01. 네트워크 계층의 기능
네트워크 계층의 기본 기능은 송수신 호스트 사이의 패킷 전달 경로를 선택하는 라우팅이다. 라우팅 과정에서 일어나는 문제도 네트워크 계층에서 처리한다. 이와 관련된 대표적인 기능이 네트워크의 특정 지역에 트래픽이 몰리는 현상을 다루는 혼잡 제어와 라우터 사이의 패킷 중개 과정에서 다루는 패킷의 분할과 병합이다.
라우팅
네트워크의 구성 형태에 대한 정보는 라우팅 테이블이라는 기억 장소에 보관된다. 그리고 이 정보를 이용해 패킷이 목적지까지 도달하기 위한 경로를 선택한다. 송수신 호스트 사이의 패킷 전달 경로를 선택하는 과정을 라우팅이라고 하고, 라우팅 테이블 정보는 네트워크 관리자나 네트워크 자신의 판단에 의해 계속 변경될 수 있다.
혼잡 제어
네트워크에 패킷의 수가 과도하게 증가하는 현상을 혼잡이라 하고, 혼잡 현상을 예방하거나 제거하는 기능을 혼잡 제어라 한다. 혼잡이 발생하면 네트워크 전체의 전송 속도가 급격히 떨어지므로 혼잡이 발생하지 않도록 관리해야 한다. 특히 네트워크의 특정 지역에서 혼잡이 발생하면, 혼잡의 특성상 주위로 빠르게 확산될 가능성이 있다.
패킷의 분할과 병합
전송 계층에서 보낸 데이터가 너무 크면 여러 개의 패킷으로 작게 쪼개 전송해야 한다. 이와 같이 큰 데이터를 여러 패킷으로 나누는 과정을 패킷 분할이라 하고, 반대로 목적지에서 분할된 패킷을 다시 모으는 과정을 병합이라 한다.
1. 연결형 서비스와 비연결형 서비스

1.1 비연결형 서비스
비연결형 서비스는 패킷의 전달 순서, 패킷 분실 여부 등에서 연결형 서비스보다 신뢰성이 떨어지는 전송 방식이다. 따라서 전송 계층에서 네트워크 계층의 비연결형 서비스를 이용할 때는 연결형 서비스를 이용하는 경우보다 자체적으로 오류 제어와 흐름 제어 기능을 더 많이 수행해야 한다.
비연결형 서비스를 이용해 패킷을 전송하면 패킷이 서로 다른 경로를 통해 목적지 호스트로 전달되기 때문에 패킷이 도착하는 순서가 일정하지 않을 수 있다. 따라서 상위 계층인 전송 계층은 수신한 패킷의 순서를 재조정하는 기능이 필요하다.
인터넷 환경에서 네트워크 계층의 기능을 지원하는 IP 프로토콜은 비연결형 서비스의 대표적인 예이다. IP 프로토콜 위에서 동작하는 전송 계층 프로토콜인 TCP는 연결형 서비스를 지원하고, 또 다른 전송 계층 프로토콜인 UDP는 비연결형 서비스를 제공한다.
1.2 연결형 서비스
연결형 서비스는 상대적으로 신뢰성이 높은 서비스로, 패킷을 전송하기 전에 연결을 미리 설정하여 송신하는 방식이다. 비연결형 서비스와 달리 전달되는 패킷들이 모두 동일한 경로를 이용하기 때문에 목적지에 도착하는 패킷의 순서가 송신된 순서와 동일하다는 특성이 있다.
2. 라우팅
패킷의 전송 경로를 지정하는 라우팅은 네트워크 계층의 가장 중요한 역할이다. 라우팅은 들어온 패킷을 어느 출력 경로를 통해 다음 호스트로 전달해야 가장 효과적인지 결정하는 것이다.
가상 회선 방식을 사용하는 연결형 서비스에서 송수신 호스트 사이의 경로 선택은 연결이 설정되는 시점에 한 번만 결정하고, 이후의 패킷들은 이 경로를 따라 목적지까지 전달된다. 따라서 가상 회선 방식에서는 전송되는 모든 패킷이 동일 경로를 거치고, 패킷의 전달 순서도 일정하게 유지된다. 그러나 비연결형 방식의 데이터그램을 사용하면 연결 설정 과정이 없기 때문에 송수신 호스트 사이에 고정 경로가 존재하지 않는다. 따라서 전송 패킷마다 독립적인 전달 경로를 선택해야 한다.
2.2 HELLO/ECHO 패킷
- HELLO: 주변 라우터에 HELLO 패킷을 보내어 주변 경로 정보를 파악하는 용도
- ECHO: 라우터 사이의 전송 지연 시간을 측정하는 용도
2.3 라우팅 테이블
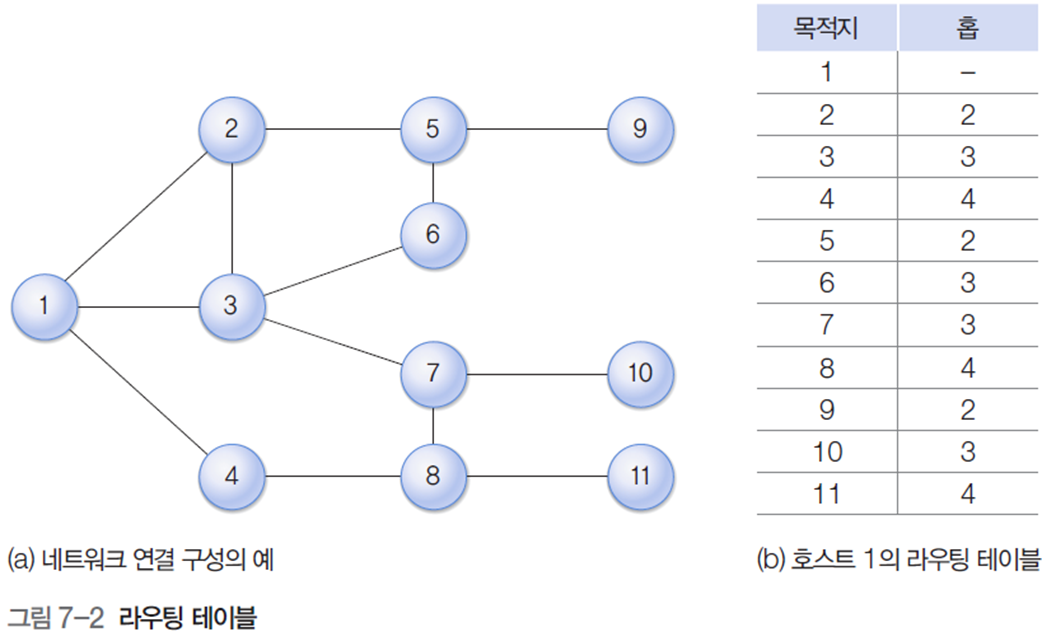
패킷 전송 과정에서 라우터들이 적절한 경로를 쉽게 찾도록 하기 위한 가장 기본적인 도구로 라우팅 테이블을 사용한다.
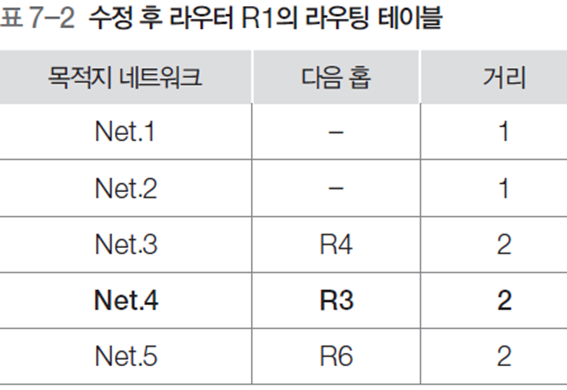
라우팅 테이블에 포함해야 하는 필수 정보는 (목적지 호스트, 다음 홉)의 조합이다. '목적지 호스트'에는 패킷의 최종 목적지가 되는 호스트의 주소 값을, '다음 홉'에는 목적지 호스트까지 패킷을 전달하기 위한 이웃 라우터를 지정한다. 즉, 목적지까지 도달하는 여러 경로 중에 효과적인 라우팅을 지원하는 경로가 있을 수 있는데, 이 경로에서 바로 다음 홉에 위치한 라우터의 주소를 기록한다.
2.4 라우팅 정보의 처리
- 소스 라우팅Source Routing
- 패킷을 전송하는 호스트가 목적지 호스트까지 전달 경로를 스스로 결정하는 방식
- 경로 정보를 전송 패킷에 기록함
- 데이터그램 방식과 가상 회선 방식에서 모두 이용함 - 분산 라우팅Distributed Routing
- 라우팅 정보가 분산되는 방식, 패킷의 전송 경로에 위치한 각 라우터가 경로 선택에 참여함
- 네트워크에 존재하는 호스트의 수가 많아질수록 다른 방식보다 효과적일 수 있음 - 중앙 라우팅Centralized Routing
- RCC라는 특별한 호스트를 사용해 전송 경로에 관한 모든 정보를 관리하는 방식
- RCC로부터 목적지 호스트까지 도착하기 위한 경로 정보를 미리 얻음
- 장점 : 경로 정보를 특정 호스트가 관리하기 때문에 경로 정보를 관리부담이 줄어듬
- 단점 : RCC에 과중한 트래픽을 주어 전체 효율이 떨어짐 - 계층 라우팅Hierarchical Routing
- 분산 라우팅 기능과 중앙 라우팅 기능을 적절히 조합하는 방식
- 네트워크 규모가 계속 커지는 환경에 효과적
3. 혼잡 제어
흐름 제어는 송신 호스트와 수신 호스트 사이의 논리적인 점대점 전송 속도를 다룬다. 반면, 혼잡 제어는 더 넓은 관점에서 호스트와 라투어를 포함한 서브넷에서 네트워크의 전송 능력 문제를 다룬다.
3.1 혼잡의 원인
- 초기 혼잡 과정에서 타임 아웃 시간이 작으면 혼잡도가 급격히 증가
- 패킷 도착 순서가 다른 상황에서 패킷을 분실 처리하면 타임아웃 증가
- 의도적으로 피기배킹을 사용하면 응답 시간이 느려져 타임아웃 증가
- 패킷 생존 시간을 작게 하면 패킷이 강제로 제거되어 타임아웃 증가
- 라우팅 알고리즘
- 혼잡이 발생하지 않는 경로를 배정하도록 설계
- 혼잡이 발생하는 경로를 선택하면 혼잡이 주변으로 확대됨
3.2 트래픽 성형
혼잡은 트래픽이 특정 시간에 집중되는 버스트 현상에서 기인하는 경우가 많다. 즉, 송신 호스트에서 전송하는 패킷의 양이 시간대별로 일정하게 발생하는 경우보다 패킷이 짧은 시간동안 많이 발생하는 경우에 혼잡이 일어날 확률이 높다. 따라서 송신 호스트가 전송하는 패킷의 발생 빈도가 네트워크에서 예측할 수 있는 전송률로 이루어지게 하는 기능이 필요한데, 이를 트래픽 성형이라고 한다.
송신 호스트가 사전에 약속한 트래픽보다 과도한 양의 패킷을 전송하면 네트워크를 적절히 통제해야 한다. 이와 같은 트래픽 성형과 관련된 알고리즘 중 유명한 것이 리키 버킷이다.
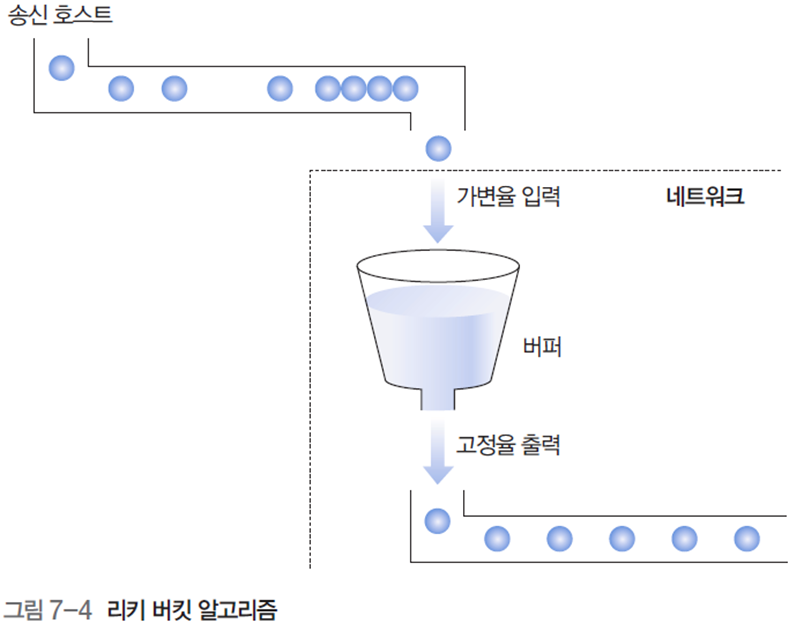
리키 버킷 알고리즘을 사용하면 송신 호스트로부터 입력되는 패킷이 시간대별로 일정하지 않아도, 즉 가변적이어도 깔때기를 통과하면서 일정한 전송률로 변경된다.
3.3 혼잡 제거
- 혼잡이 사라질 때까지 연결 설정을 허락하지 않는 것이다. 그러나 실제 네트워크에서는 전체보다 일부 지점에서 혼잡이 발생하는 경우가 많다. 따라서 특정 지역에 혼잡이 발생하면 패킷의 전송 경로를 적절히 조정해줌으로써 혼잡이 발생한 곳을 거치지 않도록 가상 회선 연결을 설정하는 방안이 필요하다.
- 전송 과정에서 사용하는 대역을 미리 할당받음으로써, 네트워크에서 수용 불가능한 정도로 트래픽이 발생하는 일을 사전에 예방한다. 문제점은 자원 예약 방식은 통신 자원을 낭비할 염려가 있다.
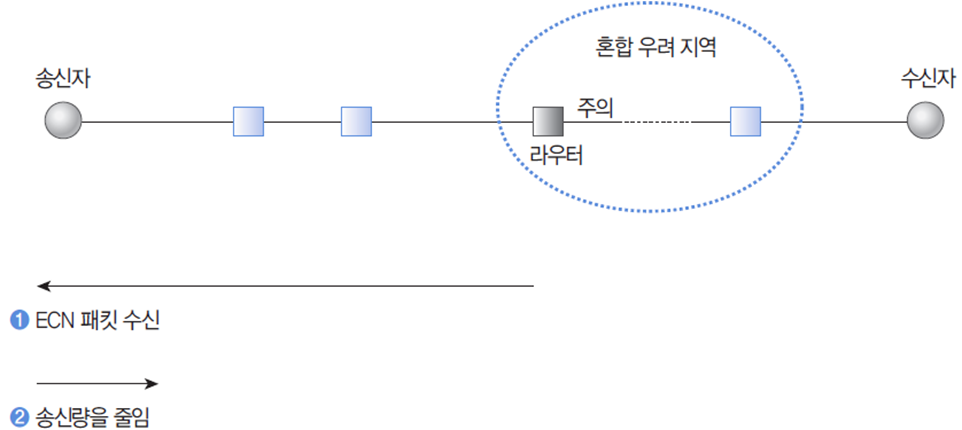
- ECN 패킷
- 라우터는 트래픽의 양을 모니터해 출력 선로의 사용 정도가 한계치를 초과하면 주의 표시를 함
- 주의 표시한 방향의 경로는 혼잡이 발생할 가능성이 높기 때문에 특별 관리함
02. 라우팅 프로토콜
1. 간단한 라우팅 프로토콜
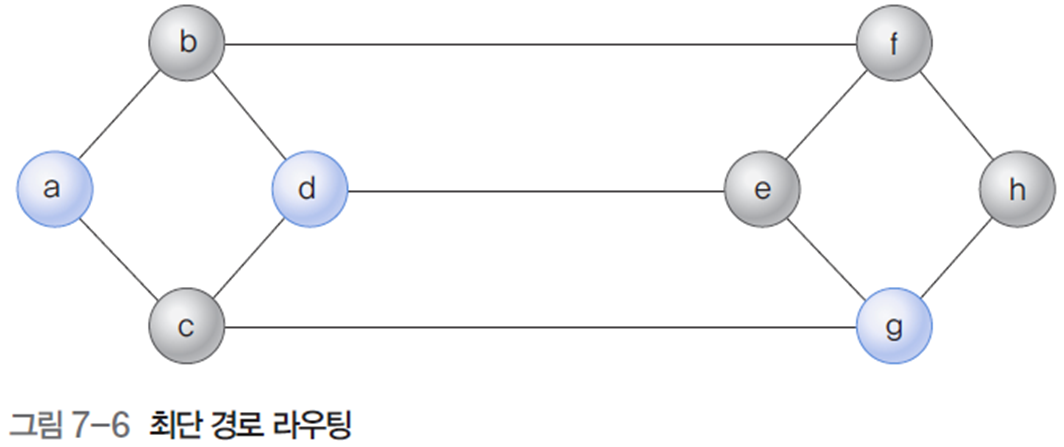
1.1 최단 경로 라우팅
패킷이 목적지에 도달할 때까지 라우터 수가 최소화될 수 있도록 경로 선택한다.
1.2 플러딩
라우터가 자신에게 입력된 패킷을 출력 가능한 모든 경로로 중개하는 방식이다. 이 방식에서는 원본 패킷과 동일한 패킷이 무수히 생서되고, 모든 경로를 통해 반복하여 전송하므로 네트워크에 패킷이 무한 개 만들어질 수 있다. 패킷이 무한정 증가하는 현상을 방지하려면 각 패킷의 홉 수를 일정 범위로 제한해 라우터에서 이를 확인하여 제거해야한다.
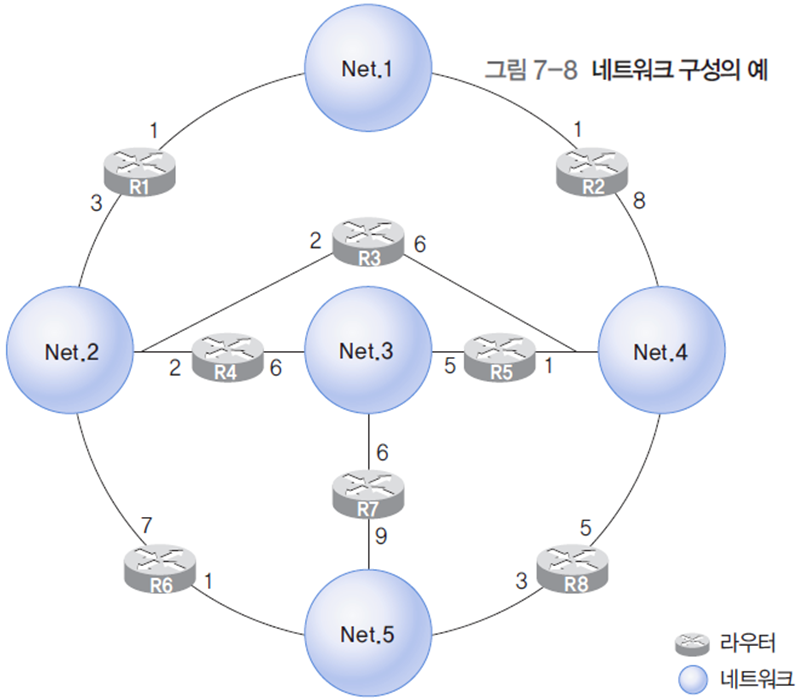
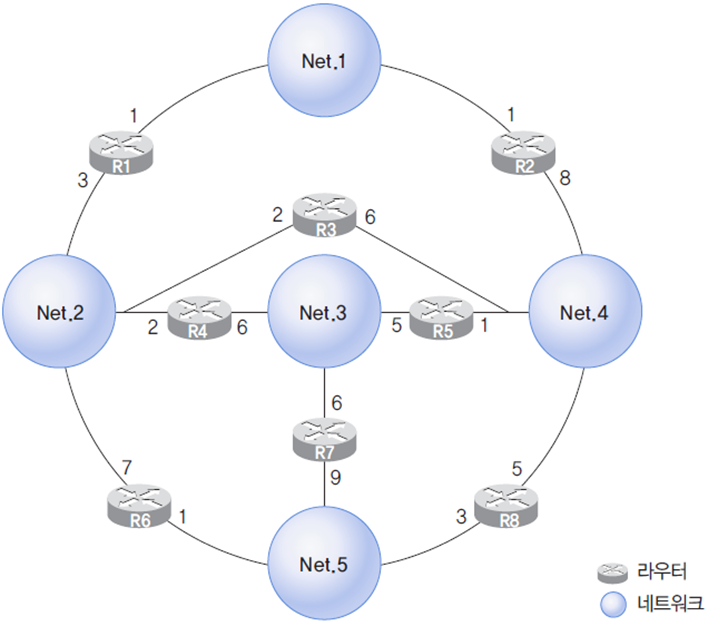
2. 거리 벡터 라우팅 프로토콜
라우터가 자신과 연결된 이웃 라우터와 라우팅 정보를 교환하는 방식이다.
- 필수 정보
- 링크 벡터 : 이웃 네트워크에 대한 연결 정보
- 거리 벡터 : 개별 네트워크까지의 거리 정보
- 다음 홉 벡터 : 개별 네트워크로 가기 위한 다음 홉 정보
2.1 링크 벡터
링크 벡터 L(x) : 라우터 x와 연결된 이웃 네트워크에 대한 연결 정보를 보관

2.2 거리 벡터
전체 네트워크에 소속된 개별 네트워크들까지의 거리 정보를 관리한다.

2.3 다음 홉 벡터
다음 홉 벡터 H(x)는 개별 네트워크까지 패킷을 전송하는 경로에 있는 다음 홉 정보를 관리한다.

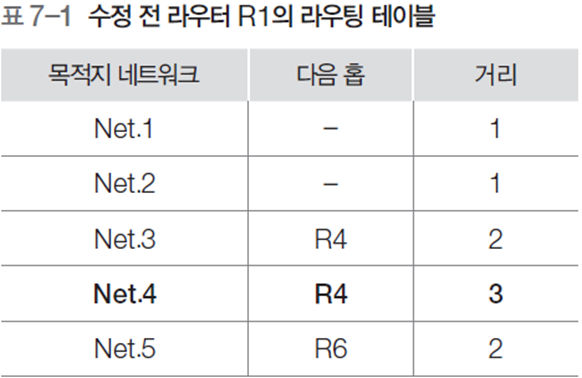
2.4 RIP 프로토콜
- 거리 벡터 방식의 내부 라우팅 프로토콜 중에서 가장 간단하게 구현된 것
- 소규모 네트워크 환경에 적합, 현재 가장 많이 사용하는 라우팅 프로토콜
- 라우팅 테이블 적용
- 새로운 네트워크의 목적지 주소이면 라우팅 테이블에 적용
- 거리 벡터 정보가 기존 정보와 비교하여 목적지까지 도착하는 지연이 더 적으면 대체
- 라우터로부터 거리 벡터 정보가 들어왔을 때, 라우팅 테이블에 해당 라우터를 다음 홉으로 하는 등록 정보가 있으면 새로운 정보로 수정
- 벡터 정보를 교환하기 위해 다음과 같은 패킷 구조를 사용함
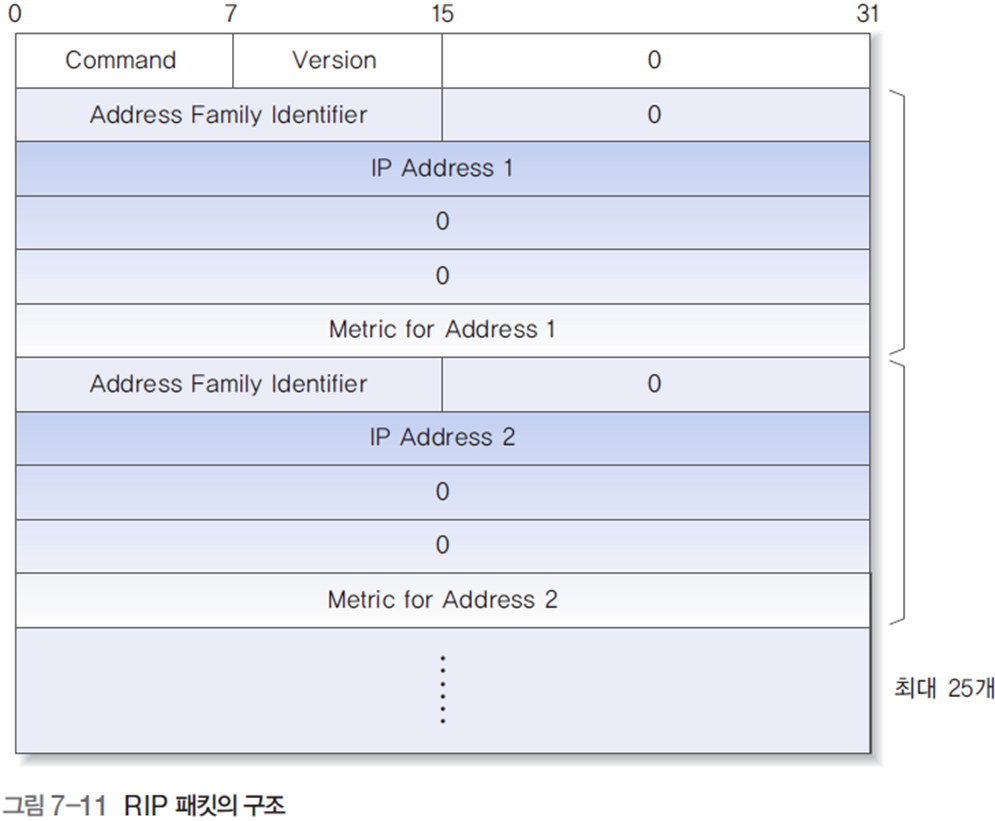
- Command(명령) : 값이 1이면 RIP 요청을, 2이면 RIP 응답을 의미.
- Version(버전) : RIP 프로토콜의 버전 번호
- Address Family Identifier(주소 패밀리 구분자) : IP 프로토콜의 주소는 2로 설정
- IP Address(IP 주소) : 특정한 네트워크를 지칭하는 용도로 사용되기 때문에 IP 주소의 네트워크 부분의 값만 사용하고, 호스트 부분은 0으로 채움
- Metric(거리) : 해당 라우터에서 목적지 네트워크까지의 거리
03. IP 프로토콜

1. IP 헤더 구조
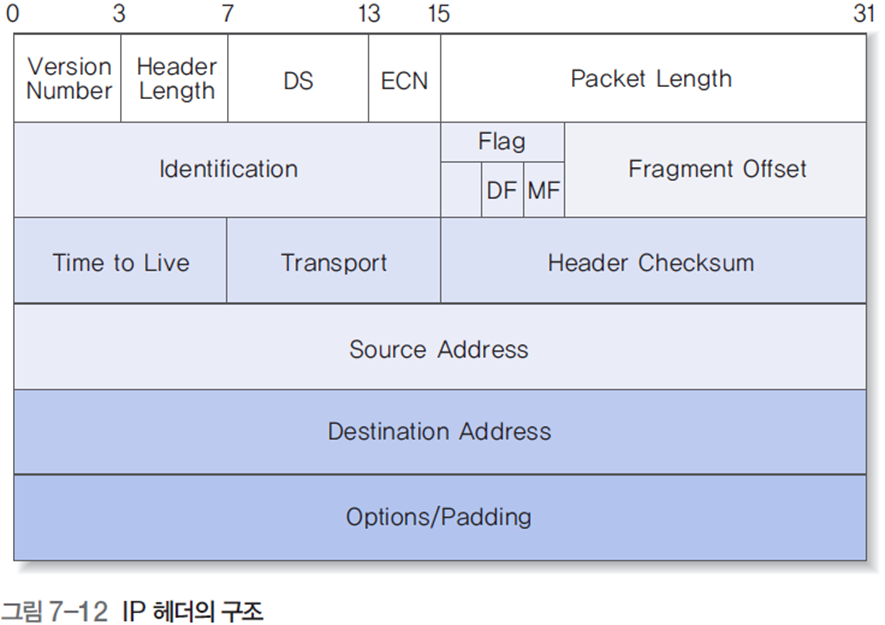
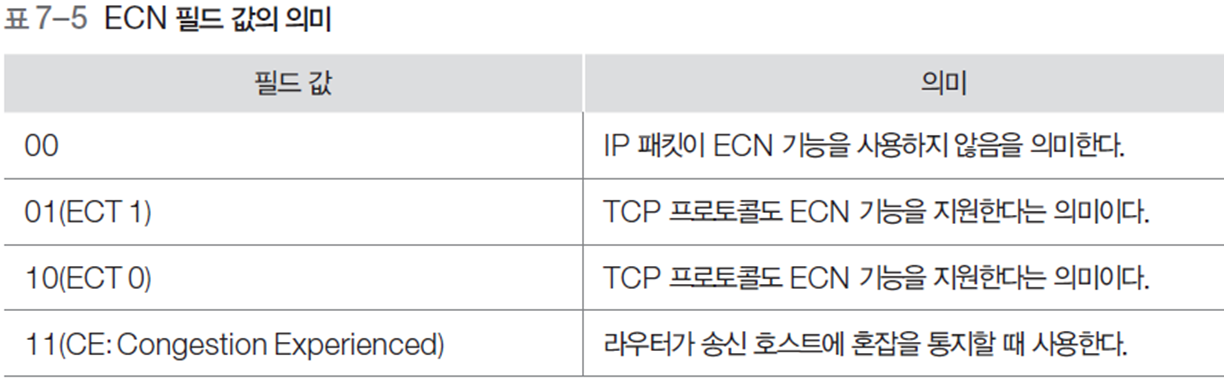
1.1 DS/ECN
- Service Type 필드
- 우선순위, 지연, 전송률, 신뢰성 등의 값을 지정할 수 있음
- IP 프로토콜이 사용자에게 제공하는 서비스의 품질에 관련된 내용을 표현
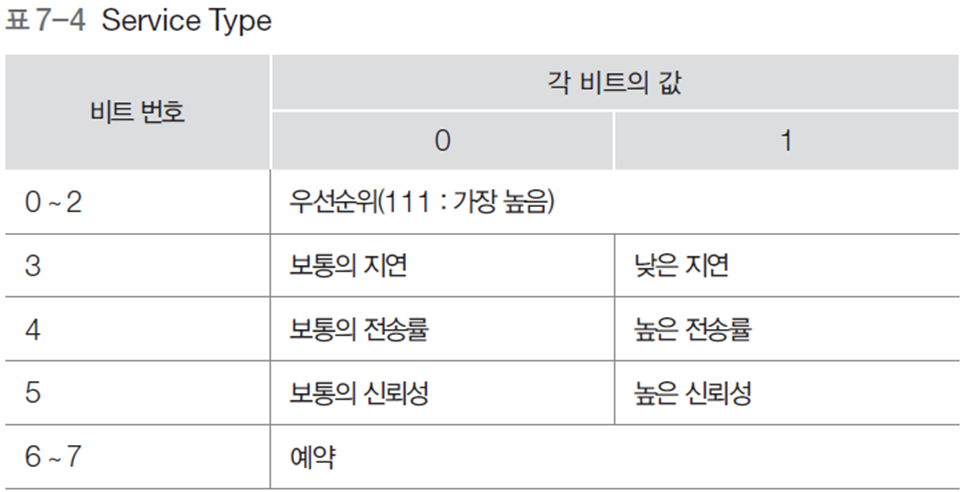
- DS
- 사전에 서비스 제공자와 서비스 이용자 사이에 서비스 등급에 대해 합의
- 동일한 DS 값을 갖는 트래픽들은 동일한 서비스 등급으로 처리됨 - ECN
- ECT 0과 ECT 1은 동일한 의미
- ECN 기능을 위하여 TCP 프로토콜의 헤더에 ECE 필드와 CWR 필드가 추가
1.2 패킷 분할

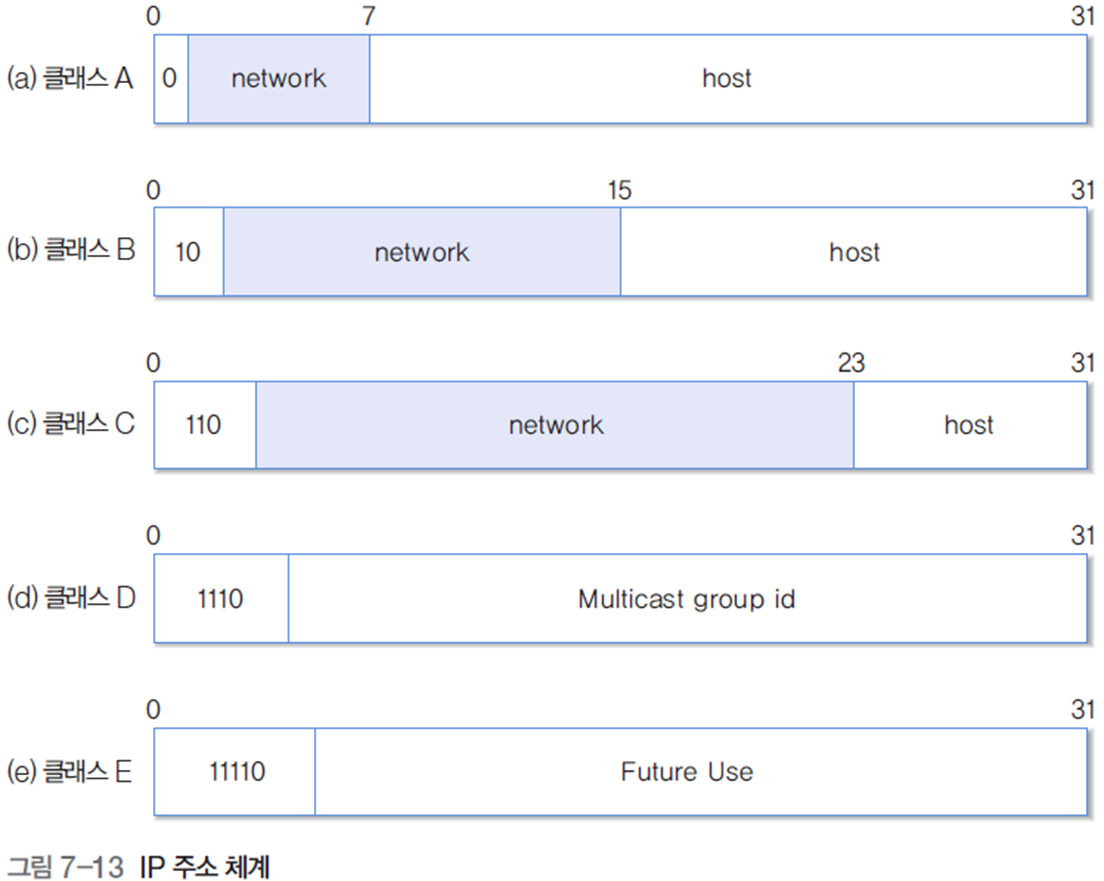
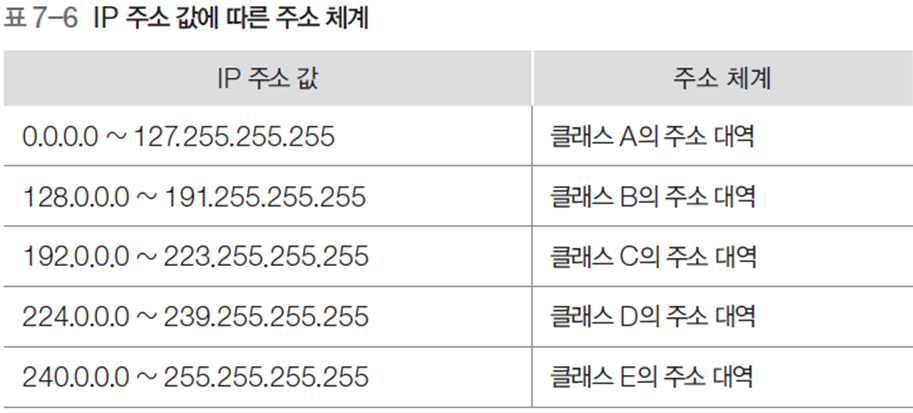
1.3 주소 관련 필드
-
Source Address : 송신 호스트의 IP 주소
-
Destination Address : 수신 호스트의 IP
-
network(네트워크) : 네트워크 주소
-
host(호스트) : 네트워크 주소가 결정되면 하위의 호스트 주소를 의미하는 host 비트 값을 개별 네트워크의 관리자가 할당
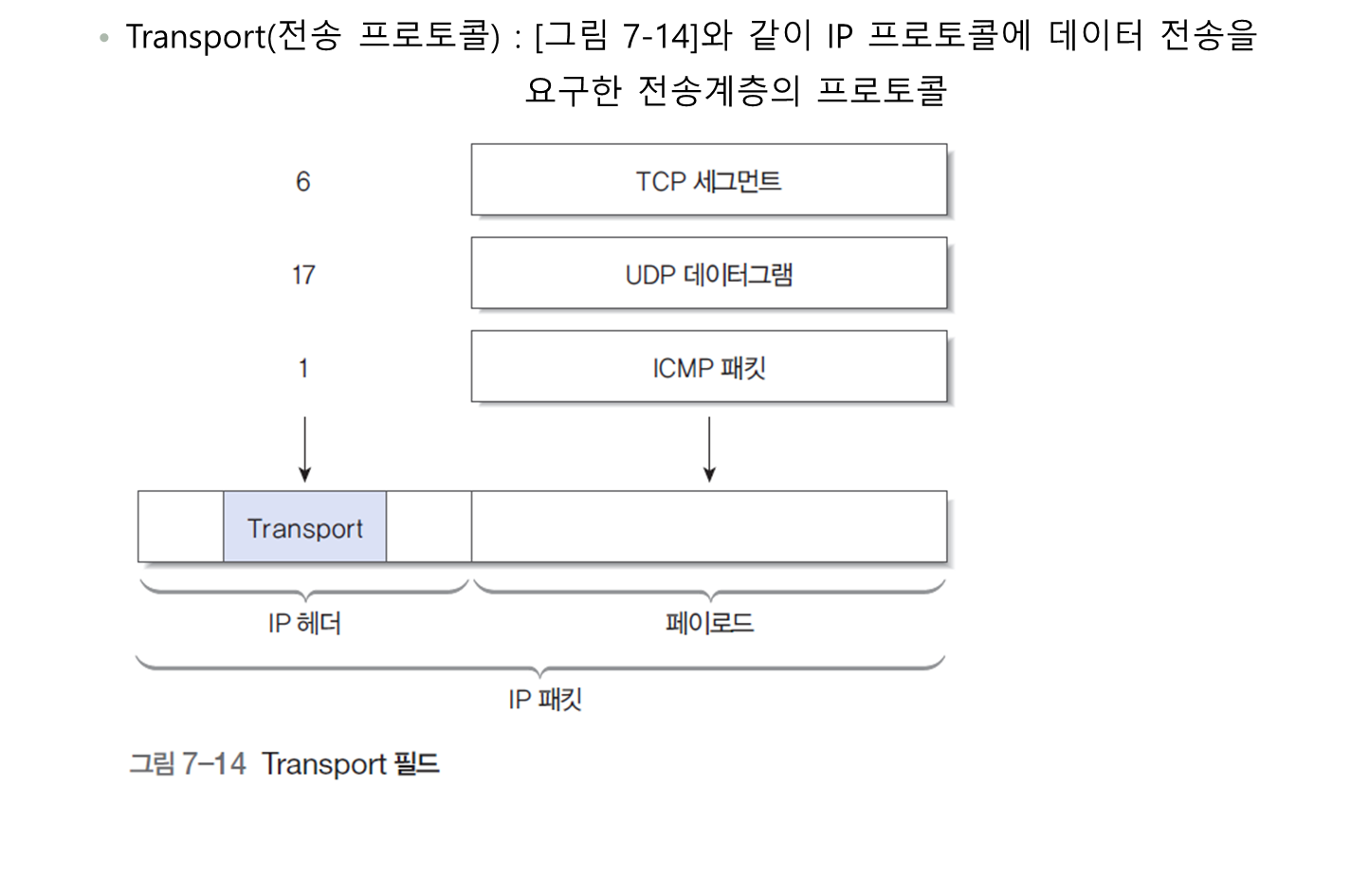
1.4 기타 필드


2. 패킷 분할
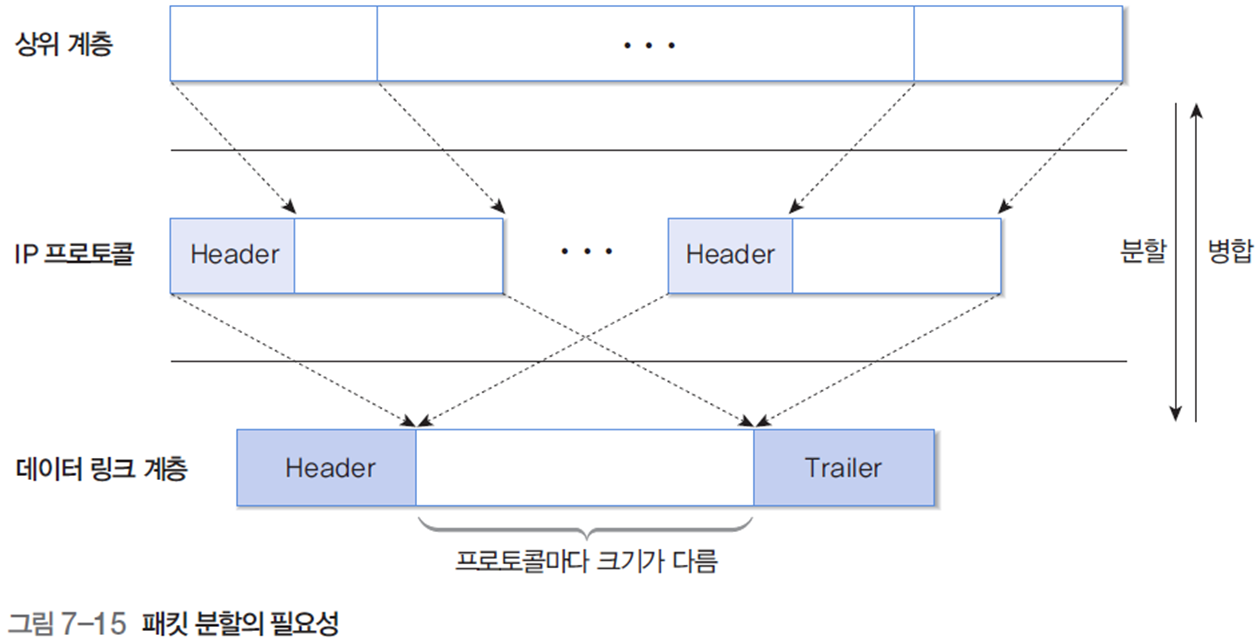
2.1 분할의 필요성
데이터 링크 계층 프로토콜의 프레임은 크기가 프로토콜마다 다르다. 따라서 상위 계층에서 내려온 데이터를 데이터 링크 계층의 프레임 틀에 담을 수 있도록 IP 프로토콜에서 분할 과정을 거친 후에 전송하고, 수신 측에서는 이를 다시 합치는 병합 작업을 수행한다.
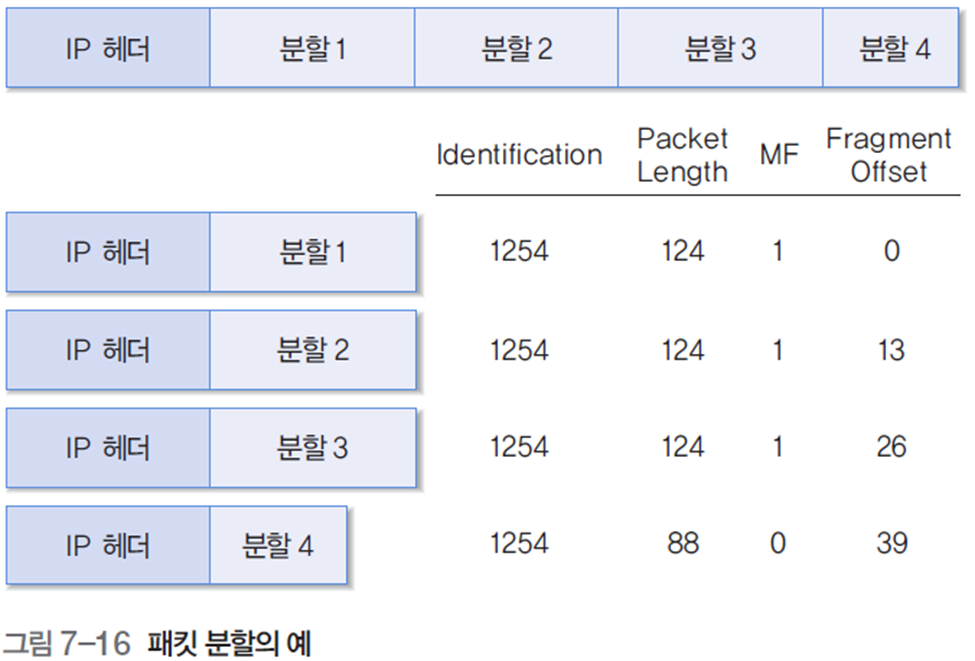
2.2 분할의 예
- IP 헤더를 제외한 전송 데이터의 크기는 380바이트
- 패킷은 최대 크기가 128바이트라고 가정
3. DHCP 프로토콜
특정 네트워크를 관리하는 네트워크 관리자는 개별 호스트들에 수동으로 고정 IP 주소를 할당할 수 있다. 그러나 IP 주소 부족 등의 사유로 DHCP를 사용하여 자동으로 할당할 수도 있다.
