1. 지식 그래프
지식 그래프란 무엇인가?
지식 그래프 (Knowledge Graph)는 다른 표현으로 Semantic Network라고도 한다.
이는 실제 세계의 개체(Entity)들 사이의 관계를 네트워크 형태로 표현한 지식 베이스이다. 이때 단순히 데이터를 나열하는 것이 아니라, 데이터 간의 연관 관계를 구조화하여 컴퓨터가 문맥을 이해할 수 있게 돕는 다는 점이 핵심이다.
지식 그래프라는 용어 자체는 2012년에 구글이 검색엔진에 이를 도입하면서 대중화 되었지만, 사실 그 전부터 Semantic Network, 인간의 기억 구조를 모방하는 개념은 존재해 왔다. 실제로 구글은 지식 그래프 도입으로 검색 성능을 향상시켰다.
지식 그래프가 LLM만을 위한 것이 아니라는 점을 유념하자.
근래에 다시 화두가 되는 이유는, GraphRAG와 같이 환각을 줄이고 LLM 모델의 정확도를 향상시키는 획기적인 방법으로 주목받고있기 때문이다.
https://www.youtube.com/watch?v=y7sXDpffzQQ (What is a Knowledge Graph?)
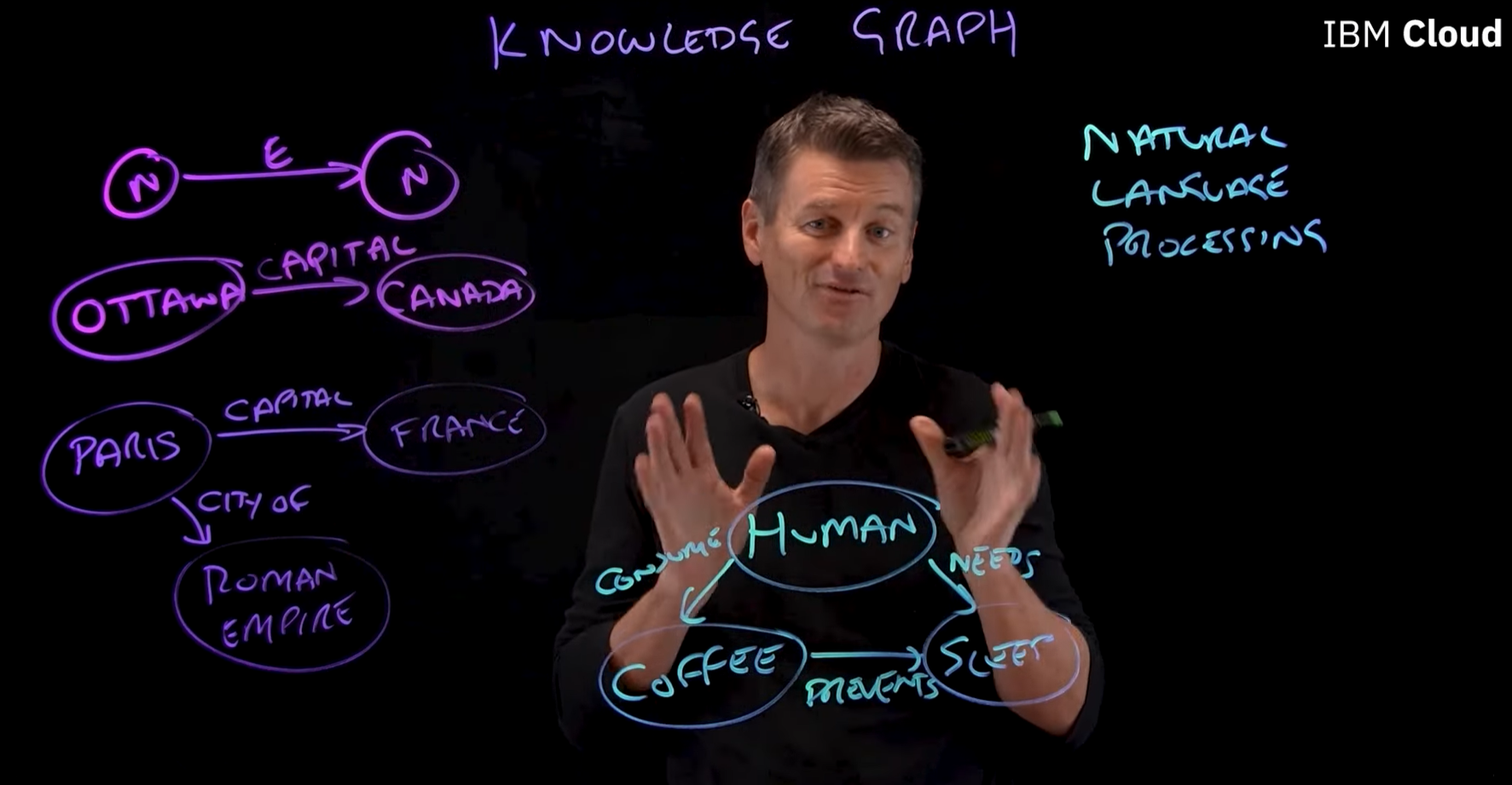
해당 영상은 지식 그래프가 무엇인지에 대해 잘 설명하고 있다. 사진의 왼쪽 상단에 지식그래프의 가장 기본이 되는 단위가 그려져 있다.
엔티티 (Entity, Node): 보라색 원 안에 적힌 'N'이다. 이는 실세계의 사물이나 개념을 의미한다. (OTTAWA, CANADA, PARIS, FRANCE)
관계 (Relation, Edge): 화살표 위에 적힌 'E'이다. 두 엔티티 사이의 연결 의미를 나타낸다. (CAPITAL, CITY OF)
이처럼 [엔티티] → [관계] → [엔티티]로 이어지는 한 세트를 트리플(Triple)이라고 부르며, 이것이 지식그래프를 구성하는 최소 정보 단위가 된다.
그리고 이런 트리플들이 여러개 모인다면, 더 복잡한 의미를 담은 그래프를 형성할 수 있는 것이다.
그렇다면 이러한 지식 그래프는 어떻게 만드는것인가?
우리는 구조화되지 않은 텍스트 데이터를 가져와 노드와 엣지를 추출한다
2. 지식 그래프 구축하기
엔티티 인식 (NER) -> 관계 추출 (RE) -> 정규화 / 스키마 매핑 -> 그래프 DB에 적재 (Neo4j 등)
위의 흐름은 정석적인 지식 그래프 구축 흐름이다.
옛날 옛적에는 당연히 이를 인간이 직접 수행했다. 인간이 직접 텍스트를 읽고, 노드와 엣지를 정의했다. 하지만 당연히 이 방식은 비용이 많이 드는 방식이다. 그렇기에 자연어 처리 기술을 통해서 이를 해결하고자 하였다. 가령 룰 베이스로 이것을 처리하거나 아니면 SVO 파서를 이용해서 주어-동사-객체 관계를 추출한다면 적합하지 않겠는가?
당연히 최근에는 LLM을 통해서 지식 그래프를 구축한다.
https://www.youtube.com/watch?v=O-T_6KOXML4 (Extracting Knowledge Graphs From Text With GPT4o)
https://neo4j.com/try-neo4j/ (Neo4j)
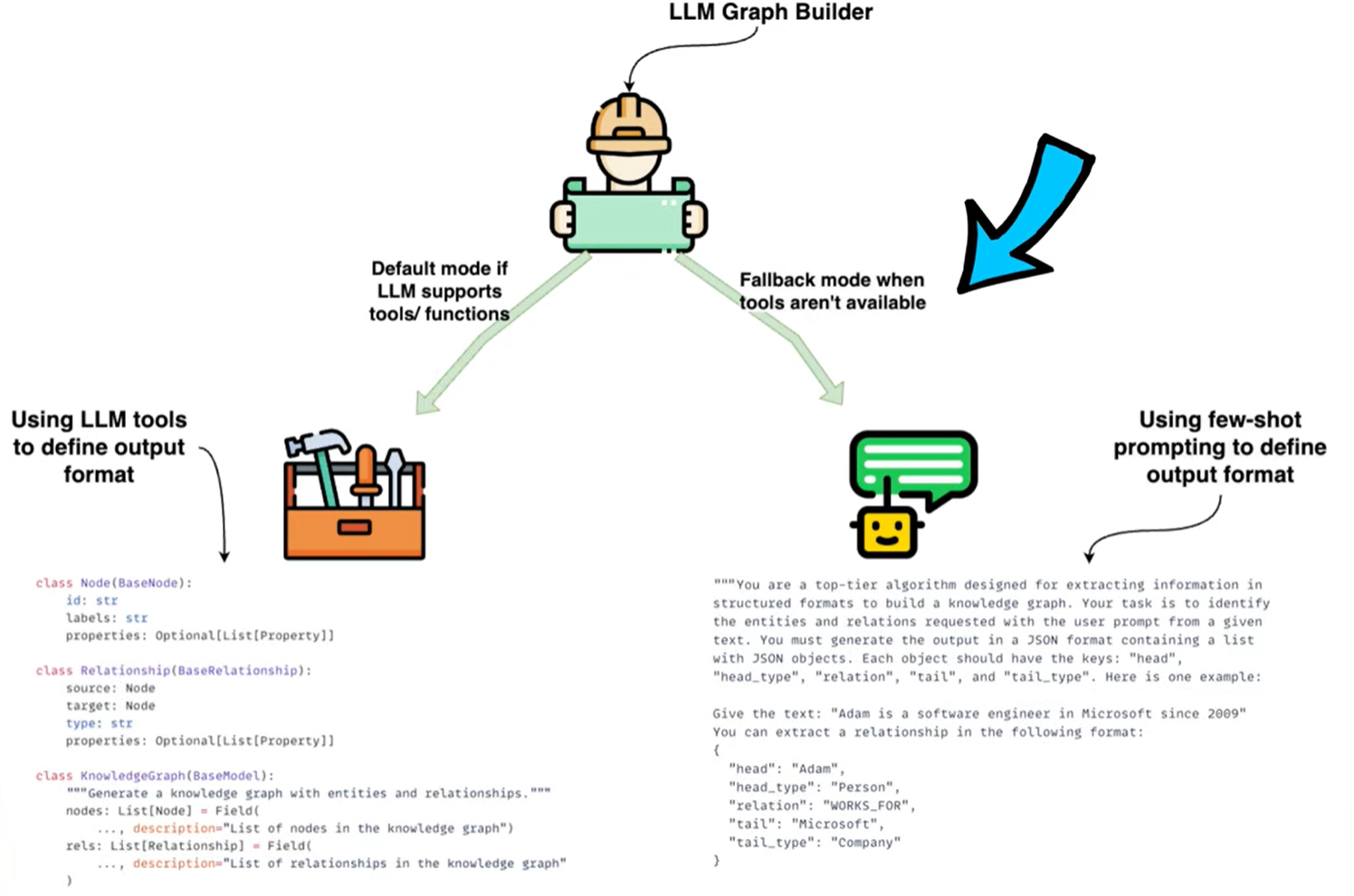
LLM 자체에서 출력을 정의하는 tool이 존재한다면, 이를 활용하면 될것이다. 만약에 그렇지 않다면 프롬프팅을 통해서 직접 뽑아내야한다. 그럼에도 불구하고 LLM에게 텍스트를 던져주고 지식 그래프를 뽑아내는 방식은 충분히 매력적이다!
이러한 과정을 거치면 추출 단계가 완료된 것이다. 이제 정합성 처리, 정제 등을 거친 후, 그래프 DB (Neo4j 등)에 적재한다.
Neo4j
Neo4j는 노드(Node)와 관계(Relationship)를 중심으로 데이터를 저장 및 탐색하는 그래프 데이터베이스다.
JOIN 없이 다단계 관계 탐색(multi-hop)을 빠르게 수행할 수 있어 지식그래프, 추천, 네트워크 분석에 적합하다.
SQL 대신 Cypher라는 그래프 패턴 기반 쿼리 언어를 사용한다.
3. 온톨로지?
온톨로지는 지식 그래프 맥락에서 자주 함께 언급되는데, 그래프에 의미와 규칙을 부여하는 공식적인 개념 설계도에 가깝다.
지식 그래프가 실제 세계의 사실을 노드와 관계로 표현한 데이터라면, 온톨로지는 그 그래프에서 어떤 엔티티가 존재할 수 있고, 어떤 관계가 허용되며, 무엇으로 서로 구별되는지를 정의한다.
예를 들어 매디슨 스퀘어 가든이라는 동일한 장소에서 열리는 여러 하키 경기는, 온톨로지에서 ‘이벤트’라는 개념과 시간·날짜 같은 속성을 통해 서로 다른 사건으로 구분된다. 이처럼 온톨로지는 분류법을 기반으로 엔티티와 관계의 의미를 명확히 하고, 지식 그래프가 일관된 구조와 해석을 유지하도록 돕는다. RDF 트리플과 OWL 같은 표준을 통해 표현되기 때문에 시각적으로는 지식 그래프와 닮아 보이지만, 지식 그래프가 ‘사실’이라면 온톨로지는 그 사실이 들어갈 ‘의미적 틀’이라는 점에서 본질적인 차이를 가진다.
https://blog.skaiworldwide.com/638 (AI 전환에 온톨로지가 필요한 이유)
아무튼 정리하면 둘은 다른 개념이라는 것이다!
4. 정리
AI Agent 시대가 도래하면서 더 똑똑한 LLM, 더 정확한 정보에 대한 수요가 발생하면서 RAG, GraphRAG 같이 방법론들이 발전하는 것 같다. 지식 그래프는 LLM을 위해서 고안된 것이 아니다. 그 전부터 데이터를 더 Semantic하게 저장하기 위해 존재하던 방법론이다. 이제 그 관계를 정의하는 것이 이전보다 비용적으로 쉬워졌으며, RAG와 결합해 GraphRAG로 진화했다. 다음에는 GraphRAG가 무엇인지에 대해서 공부해도록 하겠다.
