Abstract & Introduction
문서 이해는 단순한 텍스트 분석이 아니라, 텍스트 + 레이아웃 + 이미지를 함께 고려해야 하는 멀티모달 문제이다. 하지만 기존 모델들은 텍스트와 이미지 정보를 얕게 결합하거나, 특정 문서 형식에 최적화되어 일반화에 한계가 있었다.
LayoutLMv2는 이러한 문제를 해결하기 위해, 세 가지 정보를 사전학습 단계에서부터 하나의 Transformer 안에 통합하고, 2D 상대 위치 정보와 cross-modality pretraining task를 함께 도입한 모델이다. 그 결과, 다양한 문서 이해 벤치마크에서 기존 SOTA를 뛰어넘는 성능을 달성하며 멀티모달 문서 이해의 새로운 기준을 제시했다.
Approach
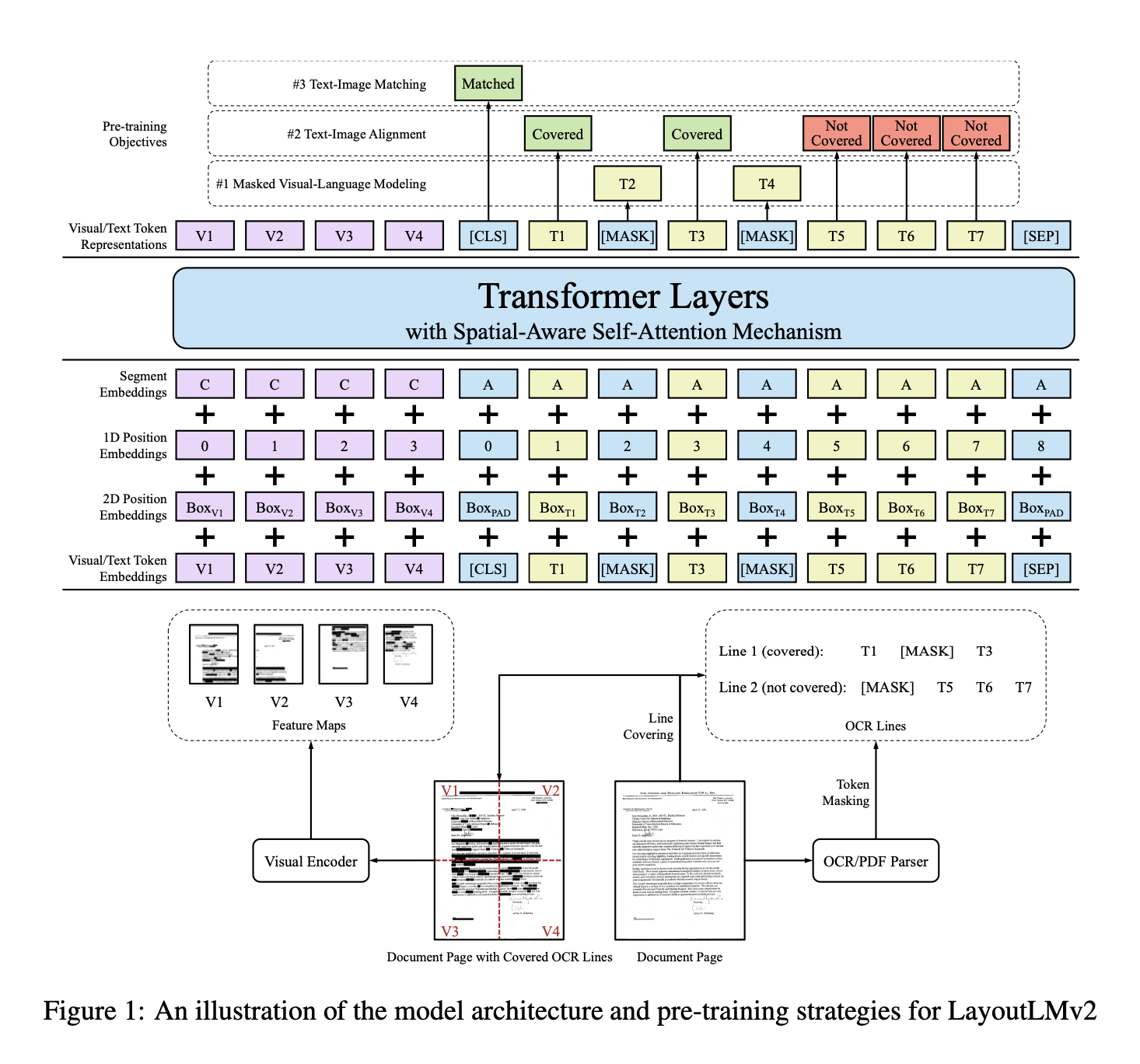
- input : text, visual, layout information
Text Embedding
- token embedding : 토큰 자체의 의미
- 1D position embedding : 한 문장 내에서 해당 토큰이 몇번째 토큰인지 순서를 나타내는 임베딩
- segment embedding : layout에서 segment를 구분하기 위함 → ex) document에서 질문/답변 OR 제목/본문 등 …
Visual Embedding
- CNN 기반 visual encoder를 통해, image feature map을 생성한다 → page image ⇒ fixed-length sequence

🧐
1D positon embedding을 text와 공유해서 사용해도 되는 것? 번호를 매기는 기준이 다른데 그래도 되는 것인가?
→ text의 position embedding 1과 visual의 position embedding 1은, segment embedding과 함께 concat 되어 사용되기 때문에, 알아서 텍스트/이미지 위치라는 것을 transformer가 이해한다!
- 1D position embedding : 이미지의 왼쪽 상단 → 오른쪽 하단 으로의 방향으로 인덱스를 매긴다
- segment embedding : 이미지를 나타내는 하나의 토큰을 지정해서 넣어주면 된다 (text와 구분되는 것으로)
Layout Embedding
OCR을 통해 얻은 token의 위치정보를 벡터로 변환해서 Transformer에 넣게 되는 embedding
- Transformer 기반 모델들은 보통 text 입력을 1차원 시퀀스로 처리함
→ 하지만 문서에서의 text는 공간에 배치된 것 이라는 차이가 있다
2D 레이아웃 정보가 필수적이다 !!
- OCR으로부터의 text token의 bounding box 좌푤르 기반으로 각 token마다 layout embedding을 추가한다
⇒ bounding box 정보
- OCR에서 추출된 text box의 절대 위치 & 크기를 의미한다
- 각 x축, y축 방향의 위치 정보를 embedding 벡터로 변환해주는 역할이다
이렇게 추출된 layout embedding에 맞추어, visual embedding과 text embedding과 하나하나 매핑해준다 (bounding box를 기반으로). 이때, text embedding 중 [CLS], [SEP], [PAD]는 위치가 따로 없기 때문에 (0, 0, 0, 0, 0, 0)의 padding값과 매핑해준다.
Multi-modal Encoder with Spatial-Aware Self-Attention Mechanism
LayoutLMv의 인코더는 문서라는 특수한 input을 다루기 위해 ‘레이아웃’이라는 것을 이해할 수 있도록 하는 인코더를 가지고 있다.
text와 visual 정보를 하나로 묶는다
- visual embedding과 text embedding을 하나의 시퀀스로 이어붙인다
- 각 토큰에 Layout embedding을 더한다
⇒ Transformer의 input이 된다
⚠️
기존의 self-attention은 순서 기반의 위치 정보(index)만을 사용해서 구조적인 이해를 하지 못하는 한계점이
존재했다.
→ 앞서 말했듯, 문서에서의 텍스트는 어느 공간에 있느냐가 중요하다 Relative spatial relationship
ex. 오른쪽에 있는 표, 그림, 텍스트그래서 이 논문에서는 Spatial-Aware Self-Attention을 제안한다. 텍스트와 이미지를 모두 문서 공간 위에 있는 ‘객체’로 보고, 토큰 간의 위치 차이를 기반으로 attention score를 조절한다.
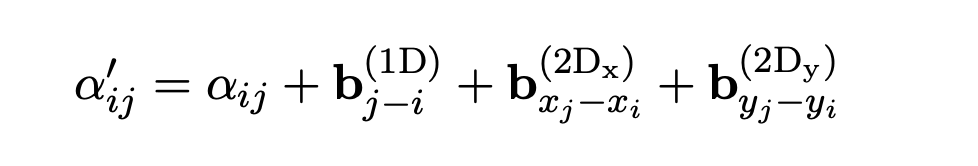
여기서
: query ↔ key 사이의 유사도 즉, 관계 강도를 의미한다 (기존의 self- attention)
bias :
- 시퀀스 상의 상대적 위치 (쉽게 말하자면, 단어와 단어 사이의 간격 정도)
- 문서 상의 x축 기준 상대 좌표 (다른 토큰에 비해 x축 방향으로 얼마나 떨어져 있는지)
- 문서 상의 y축 기준 상대 좌표 (다른 토큰에 비해 y축 방향으로 얼마나 떨어져 있는지)
bias는 transformer가 상대 위치에 따라 자동으로 학습한다.
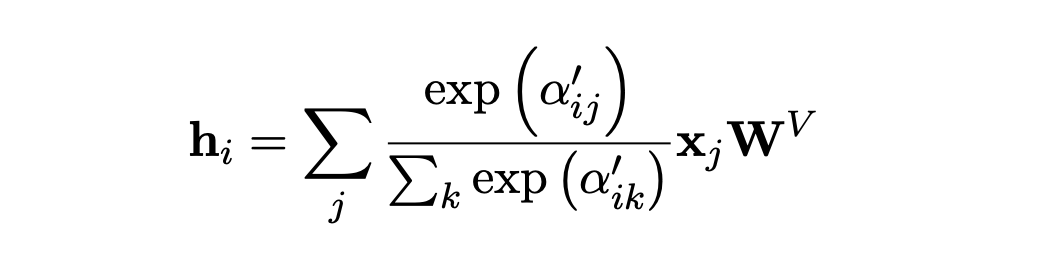
그래서 최종적으로, 이러한 output이 만들어진다. 해당 백터는 그 토큰의 ‘의미 + 위치 + 주변 공간 맥락’을 모두 반영한 벡터 표현이라고 할 수 있다.
이런 구조 덕분에, 우리는 문서의 배치 구조를 토큰 간의 관계로 학습할 수 있게 된다.
Pre-training Tasks
Masked Visual-Language Modeling (MVLM)
텍스트의 일부를 마스킹하고, 모델이 문서 안의 이미지와 레이아웃을 참고해서 텍스트를 예측하도록 하는 과제
이때, 텍스트를 마스킹하는데 위치 정보(레이아웃 정보)는 지우지 않고 그대로 둔다. 그래서 모델은 여전히 해당 텍스트가 문서의 어디에 있었는지를 알고 있다. 그래서 모델은 “이 위치에 이름이 있었는데 내용이 가려졌군?” 하면서 해당 위치에 올 법한 단어를 추론할 수 있게 된다.
이때 마스킹된 토큰의 출력 벡터는 모든 vocabulary에 대한 softmax classifier를 거쳐 가장 높은 확률을 가진 단어를 예측하게 된다. 이 과정에서 cross-entropy loss를 사용하여 모델을 학습시킨다.
그리고 모델이 이미지로 정답을 ‘컨닝’하는 것을 방지하기 위해, 텍스트 마스킹 위치에 대응해서 이미지 영역도 같이 마스킹한다고 한다.
Text-Image Alignment (TIA)
모델이 텍스트 토큰과 이미지 영역이 연결되어 있다는 것을 학습하도록 돕는 과제 (가려진 이미지 영역의 해당하는 텍스트를 ‘찾는’ 느낌)
여기서는 masking이 아니라 covering의 방식을 사용한다. Covering은 문서 이미지에서 특정 줄의 이미지 영역 자체를 지워버리는 것을 의미한다.
이렇게 이미지 일부를 가린 상태에서, 모델은 각 텍스트 토큰이 이미지에서 가려졌는지 아닌지를 예측해야 한다. (Covered or. Not Covered를 예측함)
이때, 텍스트는 그대로 입력되기 때문에 모델은 토큰의 의미 + 위치 정보 + 이미지의 유무를 종합적으로 고려하게 된다. 그리고 TIA는 앞서 설명한 MVLM과 동시에 수행될 수도 있는데, 이럴 경우 마스킹된 토큰은 TIA 대상에서 제외한다고 한다. 모델이 단순히 [MASK]면 [Covered] 겠지? 하고 쉽게 외워버리는 것을 방지하기 위함이라고 한다.
Text-Image Matching (TIM)
문서 이미지와 텍스트가 같은 페이지에서 왔는지를 맞히는 과제 (텍스트와 이미지가 서로 관련이 있는가?를 판단할 수 있도록 하는 훈련이다)
모델은[CLS] 토큰의 출력 벡터를 활용해서 텍스트와 이미지가 같은 페이지인지 아닌지를 분류한다. 입력 샘플을 구성할 때, 정상적인 조합은 positive sample, 아닌 경우는 negative sample로 만든다. 이때 negative의 경우, 이미지를 다른 문서 페이지 이미지로 바꾸거나, 이미지를 아예 제거해버리는 방식으로 만든다. 이 샘플을 모델에게 알려주고, binary classification을 학습시킨다.
그리고 negative에서는 치팅하지 못하도록, text masking과 image covering을 적용한다.
Experiments
Data
-
pretraining용 데이터셋 : IIT-CDIP
실제 문서 구조와 텍스트가 섞여있어서 사전학습에 적합하다고 한다
-
Downstream Task용 데이터셋 : 나머지
폼 문서에서의 추출 데이터, 영수증, 법률 문서 등등의 데이터셋이다
Settings
Pre-training
이 모델은 base / large 두가지 크기로 구성된다. 두개 모두 UniLMv2 기반 transformer encoder를 사용하고 visual 정보는 ResNeXt101-FPN 구조를 통해 추출한다. 텍스트 임베딩은 UniLMv2의 사전 학습된 가중치로 초기화되고, ResNeXt101-FPN은 PubLayNet에서 학습된 Mask R-CNN 백본을 사용한다. 그 외 나머지 파라미터들은 랜덤으로 초기화된다.
그리고 앞서 설명한 MVLM, TIA, TIM 과제를 동시에 학습한다.
Fine-tuning
우리 모델은 다양한 문서를 이해하는 과제에 적용하기 위해, task 유형에 따라 각기 다른 방식으로 fine-tuning한다.
-
문서 분류 (RVL-CDIP)
[CLS] 토큰의 출력 + 시각 정보 평균값을 함께 사용해서 문서 전체를 요약한 전역적 특성을 기반으로 분류한다
-
엔티티 추출 & QA
BERT에서 자주 사용하는 것처럼, 텍스트 토큰마다 classifier head를 붙여서 fine-tuning한다.
ex. 각 토큰이 entity의 시작인지, 질문의 정답 범위에 포함되는지 … 등 예측
-
DocVQA 특화
step 1) QG데이터셋으로 먼저 fine-tuning
step 2) DocQA 데이터셋으로 최종 fine-tuning
이 방식을 통해 모델이 질문 형태, 문서에서 정답을 찾는 방식에 더 잘 적응할 수 있게 된다
Baseline
BERT (텍스트 only), UniLMv2, LayoutLM (전작)과 비교하여 test를 진행했다
Result
Entity Extraction Task
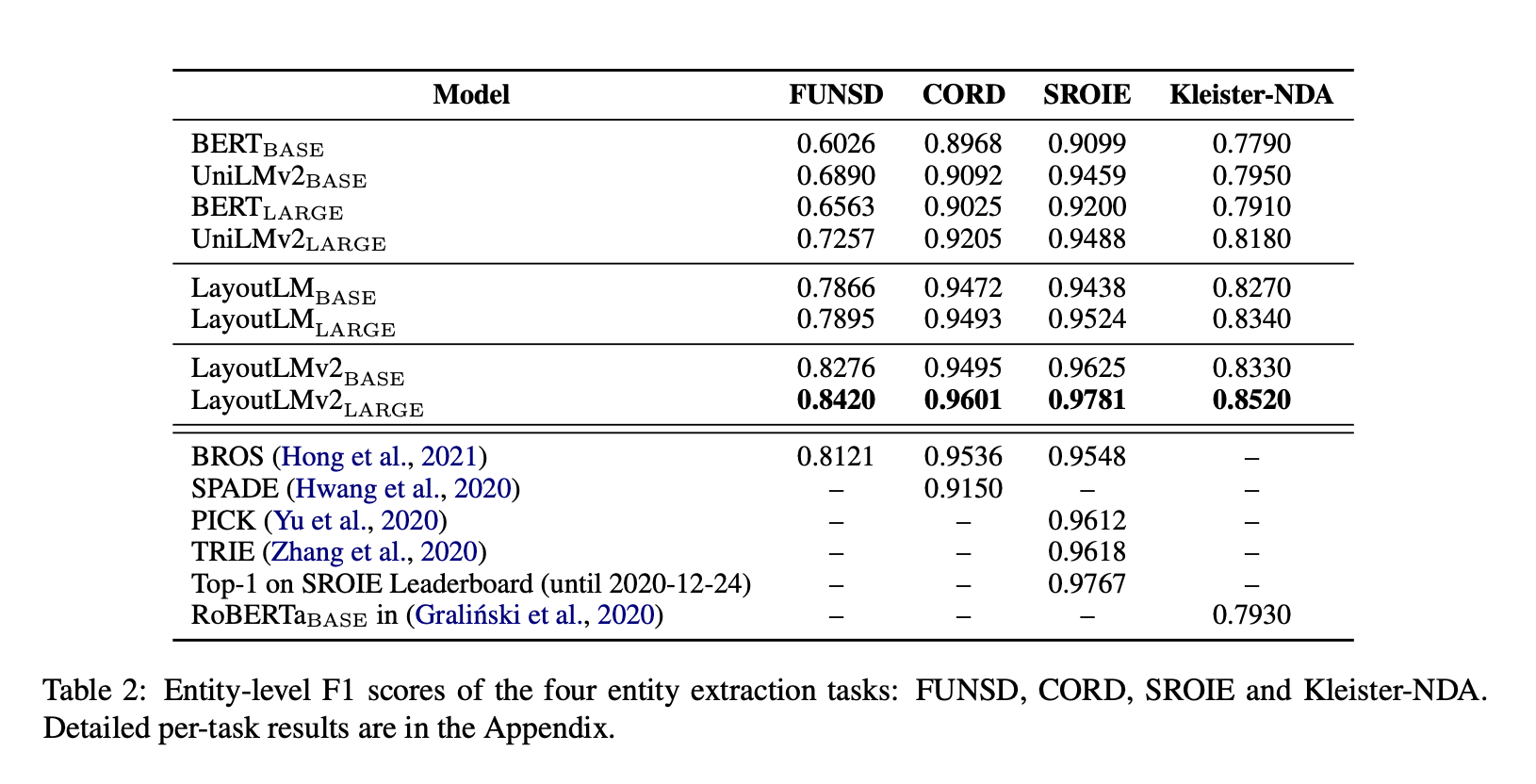
Entity를 추출한느 과제 네가지를 수행했을 때, LayoutLMv2가 대부분의 과제에서 기존 Sota 모델보다 우수한 결과를 낸 것을 확인할 수 있다.
RVL-CDIP
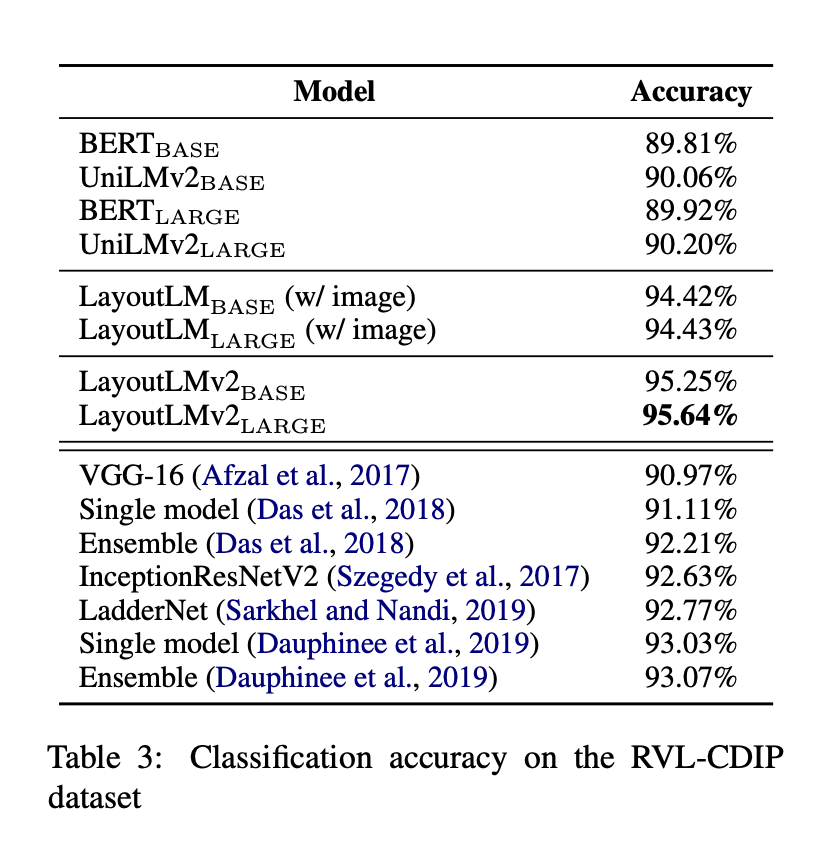
문서 이미지가 16개의 카테고리 중 어떤 유형인지 분류하는 실험
ex. letter, form … → 이런 식의 문서 타입을 맞히는 과제
여기서 (w/image) 표기된 모델은, 원래 이미지 정보 없이 학습되던 LayoutLM에 추가로 이미지 특징까지 넣어본 실험을 의미한다. 구조적으로 잘 이미지를 포함시킨 것이 아니기 때문에 LayoutLMv2보다 성능이 낮게 나온 것을 확인할 수 있다.
DocVQA
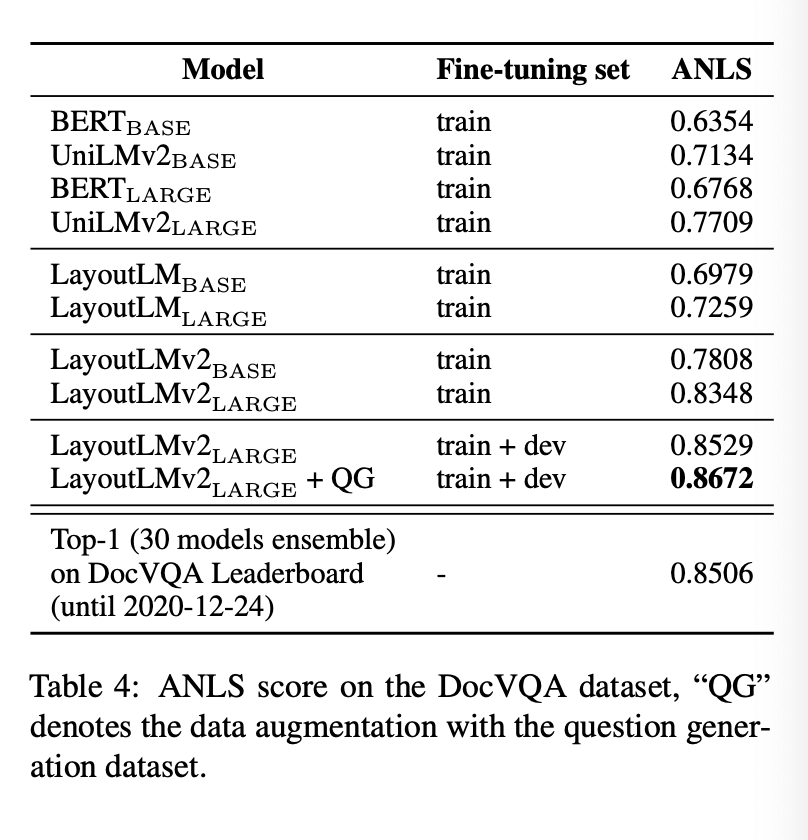
문서이미지에 기반하여 질문에 답하는 과제
ANLS 평가 지표 : 정답 문자 ↔ 예측 간의 유사도를 측정하는 지표로, 값이 1에 가까울 수록 정확한 답변을 생성했다고 본다.
QG 데이터셋을 통한 질문응답 구조의 사전학습을 한 경우, 가장 높은 성능을 보였다. 단일 모델 기준으로 leaderboard 1위를 기록했던 30개 앙상블 모델보다도 높은 ANLS 점수를 기록해 DocVQA에서 새로운 SOTA를 달성했다.
ablation study

visual module 유무, pretraining task구성, SASAM 구조 여부, 텍스트 인코더 초기화에 대해 어떤 구성 요소가 실제 성능에 기여했는지를 알아보았다.
TIA와 TIM 같은 cross-modality pretraining task는 각각 또는 함께 적용했을 때 더 큰 성능 향상을 보였다. 여기에 SASAM을 추가하면 모델의 문서 구조 이해가 더 정교해졌고, 마지막으로 UniLMv2로 텍스트 인코더를 초기화했을 때 가장 높은 성능을 기록해 모든 요소를 조합했을 때 최적의 결과를 달성할 수 있음을 확인할 수 있다.
Conclusion
LayoutLMv2는 기존 모델들과 달리 텍스트, 레이아웃, 이미지 정보를 통합적으로 고려하는 프레임워크를 통해 사전학습을 하고, SASAM를 도입하여 모달 간의 상호작용을 효과적으로 학습할 수 있었다. 다양한 task에서 기존 SOTA 모델들을 뛰어넘는 성능을 보여주었고 실제로 문서 기반 애플리케이션에 활용될 수 있는 정도의 가능성을 보여주었다.
다음 리뷰에서는 OCR 없이 end-to-end 방식으로 문서 이미지를 이해하는 네이버의 Donut 모델을 살펴볼 예정이다..
