판다스 데이터프레임의 커다란 강점은 바로 인덱스가 존재한다는 것이다. 이를 통해 데이터 핸들링의 자율성이 크게 높아진다. 본 글에서는 index를 다양하게 사용하는 방법을 살펴본다.
-
인덱스란?
-
우리말로 '색인'이라는 의미를 갖는 인덱스는 iterable한 자료형에서 요소의 위치를 의미한다. 값을 찾는 대신 인덱스를 찾음으로써 더욱 빠르고 체계적으로 데이터를 처리할 수 있다.
-
인덱스를 행 인덱스만으로 이해하는 경우가 있는데 인덱스는 열 인덱스, 즉 칼럼까지도 포함하는 개념이다.
-
-
Multi-index
- 중첩되어있는 인덱스를 의미한다. 여러 변수를 이용한 groupby 객체에서 생성된다. 예를 들면, 자동차(cars)의 연식(model_year)과 생산국가(origin)별 연비(mpg)의 평균을 구하고 싶을 때 아래와 같이 코드를 짤 수 있다.
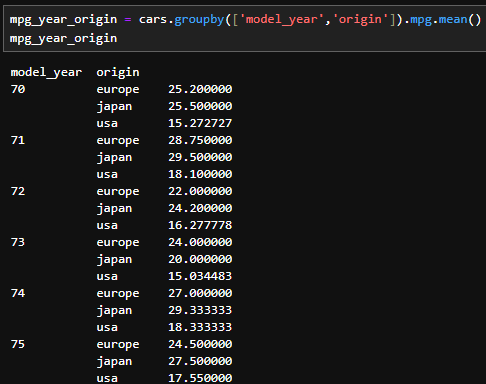
- 여기서 model_year, origin은 Multi-index가 되는데, groupby 객체에서 Multi-index의 각 index별 조건을 튜플(tuple)로 구성하여 값을 추출하는 것도 가능하다. 예를들어, 71년에 미국에서 생산된 차의 평균연비는 아래와 같이 구할 수 있다.
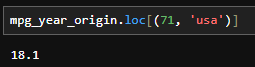
- 물론, 두 index 중 하나의 조건만 걸어서 추출할 수도 있다. 예를 들어, 미국에서 생산된 차의 평균연비를 구할때는 사용하지 않는 index(mode_year)를 slice(None)으로 지정하여 아래와 같이 구할 수 있다.
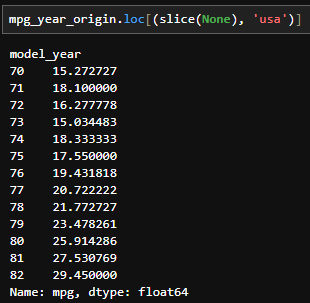
- 중첩되어있는 인덱스를 의미한다. 여러 변수를 이용한 groupby 객체에서 생성된다. 예를 들면, 자동차(cars)의 연식(model_year)과 생산국가(origin)별 연비(mpg)의 평균을 구하고 싶을 때 아래와 같이 코드를 짤 수 있다.
-
swaplevel()
- Multi-index의 순서를 바꾸는 메소드이다. 위 Multi-index에서 model_year와 origin의 인덱스 순서를 바꾸려면 아래와 같이 할 수 있다. -1번째 인덱스와 0번째 인덱스의 레벨(level)을 서로 뒤바꾸었다(swap).
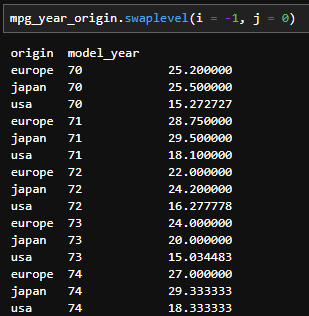
- Multi-index의 순서를 바꾸는 메소드이다. 위 Multi-index에서 model_year와 origin의 인덱스 순서를 바꾸려면 아래와 같이 할 수 있다. -1번째 인덱스와 0번째 인덱스의 레벨(level)을 서로 뒤바꾸었다(swap).
-
reindex
- 기존 데이터프레임에 존재하는 인덱스(칼럼)를 이용하거나 인덱스를 추가하여 새로운 데이터프레임을 만들어낸다. 예를 들면, 다음과 같은 자료가 있다고 할 때
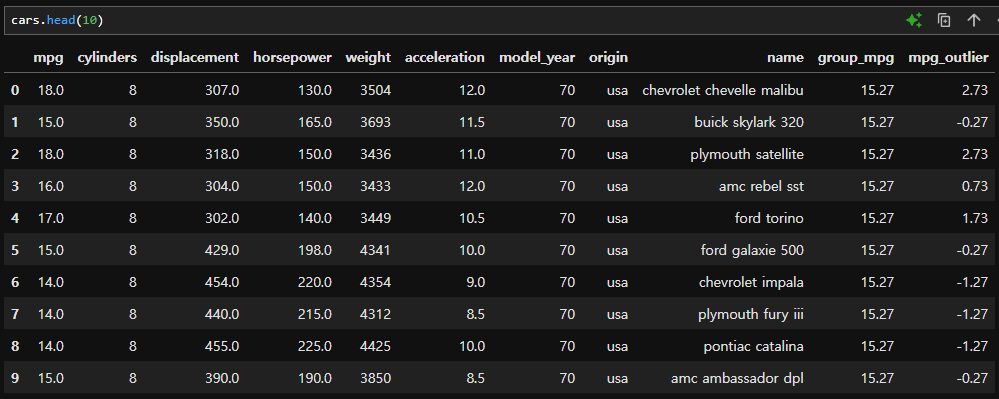
- 아래와 같이 reindexing이 가능하다. 기존 데이터에서 행 인덱스는 0~4까지, 열 인덱스는 'mpg', 'cylinders'를 이용하고 나머지 인덱스는 신규로 생성하였다.
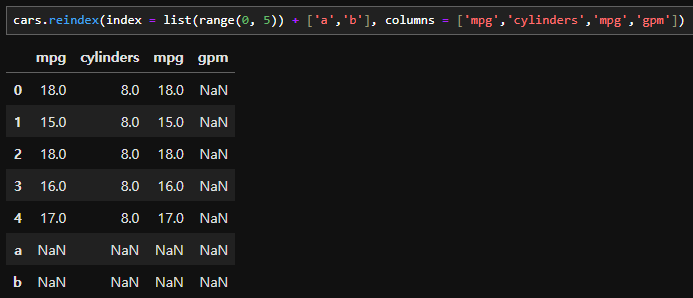
- 기존 데이터프레임에 존재하는 인덱스(칼럼)를 이용하거나 인덱스를 추가하여 새로운 데이터프레임을 만들어낸다. 예를 들면, 다음과 같은 자료가 있다고 할 때
-
stack
- '인덱스를 쌓는다.' 즉, Multi-index를 만드는 메소드이다. 반대의 기능을 하는 unstack이라는 메소드가 존재한다. 데이터가 아래와 같다고 할 때,
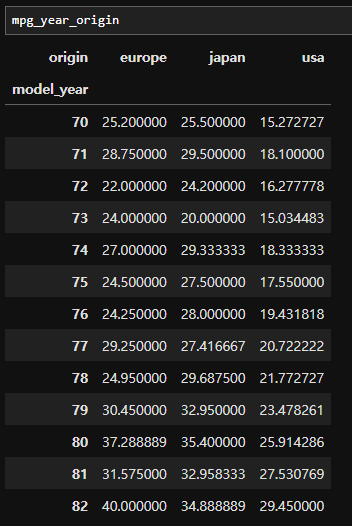
- stack 메소드를 이용하고 level을 -1로 주면 가장 말단에 있는 열 인덱스를 행 인덱스로 쌓는다.
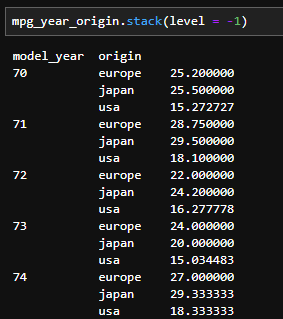
- 만약 model_year를 열 인덱스로 옮기고 싶으면 unstack 메소드를 이용하고 level을 0(첫 번째)으로 주면 된다.
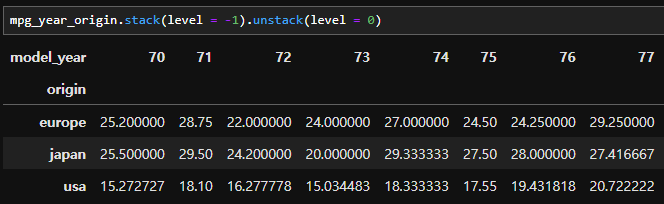
- '인덱스를 쌓는다.' 즉, Multi-index를 만드는 메소드이다. 반대의 기능을 하는 unstack이라는 메소드가 존재한다. 데이터가 아래와 같다고 할 때,
-
insert
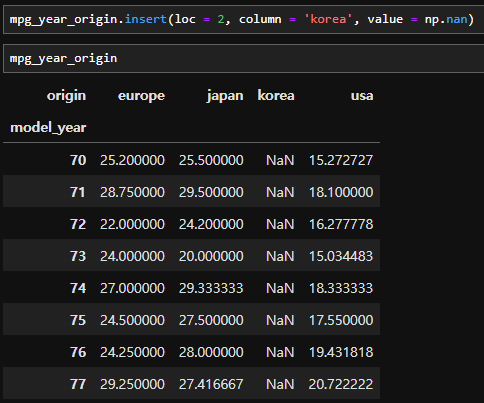
- 열 인덱스(칼럼)를 내가 원하는 위치에 삽입하고 싶을 때 사용할 수 있는 메소드이다. stack의 사례와 같은 데이터가 있다고 할 때, 'japan'과 'usa' 사이에 'korea' 칼럼을 넣고자 한다면 아래와 같이 코드를 짤 수 있다. 즉각 반영이 되는 메소드이므로 사용에 유의한다.
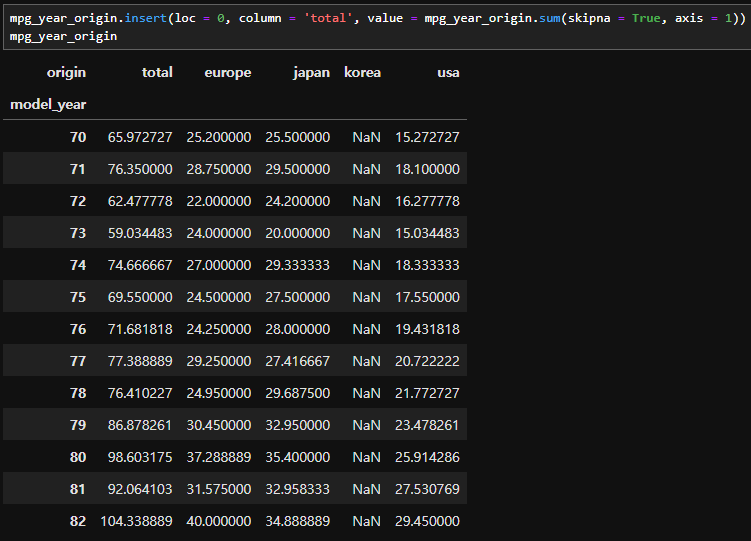
- 값이 들어가는 부분인 value 옵션에는 특정 값 뿐만 아니라 연산 결과 또한 들어갈 수 있다. 예를 들어서, 아래와 같이 열 삽입이 가능하다.
- 열 인덱스(칼럼)를 내가 원하는 위치에 삽입하고 싶을 때 사용할 수 있는 메소드이다. stack의 사례와 같은 데이터가 있다고 할 때, 'japan'과 'usa' 사이에 'korea' 칼럼을 넣고자 한다면 아래와 같이 코드를 짤 수 있다. 즉각 반영이 되는 메소드이므로 사용에 유의한다.
-
ignore_index = True
- 이는 주로 정렬하는 메소드에 등장하는 옵션 중 하나인데, 특정 메소드를 실행할 때 인덱스의 정렬이 섞이는 것을 방지하기 위해 메소드 실행 후 인덱스를 초기화하는 기능을 한다.

의미 있는 한걸음을 추구합니다.