Software Testing & Fuzzing Camp Lab1
Replace
replace.c는 단순히 텍스트 변환기 프로그램이다.
lab1-replace폴더는 다음과 같이 bin src test 3개의 폴더로 구성되어 있다.

src 폴더는 replace.c파일로 구성되어있다.
bin 폴더는 다음과 같이 make파일과 txt파일로 구성되어있다.
hello.txt파일은 다음과 같이 구성되어있다.

"make"명령어로 컴파일을 해보겠다.
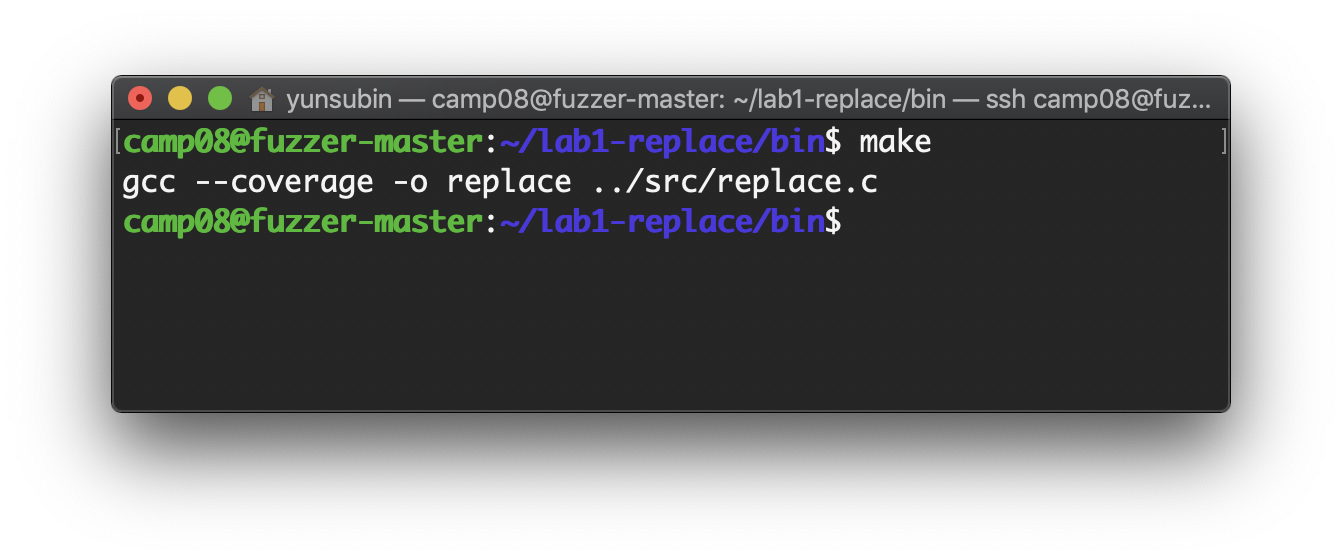
make다음과 같이 src폴더에 있는 replace.c가 컴파일되었다.
그리고 replace.gcno파일이 생성됨을 확인할 수 있다.

그럼 실행파일을 실행시켜보자.
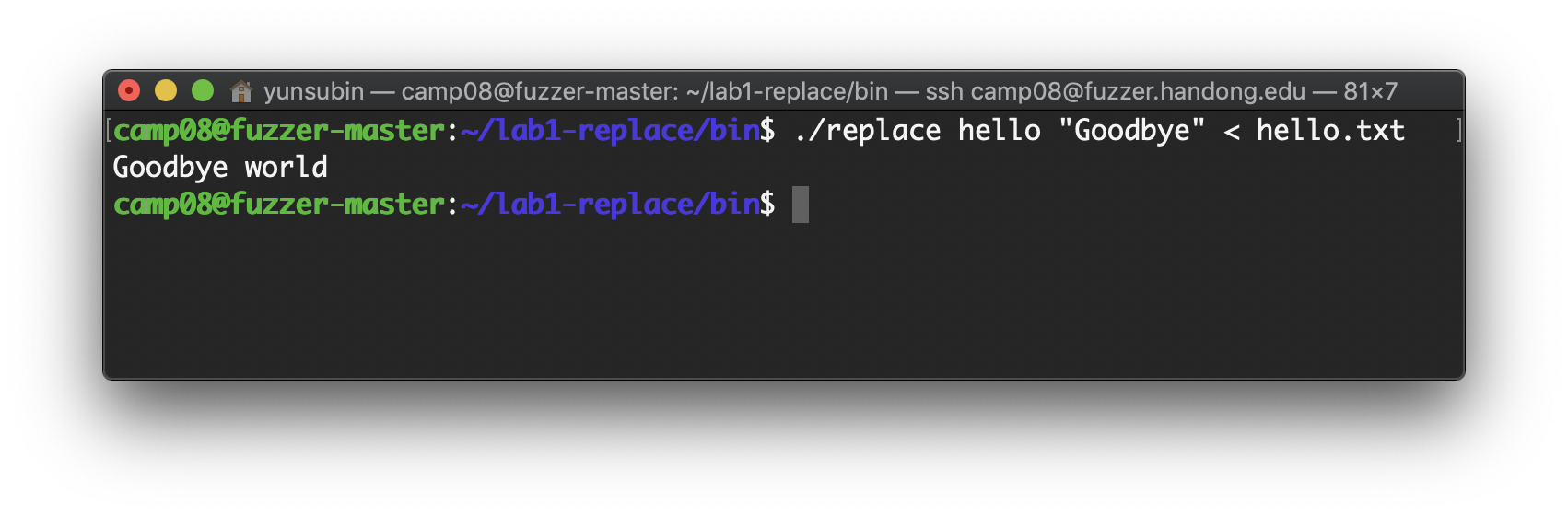
./replace hello "Goodbye" < hello.txthello.txt안에 있는 hello라는 단어를 Goodbye로 바꾼다는 뜻이다.
coverage를 확인해보자. input "hello "Goodbye" < hello.txt"는 line coverage 47.24%를 cover했음을 볼 수 있다.
gcov replace.gcda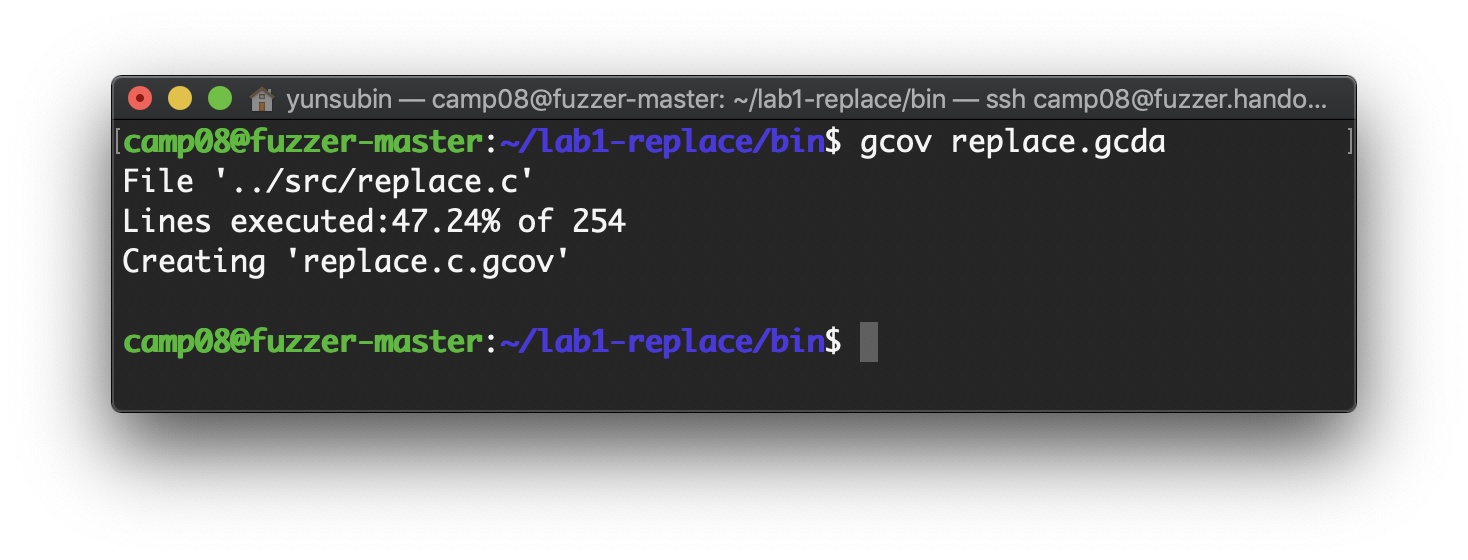
ls 명령어를 통해서 "replace.c.gcov"파일이 생성되었다.
이제, test폴더에 들어가서 어떤 것들이 있는지 보자.
다음에 보이는 .sh파일들은 test case들이 들어 있는 파일이다.
예를 들어, "t198.sh"를 열어서 살펴보자
vi t198.shreplace실행파일을 실행시키고 있음을 볼 수 있다.
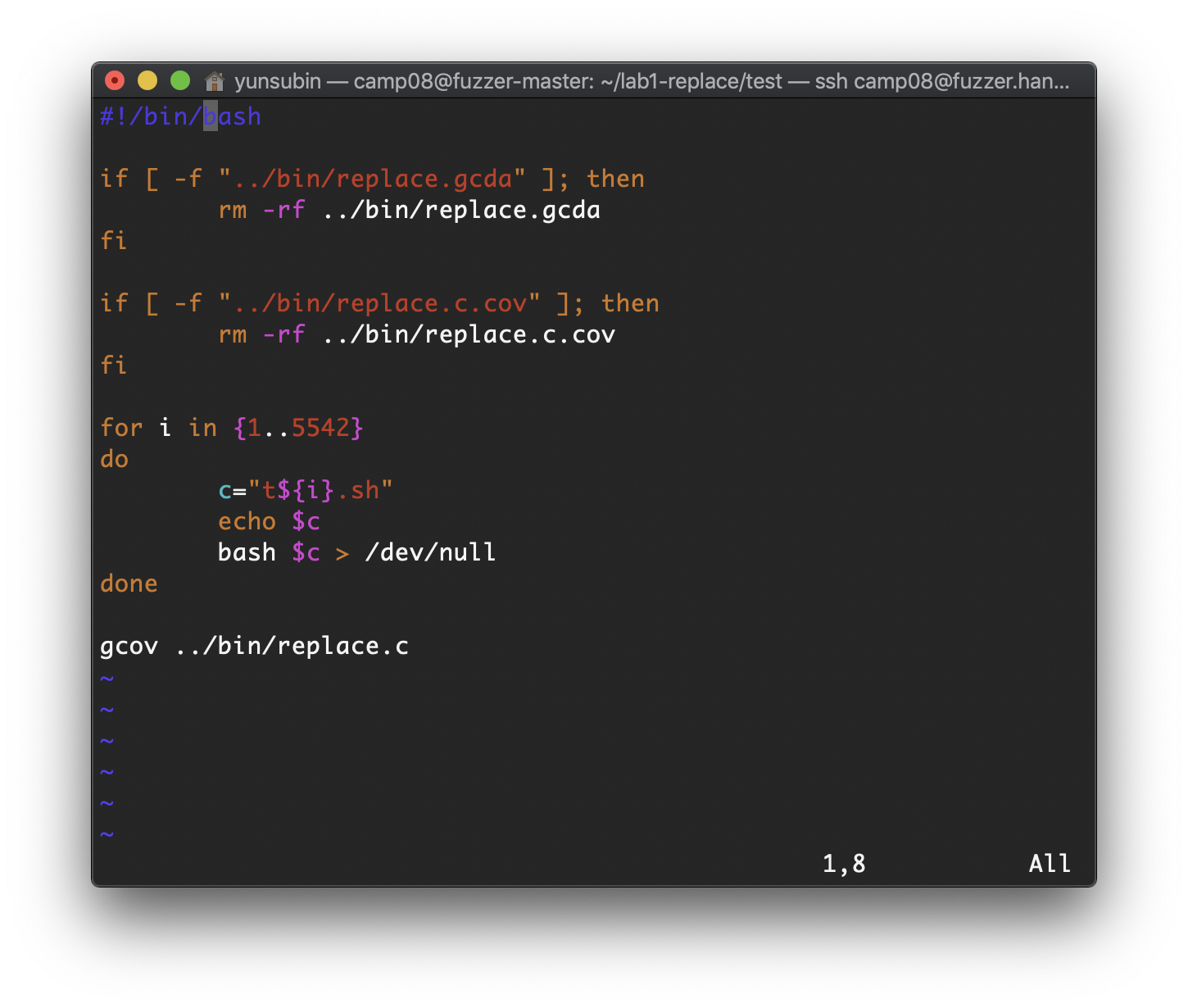
"test_all.sh"를 열어서 살펴보자
vi test_all.sh다음은 t1.sh ~ t5542.sh 테스트 케이스를 모두 실행하는 bash파일이다.
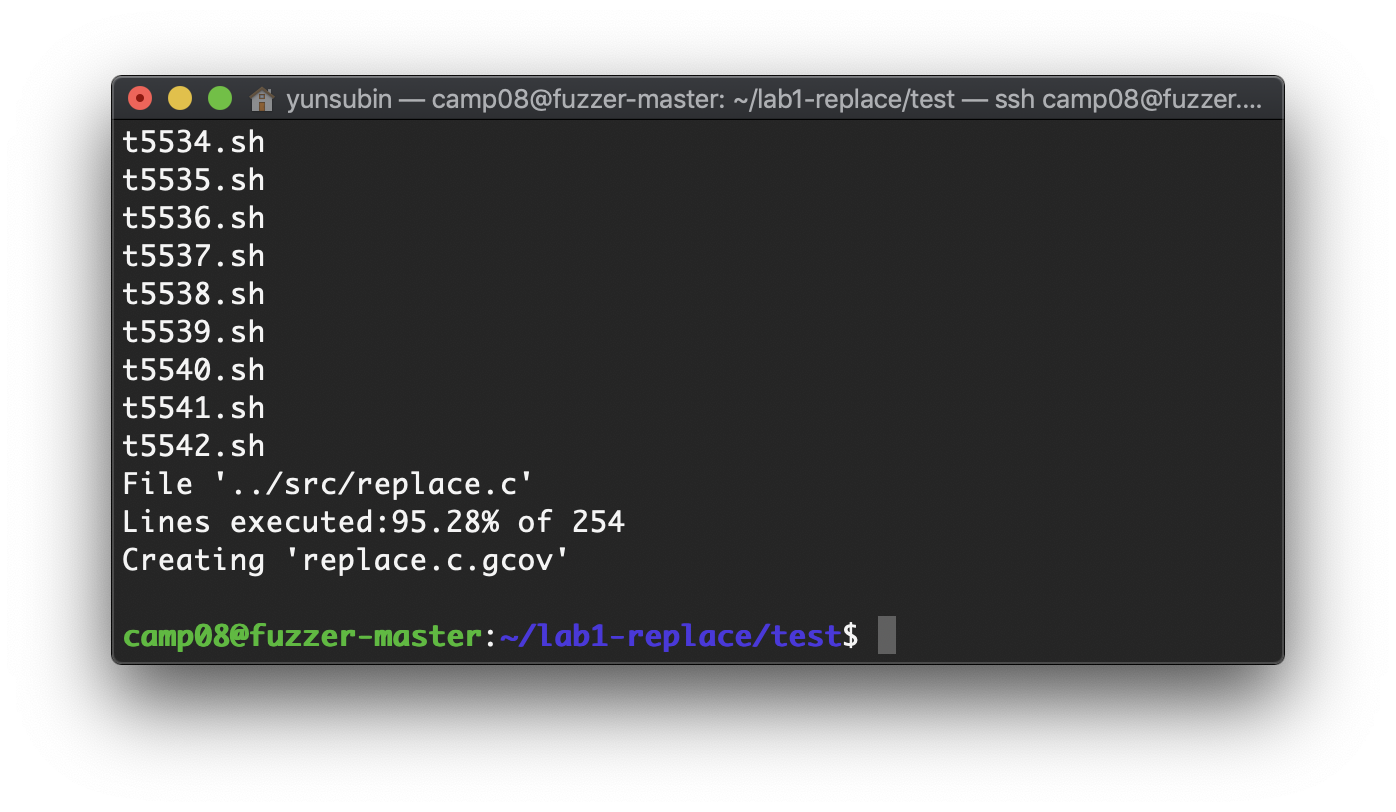
이것을 실행시켜 coverage를 살펴보자
./test_all.sh모든 test case를 실행시키니 line coverage가 95.28%정도 cover되었다.
다음으로는 "test_each.sh"를 열어서 살펴보자
vi test_each.sh다음은 각 test case에 대해서 cover된 line들의 정보만 뽑아내어 따로 coverage라는 디렉토리에 저장한다는 bash파일이다.
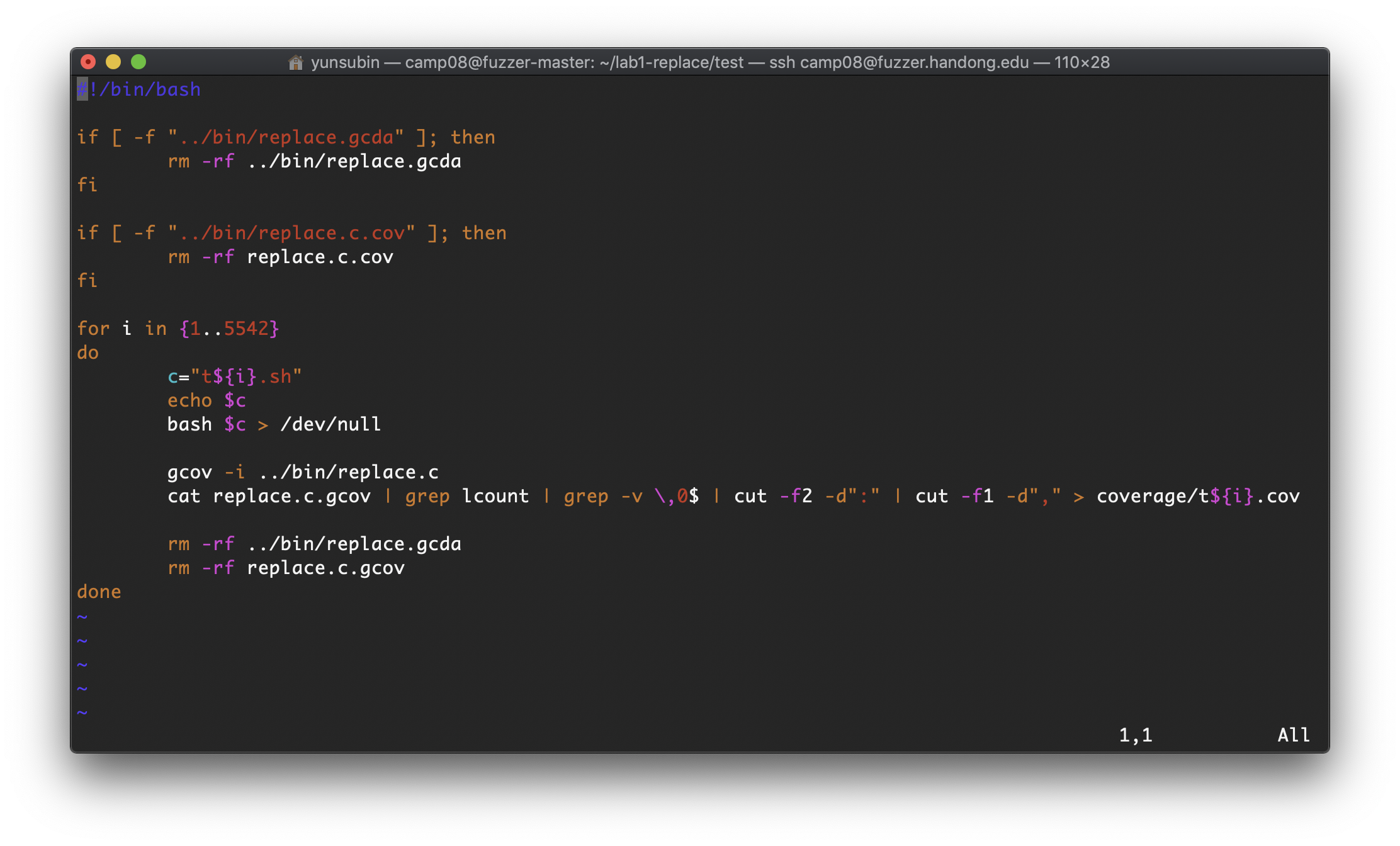
위에서 중점적으로 봐야 할 것은 아래 명령어이다.
cat replace.c.gcov | grep lcount | grep -v \,0$ | cut -f2 -d":" | cut -f1 -d"," > coverage/t${i}.cov해석해보자면, replace.c.gcov의 파일을 읽어들여, "lcount"에 해당하는 부분만 뽑아내고, ":"기준으로 잘라 뒤에 필드만 남겨높고 cut off한다. 그리고 남은 필드에서 도 ","를 기준으로 잘라 이번에는 앞의 필드만 남기고 cut off한다. 이렇게 하면, cover된 라인의 넘버만 .cov파일에 저장된다.
이제 실행시켜보자.
./test_each.sh실행되고 있음을 볼 수 있다.
coverage 폴더에 들어가 ls 명령어로 확인해보니, cov파일이 생성되었음을 볼 수 있다.
t9.cov파일을 열어 확인해보자
안의 내용은 t9.sh에 대해서 cover된 라인넘버에 대한 정보를 담고 있다.
vi t9.cov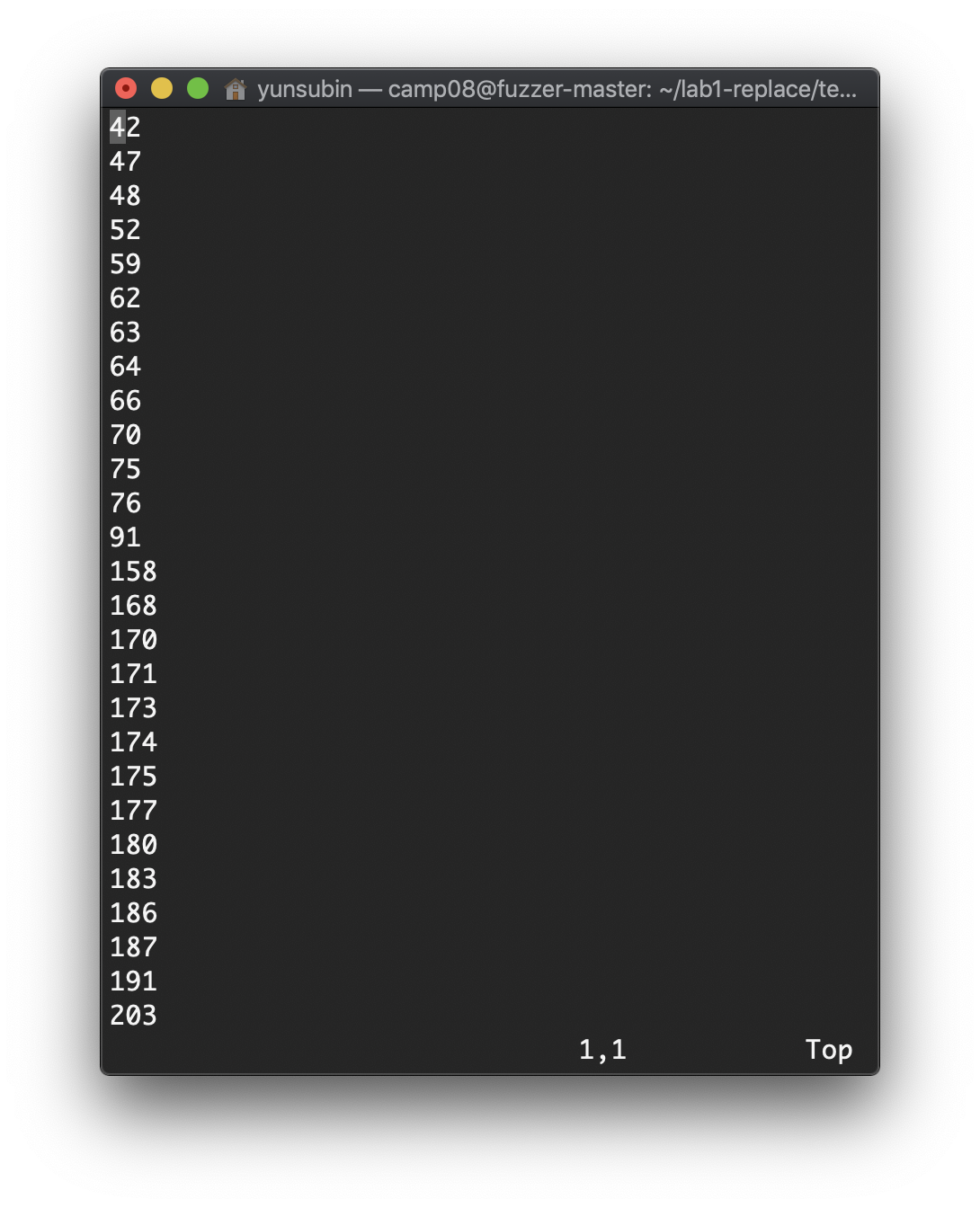
아까 모든 test case를 실행시켰을 때, coverage는 약 95%로 매우 높게 나왔다.
하지만 실제로 sw testing할 때 모든 test case를 실행시키기에는 시간이 많이 걸리므로 실제로 coverage가 높은 test case들을 뽑아 실행하는 경우가 많다.
따라서 coverage가 높게 나오는 test case들을 추출하는 과정이 필요하다.
greedy알고리즘을 사용하거나, 또는 각각의 test case의 coverage를 sorting하여 높은 순서대로 test case를 추출한다던지 등 다양한 방법을 생각해 낼 수 있다.
