지역별 모델링 결과 요약
- 선형회귀의 기본 가정이 일부 충족되지 않으며 발생환자수와 발생건수가 특정 값에 집중된 결과 좋은 모델 성능을 기대하기 어려워짐 → 분류 모델링을 계획하고 발생확률을 제시하기로 결정
- 식중독 발생여부 데이터가 지역별 분균형 편차를 보임 → 전국 시도 지역별 모형을 각각 모델링하기로 결정
- 식중독이라는 질병을 민감하게 식별하는 데 유리한 지표인 재현율(Recall)을 1순위 평가지표로 선정
- 지역별로 모형의 성능이 최소 0.5714부터 최대 0.9848까지 나타남
-
선형회귀의 기본 가정 검토
-
모델링에 앞서 선형회귀(단순/다중) 적용이 가능한지 네 가지 가정을 통해 검토하였다.
가정을 충족하지 않는 경우 선형 조합으로 구성되는 회귀모델은 통계적 유의성을 확보하기 어려우므로 선형성을 가정하지 않는 트리기반 모델 등을 검토해야한다. -
원활한 해석을 위해 변수의 영문 이름을 한글로 변환하여주었다.
-
검토 결과 본 데이터는 선형회귀의 가정을 일부 충족하지 않는 것으로 판단되어 통계적 선형모형 대신 비선형모형 또는 Tree 기반 알고리즘을 이용한 모델링이 적절할 것으로 판단되었다.
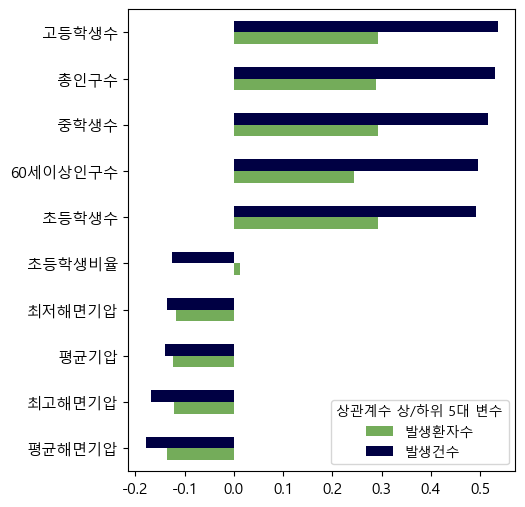
① 선형성: 피어슨 상관계수를 통해 종속변수와 개별 독립변수 간 선형 관계를 파악하였다.
- 검토 결과 주로 인구 변수가 종속변수과 높은 상관관계를 보이는 것이 확인되었다.
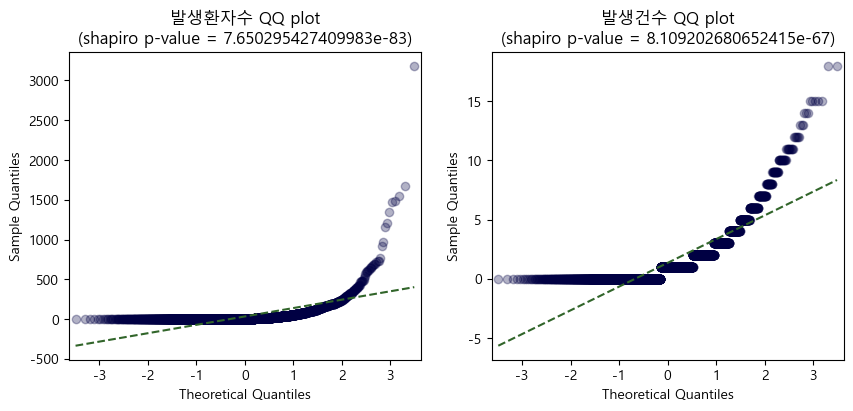
② 정규성: QQ Plot과 shapiro 검정을 이용해 종속변수의 모집단이 정규분포를 따르는지 검정한다.
-
정규성을 만족하지 않는 경우 이에 기반한 회귀계수의 통계적 유의성 검정이 어려워진다.
-
QQ plot을 그려본 결과 데이터 개별 값의 위치가 이론적인 정규분포의 위치와 크게 다르며, 정규성을 따른다는 귀무가설 하 shapiro 검정통계량 또한 p-value가 매우 낮은 것이 확인된다.
-
이에 따라 데이터의 모집단이 정규분포를 따르지 않는 것으로 판단하였다.
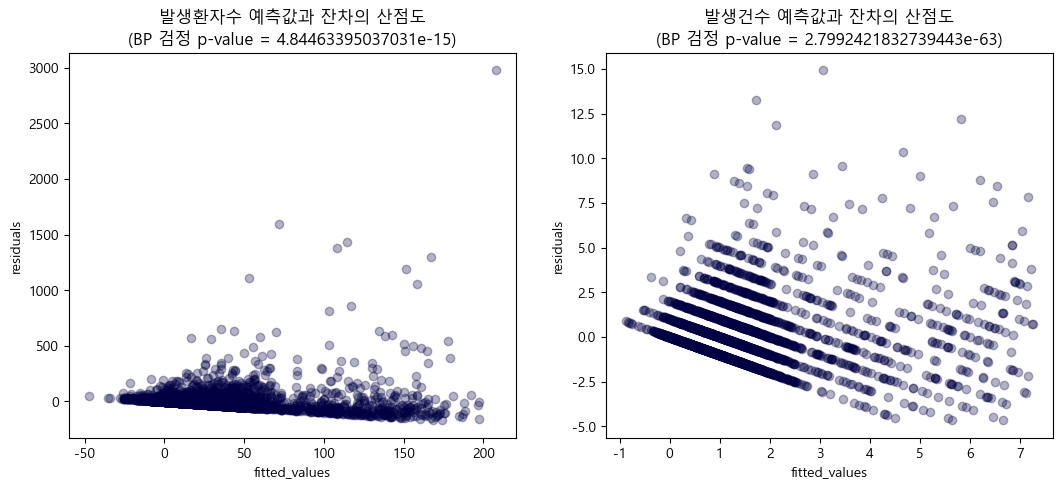
③ 등분산성: 오차항의 분산이 데이터포인트에 상관 없이 무작위적인 분포를 보이는지 검정한다.
-
만약 오차항이 데이터포인트에 따라 어떠한 경향성을 보인다면 회귀계수에 대한 통계적 가설검정 시 모집단(표본집단)의 분산이 일정하다고 보장할 수 없어 검정 결과를 신뢰할 수 없다.
-
검정 결과 발생환자수와 발생건수의 잔차 모두 예측값(fitted_values, 독립변수의 조합)에 따라 분포가 확산되는 모습을 보였으며 등분산성을 따른다는 귀무가설 하 Breusch-Pagan 검정통계량의 p-value 또한 매우 낮은 것이 확인된다.
-
이에 따라 데이터의 모집단이 등분산성을 따르지 않는 것으로 판단하였다.
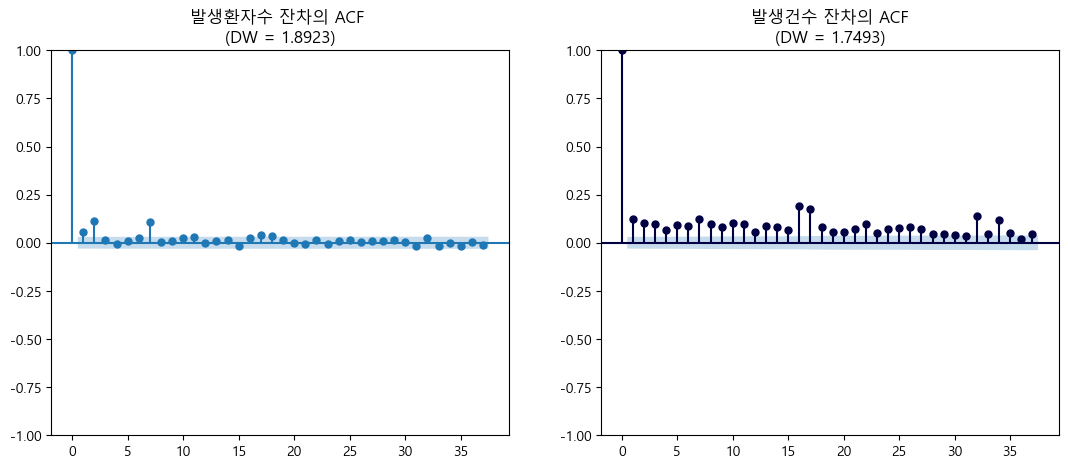
④ 독립성: 오차항의 분포가 이전 오차의 값에 영향을 받지 않는지 검정한다.
-
만약 오차항이 이전 오차에 영향을 받는다면 오차항의 위치는 더 이상 무작위적이 아니며 시간 종속적이므로 일반적인 회귀분석이 아니라 시계열분석을 고려할 필요가 있다.
-
다중선형회귀모형의 잔차에 대해 자기상관함수(ACF)를 그려본 결과 발생환자수는 1, 2, 7기 전의 시차와 연관성을 보이며 발생건수는 과거 시차와 계속적으로 연관성을 보이는 것이 확인된다.
-
또한 자기상관성 검정통계량인 Durbin-Watson(DW) 검정 결과 2보다 작은 결과를 보여 오차항의 독립성을 충족한다고 보기 어려운 것으로 판단하였다.
-
-
모델링 방법 선택(회귀/분류)
-
데이터의 특징에 따라 수치형 변수를 이용한 회귀모형을 모델링할 것인지 아니면 범주형 변수를 이용한 분류모형을 모델링할 것인지 달라진다.
-
본 데이터의 발생 건수와 발생 환자수를 이용해 모의로 모델링을 시도한 결과 상대적으로 모형 성능이 낮게 나타났다. 이는 데이터의 분포가 특정 값(0 또는 1)에 집중되어 모형이 식중독 다수발생 상황을 적절히 예측하지 못하기 때문인 것으로 판단되었다.
-
반면, 발생여부 이진변수를 종속변수로 두고 모델링하는 경우 지역별 범주의 불균형만 샘플링으로 적절히 해소한다면 꽤 준수한 모델 성능을 기대할 수 있었다.
모의 모델링 결과(2015~2022년 자료, 회귀는 R2, 분류는 Accuracy 기준 성능)
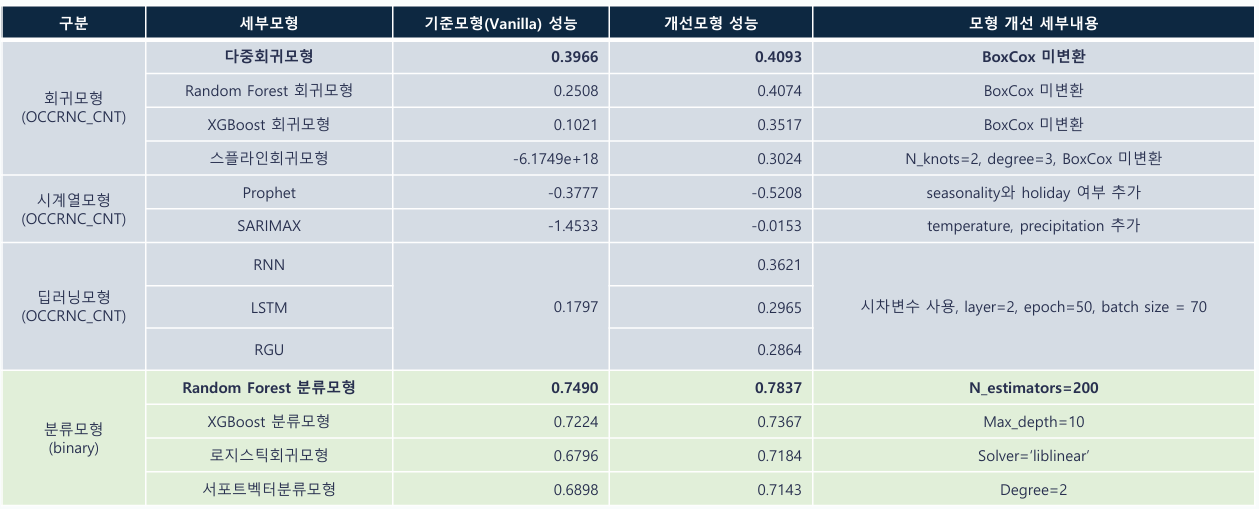
-
따라서 본 프로젝트에서는 식중독 발생 회귀모델링 대신 발생여부 분류모델링을 시도하고, 모델에서 예측하는 발생확률을 발생의 정도로 제시하여 모델링의 활용도를 보완하기로 하였다.
-
-
모델링 단위 선택(전국/지역)
-
식중독 발생여부 데이터는 전국 통합 자료에서는 불균형이 심하지 않지만 지역별로는 심한 불균형 편차를 보이고 있었다. 따라서 전국 17개 시도 지역별 모형을 각각 모델링하여 예측력을 높이기로 하였다.
지역별 식중독 발생여부의 분포
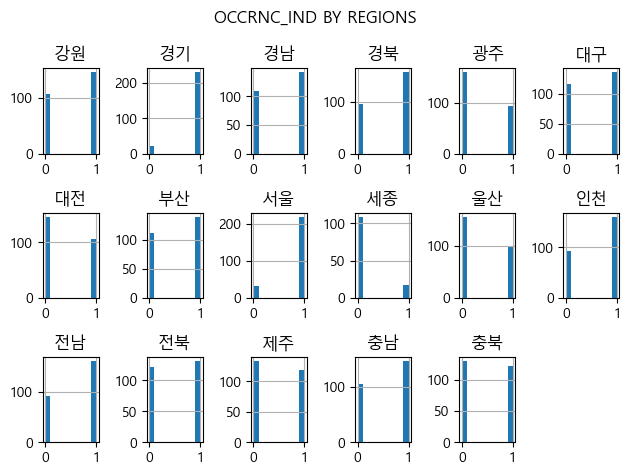
-
-
모형 평가지표의 선정
-
모형 평가지표에 대한 의사결정은 이번 프로젝트에서 꽤 비중 있는 절차였다. 불균형을 보이는 변수의 특성상 과적합이 일어나기 쉬웠기 때문에 재현율(Recall)이 우수해도 정밀도(Precision)은 떨어지는 상충관계가 나타났다.
-
객관적으로 납득할 수 있는 지표를 선정하기 위해 고심했고 결과적으로 식중독이라는 질병을 민감하게 식별하는 데 유리한 지표인 재현율(Recall)을 1순위 평가지표로 선정하였다.
재현율(Recall)
실제 양성(Positive) 중 양성으로 예측한 비율을 의미한다. 민감도(Sensitivity)라고 부르기도 한다. 의학적으로 음성을 양성으로 예측하는 오류(제1종오류)보다 양성을 음성으로 예측하는 오류(제2종오류)의 위험성이 더욱 크기 때문에 재현율을 주된 모형 평가지표로 사용할 수 있다.
-
-
지역별 모델링 결과
-
학습데이터 과적합을 막기 위해 학습 전 Oversampling을 하였으며 하이퍼파라미터 튜닝을 진행했다.
-
지역별로 모형의 성능이 최소 0.5714부터 최대 0.9848까지 다르게 나타났다. 전반적으로 성능이 0.7을 넘고 0.9를 넘은 경우도 존재하여 준수한 성능을 보인 것으로 판단했다.

-
