18장
순환 신경망(RNN)
여러 개의 데이터가 순서대로 입력되었을때 앞서 입력받은 데이터를 잠시 기억해 놓는 방법
여기선 기억된 데이터가 얼마나 중요한지 판단하여 별도의 가중치를 주는 과정도 존재
LSTM(Long Short Term Memory)
한 층 안에서 반복을 많이 해야 하는 RNN의 특성상 일반 신경망보다 기울기 소실 문제가 더 많이 발생
따라서 다음 층으로 기억된 값을 넘길지 여부를 관리하는 단계를 추가
RNN의 활용법
-
다수 입력 단일 출력
문장을 읽고 뜻을 파악 -
단일 입력 다수 출력
사진의 캡션 만들기 -
다수 입력 다수 출력
문장 번역
로이터 뉴스 카테고리 분류
긴 텍스트를 읽고 이 데이터가 어떤 의미를 지니는지 카테고리로 분류
import numpy as np
import matplotlib.pyplot as plt
# 로이터 뉴스 데이터셋
from tensorflow.keras.datasets import reuters
# 단어의 갯수 맞추기
from tensorflow.keras.preprocessing import sequence
# 원-핫 인코딩 처리
from tensorflow.keras.utils import to_categorical
# 모델 객체 불러오는 용도
from tensorflow.keras.models import Sequential
# word embedding: 단어간의 유사도를 계산하여 주어진 배열을 정해진 길이로 압축
from tensorflow.keras.layers import Embedding
# LSTM: 다음 층으로 기억된 값을 넘길지 여부를 관리
from tensorflow.keras.layers import LSTM
# fully connected layer
from tensorflow.keras.layers import Dense
# 개선이 없으면 조기 종료
from tensorflow.keras.callbacks import EarlyStopping
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
# 빈도가 1~1,000에 해당하는 단어만 선택해서 불러오기
category = np.max(y_train) + 1 # 각 샘플의 클래스값들중 가장 큰값 -> 카테고리 갯수
print(f'카테고리 갯수: {category}')
print(f'학습용 뉴스 기사: {len(X_train)}')
print(f'테스트용 뉴스 기사: {len(X_test)}')
print('0번째 기사:', X_train[0])카테고리 갯수: 46
학습용 뉴스 기사: 8982
테스트용 뉴스 기사: 2246
0번째 기사: [1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 2, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 2, 2, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 2, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]# 단어의 갯수 맞추기
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
# 원-핫 인코딩 처리
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)# 프레임 설정
model = Sequential()
# word embedding: 단어간의 유사도를 계산하여 주어진 배열을 정해진 길이로 압축
model.add(Embedding(1000, 100))
# 입력 갯수, 출력 갯수
# LSTM: 다음 층으로 기억된 값을 넘길지 여부를 관리
# 활성화 함수로 하이퍼볼릭탄젠트 함수를 가진 100개의 노드
model.add(LSTM(100, activation='tanh'))
# 다항분류는 softmax, 이항분류는 sigmoid
model.add(Dense(46, activation='softmax'))
# 모델의 실행 옵션
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 다항 분류용 교차 엔트로피 오차 함수 # 고급경사하강법
# 5번 val_loss(검증셋의 오차)에서 개선이 없으면 조기 종료
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
model.summary()WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\backend.py:873: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\optimizers\__init__.py:309: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 100) 100000
lstm (LSTM) (None, 100) 80400
dense (Dense) (None, 46) 4646
=================================================================
Total params: 185046 (722.84 KB)
Trainable params: 185046 (722.84 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________''' train set에서 일부를 떼서 검증셋 만들기 (14장)
validation_split으로 비율을 정함
history = model.fit(
X_train ,
y_train ,
epochs = 50 ,
batch_size = 500 ,
validation_split = 0.25 # 0.8 * 0.25 = 0.2
)
# train : test : validation = 6 : 2 : 2
'''
history = model.fit(
X_train,
y_train,
batch_size = 20 ,
epochs = 200,
validation_data = (
X_test, y_test # 검증셋으로 test set을 씀
),
callbacks = [early_stopping_callback]
)Epoch 1/200
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead.
450/450 [==============================] - 10s 18ms/step - loss: 2.1052 - accuracy: 0.4666 - val_loss: 1.7962 - val_accuracy: 0.5374
Epoch 2/200
450/450 [==============================] - 8s 17ms/step - loss: 1.8382 - accuracy: 0.5318 - val_loss: 1.7417 - val_accuracy: 0.5623
...
Epoch 18/200
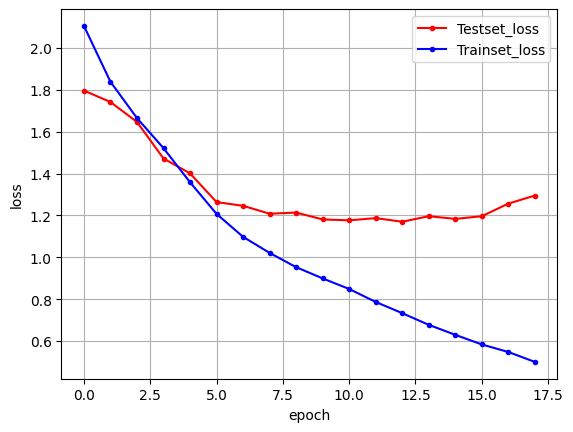
450/450 [==============================] - 8s 18ms/step - loss: 0.5001 - accuracy: 0.8740 - val_loss: 1.2948 - val_accuracy: 0.7128# 테스트 정확도를 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))71/71 [==============================] - 1s 8ms/step - loss: 1.2948 - accuracy: 0.7128
Test Accuracy: 0.7128# 그래프
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
Internet Movie DataBase, IMDB
IMDB란 영화와 관련된 정보와 출연진 정보, 개봉 정보, 영화 후기, 평점까지 매우 폭넓은 데이터가 저장된 자료로
2만 5,000여개의 영화 리뷰와 해당 영화를 긍정적으로 평가했는지 혹은 부정적으로 평가했는지 담겨 있음
컨볼루션 신경망(CNN) 맥스 풀링(Max pooling)을 사용할 것
# Drop out: 은닉층에 배치된 노드 중 일부를 임의로 꺼서 과적합을 방지
from tensorflow.keras.layers import Dropout
# 컨볼루션 신경망(CNN): 입력된 이미지의 특징을 추출하기 위해 커널(슬라이딩 윈도)을 도입
from tensorflow.keras.layers import Conv1D
# 맥스 풀링(Max pooling): 정해진 구역 안에서 최댓값을 뽑아내는 것
from tensorflow.keras.layers import MaxPooling1D
# IMDB 데이터셋
from tensorflow.keras.datasets import imdb(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=5000)
# 단어의 갯수 맞추기
X_train = sequence.pad_sequences(x_train, maxlen=500) # 500개로
X_test = sequence.pad_sequences(x_test, maxlen=500)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 2s 0us/stepmodel = Sequential()
# word embedding: 단어간의 유사도를 계산하여 주어진 배열을 정해진 길이로 압축
model.add(Embedding(5000, 100))
# 입력 갯수, 출력 갯수
# Drop out: 은닉층에 배치된 노드 중 일부를 임의로 꺼서 과적합을 방지
model.add(Dropout(0.5))
# 컨볼루션 신경망(CNN): 입력된 이미지의 특징을 추출하기 위해 커널(슬라이딩 윈도)을 도입
model.add(Conv1D(64, 5, padding='valid', activation='relu', strides=1))
# 맥스 풀링(Max pooling): 정해진 구역 안에서 최댓값을 뽑아내는 것
model.add(MaxPooling1D(pool_size=4))
# LSTM: 다음 층으로 기억된 값을 넘길지 여부를 관리
model.add(LSTM(55))
# 다항분류는 softmax, 이항분류는 sigmoid # 이거랑 같음
model.add(Dense(1, activation='sigmoid')) # model.add(Dense(1))
# model.add(Activation('sigmoid'))
# 모델의 실행 옵션
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 이항 분류용 교차 엔트로피 오차 함수 # 고급경사하강법
model.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 100) 500000
dropout_1 (Dropout) (None, None, 100) 0
conv1d_1 (Conv1D) (None, None, 64) 32064
max_pooling1d_1 (MaxPoolin (None, None, 64) 0
g1D)
lstm_2 (LSTM) (None, 55) 26400
dense_2 (Dense) (None, 1) 56
=================================================================
Total params: 558520 (2.13 MB)
Trainable params: 558520 (2.13 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________# 학습의 조기 중단
# 검증셋의 오차가 3번 이상 개선되지 않으면 정지
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
# 모델 실행
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_split=0.25, callbacks=[early_stopping_callback])
# train set의 1/4를 검증셋으로Epoch 1/100
469/469 [==============================] - 22s 43ms/step - loss: 0.4121 - accuracy: 0.7982 - val_loss: 0.2759 - val_accuracy: 0.8862
Epoch 2/100
469/469 [==============================] - 20s 42ms/step - loss: 0.2432 - accuracy: 0.9037 - val_loss: 0.2900 - val_accuracy: 0.8811
Epoch 3/100
469/469 [==============================] - 20s 43ms/step - loss: 0.1853 - accuracy: 0.9305 - val_loss: 0.2756 - val_accuracy: 0.8928
Epoch 4/100
469/469 [==============================] - 20s 43ms/step - loss: 0.1519 - accuracy: 0.9434 - val_loss: 0.2856 - val_accuracy: 0.8810
Epoch 5/100
469/469 [==============================] - 20s 43ms/step - loss: 0.1216 - accuracy: 0.9594 - val_loss: 0.3435 - val_accuracy: 0.8744
Epoch 6/100
469/469 [==============================] - 20s 43ms/step - loss: 0.0965 - accuracy: 0.9664 - val_loss: 0.3249 - val_accuracy: 0.8851# 테스트 정확도
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 그래프
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')# 그래프에 그리드를 주고 레이블을 표시하겠습니다.
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()782/782 [==============================] - 7s 8ms/step - loss: 0.3601 - accuracy: 0.8747
Test Accuracy: 0.8747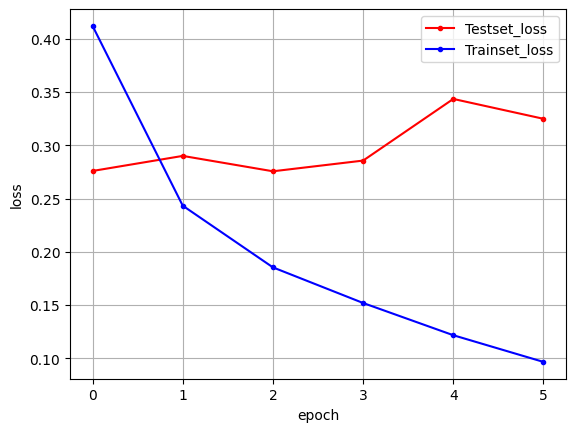
문맥 벡터(context vector)
RNN은 인코더 쪽에서 각 셀 값을 하나씩 뒤의 셀의 입력으로 보내고,
맨 마지막 셀이 이 값을 디코더에 전달하는 구조 이때 그 마지막 셀을 문맥 벡터라고 함
RNN의 한계
입력 값의 길이가 너무 김 -> 입력받은 셀의 결과들이 너무 많아짐 ->
선두에서 전달받은 결괏값이 중간에 희미해지는 문제 발생,
문맥 벡터가 모든 값을 제대로 디코더에 전달하기 힘들어 지는 문제 발생
요약하자면 마지막 셀에 모든 입력이 집중되는게 단점
Attention의 원리
인코더와 디코더 사이에 새로 삽입된 층 내의 각 셀로부터 계산된 스코어를 이용해
소프트맥스 함수를 사용해서 어텐션 가중치를 만듦
이 가중치를 이용해 입력 값 중 어떤 셀을 중점적으로 볼지 결정
IMDB 2
영화 리뷰와 해당 영화를 긍정적으로 평가했는지 혹은 부정적으로 평가했는지
이전에 컨볼루션 신경망(CNN) 맥스 풀링(Max pooling)을 추가적으로 사용하였음
이번엔 CNN, Max pooling 대신에 Attention을 사용함
from attention import Attentionmodel = Sequential()
model.add(Embedding(5000, 500))
model.add(Dropout(0.5))
# Attention layer는 LSTM 레이어의 전체 출력 시퀀스를 입력으로 받아야하기 때문에
# return_sequences=True로 설정
model.add(LSTM(64, return_sequences=True))
# Attention: 각 출력 노드에서 어텐션 가중치를 이용해 입력 값 중 어떤 셀을 중점적으로 볼지 결정
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# 모델 실행 옵션
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, None, 500) 2500000
dropout_3 (Dropout) (None, None, 500) 0
lstm_4 (LSTM) (None, None, 64) 144640
attention (Attention) (None, 128) 20480
dropout_4 (Dropout) (None, 128) 0
dense_3 (Dense) (None, 1) 129
=================================================================
Total params: 2665249 (10.17 MB)
Trainable params: 2665249 (10.17 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________# 학습의 조기 중단을 설정합니다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=3)
# 모델을 실행합니다.
history = model.fit(X_train, y_train, batch_size=40, epochs=100, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])Epoch 1/100
625/625 [==============================] - 158s 250ms/step - loss: 0.3735 - accuracy: 0.8269 - val_loss: 0.2820 - val_accuracy: 0.8849
Epoch 2/100
625/625 [==============================] - 157s 252ms/step - loss: 0.2274 - accuracy: 0.9103 - val_loss: 0.2688 - val_accuracy: 0.8920
Epoch 3/100
625/625 [==============================] - 156s 250ms/step - loss: 0.1651 - accuracy: 0.9378 - val_loss: 0.3107 - val_accuracy: 0.8848
Epoch 4/100
625/625 [==============================] - 155s 249ms/step - loss: 0.1204 - accuracy: 0.9526 - val_loss: 0.3496 - val_accuracy: 0.8909
Epoch 5/100
625/625 [==============================] - 156s 249ms/step - loss: 0.0849 - accuracy: 0.9679 - val_loss: 0.3741 - val_accuracy: 0.8802# 테스트 정확도
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 그래프
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()782/782 [==============================] - 35s 44ms/step - loss: 0.3741 - accuracy: 0.8802
Test Accuracy: 0.8802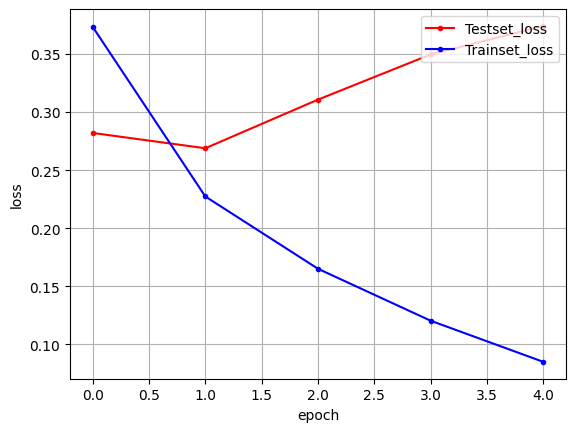
accuracy가 0.8747에서 0.8802로 향상됨
19장
GAN(Generative Adversarial Networks, 생성적 적대 신경망)
가짜를 만들고, 그 가짜를 진짜와 비교하는 적대적 경합 과정
Generator(생성자): 가짜를 만들어 내는 파트, Discriminator(판별자): 진위를 가려내는 파트
DCGAN(Deep Convolutional GAN)
컨볼루션 신경망(CNN, 16장 참조)을 GAN에 적용한 알고리즘
생성자가 가짜 이미지를 만들 때 컨볼루션 신경망(CNN)을 이용
Generator(생성자)
랜덤한 픽셀 값으로 채워진 이미지부터 판별자의 판별 결과에 따라
지속적으로 업데이트하며 점차 원하는 이미지를 만듦
-
옵티마이저(optimizer)를 사용하는 최적화 과정이나 컴파일하는 과정이 없음
-
CNN을 통해 크기가 줄어든 이미지를 패딩 과정(padding)을 통해
빈 곳을 채워서 입력 크기와 출력 크기를 똑같이 맞추는 과정 필요 -
입력 데이터의 평균이 0, 분산이 1이 되도록 재배치하는 배치 정규화(Batch Normalization) 과정이 필요
-
생성자의 활성화 함수는 ReLU() 함수를 사용
-
tanh() 함수를 쓰면 출력되는 값을 -1~1 사이로 맞출 수 있기 때문에
판별자로 넘겨주기 직전에는 tanh() 함수를 거치도록 함 -
판별자에 입력될 MNIST 손글씨의 픽셀 범위를 -1~1로 맞춰야됨
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist # 손글씨 숫자 이미지 데이터셋
from tensorflow.keras.layers import Input # 입력
from tensorflow.keras.layers import Dense # fully connected layer
from tensorflow.keras.layers import Reshape # 입력의 형태를 바꾸어줌
from tensorflow.keras.layers import Flatten # 평탄화, 다차원 입력을 1차원으로 바꾸어줌
from tensorflow.keras.layers import Dropout # 과적합을 방지하기 위해 입력의 일부를 무작위로 버림
from tensorflow.keras.layers import BatchNormalization # 입력 데이터의 평균이 0, 분산이 1이 되도록 재배치
from tensorflow.keras.layers import Activation # 입력에 활성화 함수를 적용
from tensorflow.keras.layers import LeakyReLU # 입력이 음수일 때도 작은 기울기를 가지는 ReLU함수
from tensorflow.keras.layers import UpSampling2D # 입력의 크기를 2배로 늘림
from tensorflow.keras.layers import Conv2D # 입력에 필터를 적용하여 특징을 추출
from tensorflow.keras.models import Sequential # 레이어를 순서대로 쌓아서 만드는 모델
from tensorflow.keras.models import Model # 레이어의 입출력을 직접 정의하여 만드는 모델WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
generator = Sequential()
## fully connected layer
# 임의의 100차원 벡터를 입력으로 받아 7*7*128 크기의 은닉층 노드로
# 7*7의 픽셀 각각 128개의 노드
generator.add(
Dense(
units = 7*7*128 , # 은닉층 노드의 수
input_dim = 100 , # 입력 노드 수
activation = LeakyReLU(0.2) # LeakyReLU: 음수 값에도 0.2의 작은 기울기를 부여
)
)
## 컨볼루션 레이어에 입력시킬 준비
# 입력의 분포를 정규화
# 입력 데이터의 평균이 0, 분산이 1이 되도록 재배치
generator.add(BatchNormalization())
# 컨볼루션 레이어의 입력 형태와 일치시키기 위해 출력을 7*7*128 크기의 3차원 텐서로
generator.add(Reshape((7, 7, 128)))
# 업샘플링 레이어를 추가하여 입력의 크기를 2배로
# 7*7에서 14*14로, 128에서 64(채널 갯수 = 필터 갯수)로
generator.add(UpSampling2D())
## 컨볼루션 레이어
generator.add(
Conv2D(
filters = 64 , # 64개의 필터
kernel_size = 5 , # 5*5 크기의 커널
padding = 'same' # 입력과 출력의 크기를 동일하게 유지하도록 패딩
)
)
## 컨볼루션 레이어에 입력시킬 준비
# 입력의 분포를 정규화
generator.add(BatchNormalization())
# LeakyReLU: 음수 값에도 0.2의 작은 기울기를 부여
generator.add(Activation(LeakyReLU(0.2)))
# 업샘플링 레이어를 추가하여 입력의 크기를 2배로
# 14*14에서 28*28로
generator.add(UpSampling2D())
## 컨볼루션 레이어
generator.add(
Conv2D(
filters = 1 , # 1개의 필터
kernel_size = 5 , # 5*5 크기의 커널
padding = 'same', # 입력과 출력의 크기를 동일하게 유지하도록 패딩
activation = 'tanh' # tanh를 통해 출력의 범위를 -1과 1 사이로 조정
)
)
generator.summary()Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 6272) 633472
batch_normalization_2 (Bat (None, 6272) 25088
chNormalization)
reshape_1 (Reshape) (None, 7, 7, 128) 0
up_sampling2d_2 (UpSamplin (None, 14, 14, 128) 0
g2D)
conv2d_4 (Conv2D) (None, 14, 14, 64) 204864
batch_normalization_3 (Bat (None, 14, 14, 64) 256
chNormalization)
activation_3 (Activation) (None, 14, 14, 64) 0
up_sampling2d_3 (UpSamplin (None, 28, 28, 64) 0
g2D)
conv2d_5 (Conv2D) (None, 28, 28, 1) 1601
=================================================================
Total params: 865281 (3.30 MB)
Trainable params: 852609 (3.25 MB)
Non-trainable params: 12672 (49.50 KB)
_________________________________________________________________discriminator = Sequential()
# 합성곱 층
# 64개의 필터와 5x5의 커널 크기
# 스트라이드를 2로 설정해서 커널 윈도를 두 칸씩 움직이도록 하여 가로세로 크기를 더 줄임 -> 드롭아웃, 풀링의 효과
# 입력 이미지의 형태는 28x28x1
# 패딩을 same으로 설정하여 입력과 출력의 크기를 동일하게 유지
discriminator.add(Conv2D(64, kernel_size=5, strides=2, input_shape=(28,28,1), padding="same"))
# 활성화 함수층
# LeakyReLU: 음수 값에도 0.2의 작은 기울기를 부여
discriminator.add(Activation(LeakyReLU(0.2)))
# 드롭아웃 층
# 0.3의 비율만큼 무작위로 일부 노드를 비활성화하여 과적합을 방지
discriminator.add(Dropout(0.3))
# 합성곱 층
# 128개의 필터와 5x5의 커널 크기
# 스트라이드를 2로 설정해서 커널 윈도를 두 칸씩 움직이도록 하여 가로세로 크기를 더 줄임 -> 드롭아웃, 풀링의 효과
# 패딩을 same으로 설정하여 입력과 출력의 크기를 동일하게 유지
discriminator.add(Conv2D(128, kernel_size=5, strides=2, padding="same"))
# 활성화 함수층
# LeakyReLU: 음수 값에도 0.2의 작은 기울기를 부여
discriminator.add(Activation(LeakyReLU(0.2)))
# 드롭아웃 층
# 0.3의 비율만큼 무작위로 일부 노드를 비활성화하여 과적합을 방지
discriminator.add(Dropout(0.3))
# flatten 층
# 2차원의 이미지 데이터를 1차원의 벡터로 변환
# fully connected 층과 연결하기 위해 필요
discriminator.add(Flatten())
# fully connected 층
# 출력 노드의 개수는 1개
# 다항분류는 softmax, 이항분류는 sigmoid
discriminator.add(Dense(1, activation='sigmoid'))
# 이항 분류용 교차 엔트로피 오차 함수 # 고급경사하강법
discriminator.compile(loss='binary_crossentropy', optimizer='adam')
# 판별자의 학습 기능을 꺼줌
discriminator.trainable = False
discriminator.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 14, 14, 64) 1664
activation_4 (Activation) (None, 14, 14, 64) 0
dropout_2 (Dropout) (None, 14, 14, 64) 0
conv2d_7 (Conv2D) (None, 7, 7, 128) 204928
activation_5 (Activation) (None, 7, 7, 128) 0
dropout_3 (Dropout) (None, 7, 7, 128) 0
flatten_1 (Flatten) (None, 6272) 0
dense_3 (Dense) (None, 1) 6273
=================================================================
Total params: 212865 (831.50 KB)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 212865 (831.50 KB)
_________________________________________________________________G(input): 생성자 G()에 입력 값 input을 넣은 결과
D(G(input)): G(input)을 판별자 D()에 넣은 결과
생성자는 D(G(input))이 참(1)이라고 주장,
판별자는 실제 데이터인 x로 만든 D(x)만이 참이라고 여김
D(G(input))과 실제 데이터로 만든 D(x)를 잘 구별하지 못하게 됨
# ginput: 생성자에 입력할 랜덤한 벡터
# 100차원의 벡터를 입력받을것
ginput = Input(shape=(100,))
# dis_output: 생성자의 출력을 판별자의 입력으로 넣어서 얻은 결과
# generator 함수는 ginput을 입력받아 가짜 이미지를 출력
# discriminator 함수는 가짜 이미지를 입력받아 진짜일 확률을 출력
dis_output = discriminator(generator(ginput))
# 생성자와 판별자를 연결하는 모델
gan = Model(ginput, dis_output)
# gan 모델을 컴파일
gan.compile(loss='binary_crossentropy', optimizer='adam')
# 이항 분류용 교차 엔트로피 오차 함수 # 고급경사하강법
gan.summary()Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 100)] 0
sequential_2 (Sequential) (None, 28, 28, 1) 865281
sequential_3 (Sequential) (None, 1) 212865
=================================================================
Total params: 1078146 (4.11 MB)
Trainable params: 852609 (3.25 MB)
Non-trainable params: 225537 (881.00 KB)
_________________________________________________________________# saving_interval: 중간 과정을 저장할 때 몇 번마다 한 번씩 저장할지
# batch_size: 한 번에 몇 개의 실제 이미지와 몇 개의 가상 이미지를 판별자에 넣을지 결정하는 변수
def gan_train(epoch, batch_size, saving_interval):
# 판별자에서 사용할 MNIST 손글씨 데이터
# 테스트 과정은 필요 없고 이미지만 사용할 것이기 때문에 X_train만 호출
(X_train, _), (_, _) = mnist.load_data()
# 가로 28픽셀, 세로 28픽셀, 흑백이므로 1
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
# 0~255 사이 픽셀 값에서 127.5를 뺀 후 127.5로 나누면 -1~1 사이 값으로 바뀜
X_train = (X_train - 127.5) / 127.5
# batch_size만큼 MNIST 손글씨 이미지를 랜덤하게 불러와 판별자에 집어넣음
# 실제 이미지를 입력했으므로 '모두 참(1)'이라는 레이블을 붙임
true = np.ones((batch_size, 1))
# '거짓(0)'이라는 레이블 값을 가진 열을 batch_size 길이만큼 만듦
fake = np.zeros((batch_size, 1))
for i in range(epoch):
# np.random.randint(a, b, c): a부터 b까지 숫자 중 하나를 랜덤하게 선택해 가져오는 과정을 c번 반복하라
# 0부터 X_train의 개수 사이의 숫자를 랜덤하게 선택해 batch_size만큼 반복해서 가져오게 함
idx = np.random.randint(0, X_train.shape[0], batch_size)
# 선택된 숫자에 해당하는 이미지를 불러옴
imgs = X_train[idx]
# train_on_batch(x, y) 함수는 입력 값(x)과 레이블(y)을 받아서 딱 한 번 학습을 실시해 모델을 업데이트
d_loss_real = discriminator.train_on_batch(imgs, true)
# 생성자에서 만든 가상의 이미지를 판별자에 넣음
# 가상의 이미지는 거짓(0)이라는 레이블을 붙
# 학습이 반복될수록 가짜라는 레이블을 붙인 이미지들에 대한 예측 결과가 거짓으로 나올 것임
# 생성자에 집어넣을 가상 이미지를 만듦
# 정수가 아니기 때문에 np.random.normal() 함수를 사용함
# batch_size만큼 100열을 뽑으라
noise = np.random.normal(0, 1, (batch_size, 100))
# noise가 생성자에 들어가고 결괏값이 gen_imgs로 저장됨
gen_imgs = generator.predict(noise)
# 거짓(0)이라는 레이블을 붙여 판별자로 입력됨
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
# 실제 이미지를 넣은 d_loss_real과 가상 이미지를 입력한 d_loss_fake가 판별자 안에서 번갈아 가며 진위를 판단
# d_loss_real, d_loss_fake 값을 더해 둘로 나눈 평균이 바로 판별자의 오차
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 판별자와 생성자를 연결해서 만든 gan 모델을 이용해 생성자의 오차, g_loss를 구함
# train_on_batch() 함수와 앞서 만든 gen_imgs를 사용
# 생성자의 레이블은 무조건 참(1)이라 해놓고 판별자로 넘김
# 앞서 만든 true 배열로 레이블을 붙임
g_loss = gan.train_on_batch(noise, true)
# 학습이 진행되는 동안 생성자와 판별자의 오차가 출력되게 함
print('epoch:%d' % i, ' d_loss:%.4f' % d_loss, ' g_loss:%.4f' % g_loss)
# 정해진 인터벌만큼 학습되면 만든 이미지를 gan_images 폴더에 저장
if i % saving_interval == 0:
# r, c = 5, 5
noise = np.random.normal(0, 1, (25, 100))
gen_imgs = generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(5, 5)
count = 0
for j in range(5):
for k in range(5):
axs[j, k].imshow(gen_imgs[count, :, :, 0], cmap='gray')
axs[j, k].axis('off')
count += 1
fig.savefig("./gan_mnist_%d.png" % i)
# 2000번 반복되고(+1을 하는 것에 주의),
# 배치 크기는 32, 200번마다 결과가 저장
gan_train(2001, 32, 200)1/1 [==============================] - 0s 73ms/step
epoch:0 d_loss:0.7040 g_loss:0.4531
1/1 [==============================] - 0s 70ms/step
1/1 [==============================] - 0s 18ms/step
epoch:1 d_loss:0.5400 g_loss:0.2114
1/1 [==============================] - 0s 19ms/step
epoch:2 d_loss:0.5148 g_loss:0.1527
1/1 [==============================] - 0s 18ms/step
...
epoch:2000 d_loss:0.5632 g_loss:1.4037
1/1 [==============================] - 0s 21ms/step










오토인코더
입력층보다 적은 수의 노드를 가진 은닉층을 중간에 넣어서 차원을 줄이고 입력층과 똑같은 크기로 출력층을 만듦
은닉층에서 차원이 줄어들어 소실된 데이터를 복원하기 위해 학습을 하게 되며
학습이 진행될 수록 데이터의 특징을 효율적으로 응축한 새로운 출력이 나오게 됨
오토인코더의 의의
GAN은 세상에 존재하지 않는 완전한 가상의 것을 만들어 냄,
세상에 존재하지 않는 가상의 것을 학습 데이터로 사용 불가
하지만 오토인코더는 입력 데이터의 특징을 효율적으로 담아낸 이미지를 만들어 내기 때문에
부족한 학습 데이터 수를 효과적으로 늘려 주는 효과를 기대할 수 있음
from tensorflow.keras.layers import MaxPooling2D# 생성자 모델 만들기
autoencoder = Sequential()
## 입력된 값의 차원을 축소시키는 인코딩 부분
autoencoder.add(Conv2D(16, kernel_size=3, padding='same', input_shape=(28,28,1), activation='relu'))
# 맥스 풀링을 통해 입력 크기를 줄임
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
autoencoder.add(Conv2D(8, kernel_size=3, activation='relu', padding='same'))
# 맥스 풀링을 통해 입력 크기를 줄임
autoencoder.add(MaxPooling2D(pool_size=2, padding='same'))
autoencoder.add(Conv2D(8, kernel_size=3, strides=2, padding='same', activation='relu'))
# 차원을 점차 늘려 입력 값과 똑같은 크기의 출력 값을 내보내는 디코딩 부분
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
# UpSampling을 통해 크기를 늘림
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(8, kernel_size=3, padding='same', activation='relu'))
# UpSampling을 통해 크기를 늘림
autoencoder.add(UpSampling2D())
# 아래에 크기를 유지시켜 주는 패딩 과정이 없으므로 (padding='same') 디코딩 부분에 3번에 걸쳐서 upsampling 필요
autoencoder.add(Conv2D(16, kernel_size=3, activation='relu'))
# UpSampling을 통해 크기를 늘림
autoencoder.add(UpSampling2D())
autoencoder.add(Conv2D(1, kernel_size=3, padding='same', activation='sigmoid'))
# 모델 컴파일
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 전체 구조 확인
autoencoder.summary() WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\optimizers\__init__.py:309: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_8 (Conv2D) (None, 28, 28, 16) 160
max_pooling2d_2 (MaxPoolin (None, 14, 14, 16) 0
g2D)
conv2d_9 (Conv2D) (None, 14, 14, 8) 1160
max_pooling2d_3 (MaxPoolin (None, 7, 7, 8) 0
g2D)
conv2d_10 (Conv2D) (None, 4, 4, 8) 584
conv2d_11 (Conv2D) (None, 4, 4, 8) 584
up_sampling2d_3 (UpSamplin (None, 8, 8, 8) 0
g2D)
conv2d_12 (Conv2D) (None, 8, 8, 8) 584
up_sampling2d_4 (UpSamplin (None, 16, 16, 8) 0
g2D)
conv2d_13 (Conv2D) (None, 14, 14, 16) 1168
up_sampling2d_5 (UpSamplin (None, 28, 28, 16) 0
g2D)
conv2d_14 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 4385 (17.13 KB)
Trainable params: 4385 (17.13 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________# MNIST 데이터셋을 불러옴
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255# 학습
autoencoder.fit(X_train, X_train, epochs=50, batch_size=128, validation_data=(X_test, X_test))Epoch 1/50
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
469/469 [==============================] - 10s 19ms/step - loss: 0.2056 - val_loss: 0.1357
Epoch 2/50
469/469 [==============================] - 9s 19ms/step - loss: 0.1251 - val_loss: 0.1164
...
Epoch 50/50
469/469 [==============================] - 9s 18ms/step - loss: 0.0822 - val_loss: 0.0810
<keras.src.callbacks.History at 0x196d3b96910>## 학습 결과 출력 부분
# 오토인코더 모델에 입력으로 넣음
ae_imgs = autoencoder.predict(X_test) 313/313 [==============================] - 1s 2ms/step# 테스트할 이미지를 랜덤으로 호출
random_test = np.random.randint(X_test.shape[0], size=5)
plt.figure(figsize=(7,2)) # 출력 이미지의 크기
for i, image_idx in enumerate(random_test):
# 랜덤으로 뽑은 이미지를 차례로 나열
ax = plt.subplot(2, 7, i+1)
# 테스트할 이미지를 그대로 보여 줌
plt.imshow(X_test[image_idx].reshape(28, 28))
ax.axis('off')
# 오토인코딩 결과를 다음 열에 입력
ax = plt.subplot(2, 7, 7+i+1)
plt.imshow(ae_imgs[image_idx].reshape(28, 28))
ax.axis('off')
plt.show()

20장
supervised learning(지도 학습)
각 데이터마다 ‘클래스’라는 정답을 주어 학습
폐암 수술 환자의 생존율 예측, 피마 인디언의 당뇨병 예측, CNN을 이용한 MNIST
unsupervised learning(비지도 학습)
정답을 예측하는 것이 아닌 주어진 데이터의 특성을 찾음
GAN, 오토인코더
Data Augmentation (데이터 증강)
CNN 모델의 성능을 높이고 오버피팅을 극복하기 위해선 이미지 데이터 양을 늘리는 것이 필요
하지만 이미지 데이터 양을 늘리는 것에는 한계가 있음 따라서 개별 원본 이미지를 변형시켜서 데이터량을 늘림
MRI 뇌 사진을 보고 치매 환자의 뇌인지, 일반인의 뇌인지 예측
컨볼루션 신경망(CNN)을 통한 이미지 분류, 지도학습
데이터:
치매 환자의 뇌 사진 140장과 일반인의 뇌 사진 140장, 160개는 train 120개는 test
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
# 치매 환자의 뇌 사진 140장과 일반인의 뇌 사진 140장
!git clone https://github.com/taehojo/data-ch20.gitfatal: destination path 'data-ch20' already exists and is not an empty directory.# Data Augmentation (데이터 증강)
train_datagen = ImageDataGenerator(
rescale = 1./255 , # 0~255의 RGB값을 255로 나눠 0~1의 값으로 변환
horizontal_flip = True , # 수평 대칭 이미지를 50% 확률로 만듦
vertical_flip = True , # 수직 대칭 이미지를 50% 확률로 만듦
width_shift_range = 0.1 , # 전체 크기의 15% 범위에서 좌우로 이동
height_shift_range = 0.1 , # 전체 크기의 15% 범위에서 위아래로 이동
rotation_range = 5 , # 정해진 각도만큼 회전
shear_range = 0.7 , # 좌표 하나를 고정시키고 나머지 픽셀의 좌표를 이동
# zoom_range = [0.9, 2.2], # 확대 또는 축소
fill_mode = 'nearest' # 축소, 회전, 이동할 때 생기는 빈 공간을 어떻게 채울지
) # nearest: 가장 비슷한 색으로 빈 공간을 채움
train_generator = train_datagen.flow_from_directory(
directory = './data-ch20/train', # 학습셋이 있는 폴더 위치
target_size = (150,150) , # 이미지 크기
batch_size = 5 ,
class_mode = 'binary' # 치매/정상 이진 분류이므로 바이너리 모드로 실행
)
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
directory = './data-ch20/test', # 테스트셋이 있는 폴더 위치
target_size = (150,150) ,
batch_size = 5 ,
class_mode = 'binary'
)Found 160 images belonging to 2 classes.
Found 120 images belonging to 2 classes.model = Sequential()
model.add( Conv2D ( 32, (3, 3), input_shape=(150,150,3) ) )
model.add( Activation ( 'relu' ) )
model.add( MaxPooling2D ( pool_size=(2,2) ) )
model.add( Conv2D ( 32, (3, 3) ) )
model.add( Activation ( 'relu' ) )
model.add( MaxPooling2D ( pool_size=(2,2) ) )
model.add( Conv2D ( 64, (3, 3) ) )
model.add( Activation ( 'relu' ) )
model.add( MaxPooling2D ( pool_size=(2,2) ) )
model.add( Flatten ( ) )
model.add( Dense ( 64 ) )
model.add( Activation ( 'relu' ) )
model.add( Dropout ( 0.5 ) )
model.add( Dense ( 1 ) )
model.add( Activation ( 'sigmoid' ) )
# 모델 실행 옵션
model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])# 학습 조기 중단
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = model.fit(
x = train_generator ,
epochs = 100 ,
validation_data = test_generator ,
validation_steps = 10 ,
callbacks = [early_stopping_callback]
)Epoch 1/100
32/32 [==============================] - 2s 34ms/step - loss: 0.7084 - accuracy: 0.5250 - val_loss: 0.6881 - val_accuracy: 0.6600
...
Epoch 28/100
32/32 [==============================] - 1s 31ms/step - loss: 0.0898 - accuracy: 0.9750 - val_loss: 0.0903 - val_accuracy: 0.9800# 그래프
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
transfer learning(전이 학습)
수만 장에 달하는 기존의 이미지에서 학습한(가중치 등) 정보를 가져와 활용하는 것
대규모 데이터셋에서 학습된 기존의 네트워크를 앞쪽에 채우고 뒤쪽 레이어에서 내 프로젝트와 연결
그리고 이 두 네트워크가 잘 맞물리게끔 미세 조정(fine tuning)
VGGNet
VGGNet은 옥스포드 대학의 연구 팀 VGG에 의해 개발된 모델로,
2014년 이미지넷 이미지 인식 대회에서 2위를 차지
학습 구조에 따라 VGG16, VGG19등이 있으며 우리는 VGG16을 사용할 것
from tensorflow.keras.applications import VGG16 # Pre-trained model
transfer_model = VGG16(
weights = 'imagenet' ,
# include_top: VGG16의 마지막 층 분류를 담당하는 부분을 불러올지 말지를 정하는 옵션
include_top = False , # 직접 만든 로컬 네트워크를 연결할 것이므로 False로 설정
input_shape = (150,150,3)
)
# 불러올 부분이 학습되지 않도록 False로 설정
transfer_model.trainable = False
transfer_model.summary()Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 150, 150, 3)] 0
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14714688 (56.13 MB)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 14714688 (56.13 MB)
_________________________________________________________________# Fine-tuning model
finetune_model = models.Sequential()
finetune_model.add( transfer_model )
finetune_model.add( Flatten ( ) )
finetune_model.add( Dense (64 ) )
finetune_model.add( Activation ('relu' ) )
finetune_model.add( Dropout (0.5 ) )
finetune_model.add( Dense (1 ) )
finetune_model.add( Activation ('sigmoid' ) )
# 모델 실행 옵션
finetune_model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
finetune_model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten_1 (Flatten) (None, 8192) 0
dense_2 (Dense) (None, 64) 524352
activation_2 (Activation) (None, 64) 0
dropout_1 (Dropout) (None, 64) 0
dense_3 (Dense) (None, 1) 65
activation_3 (Activation) (None, 1) 0
=================================================================
Total params: 15239105 (58.13 MB)
Trainable params: 524417 (2.00 MB)
Non-trainable params: 14714688 (56.13 MB)
_________________________________________________________________# 학습 조기 중단
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = finetune_model.fit(
x = train_generator ,
epochs = 100 ,
validation_data = test_generator ,
validation_steps = 10 ,
callbacks = [early_stopping_callback]
)Epoch 1/100
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\utils\tf_utils.py:492: The name tf.ragged.RaggedTensorValue is deprecated. Please use tf.compat.v1.ragged.RaggedTensorValue instead.
WARNING:tensorflow:From c:\ProgramData\anaconda3\envs\study\Lib\site-packages\keras\src\engine\base_layer_utils.py:384: The name tf.executing_eagerly_outside_functions is deprecated. Please use tf.compat.v1.executing_eagerly_outside_functions instead.
32/32 [==============================] - 7s 191ms/step - loss: 0.6627 - accuracy: 0.5875 - val_loss: 0.6013 - val_accuracy: 0.6200
Epoch 2/100
32/32 [==============================] - 6s 174ms/step - loss: 0.5618 - accuracy: 0.6938 - val_loss: 0.5416 - val_accuracy: 0.7800
...
Epoch 19/100
32/32 [==============================] - 6s 173ms/step - loss: 0.1762 - accuracy: 0.9312 - val_loss: 0.2003 - val_accuracy: 0.9000# 그래프
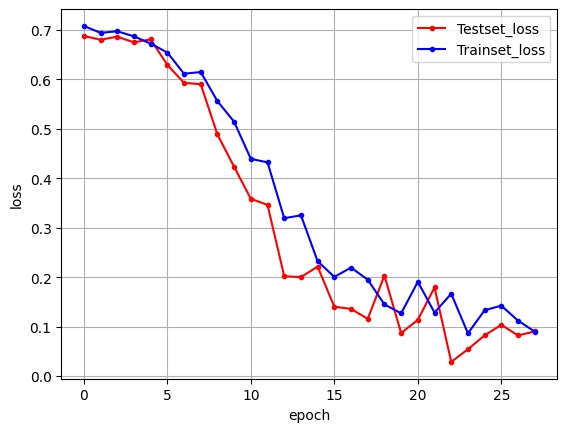
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
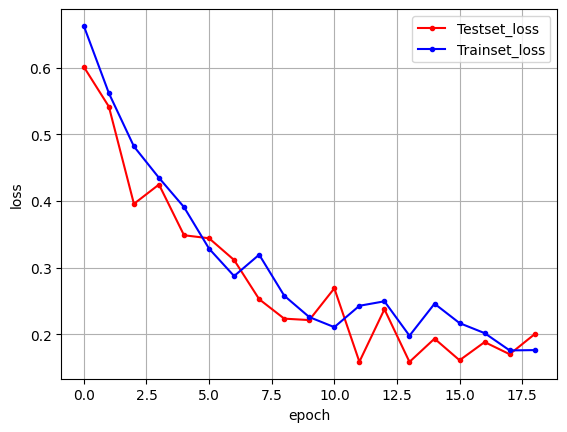
전이 학습을 사용하지 않았던 이전보다 더 높은 정확도로 출발하는 것을 볼 수 있음
따라서 학습 속도도 빨라진 것이 확인되며 그래프의 변화 추이가 안정적임
