Diffusion Transformer(DiT)는 Diffusion model에 transformer 구조를 넣어 class-conditional ImageNet 512x512 and 256x256 benchmarks에서 기존의 diffusion model 보다 더 좋은 성능을 거두었음.
- Diffusion Transformer Design Space
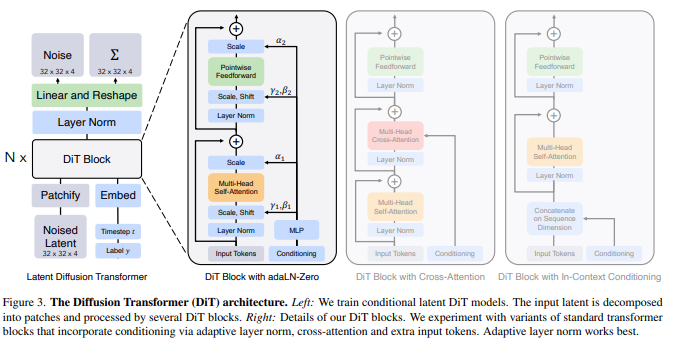
The focus is training DDPMs of images (specifically, spatial representations of images), DiT is based on the Vision Transformer(ViT) architecture which operates on sequences of patches.
위 그림은 DiT architecture의 개요이다.
1) Patchify.
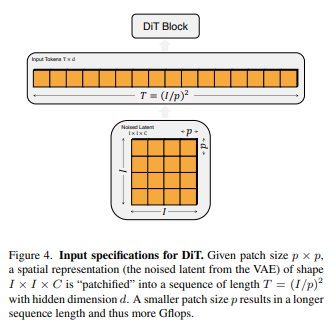
DiT의 input으로 spatial representation z(for 256x256x3 images, z has shape 32x32x4)가 주어진다. DiT의 첫번째 layer는 "patchify"로, 위의 spatial input z를 T개의 연속 토큰(with dimension d)으로 변화시킨다. 토큰 T의 개수는 hyperparameter 인 p에 영향 받게 되는데, Noised latent size IxIxC를 patch size로 나눈 조각들을 이어 붙이기 때문이다. 즉 p의 사이즈가 작아질 수록 토큰 T의 개수는 증가하게 되고, 이는 more Gflops를 유발한다. patchify 후에는 모든 입력 토큰에 standard ViT frequency-based positional embeddings를 적용한다.
2) DiT block design.
Patchify를 지나 input tokens는 연속적인 transformer block에 의해 처리되는데, noised image inputs과는 별개로, diffusion models은 간혹 추가적인 조건 정보를 입력하게 되는데, 이는 noise timestep t, class labels c, natural language 등이 그것이다. 바로 이 conditional input을 다르게 처리함으로써 4가지 변형된 transformer block에 대한 검토를 진행하였다.
- In context conditioning.
단순하게 vector embeddings of t and c를 input sequence의 토큰으로 2개 추가한 버전
이는 cls tokens in VITs로, standard ViT block을 수정없이 사용할 수 있게 해준다. 최종 block을 지나면 conditioning tokens를 sequence에서 제거한다. model에 무시할만한 Gflops 추가를 유발한다. - Cross-attention block.
embeddings of t and c를 길이 2 sequence로 image input token과 따로 분리한다. transformer block을 multi-head cross-attention layer를 multi-head self-attention block 다음에 올 수 있도록 배치했다. conditioning embedding은 multi-head cross-attention에 따로 공급된다. 약 15% 정도의 Gflops overhead를 유발한다. - Adaptive layer norm (adaLN) block.
GANs and diffusion models with U-Net backbones에서 자주 사용되는 adaptive normalization layer를 적용하기 위해 transformer block의 standard layer norm layers를 대체하여 적용하였다. 직접적으로 dimension-wise scale and shift parameter인 γ와 β를 배우는 대신 embedding vector인 t와 c에서 도출할 수 있도록 했다.
adaLN은 가장 작은 Gflops를 추가하여 가장 계산 효율적인 모델이다. - adaLN-Zero block.
ResNets에서 residual block을 identity function으로 사용한 것은 효과적이었다. Diffusion U-Net model에서도 비슷한 초기화 전략을 구사하는데, 마지막 convolutional layer를 residual connection이전에 zero-initializing하는 것이다. adaLN-Zero로 비슷한 전략을 구사한다. γ와 β를 회귀값 도출하는 것과 더불어 dimension-wise scaling parameter인 α를 도입하고, 이는 DiT block내에서 residual connection 바로 이전에 적용된다. 모든 α에 대해서 zero백터를 도출하기 위해 MLP를 초기화하였고, 이것은 full DiT block을 identity function으로 초기화 한다.
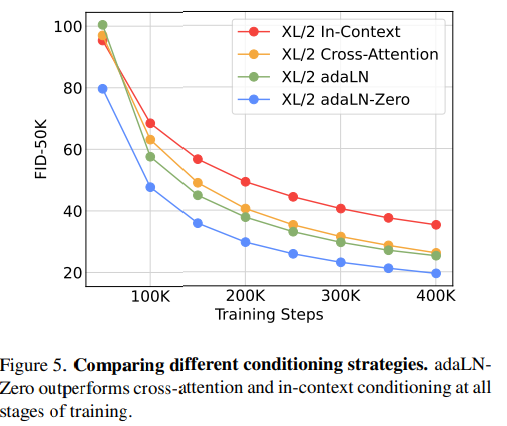
3) Model size.
N DiT block을 연결하여 적용(widh hidden dimension size d)하고 표준 transformer 구성을 사용한다. 모델은 DiT design space에 따라 DiT-S, DiT-B, DiT-L, DiT-XL로 구분하여 탐색한다.

4) Transformer decoder.
마지막 DiT block을 지나고 sequence of image tokens를 output noise prediction과 output diagonal covariance prediction으로 decode한다. 결과물의 dimension은 original spatial input과 같고, final layer norm을 거쳐 pxpx2C(number of channels in the spatial input to DiT)로 decode하고, 마지막으로 다시 orifinal spatial layout으로 재구성 한다.
The complete DiT design space we explore is patch size, transformer block architecture and model size.

In to the code!