Introduction
-
이미지 모델 : 이미지만 학습한 모델로 일반화 능력이 부족하고 이미지를 얼마나 더 잘 표현하느냐에 집중해옴
-
자연어처리 모델에 비해 작은 모델, 데이터셋 크기 (ImageNet → 레이블을 직접 달아야함)
-
주어진 카테고리 내에서만 예측을 수행해왔음
-
VirTex, ConVIRT와 같은 모델이 transformer-based language modeling, contrastive objectives의 가능성을 보여줌
-
VirTex :
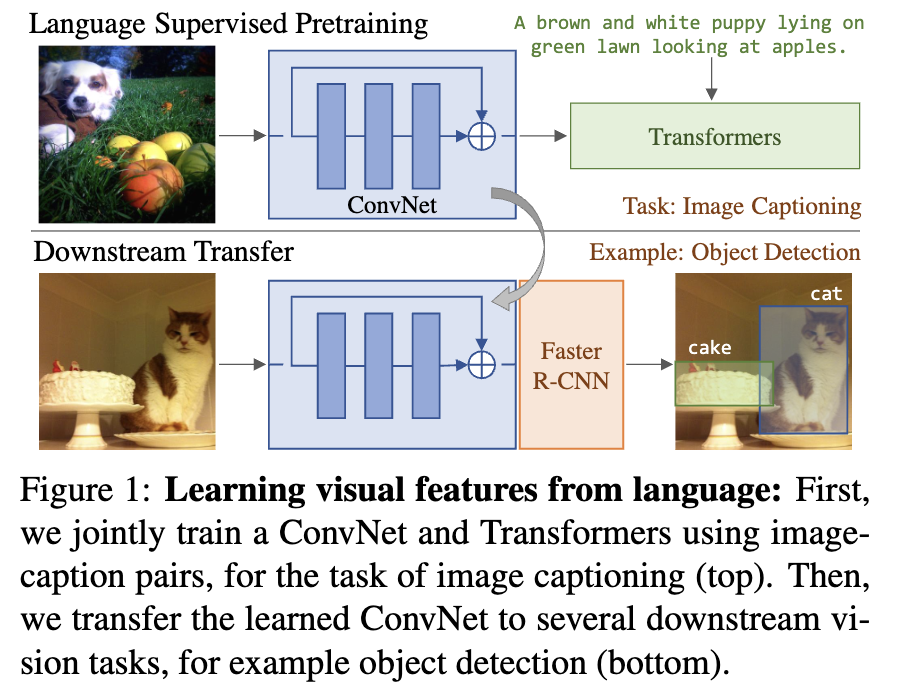
- Transformer 기반 언어 모델링을 통해 이미지에서 텍스트 설명 생성
- 이미지 캡셔닝에 초점, 텍스트 생성을 통해 이미지의 표현을 학습
- Transformer를 통해 나온 language supervision이 semantic density를 가지기 때문에 효과가 좋음
-
ConVIRT :
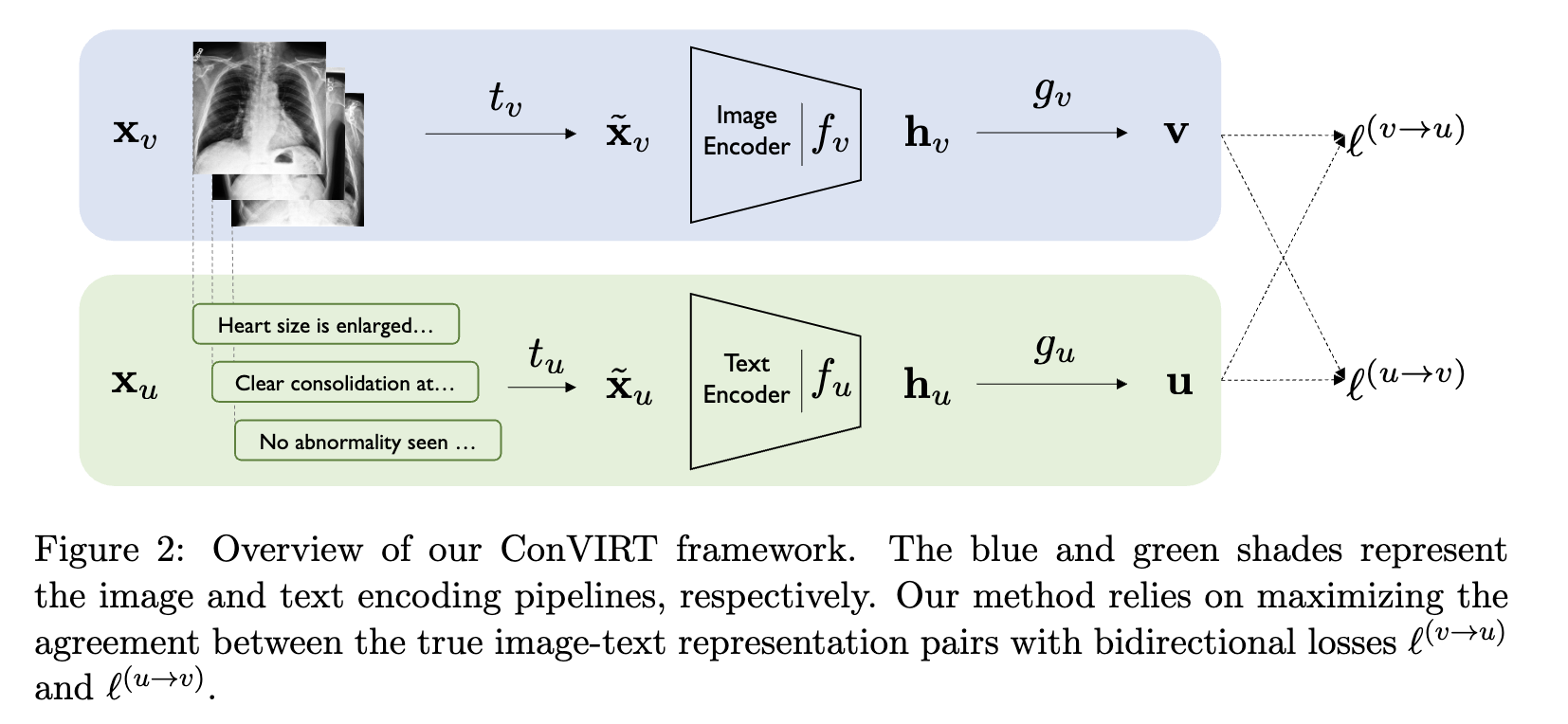
- 의료 이미지 - 텍스트에 대해 contrastive learning 적용
- ConVIRT의 간략화된 scratch부터 학습한 것이 CLIP
-
-
contrastive objective learning 기술 사용
Approach
-
efficient pre-training method

- VirTex와 비슷하게 text transformer와 image CNN을 사용하여 image classification
- ResNet-50 image encoder 보다 2배 더 많은 계산을 통해 ImageNet 클래스를 인식하는데 baseline보다 3배 느리게 학습
- 이미지에 맞는 정확한 단어를 예측하려고 하기 때문
- CLIP → 정확한 단어가 아니라 전체적으로 어떤 텍스트가 어떤 이미지와 쌍을 이루는지 예측하는데 집중
- VirTex와 비슷하게 text transformer와 image CNN을 사용하여 image classification
-
natural language supervision
- WIT dataset 구축 : 4억개의 (이미지-텍스트) 쌍
- 인터넷에서 모은 대규모 데이터로, 이미지마다 달려있던 자연어 문장을 그대로 supervision으로 사용
- 기존의 레이블이 달려있는 데이터셋과 다른점
- WIT dataset 구축 : 4억개의 (이미지-텍스트) 쌍
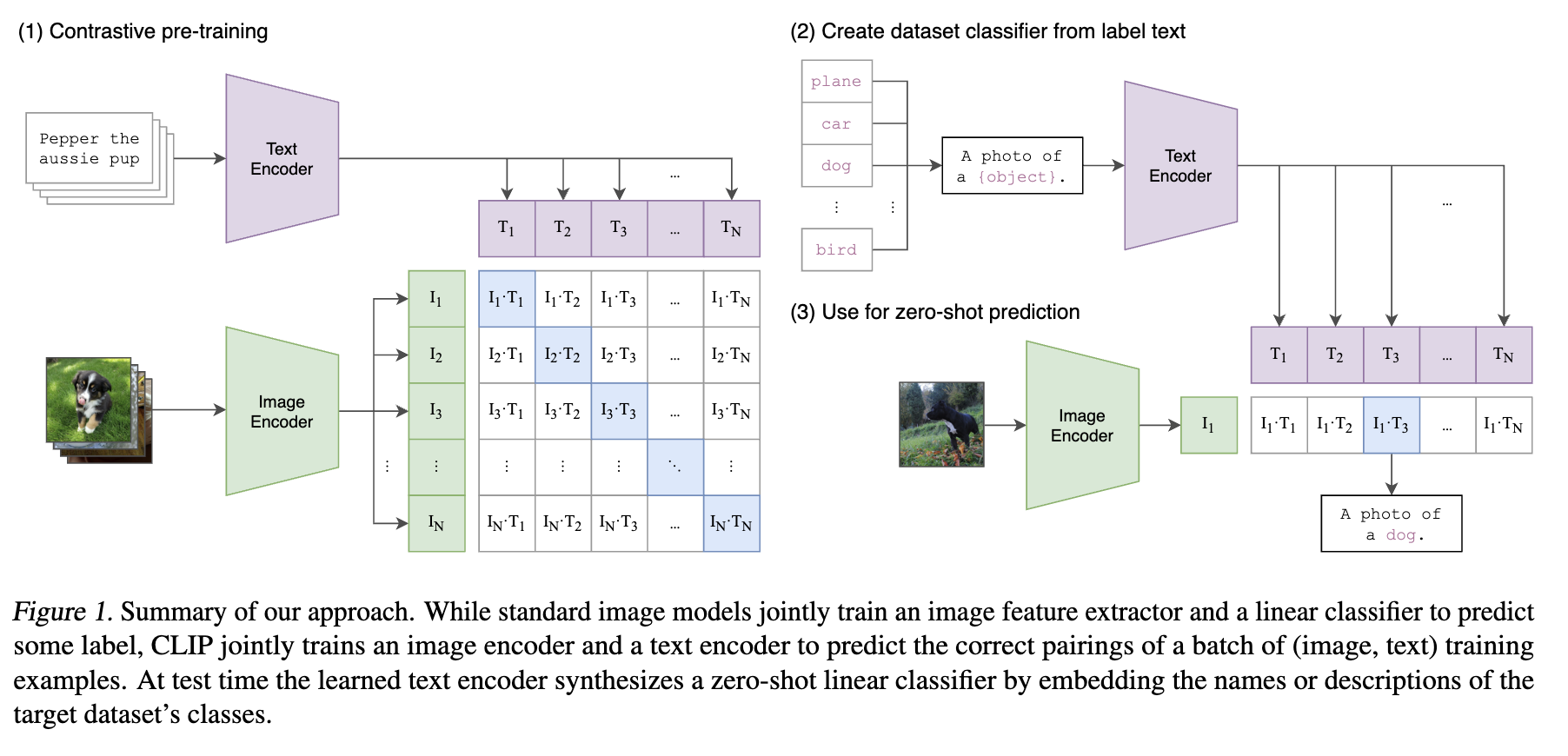

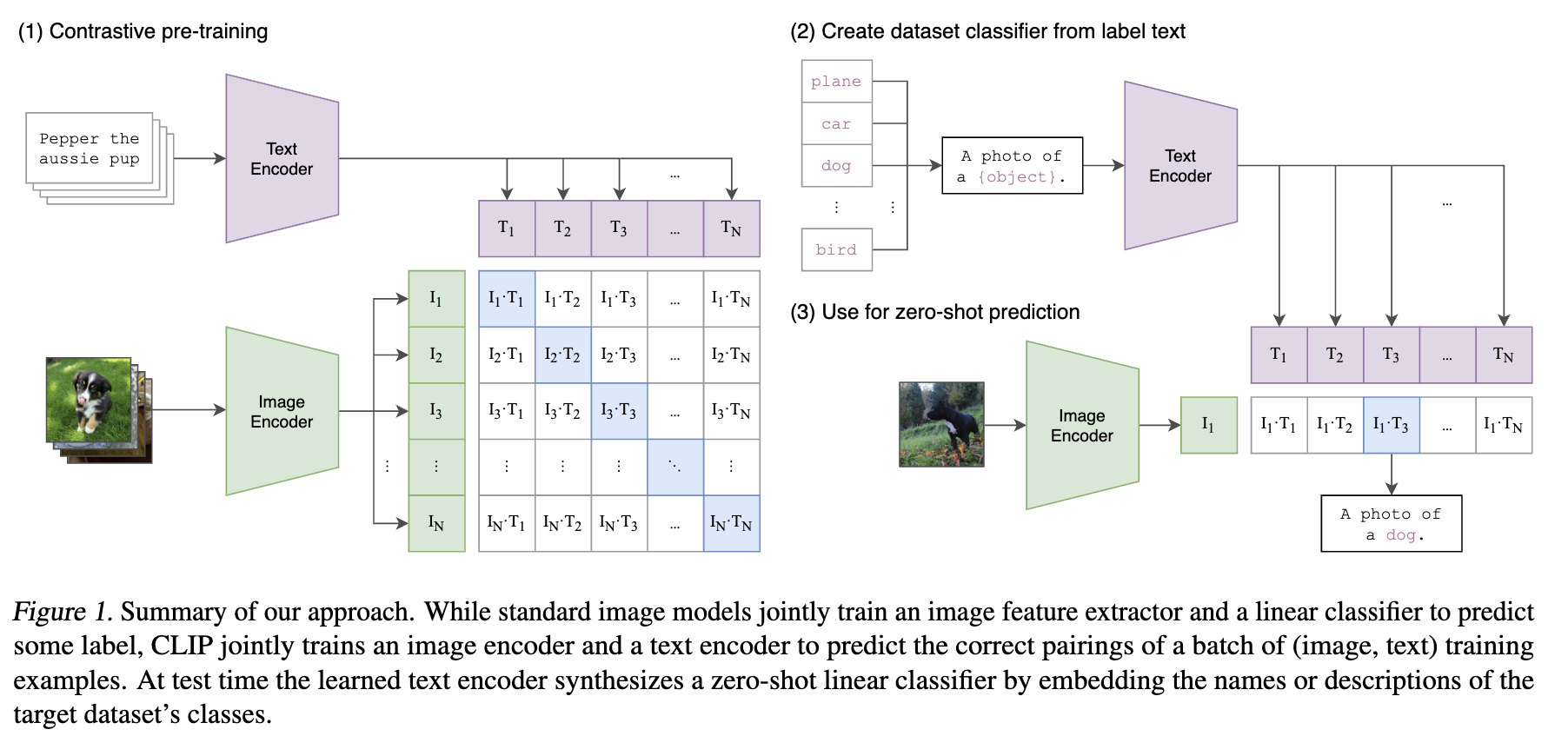
Contrastive pre-training
- image representation & text representation 추출
- 이전의 contrastive pre-training과 다른 지점
- early → single modality base (image - image / text - text) ⇒ Single encoder
- CLIP → multi modality base (image - text) ⇒ Image encoder, Text encoder
- early → single modality base (image - image / text - text) ⇒ Single encoder
- 이전의 contrastive pre-training과 다른 지점
- 총 쌍 중 positive pairs 개, negative pairs 개
- early → 같은 modality 내의 data augmentation을 통해 positive & negative pair를 구성함
- CLIP → image - text pair를 positive sample로, 다른 image - text 조합을 negative sample로 사용
- 전자의 cosine similarity 최대화, 후자 최소화하는 방향으로 인코더 학습 = 매칭되는 데이터는 가까워지고, 매칭되지 않는 데이터는 멀어지게끔 이미지와 텍스트 멀티모달의 임베딩 공간을 학습
Encoder
- Image : ResNet (Attention pooling), ViT
- transformer와 유사한 multi-head QKV 구조를 채택
- query가 global average-pooled representation에 의해 조절
- Text : Transformer
Zero-shot prediction
-
문장 형태 → text encoder → text representation (vector)
-
앞서 학습된 이미지 인코더에서 나온 이미지 벡터와의 유사도가 가장 높은 텍스트 선정
-
각 task에 대해 prompt를 적절히 설정하면 더 나은 분류 성능을 볼 수 있음
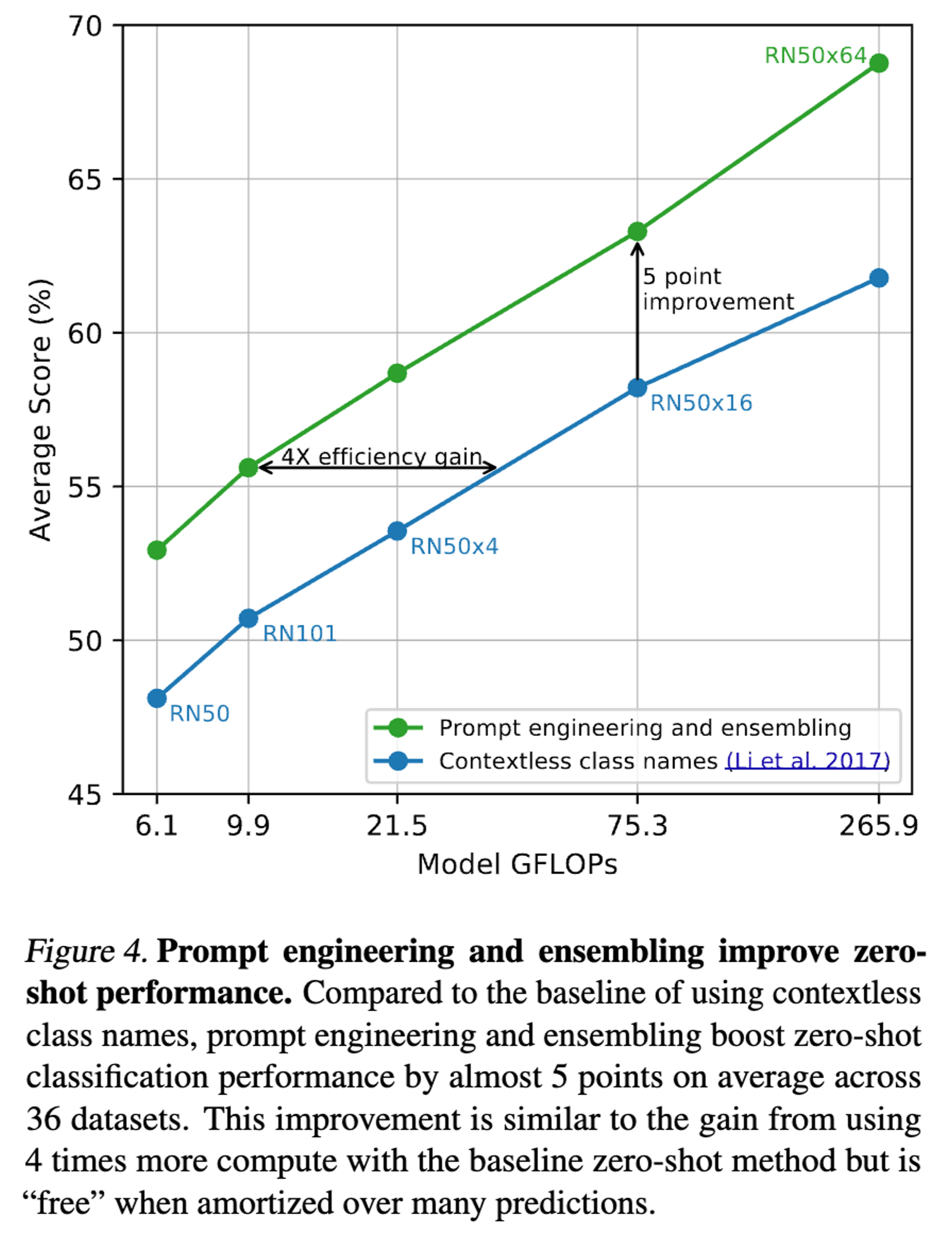
- Prompt engineering, ensembling을 적용 시 약 5포인트의 성능 향상
- 기존 방식의 4배된 연산 효과를 낼 수 있음
- 추가 연산 비용 필요 없음
Experiments
-
Zero-shot CLIP
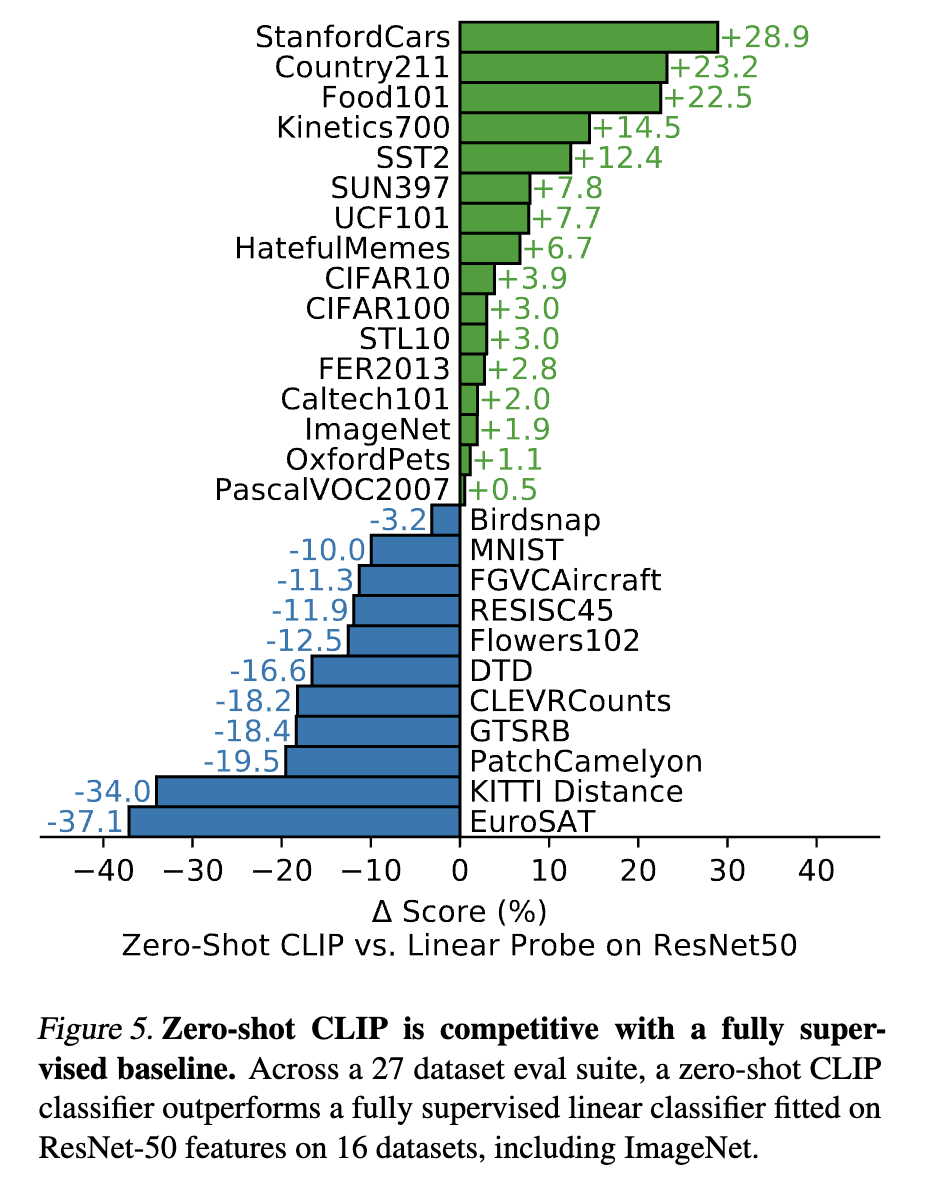
- STL10 dataset : SOTA 달성
- MNIST, EuroSAT, PatchCamelyon 등의 데이터셋은 학습 데이터 셋에 포함되지 않음
- 특이하거나 복잡하고 추상적인 task에 대해서는 성능이 좋지 못했다
-
Zero-shot VS. Few-shot
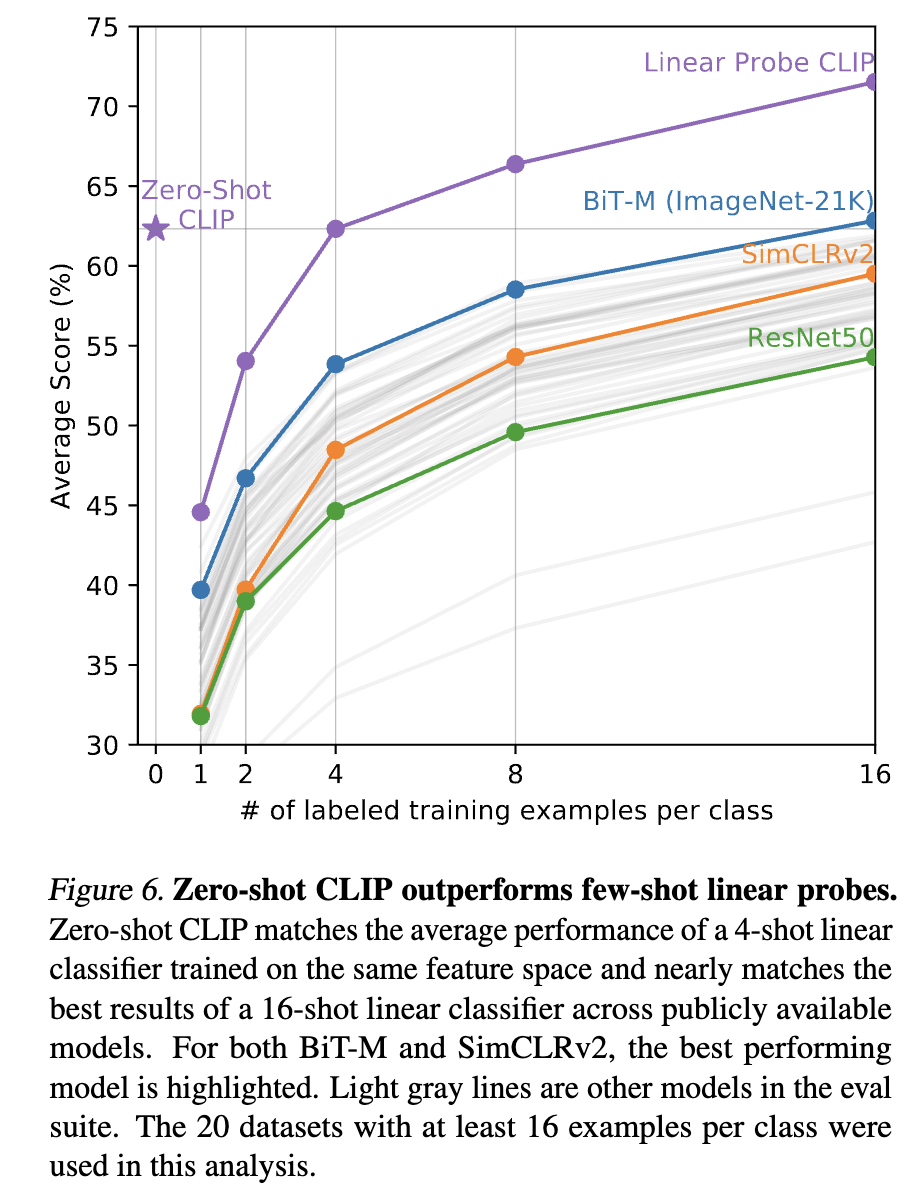
- few-shot : 훈련 데이터 클래스 당 샘플 몇개만을 linear layer로 붙여서 학습
- 4개 미만의 샘플로 훈련시, zero-shot보다 성능이 뒤처짐
- one-shot : Zero Shot 성능에 특화된 CLIP, 이전의 학습 과정을 무시하고 Few shot으로 재학습하는 과정에서 기존 학습된 파라미터가 모두 변경되면서 성능이 하락한 것으로 볼 수 있음
-
Zero-shot CLIP performance
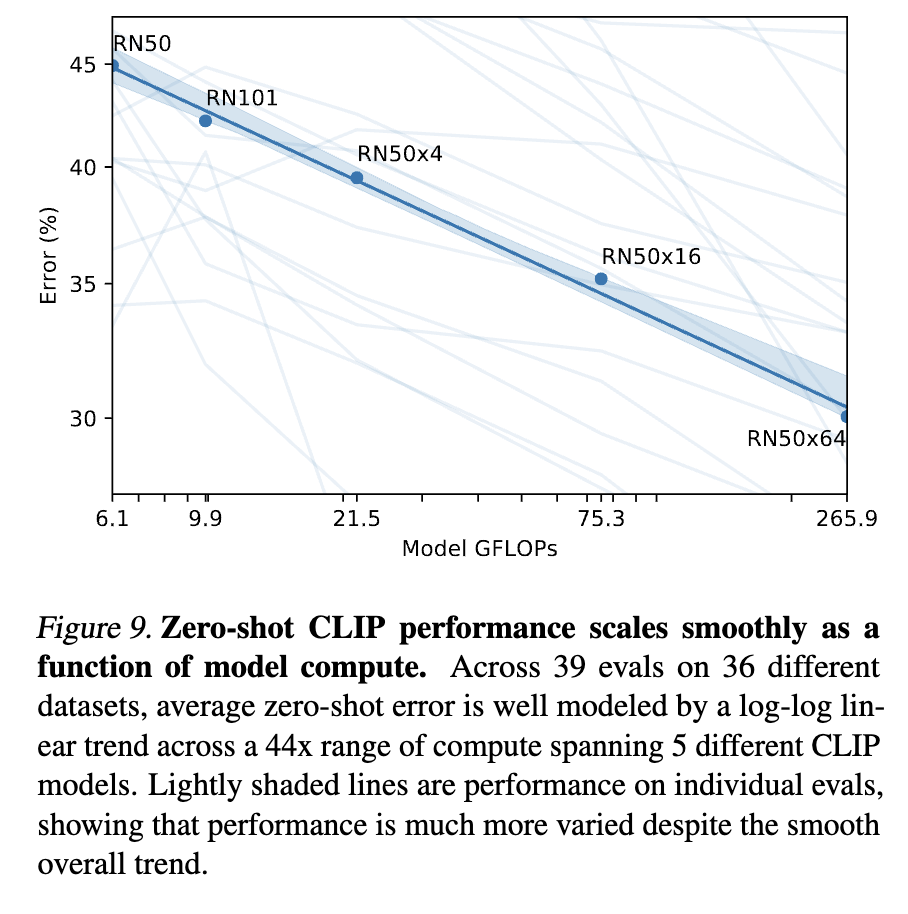
- 모델의 크기가 커질수록 성능이 개선됨을 확인
- 특정 태스크, 데이터셋에서는 성능 향상이 꼭 일어날 것이라고 보기 어려움
-
Robustness on natural distribution shift

- image variance에도 성능이 좋았다
-
사람과의 비교

- 사람의 zero, one, two -shot 보다 zero-shot CLIP의 성능이 좋았다
- 우리는 무엇을 알고 있는지, 모르고 있는지를 알고 있기 때문에, 하나의 샘플만 주어져도 기존 지식과 비교해가며 새로운 정보를 잘 일반화하여 해석할 수 있음.
