Survey on Software Defect Prediction Review
기본 개념
Metric
: S/W 측정을 통하여 S/W의 품질, 생산성 또는 개발 비용들을 추정할 수 있는 척도이다.
머신러닝
1. Classification
: 주어진 데이터를 정해진 카테고리에 따라 분류하는 문제이다.
binary Classification : 분류 규칙에 따라 주어진 집합의 요소를 두 그룹으로 분류하는 작업 (맞다 or 아니다 2가지 선택지)
(결함 예측에서는 버그 or clean으로 구분된다.)
2. Regresstion
: 연속된 값을 예측하는 문제이다. 어떤 패턴이나 트랜드, 경향을 예측할 때 사용한다. 다른말로 다시 말하자면 어떤 자료에 대해서 그 값에 영향을 주는 조건을 고려하여 구한 평균값이다.한글로는 회귀 분석이라고 한다.
(결함 예측에서는 Regresstion을 통해 버그의 개수를 구한다.)
Defect Prediction의 최초 가정
: 복잡한 코드가 버그를 가질 가능성이 높다.
따라서 코드의 복잡성을 측정하는 다양한 척도(Metric)이 제안되었다.
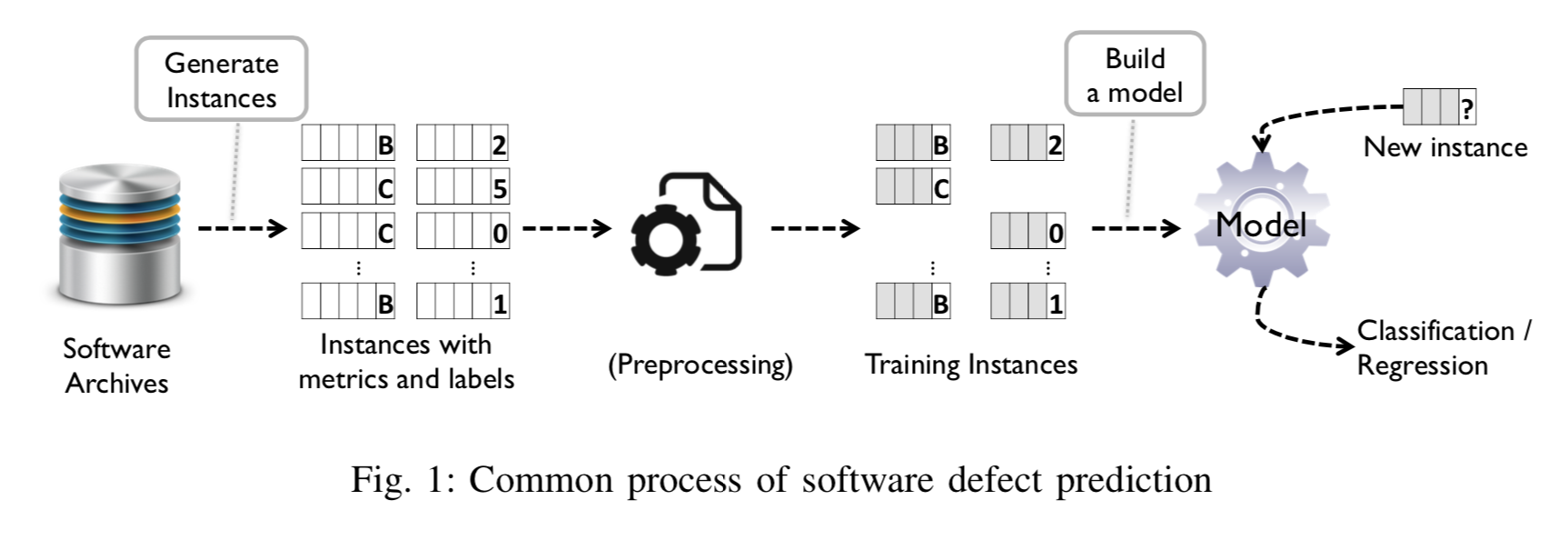
버그 예측 과정 3단계
용어
예측 : 답이 없는 것에 대해서 답을 추측하는 것
인스턴스 : 시스템 소프트웨어 컴포넌트(패키지), 소스코드 파일, 클래스, 함수 또는 방법, 코드 변경 사항
Software artifacts : 소프트웨어 개발 중에 생산되는 많은 유형의 부산물 중 하나, 리포지토리, Version Control SystemStep1 : 인스턴스 생성
: 인스턴스는 software artifacts로부터 추출된 메트릭이 있고, buggy/clean or the number of bugs로 레이블이 지정이 된다.
Step2 : 전처리 과정
: 메트릭과 레이블이 지정된 인스턴스를 전처리 과정을 거친다. 결함 예측에서 사용하는 전처리 기술에는 feature selection, data normalization (분류 모델의 성능을 향상시키기 위해 메트릭 값에 동일한 가중치를 부여하는 일반적인 기술), noise reduction 세가지가 있다.
- 하지만 모든 버그 예측 기술에서 전처리 과정을 거치는 것은 아니다.
Step3 : Prediction model 을 훈련
: Final set of training instances를 가지고 prediction model 을 훈련시킬 수 있다. 그리고 이는 2가지의 정보를 준다.
- regression : 버그의 수
- binary classification - bug or clean
(주로 classification이 많이 쓰임, 버그인 확률까지 나온다.)
결함 예측 모델 평가 방법
목적 : 결함 예측 성능 향상을 위해서 고안되었다.
A. Classification
양성 : 내가 관심이 있는 것 (Positive)
EX) 코로나 양성 반응 : Positive
결함 예측에서는 bug가 양성(Positive)에 해당됨.
버그로 예측했다 : positive
clean으로 예측했다 : negative
예측이 맞았다 : True
예측이 틀렸다 : False
True positive (TP): 버그 인스턴스를 버그로 예측
False positives (FP): 버그 인스턴스를 클린으로 예측
True negative (TN): 클린 인스턴스를 클린으로 예측
False negative (FN): 클린 인스턴스를 버그로 예측
1. False positive rate(FPR or PF)
- clean instance 중에 buggy로 예측한 것
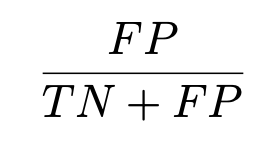
2. Accuracy (정확도)
-
전체 중에
전체 중에 True값, 데이터 값의 불균형 때문에 자주 쓰지는 않는다.
여기서 데이터 값의 불균형이란?
: 데이터가 불균형하다는 것인데, 데이터가 불균형할 때의 정확도는 의미가 없다.EX) 코로나 검사를 1000명이 한다고 한다. 그런데 이 중에서 실제로 코로나 걸린사람은 3명 뿐이고 나머지 997명은 코로나가 아니다. (데이터 불균형이 일어남) 그런데 내가 만든 툴킷 A는 항상 clean이라는 값만 내놓는다. 툴킷 A는 위와 같은 상황에서 Accuracy가 99.7%가 나온다. 정말 의미가 없어진다.
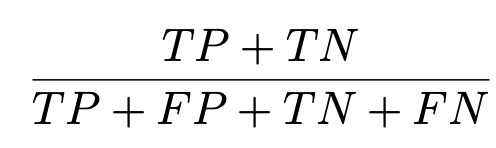
3. Precision
- 버그로 예측한 것들 중에 실제 버그인 것.
버그를 정확하게 찾는 것.
Precision이 높을 때, 찾는 bug는 bug일 확률이 높다.
Precision이 낮을 때, 찾는 bug는 bug일 확률이 낮다.
주로 쓰이는 곳 : 일반 개발자들(개발자들 입장에서는 버그를 찾는 개수보다는 버그를 찾아도 그것이 버그인 것이 더 중요하다.)
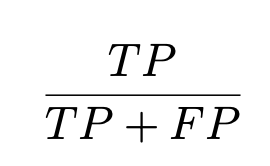
4. Recall (PD or TPR)
- 버그 인스턴스 중에 버그로 예측한 경우
버그를 놓치지 않고 찾는 것.
Recall이 높을수록 bug를 찾는 개수가 많아진다.
주로 쓰이는 곳 : 우주 소프트웨어, 의료 장비 소프트웨에서 많이 중요하다 (bug를 bug가 아니라고 판단하면 안되기 때문이다.)
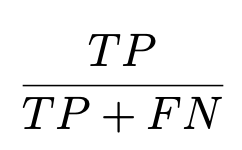
5. F - measure
- precision과 Recall의 harmony
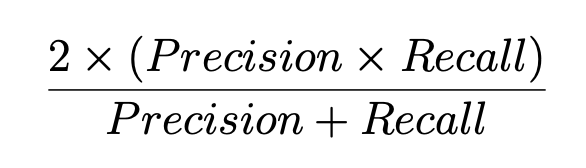
Recall과 Precision의 관계
: Recall과 Precision는 상충관계이다.
모든 환자에 대해서 양성이라고 나오는 키트가 있고 사람 100명중 50명은 암에 걸려있다.
이때, Recall은 1이 되고,
Prescision은 0.5가 된다.
키트의 성능이 향상되면서, 암환자로 판단되는 기준이 까다로워 졌다.
(TN이 늘어나면, FP는 줄어들고 FN은 늘어난다.)
암환자가 아닌 사람은 아니라고 판단함으로써 정확히 암환자를 파악할 수 있지만, 놓치는 암환자가 존재한다.
이런 경우, 암환자를 놓치지 않고 찾는 값을 나타내는 Recall 값은 떨어지고, 암환자를 정확하게 예측하는 값을 나타내는 Precision은 늘어난다.
6. AUC
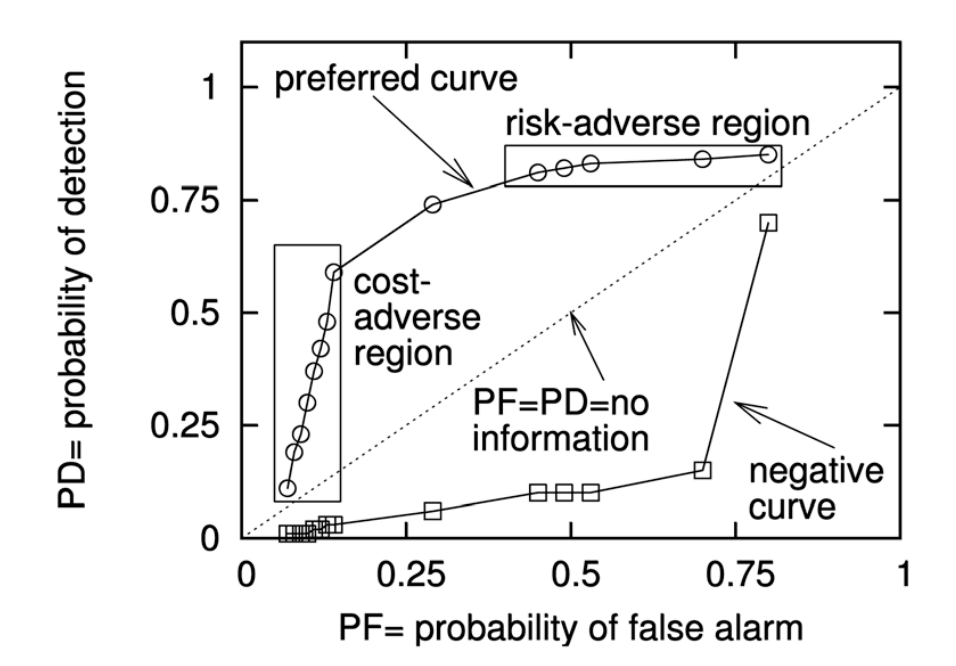
: ROC면적을 측정, ROC 곡선은 PF와 PD에 의해 표현된다. PD와 PF는 인스턴스의 예측 확률에 대한 임계값에 따라 달라지는데 예측 모델이 더 좋아질수록, PD는 1이되고 PF는 0이된다. 즉, 완벽한 예측 모델은 AUC 값을 “1”로 가진다.
(0,0) ~ (1,1)을 잇는 직선 ROC는 랜덤 예측으로 간주되며, 이 말은 AUC가 0.5인 경우 랜덤 예측으로 간주된다.
AUC는 모든 가능한 임계값에서 예측 성능을 고려하기 때문에 예측 모델을 비교하는 안정적 척도이다.
그리고 AUC는 trade-off값을 고려하지않고 모든 것을 고려하여 사용하는 평가 방법이다.
7. AUCEC(Area under cost-effectiveness curve)
: LOC를 고려한 결함 예측 측정법이다.
여기서 Cost-effectiveness란 이미 검사가 끝난 상위 n% LOC에서 발견할 수 있는 결함 수를 나타낸다.
AUCEC가 높을 수록 더 적은 LOC로 더 많은 결함을 찾는게 가능하다.
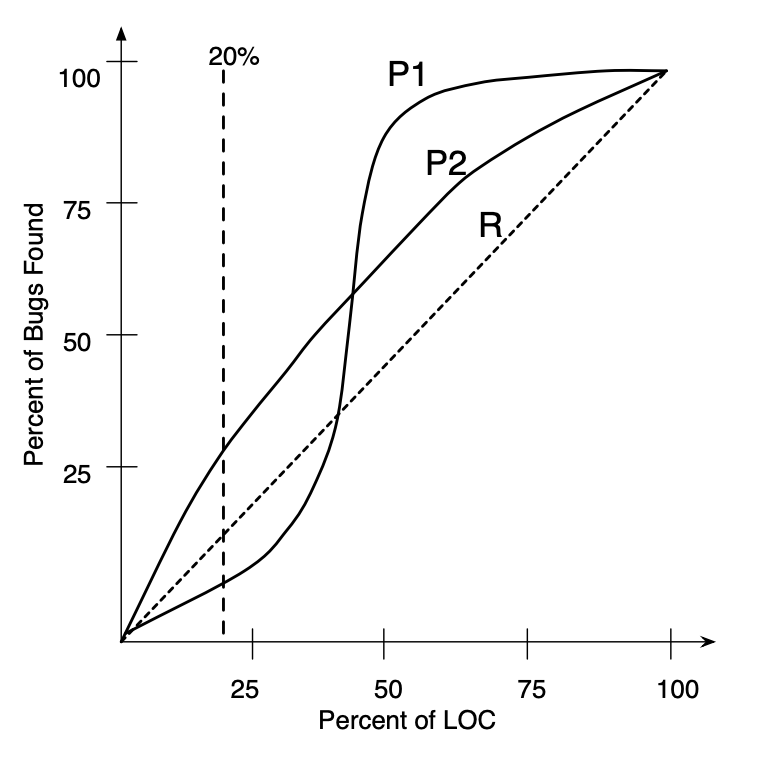
아래의 그래프에서 O는 최적의 AUCEC를 나타내는 그래프이고 P는 실제 모델을 나타내고, R은 랜덤 값을 나타낸다.
Cost-effectiveness : 특정 예측 모델이 다른 모델과 비교하여 적은 노력으로 더 많은 결함을 발견할 때,
Cost-effectiveness가 높다고 말한다. 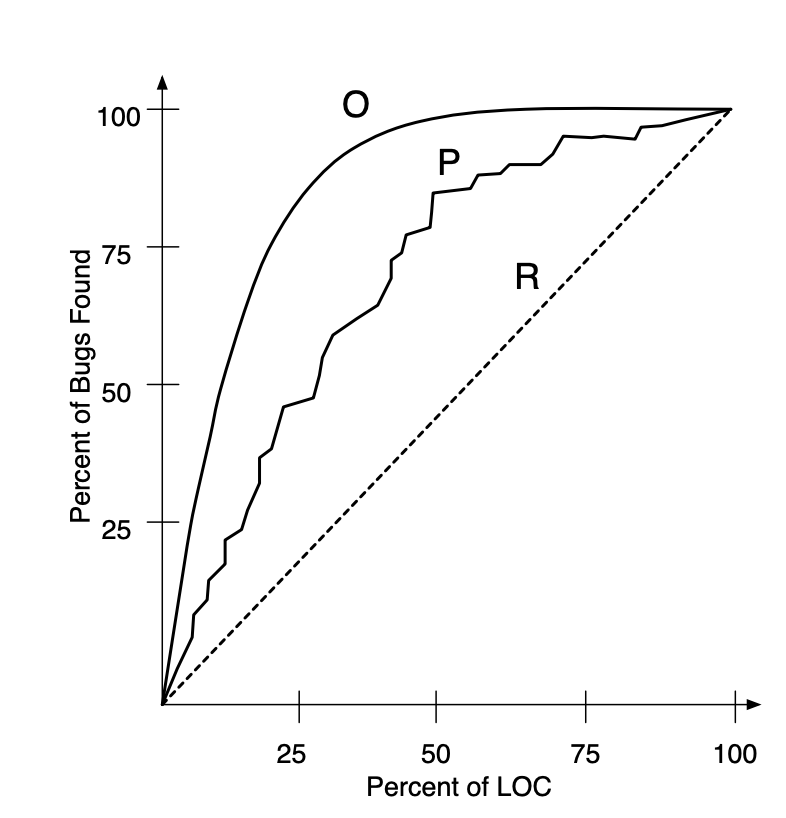
전체 LOC고려시 아래의 P1과 P2와 같이 AUCEC를 가지는 예측 모델들이 있다.
->(전체 LOC고려하는 것이 의미가 없을 수 도 있다)
-> LOC 백분율에 대한 특정 임계 값을 고려해야함
B. Measures for Regression
: “실제 버그 수”와 “인스턴스의 예측 된 버그 수” 사이의 상관 관계 계산에 기반한 측정방법이다.
상관 관계 : 상관 계수는 두 변수가 함께 변화하는 경향이 있는 범위를 측정,
상관 계수는 변수의 상관 관계 정도와 방향의 정보를 가진다.대표적인 척도
1. Spearman의 상관 관계 (스피어만) : 두 계량형 변수 또는 순서형 변수 사이의 단순 관계를 평가,
2. Pearson 상관 관계 : 피어슨 상관 계수란 두 변수 X 와 Y 간의 선형 상관 관계를 계량화한 수치, 한 변수의 변화가 다른 변수의 변화에 비례적으로 연관되어 있는 경우
3. R^2 및 변형
C. Discussion on Measures
about the Measures for Classification...
F - measure 방식이 가장 많이 사용된다.
이유 : Recall과 Precision는 상충관계 ( 한쪽이 좋아지면 한쪽이 나빠짐)에 있다. 따라서 Recall과 Precision의 조화된 평균인 F - measure방식이 많이 사용된다.
F - measure의 문제점 : F - measure은 예측 확률 임계값에 따라 달라진다. 이는 모델이 버그 인스턴스로 예측될 때, 인스턴스가 버그인지 아닌지에 대한 확률을 제공함. 하지만 임계 값에 따라 버그 예측 확률이 달라진다.
해결 : AUC & AUCEC와 같은 다른 측정도 사용
Metric의 종류
- 결함 예측 메트릭은 크게 2가지로 나뉜다.
1. 코드 메트릭 : 기존 소스 코드를 직접 수집하는 방법이다.
2. 프로세스 메트릭 : 버전 컨트롤 시스템 및 문제 추적 시스템과 같이 다양한 소프트웨어 리포지토리에 보관된 기록에서 정보를 수집한다.
Code Metric
1. size metrics
: 대표적인 예로 LOC가 있다. ( by Akiyama)
: operators and operands의 수를 기반으로 한 Metrics (By Halstead)
문제점 : 시스템의 복잡성을 보여주기에는 너무 간단한 메트릭이다.
2. The cyclomatic metric
complexity of software products를 나타낸다.(by McCabe)
소스 코드에서 nodes, arcs, connected components의 수를 계산한 것이다. 이 metric의 주 아이디어는 얼마나 많은 복잡한 control path와 contol flow graphs의 수를 가지느냐 이다.
Size metrics와의 차이점 : cyclomatic metric는 소스 코드 구조의 복잡성을 측정하는 것이고, size metric은 말그대로 size크기와 복잡성이 비례한다는 것이다.
문제점 : 실제로 예측 모델이 아닌 메트릭과 결함 수 사이의 상관 관계를 조사한 fitting모델에 불과하다.
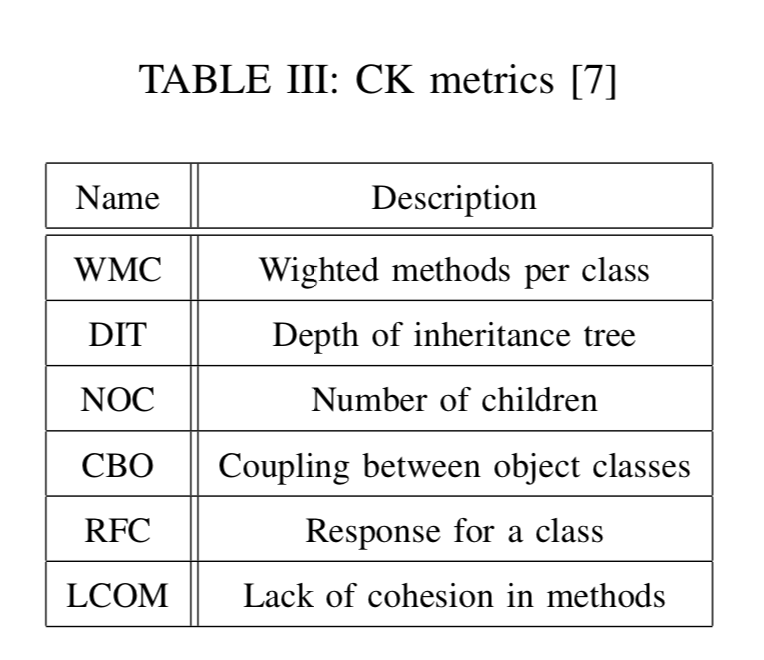
3. Chidamber and Kemerer (CK) metrics
: 객체 지향언어에 대한 메트릭이다. 객체 지향 언어의 특성인 상속, coupling, cohesion을 고려하여 만들어진 것이다.
CK list
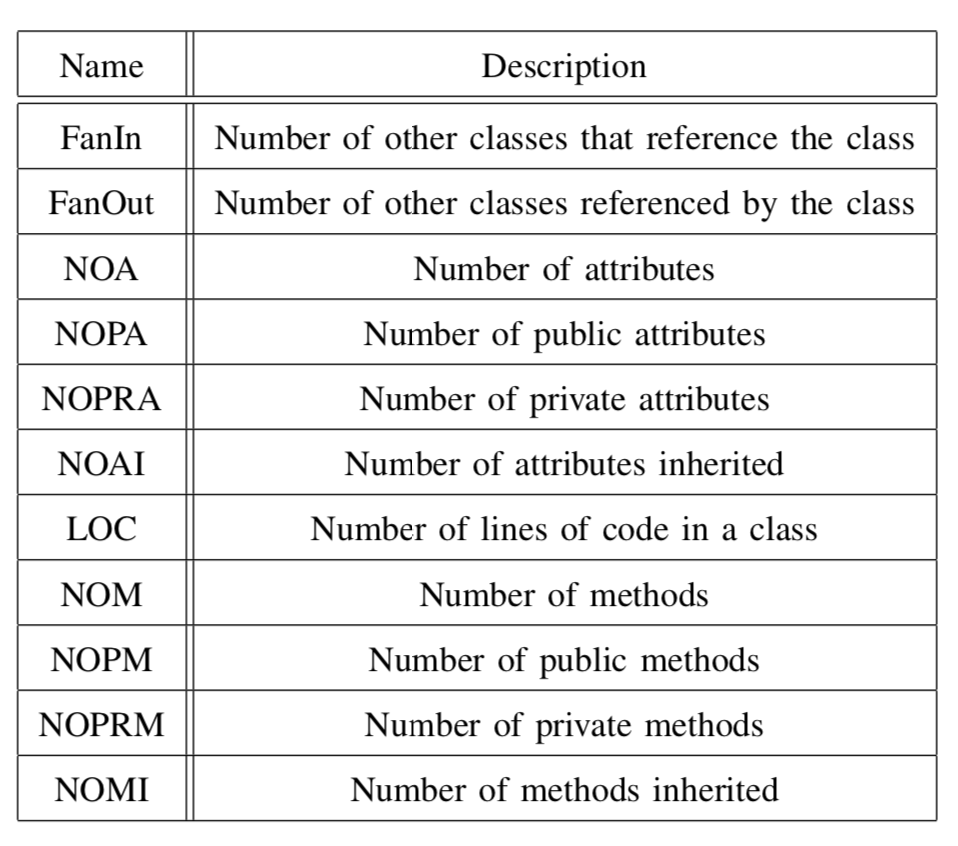
CK외에도 소스코드의 volume and quantity를 기반으로 한 OO메트릭도 제안되었다. 인스턴스 변수, 메소드 등의 수에 따라 계산되었다.
Process Metric
: 2000년대 이후부터 Version Control System이 대중화 되고, 개발 과정을 리파지토리에 저장하여 리소스가 다양해졌다. 이 이후로 다양한 Process Metric이 제안되었다.
1. Relative code change churn
: change가 얼마나 복잡하냐? 얼마나 많은 빈도? 빈도수가 많으면 누적 라인도 많다.
용어
Code churn : 개발자들이 자기의 코드를 기간내에 고친다. 즉 특정 시간 동안 코드를 고친 수를 나타낸다.
Churned LOC : 새 버전과 기존 버전 사이에 삭제 및 추가 된 LOC)
File churned : 구성요소가 변화된 파일의 수: 코드의 변화를 측정하는 8개의 relative code churn metric이 있다.
M1 Metric = churned LOC(삭제 and 추가 된 코드) / Total LOC
M2 ~ M8 = 삭제된 LOC / Total LOC
파일 : 변경된 파일의 수 / Total 파일 수
검증 결과 : Relative code change churn가 binary and bug-proneness의 결함 밀도를 설명하는데 좋은 predictor라는 것이 증명되었다.
2. Change metrics
: to measure the extent of changes in the history recorded in CVS
(by Moser et al.)
CVS로부터 파일 안에서 revisions/bugfix changes/refactorings수를 알 수 있고 파일을 수정한 authors의 수를 알 수 있다. 따라서 CVS에 기록된 정보를 가지고 변화된 범위를 측정한다.
연구 수행
목적 : code와 change metrics 사이의 비교분석을 알기 위해서 수행하였다.
Eclipse repositories로부터 18개의 change metrics을 추출 해내었다.
주로 added and deleted LOC 사용했다. (Relative code change churn과 비슷하다)
Relative code change churn과의 차이점 : Change metrics는 relativeness by the total LOC and the file count을 고려하지 않음)
대신,
average and maximum values of change churn metrics
maximum and average of change sets
age metrics 을 고려함.
age metrics : 주 단위의 파일 연령 및 추가 LOC 에 의해 정규화 된 가중치 연령
Change set : 동시에 바뀐 개수를 count, 변화된 덩어리, change의 평균 변화량검증 결과 : code metrics보다 좋은 predictor라는 것으로 판단하였다.
3. Change Entropy
History complexity metric (HCM)
: Shannon’s entropy를 적용하여 변화가 얼마나 복잡한지 측정하는 것이다.
옛날 정보는 지금에 의미가 없을 수 도 있다. 즉, 복잡한 정보의 변화들도 퇴색이된다. HCM은 정보의 유효성을 측정한다.(정보 이론) 시간이 지남에 따라 복잡도를 측정하는 metric이 복잡도를 측정하지 않을수도있다.
Shannon entropy :모든 사건 정보량의 기대값을 뜻함
옛날 정보 : 지금에 의미가 없을 수 도 있다.
정보의 유효성을 측정한다?? (정보 이론)
복잡한 정보의 변화들도 퇴색이된다.
시간이 지남에 따라 복잡도를 측정하는 metric이 복잡도를 캡쳐를 하지 않을수도있다.
참고 사이트 : https://ratsgo.github.io/statistics/2017/09/22/information/HCM 검증 수행
statistical linear regression models을 사용하였다.
statistical linear regression models : “HCM”와 “이전의 결함 수”와 “이전의 수정 횟수”의 two change metrics을 기반으로 만든 모델검증 결과
: 2개의 change metrics를 사용하는 것보다 HCM을 사용하는 것이 더 성능이 우수함.
한계점
1. 2개의 change metric만 고려 -> 제한된 검증
2. file level x, subsystem-level에서 수행되었음.
4. Code metric churn, Code Entropy
: defect prediction metrics의 비교 (by D’Ambros et al)
biweekly basis of code metrics : 2주단뒤로 정기적을 측정“code metric churn” 와”code Entropy”의 이전 하위 버전의 비교 방법은 존재하지만, "code churn"과 "change Entropy metrics"을 비교하는 방법은 존재하지 않는다.
D’Ambros et al가 CHU(code metric churn)와 HH(code Entropy)를 비교할 수 있는 방법을 제안하였다.
뜻
change Entropy : LOC가 변화된 걸 추정하여 변경된 파일의 수를 센다.
code Entropy : 메트릭(척도)를 기반으로 변화된 메트릭을 추정하여 변경된 파일의 수를 센다.
Change Entropy metric : 코드 라인 수 변화 ( 그냥 변화된 모든 것)
CHU : CK, OO metric과 같이 biweekly basis of code metrics 측정 (코드라인수 가 아님)
CHU : 이전 버전과 현재 버전의 변화의 양을 추정하는 것 보다 변화의 범위를 추정하는 것이 더 효율적 임.
CHU의 변형된 4가지 기능 : WCHU, LDCHU, EDCHU, and LGDCHU
HH의 변형된 4가지 기능 : HWH, LDHH, EDHH, and LGDHH
검증 결과
WCHU and LDHH metrics가 좋은 prediction의 결과를 가진다.
한계점
CVS로부터 biweekly changes을 추적함
-> heavy computation resources and data
5. Popularity
: 개발자들의 e-mail archives을 분석하여 개발한다.
이메일 속의 software artifacts에 더 많은 버그가 있을 것이다. (이메일 속에 특정한 class가 얼마나 있느냐?)
옜날에는 개발자들끼리 이메일로 정보와 논의를 주고 받았다.(작업 중인데 패키지 파일을 어떻게 바꿀까..?).
이 때, "이메일에서 많이 논의되는 class나 함수가 있으면 거기에 버그가 많이 있을 것이다."라고 생각하는 것이다.
마이닝을 한다. (데이터를 긁어와서 마이닝 기법을 사용하여 패턴을 찾아내고 등등 함)검증 결과
다른 code and process metric보다 성능이 좋지 못하다.
Ownership and Authorship:
: How much does ownership affect quality? (소유권이 퀄리티에 얼마나 많은 영향을 끼치는가?)
1. Component의 저작물에 기초해서 4가지의 소유권 제안되었다.(by Bird et al)
Component의 소유권 : component의 커밋 부분에 의해 정의되는데,
major contributors는 각각 소유권의 5%미만으로 정의4가지의 소유권 제안
1.MINOR (the number of minor contributors).
2.MAJOR (the number of major contributors)
3.TOTAL (the total number of contributors)
4.d OWNERSHIP (portion of ownership of the contributor with the highest portion of ownership)결과
높은 소유권은 less bug-prone을 가진다.
2. ownership and developer experience와 같은 human factors와 결함 사이의 관계성 세분화 ( by Rahman et al.)
: 개발 경험이 적은 개발자에 의해 쓰여진 파일 소스코드에 초점을 맞춘다.
7. Micro interaction metrics
: 소프트웨어 결함은 개발자의 실수로 인해 발생된다.
Ex) 소스 코드를 오랫동안 고친다. -> more bug-proneness.
Mylyn : 이클립스에 대한 개발자의 상호작용을 captures tool (이클립스 내장 라이브러리)
MIM : Mylyn에서 추출한 Metrics
연구 수행
Mylyn data가 개발자와 이클립스의 상호작용을 포함 한다. Mylyn data로부터 56개의 metric을 추출한 뒤, code and process metrics과 성능 비교
결과
classification and regression 성능을 뛰어넘었다.
한계점
Mylyn tool을 지원해주지 않는 경우, 즉, 이클립스가 아닌 경우에 MIM적용 못함.
-> MIM 실행 환경이 심하게 제한된다.
Other metrics
: existing knowledge인 network measure과 anti-pattern을 활용한다.
1.developer metrics
: developer social network을 기반으로 한 metrics ( by Meneely et al)
developer social network : collaboration structure extracted from source code repositories
결과
소프트웨어 결함은 developer network metrics와 높은 상관 관계가 있음.
2. developer network and software modules
‘contribution network’ : 각 개발자가 각 모듈에 얼마나 기여를 했는지를 나타낸다.
결과
contribution network 에 대한 centrality measures이 post-release defects 예측 할 수 있다.
centrality measures : 그래프 이론에서 중심성이란 그래프 혹은 사회 연결망에서 꼭짓점 혹은 노드의 상대적 중요성을 나타내는 척도.
1. contribution network통해 centrality measures prediction
2. centrality measures을 이용해 post release에 대한 결함을 prediction3. binaries graph의 dependency 만들고 그 dependency graphs에 대한 네트워크 분석
: centralness, closeness, betweenness와 같은 measure을 분석한다. (by Zimmermann et al)
Binary file : Binary file들이 서로 부른다
-> 서로의 관계성을 알 수 있다.
어느 파일이 어떤 파일을 부른다 (아주 복잡)
-> 그래프로 표현 가능
이런 복잡도들이 버그에 관련이 있을 수 있다.
이 관계성을 측정하는데 여러가지 척도가 있다.
Ex) 한쪽에 몰려있느냐…?, centrality measures, 용어
dependency
: 일반적으로 둘 중 하나가 다른 하나를 어떤 용도를 위해 사용.
central ness : centrality없음
closeness centrality
: 네트워크의 모든 node로부터 얼마나 가깝게 위치해 있는지를 고려 하여 centrality를 계산.
Betweenness centrality
: 네트워크의 모든 node pair간의 shortest path가 해당 노드를 지나는지를 고려한 centrality다.4. four antipattern metrics
: antipattern은 소스코드 파일에 더 많은 결함이 있을 것이다.(by Taba et al.)
antipattern : 패턴과 반대로 프로그래밍을 하는 과정에서 프로그래머들이 흔히 범하기 쉬운 바람직하지 않은 방법들을 말한다.
다시 말해서 실제 습관적으로 많이 사용하는 패턴이지만, 성능 디버깅, 유지보수, 가독성 등의 측면에서 부정적인 영향을 끼치는 패턴이다. (이상하게 짜는 패턴을 매트릭화)
대표적인 antipattern코드 : 스파케티 코드
결과
f-measure측정방법에서 예측 성능을 향상 시킬 수 있다는 것을 알게됨.
D. Discussion on code metrics vs. process metrics
Code metric은 1970년대 ~ 1990년대부터 쓰였기 때문에 Process metric보다는 사용 빈도가 많다.
Code metric은 새로운 metric이 나올 때마다 비교 대상이 된다.
Process metric은 2000년대 때에 CVS와 소프트웨어 리포지토리가 대중화 될 때부터 생겨나기 시작했다.
BugCache
: 캐시안에서 bug-prone entry에 우선순위를 유지시키는 것이다. 시간 및 공간적 지역과 같은 버그의 지역 정보를 사용한다. 내가 언제든지 cache를 볼 수 있다는 장점을 가지고 있다.
Temporal : 최근에 불린것이 또 불린것
-> 버그가 난 곳에서 버그가 난다 (어제 버그가 난 곳에서 수정했지만 버그가 또 발생 할 것이다.)
Spacial : 버그가 난 곳의 근처에서 버그가 일어 날 것이다.
비통계적인 모델이며 JIT모델이기는 하나, 완전히 JIT는 아니다.
한계점
Certain point : commit과는 관련 없다. 소스 코드에서만 볼 수 있다.
Efficiency of Defect Prediction
: 결함 예측의 효율성 -> 세분화
-
method-level defect prediction이 “package” and “file-levels”에서의 prediction보다 더 cost-effective라는 것이 제안되었다. (By Hata)
-
change classification을 사용한 prediction : 버전 컨트롤 시스템이 적용되거나 개발자가 소스코드를 변경할 때마다 바로바로 예측 결과를 제공함. 하지만 1만개가 넘는 특징으로 구성되어 실제로 사용하기에는 너무 무겁다. (By Kim et al)
-
성능 좋은 prediction 모델을 구축하기 위해서는 cost-effectiveness을 고려해야한다. cost-effectiveness을 향상시키는 것은 세분화하는 것이 가장 좋다. 따라서 많은 연구자들이 finer-grained level로 세분화 시키는 것이 필요하다.
finer-grained level의 예 :
line-level defect prediction, change classification전처리 과정
: 데이터 전처리기 - 전처리기 기술은 머신 러닝에서 널리 쓰이는 방식 중 하나이다.
1. 정규화
-
For classification models : classification model의 성능을 향상시키기 위해 메트릭 값에 동일한 가중치를 부여하는 일반적인 기술이다.
-
Exponential distribution에 대한 메트릭 값을 정규화 시키기 위해서 the logarithmic filter(log-filter)의 사용을 권장 (by Menzies et al)
-
cross-prediction performance에서 쓰이는 정규화 기술는은 조금 다르다(by Nam et al).cross-prediction performance을 위한 적절한 정규화 기술에는 min-max normalization, z-score와 variations of z-score이 있다.
2. Feature selection and extraction
classification & Feature selection
- defect prediction models의 성능 저하는 메트릭 수와 관련 있다. 따라서 change classification의 성능을 향상시킬 수 있는 a feature 22 selection technique을 제안되었다. (By Shivaji et al)
regression & extraction
- 결함 예측 데이터들을 multicollinearity 문제를 가질수 있다. 따라서 연구자들은 예측 모델에 대한 새로운 특징을 뽑아내기 위해 principal component analysis (PCA)기능을 적용하였다.
https://ratsgo.github.io/machine%20learning/2017/04/24/PCA/
multicollinearity 문제
-
회귀분석에서 등장하는 문제, 회귀 분석에서 사용된 모형의 일부 설명 변수가 다른 설명 변수와 상관 정도가 높아, 데이터 분석 시 부정적인 영향을 미치는 현상을 말한다.
-
회귀분석에서는 특정 설명 변수의 영향력을 파악할 때, 다른 설명 변수들은 모두 일정하다고 생각 -> 설명변수 끼리는 서로 독립이라는 것을 가정한다. 하지만 설명 변수 끼리 서로에게 영향을 주고 있다면 다른 하나의 영향력을 완벽히 통제 불가능하다.
참고 링크 : https://m.blog.naver.com/PostView.nhn?blogId=vnf3751&logNo=220833952857&proxyReferer=https:%2F%2Fwww.google.com%2F
3. Noise reduction
: defect data는 버전 컨트롤 시스템과 이슈 트레킹 시스템에서 자동적으로 수집된다.(szz 알고리즘) 따라서 편향될 가능성이 높다.
NOISE : 데이터 자체에 에러가 있는 것.
EX) lable정보가 틀린것, clean인데 buggy로 잘못 체크 된 것, commit message를 잘못 입력한 것, issue report type을 잘못 선택한 것, 이미 해결된 것 같은 경우는 done으로 바꾸어야 하는데 안바꾼 것(누락됨).
자동적으로 수집
: 자동으로 툴을 돌려 commit정보를 가져오는데 확인하지 않고 가져온다.
it’s not a bug its feature (13년도 논문)
- ReLink : commit logs와 issue ID사이의 올바른 links를 자동으로 복구하는 시스템 (by Wu et al)
-> 모든 commit이 이슈 id를 가지는 것은 아니다 (링크가 되어 있지 않다).
따라서 commit과 이슈 id를 연결해준다.(커밋 id와 이슈 id는 비슷하다는 개념을 사용하여 연결함)
issue ID : commit을 날리는 id
commit을 여러 issue id로 분류 - Closest List Noise Identification (CLNI)
: 노이즈를 감지하거나 제거하는 알고리즘(By Kim et al)
bug 영역에 있는 clean 제거 or clean 영역에 있는 bug 제거 (유클리드 distance를 기반으로)
bug와 clean을 나누는 기준선을 model이라고 부른다.
Defect Prediction for New Software Project
: New project는 training data set이 부족하다. 이런 경우, 좋은 prediction model을 만드는 것은 어렵다. 따라서 New Project나 history data가 부족한 project를 위해서 몇가지의 기술이 제안되었다.
Active learning
: 불확실하다고 판단된 데이터를 선별해서 사람에게 레이블링을 요구하는 방법이다. ( by Lu and Cukic)
Semi-supervised learning
: 관측치 하나마다 정답 레이블이 달려 있는 데이터셋을 가지고 모델을 학습시킨다. (히스토리가 없어서 lable이 없는 것들을 인위적으로 lable을 붙인다)
-
CoFest : 랜덤 Forest를 통해 랜덤 샘플을 가지고 예측 성능을 빠르게 평가하는 semi-supervised을 기반으로한 샘플링 접근법이다. ( 최고의 샘플을 찾기 위함)
-
ACoFest : CoFest 확장 버전이다. (by Li et al)
Cross-Project Defect Prediction
: New project나 history data가 부족한 project의 prediction model을 만드는데 사용되는 기술이다.
실제로 Zimmermann가 622개의 cross-predictions을 수행했지만,
그 중 3.4%만 제대로 작동하였다.
cross-prediction performance을 향상시키기 위해서는
"transfer learning"과 "cross-prediction feasibility"을 기초한 연구에 집중해야한다. 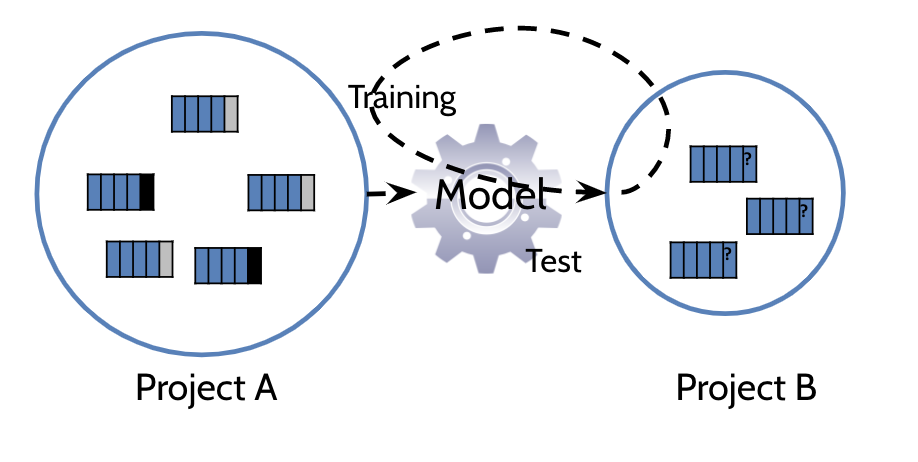
A. Transfer learning
: 학습 데이터가 부족한 분야의 모델 구축을 위해 데이터가 풍부한 분야에서 훈련된 모델을 재사용하는 머신 러닝 학습 기법이다.
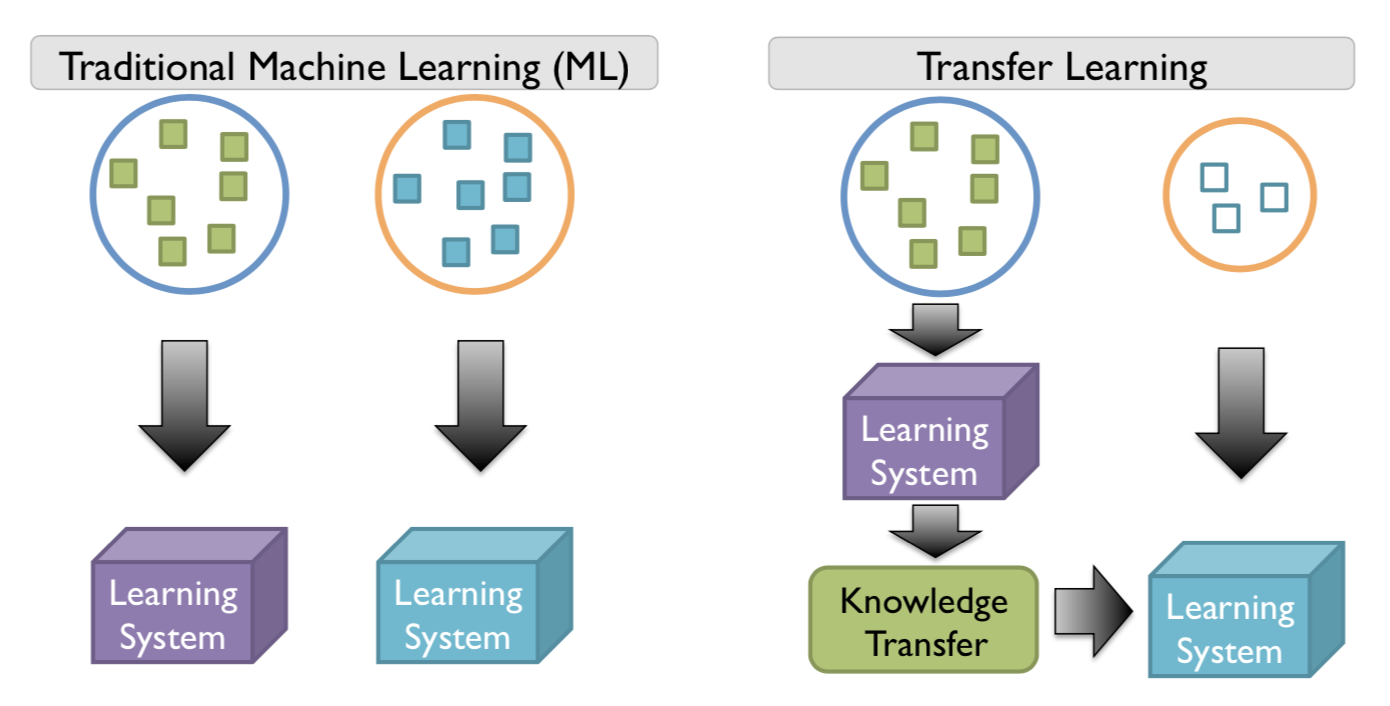
참고
기존 머신러닝에서는 training data와 test data의 데이타의 분배가 같아야한다. 이 경우, 데이타의 분배가 변하면 새로운 모델을 다시 만들어야 한다. 이 때, 새로운 모델을 위해 새 데이터를 수집하고 다시 labeling하는데 비용이 많이 든다는 문제점이 발생한다. 이를 Transfer Learning기법을 통해서 해결한다.
1. Metric compensation
: 소스코드를 사용하여 target data를 변환시키는 metric.(by Watanabe et al), transform을 수행한다.
Main idea
: Source Data의 “compensated metric”의 평균 metric값을 사용하여 각 metric을 정규화 시키는 것이다.
New target metric value
: target metric value * average source metric value / average target metric value
설명
모든 머신러닝 모델은 분배(distribution)이 같아야 잘 돌아간다.
소스와 타겟의 유사성이 있다는 가정.
소스 : 서양대학(키, 몸무게, 발사이즈 메트릭)
타겟 : 한동대(똑같이 메트릭 수집)
-> 상황에 맞지 않는다.
한동대 메트릭 값을 인위적으로 늘린다.
소스에 맞게끔, target metiric값을 바꾼다.
EX) 한동대 메트릭 값에 일정한 알파값을 더한다.
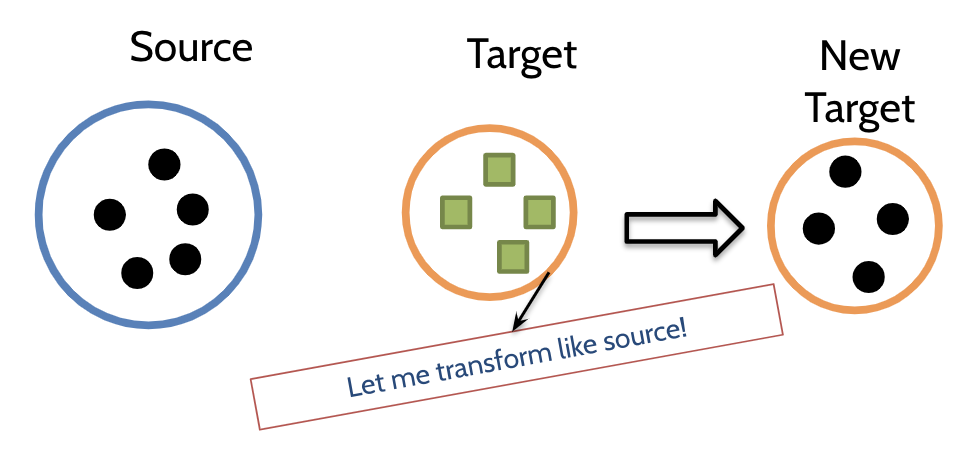
연구 수행
: Metric compensation을 가지고 cross-predictions에 대한 average f-measure을 측정하였다.
결과
Average f-measure (0.67) : metric compensation사용
Average f-measure (0.58) : 사용 x
Average f-measure (0.79) : within-predictions 사용
결론 : metric compensation을 사용한 것이 사용하지 않은 것보다 더 높게 나옴. 하지만 여전히 within-predictions이 더 좋다.
within-predictions - 기존의 방법, 자기 프로젝트 안에서 모델을 만들어서 예측하는 방법.
한계점
1. only two cross-predictions -> validate한지 판단할 수 없음.
2. 연구가 validate한지 검증할 수 있는 statistical test가 존재하지 않음.
2. NN filter - nearest neighbor filter
목적
: to improve performance of “cross-company defect” prediction
Company : 회사 단위
Cross-company Ex
: 네이버 데이타 카카오 데이타 크로스하겠다.
Project : 프로젝트 단위Main idea
: Prediction model을 training하기 위해 target instances와 비슷한 source instances을 수집하는 것이다. transform을 수행하지 않는다.
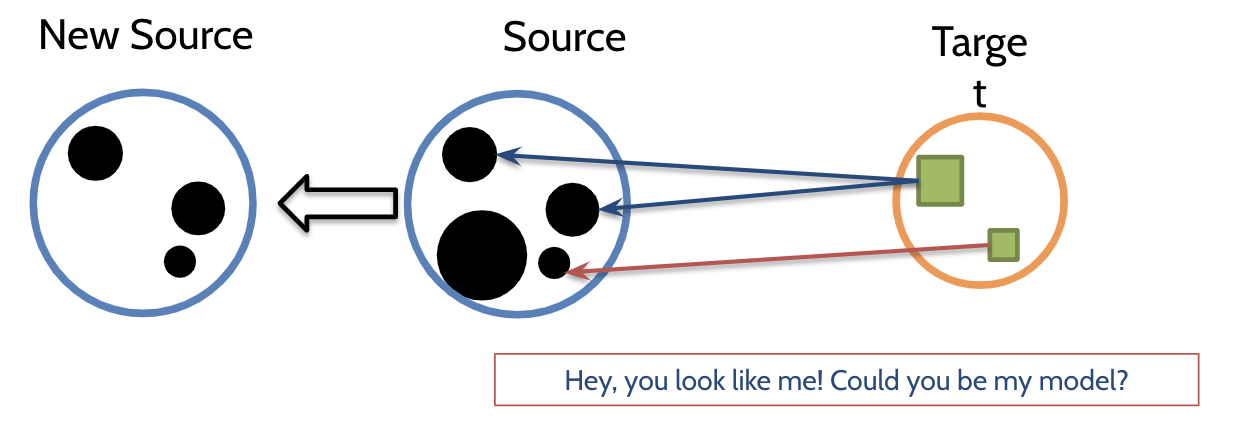
연구 수행
: NASA 와 SOFTLA의 10개의 proprietary datasets으로 실험을 수행하였다.
Mann-Whitney U test를 수행하여 실험 결과를 검증하였다.
Mann-Whitney U test: Student T Test , 통계적으로 유의미하다는 것을 표시하기위해선는 무조건 수행하는 테스트이다. 테스트를 적용한 것과 안한것과의 차이점을 밝혀 유의미한지 판단하는것 non parmeter방식이다. 과학 실험으로 예를 들땐 대조군같은 역할이다.
결과
PD and PF 결과로부터 average f-measure 계산
average f-measure (0.35) : NN filter 사용 함
average f-measure (0.26) : NN filter 사용 안함
All source instances를 사용하여 만든 model보다 더 효율적인 성능을 지닌다는 것을 확인할 수 있었다.
하지만 여전히 within-predictions이 더 좋은 성능을 가진다.
3. Transfer Naive Bayes ( by Ma et al)
Basic idea
: source instance의 weight value(가중치)사용하여 Naive Bayes model의 conditional probability(조건부 확률)과 new prior probability(사전 확률)를 계산하는 것이다.
training instance의 가중치가 높으면 높을 수록 test instances의 유사성이 높다.
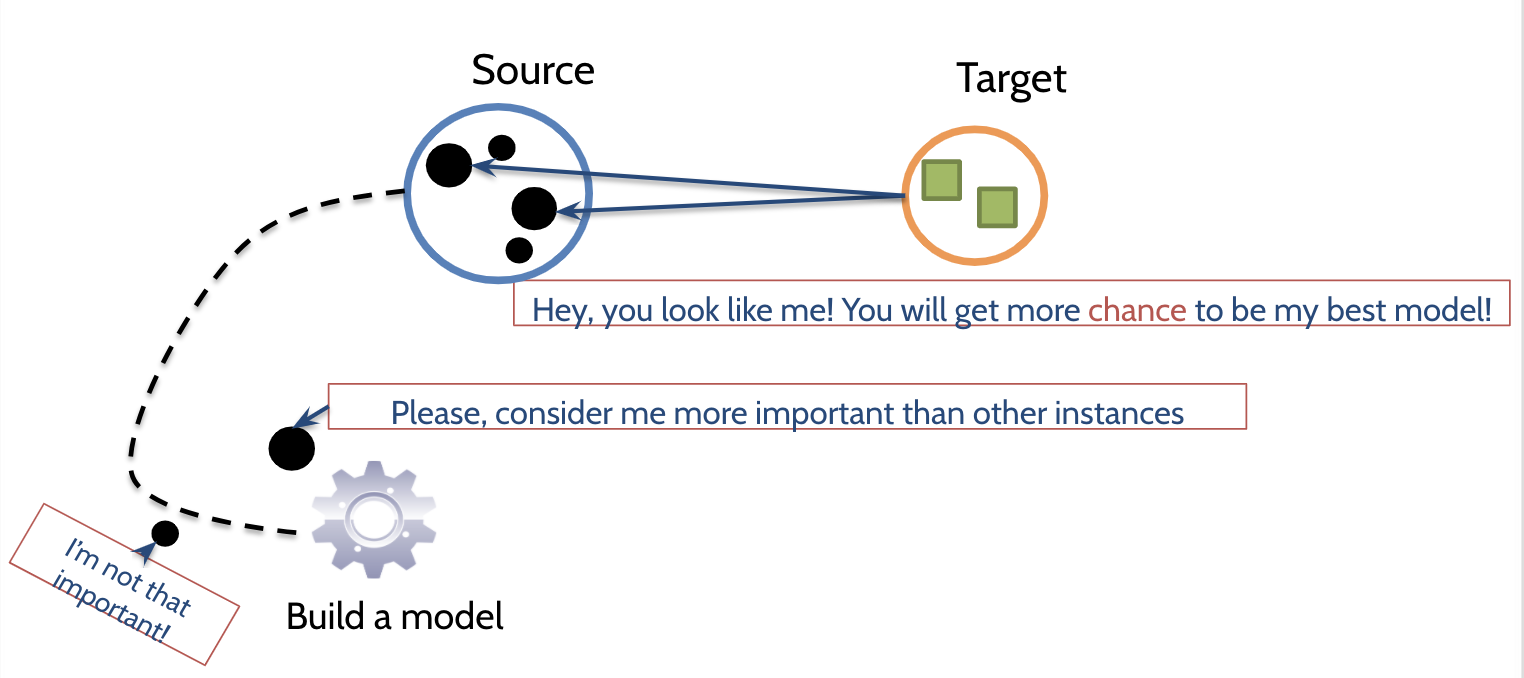
Source instance의 weight value
: Source instance와 Target instances의 비슷한 정도(유사성).
test instances의 유사성이 많은 경우, training instance의 weight이 높다.
Source instance의 weight value 계산 법 ( 유사성 계산법)
: features of a source instance의 수에 의해 유사성이 계산된다.
-> test dataset의 각각의 features의 min과 max값을 사용함.
결과
: f-measure의 측면에서 NN filter보다 더 나은 prediction performance을 가진다는 것이 증명되었다.
한계점
1. prior and conditional probabilities을 사용하지 않는 머신러닝 알고리즘에 적용하지 못한다.
2. Within prediction에 대한 연구 결과를 포함 하지 않았았다. -> TNB를 사용한 cross-prediction과 within-prediction의 비교를 결론지을 수 없다.
4. TCA+
: transfer component analysis (TCA)확장 버전
참고 사이트 : https://www.slideshare.net/hunkim/transfer-defectlearningnew-completed
TCA
: projection을 사용하여 비슷한 source and target datasets의 분포를 가지는 common latent feature space을 찾는다.
Projection : feature space을 줄여주는 머신 러닝 기술
참고 사이트 : https://excelsior-cjh.tistory.com/167PCA와 TCA
PCA
: feature extraction approach by projecting instances in lower dimensional space
: lower dimensional feature space에서 original data characteristics유지.
: distributions between source (red) and target (blue) are still different in the latent feature space
TCA
: source 와target data가 비슷한 분포를 가지는 lower dimensional feature space
을 찾는다. 마찬가지로 original data characteristics유지.
: distribution between source and target is similar in the new latent feature space
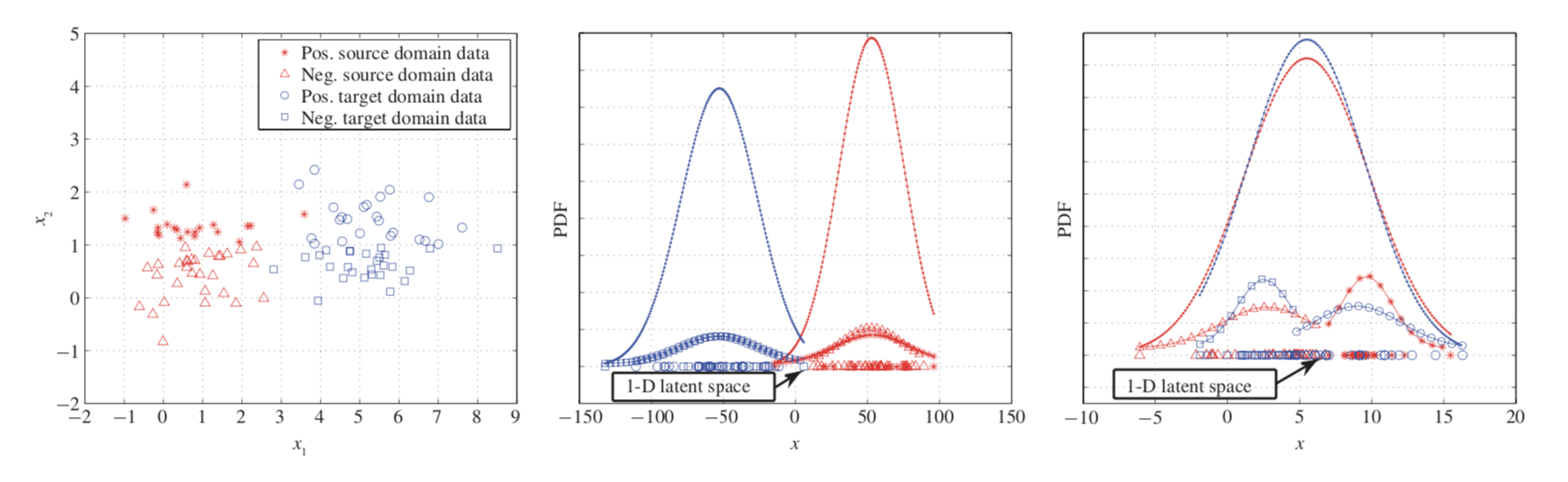
-> TCA를 cross-prediction에 적용하려면 적절한 normalization이 필요하고 이는 예측 성능에도 영향을 끼친다.
TCA+
: TCA에 적절한 normalization options을 정해주는 decision rules이 추가됨.
Normalization : 스케일이 다른 두 변수의 스케일을 동일하게 만들어 주는 기술
Normalization Options (실험에 사용됨)
: min-max
: z-score
: variations of z-score
결과
(f-measure측정값) -> 값이 비슷하게 나옴
within-prediction result (0.46)
cross-prediction result in TCA+ (0.46)
Discussion on cross-predictions based on transfer learning
Main Gole
: 새로운 프로젝트 또는 과거의 데이터가 부족한 프로젝트의 prediction model을 만들어내기 위해서 기존에 존재하던 defect dataset을 재사용하는 것이다.
- 지금까지의 cross project defect prediction은 same feature space을 가지는 dataset을 가지고 수행하였다.
- cross-predictions은 the same feature space을 가지는 dataset 이내에만 가능하다.
따라서 different feature spaces을 가지는 dataset에 대한 연구가 필요하다.
B. Cross-prediction Feasibility
decision tree (by Zimmermann et al)
-
개발자의 수와 언어와 같은 프로젝트의 특징을 사용하여 cross-project predictability(예측가능성)을 validate(검증, 확인)
-
The subjects used in their empirical study이내에서만 구성되고 검증되었기 때문에 general purpose으로 사용할 수는 없다.
-
cross prediction results을 기반으로 만들어짐.
-
source와 target datasets의 distributional characteristics(분포 특성)의 차이점으로 구성된다.
Ex) mean, median, variance, skweness and so on
validation of the decision tree
- best prediction results을 기반으로 수행됨 -> 완전한 validity를 검증한 것은 아니다.
APPLICATIONS ON DEFECT PREDICTION
defect prediction models의 주요 목적
: 소프트웨어 제품을 테스팅 및 검사하는데 있어 효과적으로 자원을 할당하기 위함이다.
-> 실제 defect prediction models을 산업에서는 적게 쓰인다. 이러한 이유로 cost-effectiveness을 고려하게 되었다.
-
Google에서 수행된 최근 연구에는, 개발자들이 BugCache보다 Rahman’s algorithm을 더 선호한다는 결과가 나왔지만 여전히 defect prediction mode을 사용함에 있어 오는 혜택을 얻지 못하였다.
-
Rahman에 수행된 최근 연구에는, defect prediction이 static bug finders(FindBug)에 의해 보고된 prioritize warnings(경고의 우선 순위)를 정하는데 도움이 될 수 있다는 결과를 얻었다.
-> defect prediction을 응용해서 test cases를 선택하거나 우선순위를 부여 가능하다. -
regression testing에서 모든 test들을 실행하는 것은 매우 비싸다.
따라서 test case를 위한 many prioritization and selection approaches 방법들이 제안되었다. -
defect prediction results는 버그가 발생하기 쉬운 software artifacts와 ranks를 제공하기 때문에, test case를 prioritization and selection하는데 사용가능하다.
OTHER EMERGING TOPICS
A. Defect Data Privacy
MORPH
: privacy issue를 해결하기 위해서 defect datasets을 변형하는 것.
-> 원래 코드를 조금 변형시킨다. - 바꿔도 프리딕션 성능을 유지한다.
몸무게 -> 전체 몸무게에 더미값을 더해준다.
더미값 -> 이게 distance-
cross-project defect prediction을 빠르게 발전시키기 위해서는, publicly(공개) available(이용가능한) defect datasets이 필요하다.
-
하지만, sensitive attribute value disclosure(민감한 속성 값 공개)때문에 대부분의 소프트웨어 회사는 defect datasets을 공유하는 것을 꺼려한다.
-
따라서 cross-project defect prediction은 open source software products와 very limited proprietary systems(제한된 독점 시스템)에서 수행가능하다.
Zimmermann가 수행한 cross-project defect prediction실험
:Microsoft defect datasets을 사용하였는데, Microsoft defect datasets은 공개되어 이용 가능한 것이 아니기 때문에 재현할 수 없다.
이를 해결하기 위해서, MORPH는 class decision boundary를 유지함으로써 instances를 random distance로 이동하였다.
random distance -> 더미값이러한 방식으로 MORPH는 original datasets를 privatize하였고, original defect datasets로부터 models trained한 것 처럼 good prediction performance를 성취할 수 있었다.
B. Comparing Defect Prediction Models to Static Bug Finders
DP
: defect prediction models
SBF
: static bug finders
-> 코드 실행없이 버그를 찾는 도구들
SBF는 DP와는 달리 “semantic abstractions of source code”을 사용해서 버그를 감지한다.
EX
- 보안 문제 find bug, pmd(소스코드경로를 인풋으로 넣어주면 몇번째 줄에 에러있다)
- 이클립스 체크스타일 - 이상하게 작성한 코드에 워닝을 준다.
cost-effectiveness관점에서 SBF와 DP비교
- 서로가 서로 다른 결함을 발견할 수 있음 -> compensate(보상)관계에 있음을 발견
- DP에 의해 우선순위가 부과된 SBF warnings은 SBF’s native priorities보다 더 높은 성능을 보여줌.
->동일한 목표를 가진 여러 연구 흐름이 수렴되는 방법과 결함이 더 잘 예측/검출하는 방법에 대한 통찰력 제공한다.
CHALLENGING ISSUES
: Defect prediction을 실제로 적용하기에는 많은 문제점이 있다.
-
대부분의 연구가 open source software project에서 검증되었기 때문에, 현재의 prediction models이 commercial software에서 작동이 되지 않는다.
비록, MORPH algorithm으로 data privacy가 증가했지만, MORPH는 cross-project defect prediction에서는 유효하지 않다.
만약 우리가 소유권이 있는 datasets을 가지기를 원한다면, cross-project defect prediction에서의 privacy issue를 조사할 필요가 있다.
-
Cross prediction은 2가지의 측면에서 여전히 어려운 문제가 남아있다.
A. Different feature space
: 이용 가능한 publicly defect datasets이 존재하지만, 다른 domains에서의 dataset은 metrics와 feautres의 수가 다르기 때문에 cross prediction에 적용할 수가 없다.
머신러닝에 기반한 prediction models은 서로 다른 features spaces를 가지는 datasets으로부터 build가 될 수 없다.
spaces를 가지는 datasets으로부터 build가 될 수 없다.B. Feasibility
: cross prediction feasibility에 대한 연구는 아직 완성되지 않았다. Feasibility을 확인하는 일반적인 접근법을 찾는 것은 cross prediction models의 사용을 활성화시키는데 매우 큰 도움이 된다. -
소프트웨어 프로젝트는 계속 점점 커지고 있기 때문에 file-level에서의 defect prediction은 cost-effectiveness측면에서 충분하지 않을 수 있다.
또한 더 정밀한 예측 입도(finer prediction granularity)에 대한 연구가 거의 없다.
따라서 line-level이나 또는 change classification과 같은 finer prediction granularity에 대한 연구가 필요하다.
-
Defect prediction metrics and models은 항상 좋은 prediction performance를 보장해오지 않았다.
소프트웨어 리파지토리가 발전됨에 따라, 우리는 defect prediction metrics/models에 사용되지 않은 새로운 유형의 개발 프로세스 information을 추출할 수 있다.
New metrics and models에 대한 연구는 계속 필요하다.
논문 출처
