ALBERT 모델 학습
transformer 라이브러리의 AlbertTokenizser 와 AlbertForSequenceClassification 의 albert-base-v2 pre-train model 을 가져와서 학습했습니다.
(자료)
https://huggingface.co/docs/transformers/model_doc/albert#transformers.AlbertForSequenceClassification
albert-base-v2 모델의 환경
(자료)
https://huggingface.co/albert-base-v2
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 768 hidden dimension
- 12 attention heads
- 11M parameters
(번외로 albert-base-v2 과 albert-base-v1 의 차이는
dropout rates, additional training data, and longer training 이라고 docs 에서 찾을 수 있었습니다)
이 모델은 token classification, qa, sequence classification 작업에 대해 특화 돼 있다고 명시되어 있어있습니다.
'''
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering.
'''
저희가 작업하고 있는 이진 분류 task 에 아주 적합할 것이라고 생각하고 있습니다.
작업한 변경한 코드

마주한 오류
- import albert model 오류
이때 AlberForSequenceClassification 를 import 할 수 없다는 오류가 발생했습니다.
확인해보니,
!pip install Sentencepiece
!pip install transformers
transformers 를 install 하기 전, Sentencepiece 를 먼저 install 해서 해결해야한다고 자료를 통해 알 수 있었습니다.
(자료)
https://stackoverflow.com/questions/65854722/huggingface-albert-tokenizer-nonetype-error-with-colab
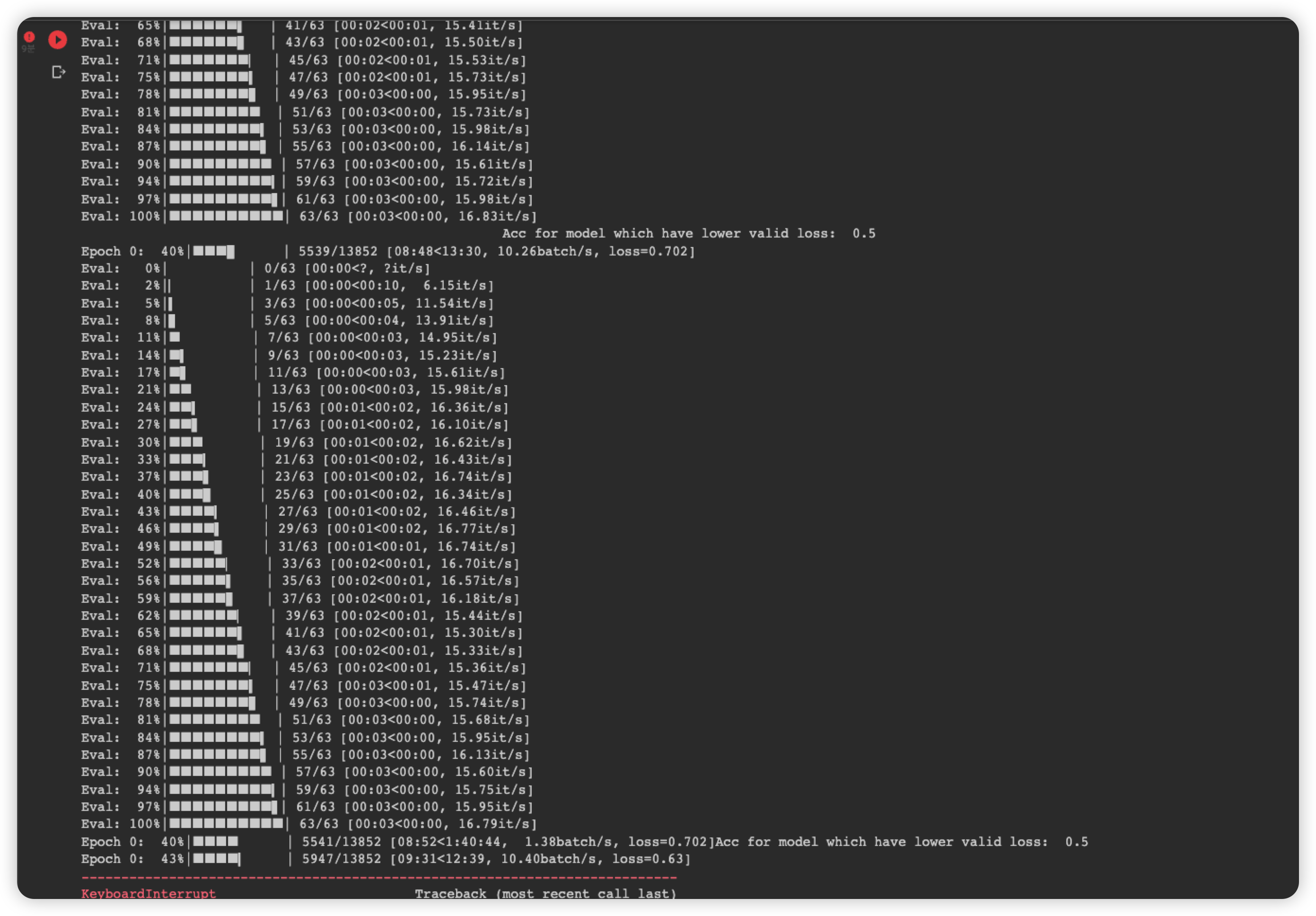
- accuracy 가 0.5 로 고정. 1 로만 예측함.