
1. Elasticsearch
- 텍스트, 숫자, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 오픈 소스 검색 및 분산 엔진이다. 그리고, 전문검색엔지(Full-text search engine)으로 개발되었으나 단순히 검색엔진을 넘어 보안, 로그분석, 전문분석 등 다양한 영역에서 중요한 역할을 하고 있다.
- Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진이다. 이것을 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, NRT(Near Real Time)으로 저장, 검색, 분석할 수 있다. Elasticsearch는 검색을 위해 단독으로 쓰이기도 하지만, ELK stack으로 사용되기도 한다.
2. Elasticsearch 관련 용어 정리 & 설명
- Elastisearch : 기본적으로 모든 데이터를 색인(indexing)하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달하여 동작하게 한다.
오픈소스https://github.com/elastic 를 통해 소스코드를 확인할 수 있고, 또한 기여도 가능하다. Lucene이 Java로 만들어졌기에 ES도 마찬가지로 Java로 코딩되어 있다. 따라서, 반드시 Java설치가 필요하다.

- 실시간분석(NRT) Elasticsearch의 특징 중 하나로, Haddoop이라는 배치 기반 분산 시스템과 달리 ES클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력 - 색인(Index)되고, 동시에 실시간에 가까운 속도(Near Real-Time)로 색인된 데이터의 검색, 집계가 가능하다.
내용 참고!!
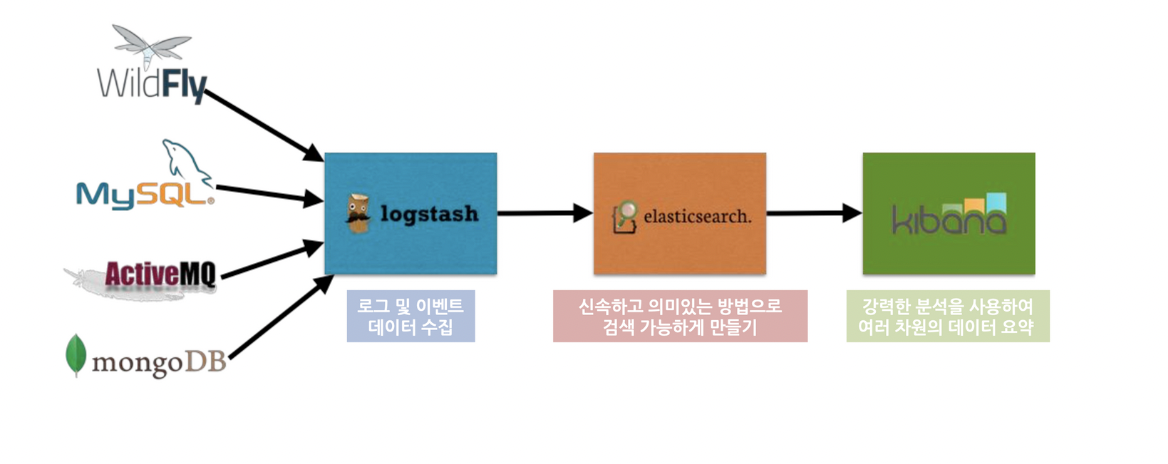

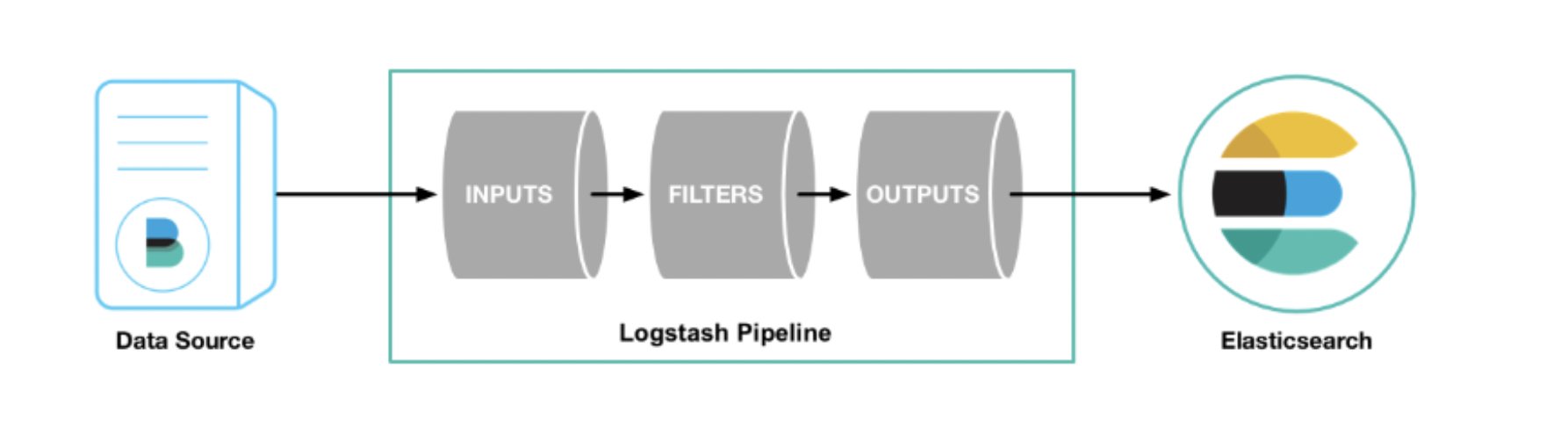
- Logstash : 원래 Elasticsearch와 별개로 다양한 데이터 수집과 저장을 위해 개발된 프로젝트였다. Elasticsearch의 입력 수단으로 사용되기 시작하면서 통합되었다. 이것이 처리하는 Data Flow는 크게 세 단계로 볼 수 있다.
입력(Inputs) ➡️ 필터(Filters) ➡️ 출력(Outputs)
- 입력 기능에서 Beats, RDBMS 등 다양한 데이터 저장소로부터 데이터를 입력 받는다.
- 필터 기능을 통해 데이터를 확장, 변경, 필터링 및 삭제 등의 처리를 통해 가공을 한다.
- 출력 기능을 통해 ES, Email, Kafaka와 같은 다양한 데이터 저장소로 데이터를 전송하게 된다.
- 위의 방식으로 데이터 처리를 위한 파이프라인을 계속 연결해서 처리한 다음에 최종적으로 출력을 엘라스틱 서치로 지정해서 인덱싱하는 구조이다. 이렇게 데이터베이스에서 데이터를 뽑아와서 넣어주는 방식을 Data Polling이라고 한다.
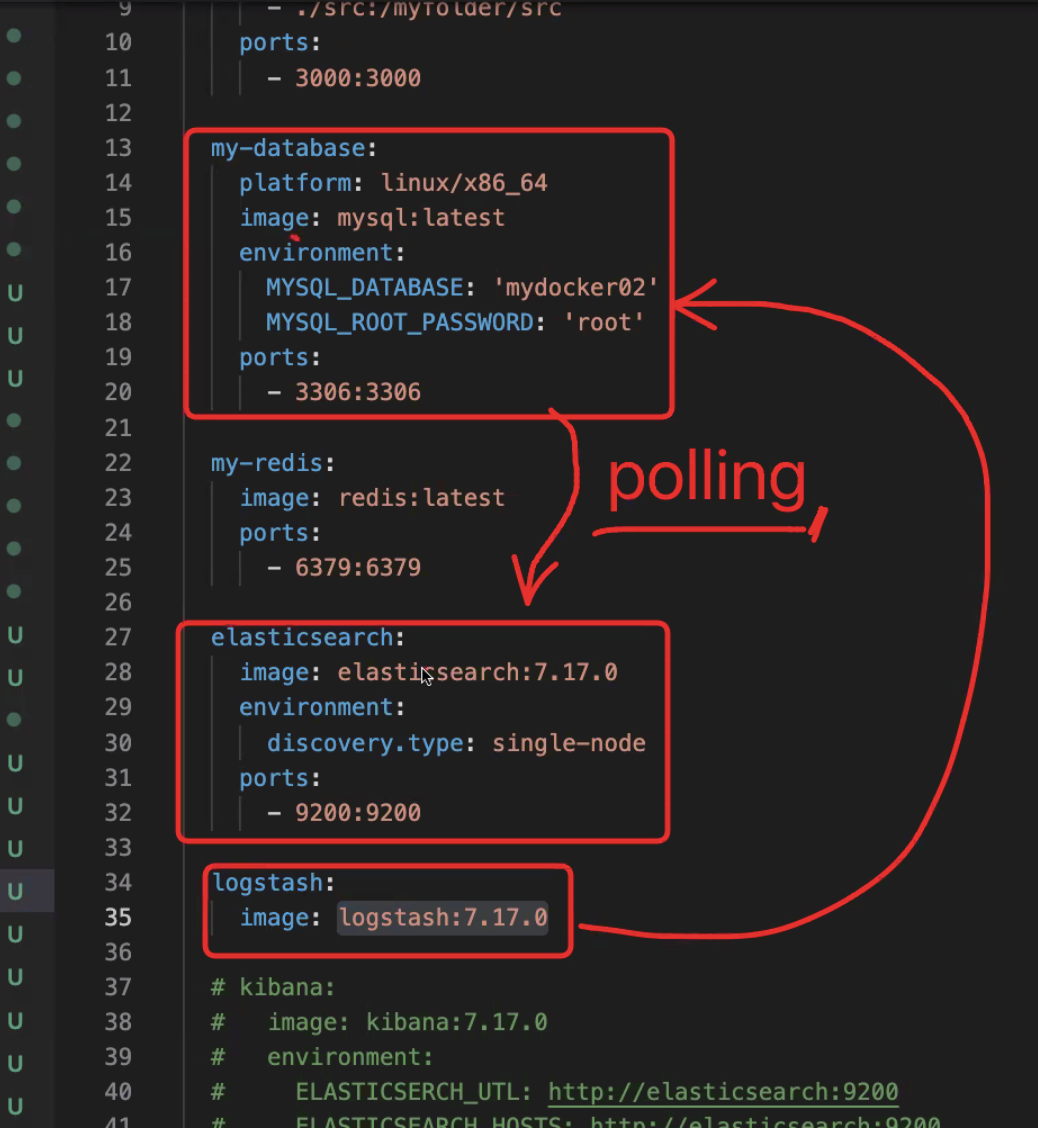
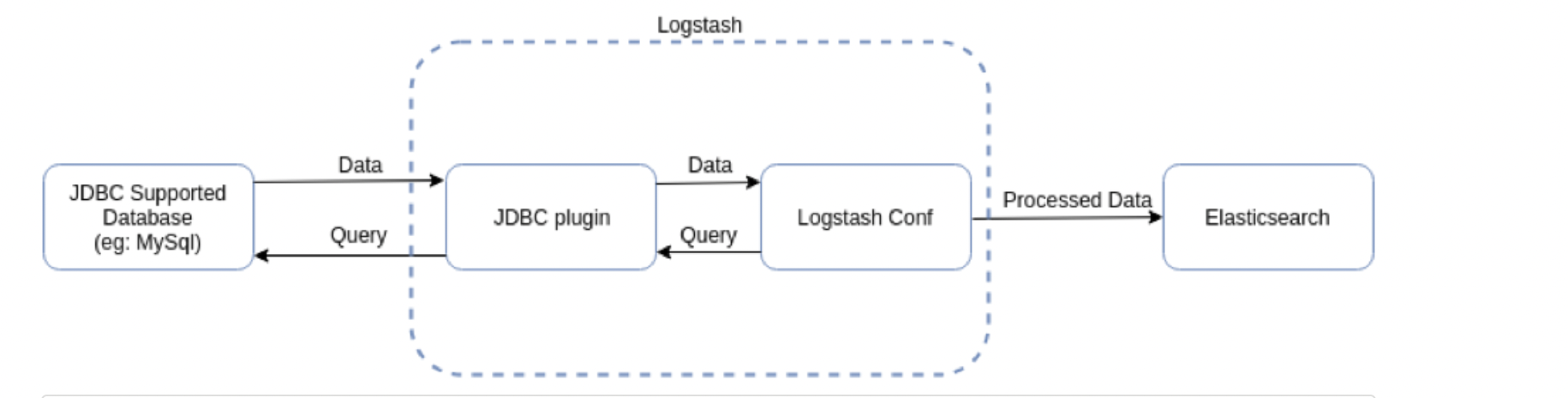
- JDBC input Plugin :
JDBC input Plugin은 Logstash의 많은 내장 인풋 플러그인 중 하나이다. MySQL처럼 기본적으로 JDBC Interface를 지원하는 모든 데이터베이스는 이 인풋 플러그인을 통해 Elasticsearch로 indexing할 수 있다. 개념적으로 Logstash의 JDBC 인풋 플러그인은 주기적으로 MySQL을 폴링하는 루프를 실행한다.- Logstash는 크론 문법을 통해 주기적으로 데이터를 가져올 수 있고, 한 번만 실행시켜 데이터를 로딩하도록 설정할 수도 있다. Database에 원하는 JDBC Query를 던지고, Return한 결과에서 각 Row가 하나의 이벤트로 맵핑되며 Column이 Elasticsearch의 Field로 대응되는 형태로 indexing한다.
- Kibana : Elasticsearch는 RESTFULgkrh, JSON 형식 Data로 통신하기 때문에 HTTP Protocol을 이용해 어떤 클라이언트와도 손쉽게 연동이 가능하다. 따라서 개발자들이 ES와 연동되는 다양한 시각화 도구를 개발하였고, 그 중 가장 널리 쓰이는 것이 Kibana이다.
그리고 검색과 Aggregation의 집계 기능을 이용해 Elasticsearch로 부터 문서, 집계 결과 등을 불러와 웹 도구로 시각화 및 모니터링을 한다.(Dbvear 같은 거)
- 결론은 문장은 Elasticsearch, 일반적으로는 MySQL에서 가져 오면 된다.
- 설치 :
1. yarn add @nestjs/elasticsearch
- yarn add @elastic/elasticsearch
마무리
=> 이 주제는 어떠한 서비스 중에서도 중요한 부분이다. 지금은 개념이나 설명 위주로 블로깅 했지만, 이 API를 만들었을때 다시 업데이트 해야겠다 ㅎㅎ

끝날때 까지 끝난게 아니야. 결국 내가 이겨!