비용 + Library Enterprise version의 비용 있을 수 있음) | △ (별도 Redis 비용) |
| Pros | - AWS에서 제공하는 solution - AWS console에서 조작 가능 | - Elastic Beanstalk는 nginx를 reverse proxy로 사용하고 있어, 별도 모듈이나 라이브러리 설치 필요X - 설정이 단순함 | Admin Dashboard 제공되어 관리가 편하다. - 설치가 쉽고 확장 가능, 다양한 공개 플러그인 지원 | - 추가 서버 구축이 필요 없다 - 단순한 처리율 제한 기능만 필요한 경우 |
| Cons | - 과금 - Lamda scaling 지연에 따른 오류 발생 가능 | - 다른 서비스에 비해 세밀한 제어가 부족할 수 있다 | - 인스턴스 최소 요구사향 (4core, 16GB RAM) | - 앞 단의 LB가 아닌 Application 에서 별도 처리량을 제어 해야한다. - 분산 시스템에서 사용 시 외부 cache store가 필요 - reference가 많진 않음 |
| Library | Kong, KrakenD, Tyk | Bucket4J, Guava, RateLimitJ |
마크다운 표가 예쁘게 안나와
내가 조사했던건 4가지였고, 그 중 과금, 추가 인프라 비용이 제일 적고 빠르게 적용할 수 있을 것으로 생각되는 NGINX Reverse Proxy와 Bucket4J를 추가로 검토하기로 했다.
어떻게 처리율 제한할 것인지 원하는 것이 있었기 때문에 두 기술 모두 좀 더 알아보면서 원하는 제한을 걸 수 있을지 파악해보기로 했다.
아래에서 이야기할 것이긴 하지만, 우선 원하는 처리율 제한 방식은 둘 다 가능했기때문에 나는 좀 더 앞단에서 제한을 두는 것이 서버 단에 부하를 줄일 수 있다고 생각해서 NGINX Reverse Proxy를 사용하는 쪽으로 말씀 드렸고, 우선 적용해보기로 했다.
NGINX Reverse Proxy
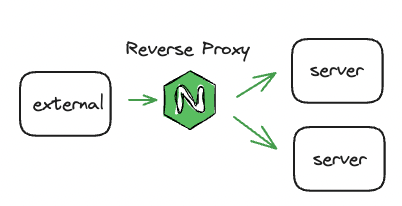
우선 팀에서 Elastic Beanstalk으로 분산 서버를 운용하고 있었기 때문에 NGINX 기본 설정을 하고 있었고 NGINX가 어디에 붙어있는지가 궁금해서 한참을 찾아보다가 AWS 공식 문서에서 다음과 같은 내용을 읽게 되었다.
Elastic Beanstalk는 nginx를 역방향 프록시로 사용하여 애플리케이션을 포트 80의 Elastic Load Balancing 로드 밸런서에 매핑합니다.
Elastic Beanstalk는 확장하거나 자체 구성으로 완전히 재정의할 수 있는 기본 nginx 구성을 제공합니다.Elastic Load Balancing 로드 밸런서에 매핑합니다.
위 문장을 읽고 인스턴스 별로 붙어있는게 아니라 로드 밸런서 쪽에 붙어있다고 오해를 해서 아래 그림과 같이 구성이 된다고 생각했다.
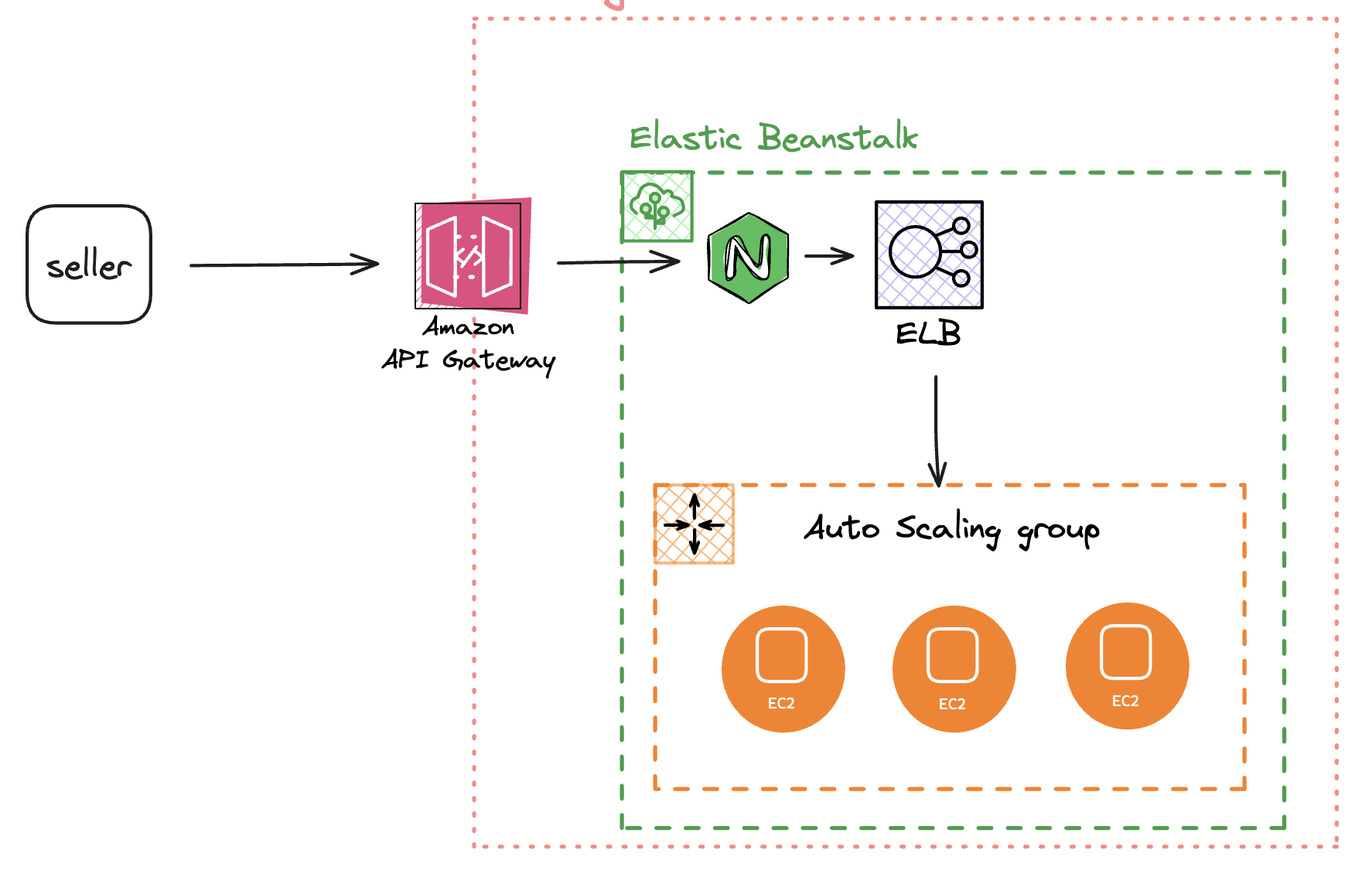
아무튼 그래서 적용 해보고 dev 환경에 배포를 해서 Test도 열심히 하고 옆 팀분들까지 조인해서 마지막 리뷰를 하게되었다.
이때 옆 팀 팀장님께서 .ebextensions 에 nginx conf를 넣어두면 각 인스턴스 별로 있는 nginx 에 설정이 적용된다는 걸 알려주셨고, ( 참고 )
dev 서버는 인스턴스가 1개라, 2개로 증가시켜 Test를 했을 때 StatusCode 429가 1개일 때 보다 절반으로 오는 것을 보고 공식문서를 잘못 해석했음을 알게되었다.
아직 공식문서를 잘 읽기 쉽지않다.
다른 설정 방식이 있는지 AWS 문서를 읽어봤으나 찾기가 어려웠고, 처리율 제한 장치를 빨리 적용해서 NGINX를 고수하는 것 보다 다른 기술로 빨리 갈아타야해서 더 상위단에 적용하는 방법은 찾지 못했다.
아무튼 그래서 실제로 PROD에 나가지 않았지만, 적용하면서 도움이된 참고 자료라도 공유한다.
- https://www.nginx.com/blog/rate-limiting-nginx/
- https://nginxstore.com/blog/nginx/%EC%9A%94%EC%B2%AD-%EC%A0%9C%ED%95%9C-nginx-%EB%B0%8F-nginx-plus%EB%A1%9C-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0/
- https://wiki.yowu.dev/ko/dev/WAS/rate-limiting-nginx-translate-kor
- https://willseungh0.tistory.com/191
Bucket4J
빨리 적용해야하는데, 시간을 허비하면서 배포 시점이 밀리게되었다.
어쨌든 내가 잘못한거니 빠르게 Application level에서 처리율 제한을 걸기위해 해외에 워케이션을 나가있는 기간임에도 불구하고 Bucket4J랑 맞장떠서 하루만에 적용해보고자 14시간동안 co working 카페에서 daily 요금 뽕을 뽑고왔다.
특징
사용하기
Baeldung과 공식 Github를 위주로 참고했다.
우선 build.gradle에 추가해준다.
implementation("com.bucket4j:bucket4j-core:8.7.0")
implementation("com.bucket4j:bucket4j-redis:8.7.0")Bucket 설정을 위해 기본적인 것들은, 자세히 설명해둔 자료들이 많아서 기본 코드만 남기고 넘어가겠다.
Refill refill = Refill.intervally(10, Duration.ofMinutes(1));
Bandwidth limit = Bandwidth.classic(10, refill);
Bucket bucket = Bucket.builder()
.addLimit(limit)
.build();
for (int i = 1; i <= 10; i++) {
assertTrue(bucket.tryConsume(1));
}
assertFalse(bucket.tryConsume(1));
그리고 TPS를 어느정도로 제한할지를 Bandwidth 설정해야한다.
나는 API endpoint path와 Request Paramter 2개를 조합해서 key를 만들고, 이 키에 따라 TPS 수준을 설정하고 token을 같이 소모할 수 있도록 했다.
다음은 Baeldung에서 참조한 내용으로 시간당 20, 40, 100으로 제한하는 것을 정의해둔 것이다.
enum PricingPlan {
FREE {
Bandwidth getLimit() {
return Bandwidth.classic(20, Refill.intervally(20, Duration.ofHours(1)));
}
},
BASIC {
Bandwidth getLimit() {
return Bandwidth.classic(40, Refill.intervally(40, Duration.ofHours(1)));
}
},
PROFESSIONAL {
Bandwidth getLimit() {
return Bandwidth.classic(100, Refill.intervally(100, Duration.ofHours(1)));
}
};
//..
}
분산 환경에서 적용하기
Application level이기 때문에 분산 환경에서 사용하려면 RDBMS나 key-value storage를 사용해 카운팅을 하는 저장소가 필요했다.
Bucket4J에서 Redis를 붙여 분산 환경을 구축하는 것을 지원하고 있었는데, 마침 최근에 서버에 Redis를 붙인 터라 바로 Redis에 붙이기로 했다.
여러 레퍼런스에서 Filter나 Interceptor에서 거쳐가도록 구현 한 것을 볼 수 있었다.
나는 Filter에 붙여야 좀 더 앞단이고, 과도한 요청이 들어왔을 때 스레드를 할당 받기 전에 처리해버리면 좋겠다고 생각해 Filter단에 구현했다.
https://bucket4j.com/8.7.0/toc.html#bucket4j-redis
import io.github.bucket4j.Bucket;
import io.github.bucket4j.BucketConfiguration;
import io.github.bucket4j.redis.lettuce.cas.LettuceBasedProxyManager;
import static io.github.bucket4j.TokensInheritanceStrategy.RESET;
public class RateLimitFilter implements Filter {
private final LettuceBasedProxyManager<byte[]> proxyManager;
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) servletRequest;
// redis의 key로 설정할 것을 custom
String key = getBucketKey(servletRequest, servletRequest);
// rate limit을 적용하지 않는 경우를 custom으로 만들어 check
if (isNotApplyRateLimit(key)) {
filterChain.doFilter(servletRequest, servletResponse);
return;
}
try {
Bucket bucket = proxyManager.builder()
.withImplicitConfigurationReplacement(1, RESET)
.build(key.getBytes(), getConfigSupplier(key));
if (bucket.tryConsume(1)) {
filterChain.doFilter(servletRequest, servletResponse);
} else {
// bucket을 모두 소모 = 요청이 threshold를 넘음
// StatusCode 429 (TOO_MANY_REQUESTS)를 전달하고 Filter 이후 과정을 거치지 않도록 함
// token이 몇 개 남았는지를 담아 전달해줄 수도 있다.
HttpServletResponse httpResponse = (HttpServletResponse) servletResponse;
httpResponse.setContentType("text/plain");
httpResponse.setStatus(HttpStatus.TOO_MANY_REQUESTS.value());
}
} catch (Exception e) {
log.error("RateLimitFilter error {}", e.getMessage(), e);
}
}
private Supplier<BucketConfiguration> getConfigSupplier(String key) {
return () -> this.findBandwidth(key)
.map(CustomBandwidth::getLimit) // 위에 PricingPlan 처럼 정의해둔 것을 찾아 Bandwidth 반환
.map(limit -> BucketConfiguration.builder().addLimit(limit).build()).orElse(null);
}
}
적용하면서 시간이 제일 오래 걸렸던 부분이 Redis를 붙여서 사용하는 부분이었다.
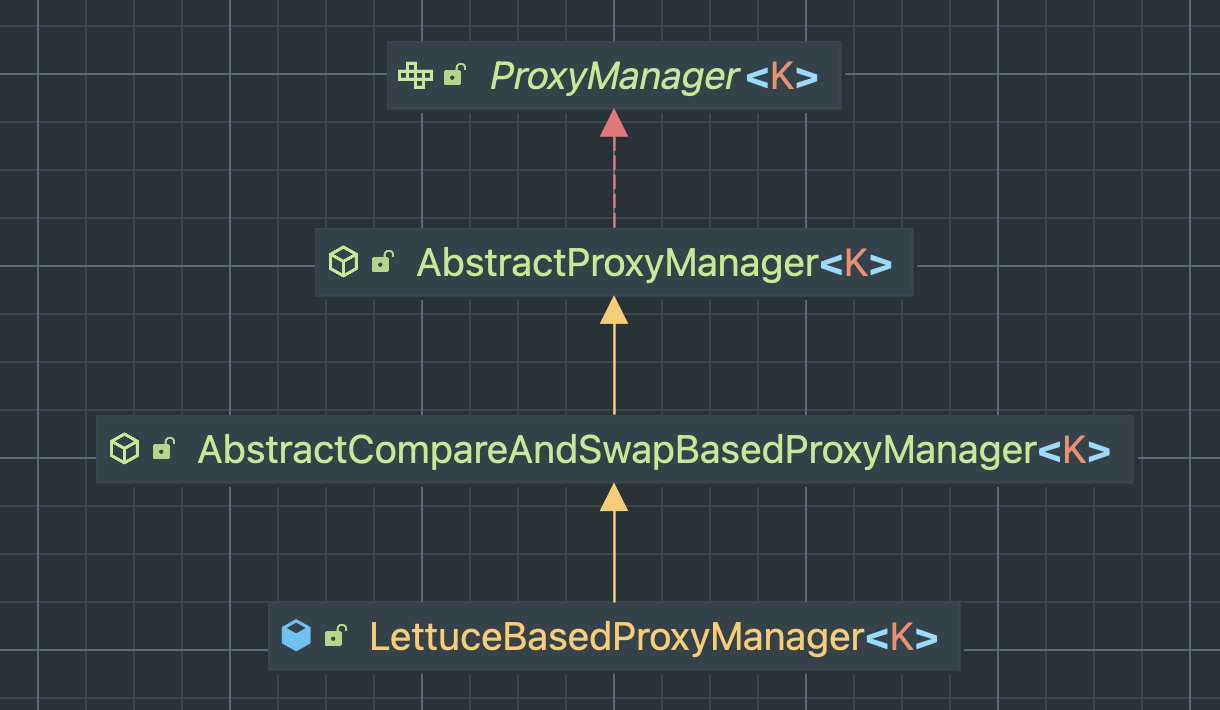
기초 내용에서는 Bucket을 Bucket.builder().build() 로 생성했는데, 난데없이 ProxyManager가 뭔지 모르겠는데 문서에서 ProxyManager로 Bucket을 가져오고 있어서 이해하기가 어려웠다. (문서가 그렇게 친절하지 않)
LettuceBasedProxyManager
LettuceBasedProxyManager의 상속 관계를 보면 ProxyManager가 존재한다.
ProxyManager class로 직접 들어가서 설명을 찾아보니 다음과 같이 적혀있다.
bucket4j 라이브러리의 확장점을 나타냅니다. ProxyManager는 backing storage에서 BucketProxy 컬렉션을 구축하고 관리하기 위한 API를 제공합니다. 일반적으로 ProxyManager의 인스턴스는 RDBMS 테이블, GRID 캐시 또는 외부 저장소를 중심으로 구성됩니다. Primary 키는 서로 다른 Bucket의 persisted state를 구분하는 데 사용됩니다.
어떤 요청이던 상관 없이 하나의 Bucket으로 처리율 제한을 적용한다면 하나의 Bucket을 생성하고 이 Bucket을 계속 사용하면 되지만, API 별로 또는 사용자 별로 다른 처리율 정책을 가진다면 Bucket을 여러 개 생성하고 이를 어딘가에 들고있어야한다.
Redis에서 값을 Bucket을 가져오는 것이 ProxyManager라고 보면 될 것 같다.
LettuceBasedProxyManager 내부 읽어보기
LettuceBasedProxyManager 가 Redis와 어떻게 연결하고 명령어를 보내서 가져오는지가 궁금해서 class를 열어서 간단하게 읽어봤다.
문서에 나와있는 Bucket을 가져오는 과정을 토대로 따라가봤다.
LettuceBasedProxyManager<String> proxyManager = LettuceBasedProxyManager.builderFor(redisConnection)
.withExpirationStrategy(ExpirationAfterWriteStrategy.basedOnTimeForRefillingBucketUpToMax(ofSeconds(10)))
.build();
BucketConfiguration configuration = BucketConfiguration.builder()
.addLimit(limit -> capacity(1_000).refillGreedy(1_000, ofMinutes(1)))
.build();
Bucket bucket = proxyManager.builder().build(key, configuration);우선 LettuceBasedProxyManager를 build 하면서 Redis API를 정의하는데 eval, get, del command를 사용한다.
public static <K> LettuceBasedProxyManagerBuilder<K> builderFor(RedisAdvancedClusterAsyncCommands<K, byte[]> redisAsyncCommands) {
Objects.requireNonNull(redisAsyncCommands);
RedisApi<K> redisApi = new RedisApi<>() {
@Override
public <V> RedisFuture<V> eval(String script, ScriptOutputType scriptOutputType, K[] keys, byte[][] params) {
return redisAsyncCommands.eval(script, scriptOutputType, keys, params);
}
@Override
public RedisFuture<byte[]> get(K key) {
return redisAsyncCommands.get(key);
}
@Override
public RedisFuture<?> delete(K key) {
return redisAsyncCommands.del(key);
}
};
return new LettuceBasedProxyManagerBuilder<>(redisApi);
}eval : Redis에 새로운 함수를 추가하는 함수
인자로 스크립트,키의 개수, (0개 이상의) 데이터를 받아 스크립트의 결과를 아웃풋으로 내보낸다.
eval을 사용하는 부분은 compareAndSwapFuture method이고 ttl이 유효한지, originData가 있는지에 따라 명령어 4개를 구분해서 보내고 있다.
private RedisFuture<Boolean> compareAndSwapFuture(K[] keys, byte[] originalData, byte[] newData, RemoteBucketState newState) {
long ttlMillis = calculateTtlMillis(newState);
if (ttlMillis > 0) {
if (originalData == null) {
// nulls are prohibited as values, so "replace" must not be used in such cases
byte[][] params = {newData, encodeLong(ttlMillis)};
return redisApi.eval(LuaScripts.SCRIPT_SET_NX_PX, ScriptOutputType.BOOLEAN, keys, params);
} else {
byte[][] params = {originalData, newData, encodeLong(ttlMillis)};
return redisApi.eval(LuaScripts.SCRIPT_COMPARE_AND_SWAP_PX, ScriptOutputType.BOOLEAN, keys, params);
}
} else {
if (originalData == null) {
// nulls are prohibited as values, so "replace" must not be used in such cases
byte[][] params = {newData};
return redisApi.eval(LuaScripts.SCRIPT_SET_NX, ScriptOutputType.BOOLEAN, keys, params);
} else {
byte[][] params = {originalData, newData};
return redisApi.eval(LuaScripts.SCRIPT_COMPARE_AND_SWAP, ScriptOutputType.BOOLEAN, keys, params);
}
}
}LuaScripts 가 어떻게 구성되어있는지 궁금해서 해당 클래스의 script 상수들을 GPT에게 해석시켰다.
- SCRIPT_SET_NX_PX : 만약 키가 존재하지 않으면 해당 키를 설정하고 값과 만료 시간을 설정하고 지정된 만료 시간(ms) 동안 유지하는 스크립트
- SCRIPT_COMPARE_AND_SWAP_PX : 키의 현재 값이 주어진 값과 일치하는 경우에만 새로운 값으로 교체하고 지정된 만료 시간(ms) 동안 유지하는 스크립트
- SCRIPT_SET_NX : "nx" 옵션을 사용하여 만약 키가 존재하지 않으면, 키를 설정하는 스크립트
- SCRIPT_COMPARE_AND_SWAP : 키의 현재 값이 주어진 값과 일치하는 경우에만 새로운 값으로 교체하는 스크립트
Redis 명령들을 정의한 다음 proxyManager.builder().build() 에서 Bucket을 가져오는 명령을 실행하도록 되어있다.
@Override
public AsyncBucketProxy build(K key, Supplier<CompletableFuture<BucketConfiguration>> configurationSupplier) {
if (configurationSupplier == null) {
throw BucketExceptions.nullConfigurationSupplier();
}
AsyncCommandExecutor commandExecutor = new AsyncCommandExecutor() {
@Override
public <T> CompletableFuture<CommandResult<T>> executeAsync(RemoteCommand<T> command) {
Request<T> request = new Request<>(command, getBackwardCompatibilityVersion(), getClientSideTime());
Supplier<CompletableFuture<CommandResult<T>>> futureSupplier = () -> AbstractProxyManager.this.executeAsync(key, request);
return clientSideConfig.getExecutionStrategy().executeAsync(futureSupplier);
}
};
commandExecutor = asyncRequestOptimizer.apply(commandExecutor);
return new DefaultAsyncBucketProxy(commandExecutor, recoveryStrategy, configurationSupplier, implicitConfigurationReplacement);
}
주의할 점
Redis가 단일 인스턴스 (Stand Alone) 인지 Cluster mode로 사용하고 있는지를 확인해서 설정을 넣어야한다.
8.2.RC2 버전부터 Redis Cluster mode의 ProxyManager를 지원하니 꼭 참고하자.
https://github.com/bucket4j/bucket4j/discussions/322#discussioncomment-4246636
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionClusterFactory() {
RedisClusterConfiguration clusterConfiguration = new RedisClusterConfiguration();
clusterConfiguration.clusterNode(host, port);
return new LettuceConnectionFactory(clusterConfiguration);
}
@Bean
public RedisClusterClient redisClusterClient() {
return RedisClusterClient.create(
RedisURI.builder().withHost(host).withPort(port).build());
}
@Bean
public LettuceBasedProxyManager<byte[]> clusteredProxyManager(RedisClusterClient redisClusterClient) {
return LettuceBasedProxyManager.builderFor(redisClusterClient)
.withExpirationStrategy(ExpirationAfterWriteStrategy.basedOnTimeForRefillingBucketUpToMax(Duration.ofSeconds(1)))
.build();
}
}마무리
삽질 전문 답게.. 두번 일하는 슬픈일이 있었지만, NGINX와 Bucket4J가 다른 알고리즘을 사용하고 있었기 때문에 누출 버킷 알고리즘과 토큰 버킷의 차이를 이론으로 아는 것 보다 더 와닿을 수 있었다.
그리고 공식 문서에도 모든걸 다 적어두지 않는다는 점, 뭐든지 설정할 때는 무작정 복사 붙여넣기하지 말고 설정의 각 객체가 어떤 일을 하는지부터 알아야 돌아가는 것 같아도 더 빨리 이해할 수 있다는 걸 다시 또 깨닫게 되었다.
참고
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- https://www.msaschool.io/operation/architecture/architecture-one/
- https://medium.com/cupist/api-gateway-part-1-%EA%B0%9C%EC%9A%94-f1ed0684d356
- https://preethamumarani.medium.com/token-bucket-rate-limiter-using-spring-boot-and-redis-bucket4j-dd67e8c4f2ce
- https://jonghoonpark.com/2023/05/17/%EC%B2%98%EB%A6%AC%EC%9C%A8-%EC%A0%9C%ED%95%9C-%EC%9E%A5%EC%B9%98-%EC%84%A4%EA%B3%84


코드 분석 감사합니다. 이해하는데 도움이 많이 되었어요