
Summary
- 상황 : 프로젝트와 가장 적합한 데이터베이스를 검토 및 결정해야함
- 논의 대상
- RDBMS인가 noSql인가?
- ORM을 사용할 것인가?
- 상황
- Relation DB인 mySql과 Document DB인 mongodb 둘 다 사용해봤다.
- 그러나 정규화를 고려한 DB를 더 많이 접해서인지, 이번 프로젝트에서 mongodb를 사용해야하는 이유를 정확히 말할 수 없었다.
- 결론
- RDB의 JOIN 테이블 검색 시간을 절약하기 위해 noSql Document DB인 mongodb으로 설계하며 ORM mongoose를 활용
현재 알고있는 SQL, NoSql을 선택하는 기준
- 요구사항에 따라 선택이 달라질 수 있다.
- NoSQL 기반의 비관계형 데이터베이스가 확장성이나 속도면에서 뛰어나다.
- READ를 자주하지만 UPDATE가 없는경우 NoSQL
- 하나만 고차원으로 구조화된 SQL 기반의 데이터베이스가 더 좋은 성능을 보여주는 서비스도 있다.
- 데이터베이스의 ACID 성질을 준수해야하는 경우 RDBMS
- Atomicity 원자성, Consistency 일관성, Isolation 격리성, Durability 지속성
- 하나의 트랜잭션에 의한 상태의 변화를 수행하는 과정에서 안전성을 보장
- 사용되는 데이터가 구조적이고 일관적인 경우 RDBMS
NodeJS는 NoSQL을 사용할 때 강력하다
- 단순한 I/O를 빠르게 처리할 수 있다.
- 순식간에 1000개의 단순하 작업의 I/O가 발생한다면
- Blocking + Sync + 멀티스레드 방식으로로 처리할 경우 컨텍스트 스위칭 때문에 불필요한 자원 소모가 심하다.
- Non-Blocking + Async + 싱글 스레드 방식으로 처리할 경우 더 효율적으로 처리할 수 있다.
- NoSQL의 경우 말 그대로 단순한 I/O를 처리하는데 적합하다.
- input 그대로 저장하거나
- output 그대로 내보내거나
- 반대로 이야기 하자면, MySQL 을 사용해야 하는 상황(복잡한 데이터를 I/O 하는 상황)에는 적합하지 않다.
- I/O의 순서가 보장되어야 하는 경우가 많은데, 이를 싱글스레드로 처리하게 된다면 Non-Blocking + sync 상태가 되기 때문에 스레드가 아무 일도 하지 않는 시간이 많아지기 때문
- 이럴 경우 Spring MVC 같이 RDBMS에 적합한 도구(프레임워크)를 쓰는게 맞다.
알겠어.. 그런데 Document 를 어떻게 구성해야할지 모르겠으니 우선 ERD를 작성해보자

대표 테이블들만 표시를 해봤는데 각 테이블 간의 관계가 너무 많이 묶여있어서 정규화를 지키려면 sub table들이 많이 생겨 JOIN 과도화 될 것 으로 예상되었다.
모든 테이블이 다른 테이블을 참조하고 있다.
- 유저 : 커뮤니티 → N : M
- 유저 : 커뮤니티 별 채널 → N : M
- 유저 : 메시지 → 1 : N
- 커뮤니티 : 채널 → 1 : N
- 채널 : 메시지 → 1 : N
관계가 너무 많다.. 성능을 개선시킬 수 없을까?
현재 사용자가 속한 커뮤니티들 중에서 채널의 정보를 RDBS로 한다고 가정해보자
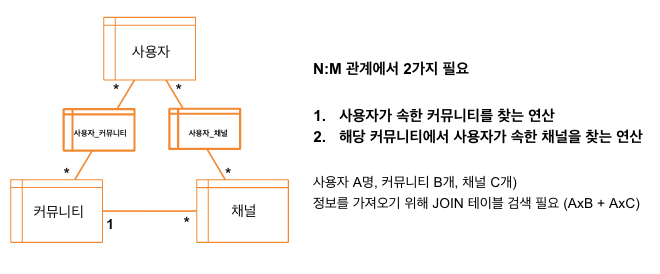
사용자 (A) x 커뮤니티 (B) + 사용자 (A) x 채널 (C) 만큼의 검색이 더 필요하다…
→ NoSQL을 활용해 비정규화 한다면?
사용자가 속한 커뮤니티 정보들을 사용자 Document에 커뮤니티라는 column을 만들고 내부를 key-value 형식으로 저장한다면! → JOIN Table 탐색을 없앨 수 있을 것 같다!
사용자 document의 communities는 용량 측면으로는 어차피 RDB도 JOIN Table을 생성해야해서 추가로 발생하는 용량은 비슷할 것이라 생각했다.

다시 MongoDB 설계를 해보자

사용자는 커뮤니티 field를 가지고 있고 value는 객체로 채널 id를 key, 채널 마지막 접속 시간을 value로 한object를 가지도록했다.
id는 document 생성시 자동으로 생성되는 document unique id(_id) 이다.
프로젝트 시작 전에 멘토님이 하나의 document에 너무 많은 data를 담고있으면 분할하는 것을 권장하셨다. (검색해보니 max 16KB)
따라서 채널의 채팅 로그 기록들은 100개 단위로 document를 구성하고, 초과하면 새로운 document를 생성하기로 설계하였다.
followings와 followers를 user collection에 가지면 갱신 이상을 챙겨줘야하는데..
followings : 내가 팔로우하는 사용자 목록
followers : 나를 팔로우 하는 사용자 목록
A가 B를 팔로우하기 시작하면 A의 document followings에 추가 + B의 document followers에 추가
A가 B를 팔로우 취소 했을 때 A의 document followings에서 삭제 + B의 document followers에 삭제
→ 하나의 Transaction에 2개의 쿼리 실행이 필요하다.
그러나 followers field만 가지고있다면, 화면에 followers 정보를 보여줘야할 때, Users collection 전체를 확인하면서 followers에 현재 사용자의 id가 있는지를 확인해봐야한다.
→ 갱신 이상이 생기지 않도록 백엔드에서 더 챙기기로 했다.
그러면 ORM은?
어떤 DB를 사용할 지 정하기 전에, 조원 중 한명이 Prisma를 추천했다. (직관적이고 러닝커브가 짧다)
Prisma를 확인해보니 확실히 직관적으로는 보이지만, NestJS에서 mongodb 사용을 위해 TypeORM과 mongoose를 지원하고 있었다.
TypeORM은 mongodb v3까지 지원했고, mongoose가 가장 많이 사용하는 MongoDB의 ORM으로 문서 찾기가 편하여 mongoose를 선택했다.

https://docs.nestjs.com/techniques/mongodb
이후의 고민들
설계를 마치고 실제로 사용하면서 추가적으로 어떤 고민들을 했는지는 다음 포스팅으로 적어두었습니다.
