1. 서론
Lovebird 프로젝트 v0.1 개발이 끝나고 배포를 진행했다. 처음엔 CICD 구축을 계획했지만, v0.1은 MVP 개발이기에 CICD가 오버 엔지니어링으로 느껴져 수동 배포를 하기로 했다. 이번 포스팅에서는 수동 배포 중 만난 이슈를 중심으로 글을 작성할 예정이다.
2. Deploy Flow
처음엔 ec2에 git clone 후 gradle build를 통해 jar 파일을 생성하여 실행하려 했다. 하지만 t2.micro의 EC2 인스턴스는 build를 버티지 못하여 CPU가 폭발하여 멈춰버렸다. 어쩔 수 없이 docker를 도입하게 되었다.
FROM azul/zulu-openjdk:17-latest
WORKDIR /app
COPY build/libs/app-0.0.1-SNAPSHOT.jar .
EXPOSE 8080
USER nobody
ENTRYPOINT [\
"java",\
"-jar",\
"-Djava.security.egd=file:/dev/./urandom",\
"-Dsun.net.inetaddr.ttl=0",\
"-Dspring.profiles.active=prod",\
"app-0.0.1-SNAPSHOT.jar"\
]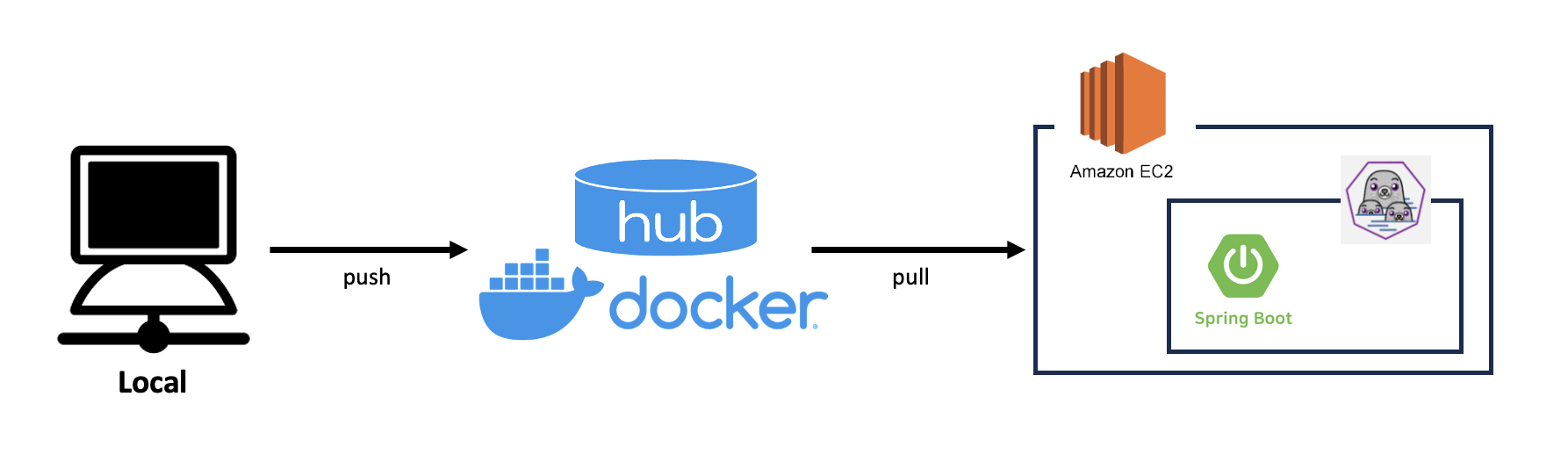
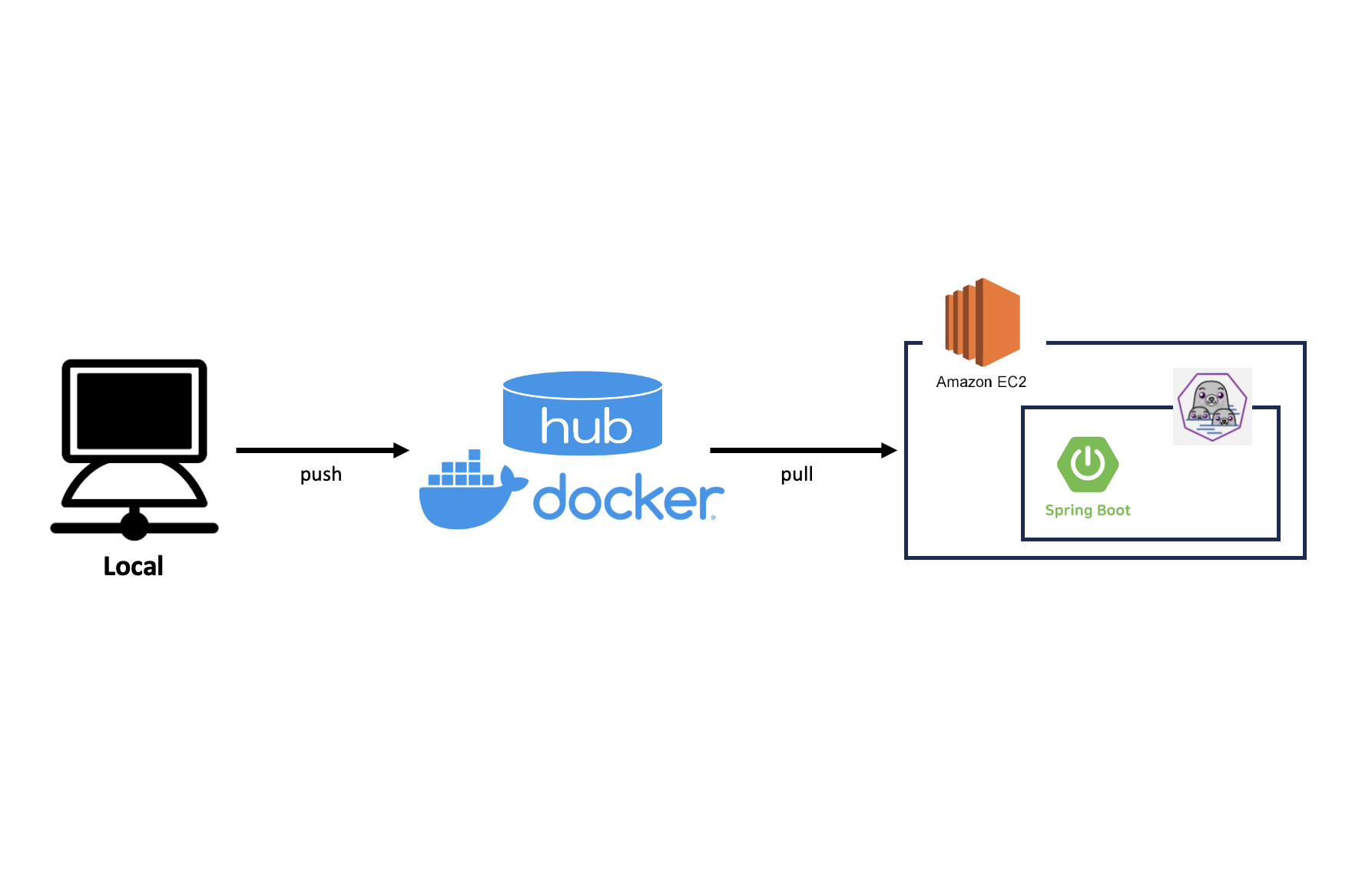
위의 아키텍처처럼 Local에서 gradle build를 통해 jar 파일을 생성했다. jar 파일을 활용하여 image를 생성하고, docker hub에 push 했다. 개발 환경이 M1 pro Mac이기 때문에 docker build 시 platform을 amd64로 지정해주었다. (이 옵션을 주지 않으면 arm64로 생성돼 정상적인 컨테이너 가동이 힘들다.)
$ ./gradlew clean
$ ./gradlew build
$ docker build --platform linux/amd64 --build-arg DEPENDENCY=build/dependency -t ${user}/${repository}:${tag} .
$ docker push ${user}/${repository}:${tag} 이후 EC2 ssh에 접속하여 docker hub로부터 pull 해오고, 컨테이너를 가동시켰다. 현재 사용하고 있는 EC2의 OS는 Red Hat 계열 Linux이고, Red Hat의 경우 Linux 8부터 docker 대신 podman을 사용하고 있기 때문에 명령어 샘플 또한 podman으로 기재한다. 또 실시간 Health Check를 하기 힘들기에 restart 옵션을 주어 가동했다.
$ podman pull ${user}/${repository}:${tag}
$ podman run --restart always --name ${app-name} -d -p 8080:8080 ${user}/${repository}:${tag}여기까지는 순조롭게 진행되었으나 이후 이슈가 발생해 삽질을 하기 시작했다.
3. 인바운드 (방화벽)
컨테이너는 분명 잘 가동되고 있는데 브라우저에서 접속이 안 됐다. 뭐지... 하면서 먼저 인스턴스의 인바운드 규칙을 다시 확인해봤는데 이상 없었다. 이번엔 EC2 ssh에 접속해 curl 명령어를 던져보았다. 이상 없었다. 그럼 도대체 왜, 뭐 때문에 안 될까 하고 애꿎은 컨테이너와 이미지만 삭제했다가 다시 만들었다가를 반복했다.
aws를 활용하며 한번도 겪어보지 못한 문제에 많은 시간을 허비하고, 찾아낸 문제는 OS에게 있었다. 이전까지 Ubuntu만 사용했는데, 이번에 차이점을 모르고 Red Hat을 사용한게 화근(?)이었다. Red Hat의 경우 iptables 위에 firewalld라는 보안적으로 한층 더 업그레이드된 방화벽이 기본으로 탑재된다고 한다. 따라서 기본적으로 firewalld가 설치돼 있는 Red Hat 인스턴스의 경우, 현재 활성화된 방화벽 규칙을 확인하고, 원하는 포트에 대하여 허용 규칙을 설정해줘야 한다. 다음은 이 과정의 명령어다. (루트 권한이 필요하므로 sudo를 활용한다.)
# 현재 활성화된 public 방화벽 규칙 확인
$ sudo firewall-cmd --zone=public --list-all
# 8080 포트 허용 규칙 설정
$ sudo firewall-cmd --zone=public --add-port=8080/tcp --permanent
# reload
$ sudo firewall-cmd --reload이렇게 해주니 거짓말처럼 외부 접근이 가능했다!
4. 컨테이너 잠금 충돌 오류
분명 문제도 없고, 컨테이너 가동 시 restart 옵션까지 주었는데, 컨테이너가 오래 버티지 못하고 계속 다운되었다. 문제를 해결하기 위해 EC2 ssh에 접속해 podman ps 명령어를 쳤을 때 다음과 같은 에러 로그가 리턴되었다.
$ podman ps
ERRO[0000] Refreshing container 7f02bfa893b167af6198c5d8da729bfff760b47455c3cb08dcfc7be925f8a270: acquiring lock 0 for container 7f02bfa893b167af6198c5d8da729bfff760b47455c3cb08dcfc7be925f8a270: file exists
ERRO[0000] Refreshing volume 03be7eec8253ded952f2efca285c88bfeed26ff893989f7da77d52635d028fe9: acquiring lock 6 for volume 03be7eec8253ded952f2efca285c88bfeed26ff893989f7da77d52635d028fe9: file exists
ERRO[0000] Refreshing volume 10d50e72bdcc116dee4f81d027b79a549e987d6e8016bae815126556ebcb3853: acquiring lock 7 for volume 10d50e72bdcc116dee4f81d027b79a549e987d6e8016bae815126556ebcb3853: file exists
ERRO[0000] Refreshing volume 1c77ab0660aa173b01523a8700ec0f79e6692580c98719bc7af1b36cf8a3c432: acquiring lock 1 for volume 1c77ab0660aa173b01523a8700ec0f79e6692580c98719bc7af1b36cf8a3c432: file exists
ERRO[0000] Refreshing volume 71ab8a798bc063d3f1da260c99786fc3c5132f06e47e2b52bcc4efc23a2e36c4: acquiring lock 4 for volume 71ab8a798bc063d3f1da260c99786fc3c5132f06e47e2b52bcc4efc23a2e36c4: file exists
ERRO[0000] Refreshing volume 7d9cd61445d241bb3923a9a371a048909a3ab81cf5c57192a6f7979c1bfcd91a: acquiring lock 5 for volume 7d9cd61445d241bb3923a9a371a048909a3ab81cf5c57192a6f7979c1bfcd91a: file exists
ERRO[0000] Refreshing volume fc9e6c9cf23b671750a3fae6a7283c3ebe7ef24662da3549c7b25634b1fc24e3: acquiring lock 8 for volume fc9e6c9cf23b671750a3fae6a7283c3ebe7ef24662da3549c7b25634b1fc24e3: file exists
ERRO[0000] Refreshing volume fd13b958389b2696fcc391a64f03402e172f679ee0c03a0325a36c858234a596: acquiring lock 3 for volume fd13b958389b2696fcc391a64f03402e172f679ee0c03a0325a36c858234a596: file exists
ERRO[0000] Refreshing volume ff952b2b0c8f9d8aa2b0f132c8b71ef02b4b3fc9bcfdb4c700d2fa47bc7a91c0: acquiring lock 2 for volume ff952b2b0c8f9d8aa2b0f132c8b71ef02b4b3fc9bcfdb4c700d2fa47bc7a91c0: file exists해당 오류는 컨테이너 또는 볼륨이 현재 다른 프로세스 또는 컨테이너에 의해 사용 중일 때 발생한다고 한다. 일단 다음 명령어를 통해 해결해보았다.
# 컨테이너 삭제
$ podman rm ${container-id}
# 실행 중인 컨테이너와 관련된 볼륨 잠금 해제
$ sudo rm -rf /var/lib/podman/volumes/${volume_name}/*
# Podman과 관련된 잠금 파일 제거
$ sudo rm -rf /var/run/containers/*.lock
# 컨테이너 재가동
$ podman run --restart always --name ${app-name} -d -p 8080:8080 ${user}/${repository}:${tag}휴... 일단 2시간째 이상은 없으니 해결된 것 같지만, 이슈 발생 시 조치 후 추가 작성해야겠다..!
추가) SSH Exit이 문제였다.
또 컨테이너가 exit 되었고, 잠금 충돌 관련 에러 로그가 찍혔다. 그래서 문제가 무엇일지 되돌아보았다. 팀원과 이야기 하던 중 캐치한 것이 SSH에서 컨테이너를 띄우고 exit 하는 시점과 비슷하게 컨테이너가 내려갔다는 것이다. 곧바로 테스트 해보았는데 맞는 것 같았다...! 그렇게 구글링을 해본 결과는 다음과 같다.
SSH 세션에서
exit명령어를 실행하면 해당 SSH 세션이 종료돼, 그 SSH 세션과 관련된 프로세스 및 작업이 종료된다.
이런 논리로 docker 컨테이너가 계속 내려갔던 것이다. 이를 해결하기 위한 방법으로 tmux를 채택했다. (Red Hat에서는 screen이 deprecated 상태이고, tmux가 이를 대신한다.)
# 현재 컨테이너 삭제
$ podman rm ${container-id}
# tmux으로 세션 생성 및 컨테이너 가동
$ tmux new-session -s ${session-name}
$ podman run --restart=always --name=${app-name} -d -p 8080:8080 ${user}/${repository}:${tag}이렇게 컨테이너를 가동시키니 SSH 세션을 종료해도 컨테이너가 잘 가동됐다...! 추가적으로 다시 SSH에 접속해 이전에 실행한 tmux 세션에 연결하려면 다음과 같은 명령을 하면 된다.
$ tmux attach-session -t ${session-name}해당 프로젝트는 여기에서 관리하고 있습니다 ❗️
기술 관련 내용은 여기에 업로드하고 있습니다 ❗️

ecs를 쓰면 ECR같은 컨테이너 레지스트리에 이미지를 올려서 클러스터가 배포하기 때문에 ssh로 접속해서 발생하는 문제를 해결할 수 있어요.로컬에서 도커 이미지만 말아서 올리면 되니 빌드 시간을 아끼고 쉽게 배포할 수 있어요.