요약
- 대형 페이지(Huge Page) 기능을 활용하여 TLB miss로 인한 오버헤드를 최소화할 수 있습니다.
- 워킹셋의 데이터가 크고 (수십 MB~), 메모리 접근이 매우 빈번한 워크로드에 유용한 최적화입니다.
- CPU 및 I/O 바운드가 지배적인 워크로드에서는 별다른 효용이 없을 수 있습니다.
배경
- 모든 프로세스는 가상 메모리 주소 공간을 할당 받습니다.
- 프로세스에서 가상 메모리 주소에 접근하면 CPU는 이를 실제 물리 메모리 주소로 치환하여 처리합니다.
- OS는 가상 메모리 주소를 물리 메모리 주소로 매핑하기 위한 Page Table을 관리합니다.
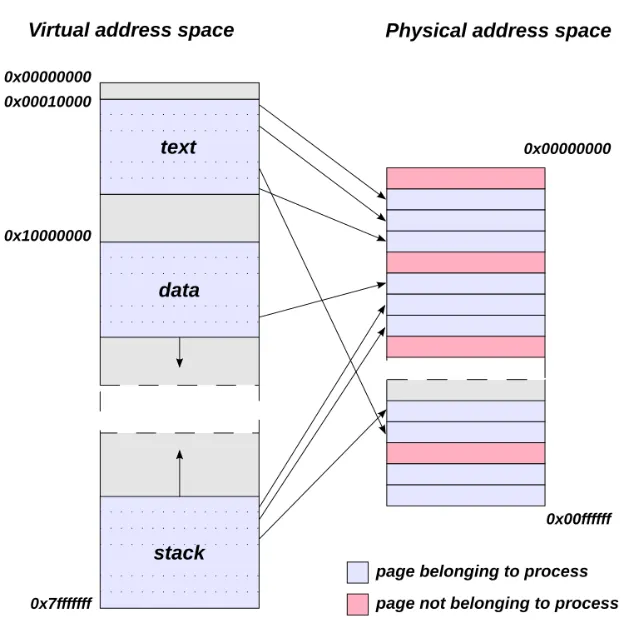
- 프로세스가 메모리에 접근할 때 마다, 가상 메모리 주소 → 물리 메모리 주소 변환이 매번 발생합니다.
- CPU는 이를 최적화 하기 위해 최근 변환된 메모리 주소를 캐싱합니다 → Translation Lookaside Buffer (TLB)

- 문제는 TLB의 크기가 일반적으로 매우 작습니다. (~ 4KB)
- 따라서, 워킹 셋의 크기가 큰 경우에는 TLB 미스가 빈번하게 발생합니다.
- TLB의 크기는 제한적이므로, 대신 페이지 의 크기를 크게 만들어서 TLB hit를 높이는 방법이 고안되었습니다.
Huge Pages
- 리눅스에서는 페이지 크기를 늘릴 수 있는 두 가지 옵션을 제공합니다.
- hugetlbfs
- 리눅스에서 대형 페이지(Huge Page)를 활용하기 위해 제공되는 특별한 파일시스템입니다.
- 커널이 제공하는 가상 파일시스템으로,
/dev/hugepages와 같은 경로를 마운트할 수 있습니다. - 프로세스가 이 파일시스템에 파일을 만들고
mmap()을 하면, 그 매핑은 대형 페이지 단위로 할당됩니다. - 즉, 일반적인
malloc이 아니라hugetlbfs로 마운트한 경로를 통해 대형 페이지 메모리를 사용합니다.
- 커널이 제공하는 가상 파일시스템으로,
- 특징
- 시스템 메모리 중, hugetlbfs에서 사용할 대형 페이지 개수를 미리 설정해야 합니다.
- 예약된 대형 페이지는 다른 용도로 사용되지 않습니다.
- 어플리케이션에서 이를 사용하지 않으면 그냥 낭비됩니다.
- 어플리케이션 코드에서 메모리를 사용하는 방식의 전환이 필요합니다.
- 명시적으로 메모리를 할당하는 C와 같은 프로그램은 코드 수정이 요구됩니다.
- JVM과 같은 런타임에서는 옵션(
-XX:+UseHugeTLBFS)을 사용하면 적용할 수 있습니다.
- 시스템 메모리 중, hugetlbfs에서 사용할 대형 페이지 개수를 미리 설정해야 합니다.
- 활용 레퍼런스
- 리눅스에서 대형 페이지(Huge Page)를 활용하기 위해 제공되는 특별한 파일시스템입니다.
- Transparent Huge Pages (THP)
- 리눅스 커널에서 일반 페이지를 대형 페이지로 자동 승격/강등 해주는 기능입니다.
- 어플리케이션에서 기존과 동일하게 메모리를 할당하면 커널이 자동으로 일반 페이지를 대형 페이지로 승격(promotion)시키거나 대형 페이지를 일반 페이지로 강등(demotion) 합니다.
- 커널이 주기적으로 defrag를 수행하여 페이지를 압축합니다.
- 특징
- hugetlbfs와 달리 메모리 공간 예약이 필요하지 않습니다.
- 어플리케이션 코드의 수정이 불필요합니다.
- defrag의 영향으로 지연 시간 스파이크가 발생할 수 있습니다.
- 활용 레퍼런스
- linux RedHat 배포판에서는 기본값으로 THP 기능이 활성화되어 있습니다.
- MS SQL Server에서는 THP 기능을 사용하는 것을 권장합니다.
- 반대로 사용을 경고하는 사례도 일부 존재합니다.
- 리눅스 커널에서 일반 페이지를 대형 페이지로 자동 승격/강등 해주는 기능입니다.
- hugetlbfs
검증
- 아래는 벤치마크 테스트에 활용된 코드 예시입니다.
- 임의의 크기의
byte[]를 생성하고 랜덤한 인덱스에 접근합니다. - 바이트 배열의 크기가 커질수록 많은 page가 할당되며 TLB miss가 발생할 가능성이 높아집니다.
- 임의의 크기의
public class ByteArrayTouch {
@Param(...)
int size;
byte[] mem;
@Setup
public void setup() {
mem = new byte[size];
}
@Benchmark
public byte test() {
return mem[ThreadLocalRandom.current().nextInt(size)];
}
}- 벤치마크 테스트 결과, 바이트 배열의 크기가 큰 구간에서 최대 15% 수준의 성능 개선이 이뤄졌습니다.
Benchmark (size) Mode Cnt Score Error Units
# Baseline
ByteArrayTouch.test 1000 avgt 15 8.109 ± 0.018 ns/op
ByteArrayTouch.test 10000 avgt 15 8.086 ± 0.045 ns/op
ByteArrayTouch.test 1000000 avgt 15 9.831 ± 0.139 ns/op
ByteArrayTouch.test 10000000 avgt 15 19.734 ± 0.379 ns/op
ByteArrayTouch.test 100000000 avgt 15 32.538 ± 0.662 ns/op
# -XX:+UseTransparentHugePages
ByteArrayTouch.test 1000 avgt 15 8.104 ± 0.012 ns/op
ByteArrayTouch.test 10000 avgt 15 8.060 ± 0.005 ns/op
ByteArrayTouch.test 1000000 avgt 15 9.193 ± 0.086 ns/op // !
ByteArrayTouch.test 10000000 avgt 15 17.282 ± 0.405 ns/op // !!
ByteArrayTouch.test 100000000 avgt 15 28.698 ± 0.120 ns/op // !!!
# -XX:+UseHugeTLBFS
ByteArrayTouch.test 1000 avgt 15 8.104 ± 0.015 ns/op
ByteArrayTouch.test 10000 avgt 15 8.062 ± 0.011 ns/op
ByteArrayTouch.test 1000000 avgt 15 9.303 ± 0.133 ns/op // !
ByteArrayTouch.test 10000000 avgt 15 17.357 ± 0.217 ns/op // !!
ByteArrayTouch.test 100000000 avgt 15 28.697 ± 0.291 ns/op // !!!- CPU 카운터를 분석해본 결과
- 일반 페이지를 사용한 경우 100%에 가까운 TLB miss가 발생하였습니다.
- 반면, THP를 사용한 경우 TLB 미스가 거의 발생하지 않았습니다.
Benchmark (size) Mode Cnt Score Error Units
# Baseline
ByteArrayTouch.test 100000000 avgt 15 33.575 ± 2.161 ns/op
ByteArrayTouch.test:cycles 100000000 avgt 3 123.207 ± 73.725 #/op
ByteArrayTouch.test:dTLB-load-misses 100000000 avgt 3 1.017 ± 0.244 #/op // !!!
ByteArrayTouch.test:dTLB-loads 100000000 avgt 3 17.388 ± 1.195 #/op
# -XX:+UseTransparentHugePages
ByteArrayTouch.test 100000000 avgt 15 28.730 ± 0.124 ns/op
ByteArrayTouch.test:cycles 100000000 avgt 3 105.249 ± 6.232 #/op
ByteArrayTouch.test:dTLB-load-misses 100000000 avgt 3 ≈ 10⁻³ #/op // !!!
ByteArrayTouch.test:dTLB-loads 100000000 avgt 3 17.488 ± 1.278 #/op레퍼런스

안녕하세요