JDBC가 메이븐에서 어떻게 관리되고 있는지
https://mvnrepository.com/
위 주소에서 필요한 라이브러리가 있으면 찾아서 추가해준다. 어디에?

Dependency에 대해 찾아서 pom파일에 넣어주면된다
Driver SPY 에 대하여

▲드라이브 스파이에서 가져온 log4.jdbc의 로그를 찍는 방법 설정 log4j2.xml 을 보시오!
▼스파이를 통해 테이블을 결과에 추가해줌
@Log4j2
public class JDBCExampleWithDriverSpy2 {
// log4jdbc 이 부분 추가해주면 드라이버 스파이가 작동한다.
private static String jdbcUrl = "jdbc:log4jdbc:oracle:thin:@db20220510181319_high?TNS_ADMIN=C:/opt/OracleCloudWallet/ATP";
private static String user = "HR";
private static String pass = "Oracle12345678";
// Driver SPY (별칭) => log4jdbc (정식명칭) : 라이브러리
public static void main( String[] args ) {
try {
@Cleanup Connection conn = DriverManager.getConnection(jdbcUrl, user, pass);
// 1. 문제에 맞는 쿼리 설정
String sql= "SELECT current_date,sysdate FROM dual ";
PreparedStatement pstmt = conn.prepareStatement(sql);
// 2. Bind Variable에 값 설정 (Binding)
//jdbc에서 Date()는 시간, 분, 초 정보는 가지고 있지 않다.
@Cleanup ResultSet rs =pstmt.executeQuery();
while(rs.next()) {
Timestamp CURRENT_DATE = rs.getTimestamp("CURRENT_DATE");
Timestamp SYSDATE = rs.getTimestamp("SYSDATE");
String DATE = String.format("%s,%s",CURRENT_DATE,SYSDATE);
log.info("Employee: {}" , DATE);
}
} catch(SQLException e ) {
e.printStackTrace();
} // try- catch
}//main
이런식으로
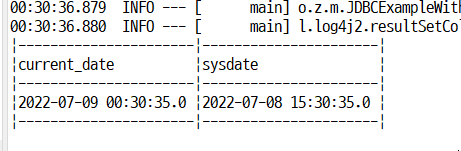
이건 어제 마지막 예제
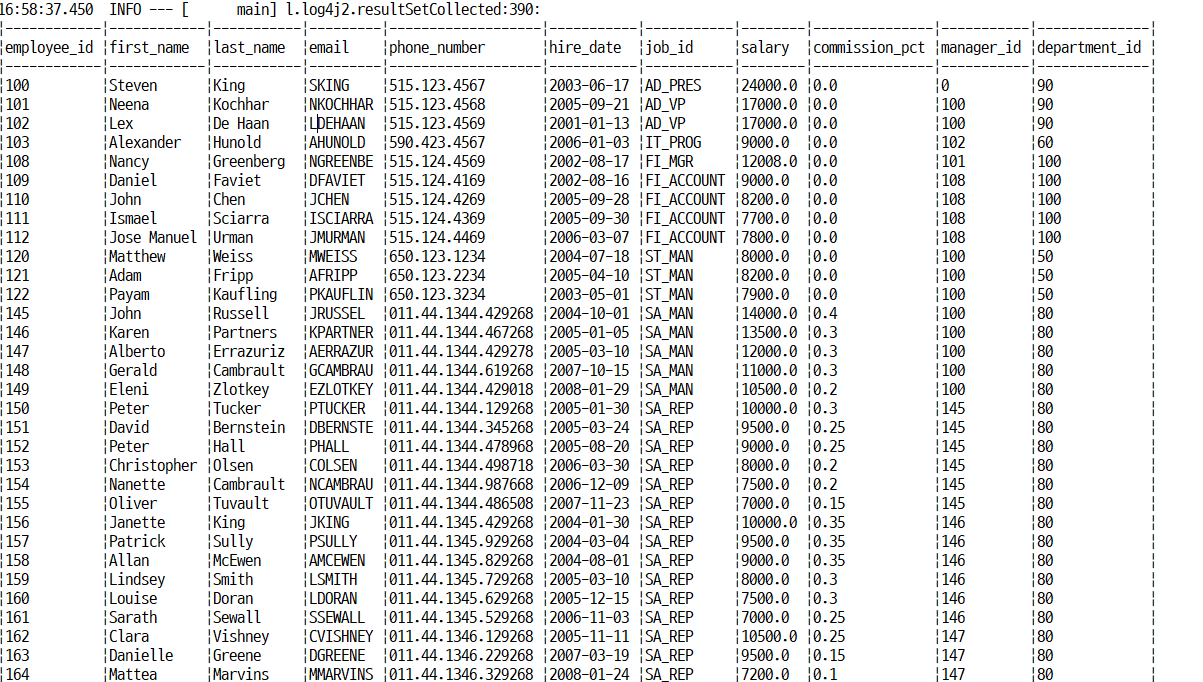
스파이 사용시 이렇게 테이블 형태로 보여줌

중요한 것은 이렇게 어떤 쿼리의 실제 바인딩된 값을 알려준다.
- 왜 중요하냐면 자바와 DB간 데이터 타입이 다른 경우로 개발자가 잘못 바인딩해서 데이터를 잘못 뽑아내는 경우가 있다. 그것을 알아볼 수 있기 때문에 즁요!
JUnit에 대하여 (TDD - 테스트 주도개발)




먼저 JDBC처럼 메이븐에 dependency로 정의 되어있어야 한다
버전4부터 봐보면
▼ 5버젼과 import부분부터 다름 어노테이션 종류도 다름
package org.zerock.myapp;
import static org.junit.Assert.assertNotNull;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import lombok.NoArgsConstructor;
import lombok.extern.log4j.Log4j2;
@Log4j2
// Rule1: JUnit 용 테스트 클래스는 반드시 기본생성자를 가져야합니다!
// 즉, 매개변수있는 생성자를 선언하시면, 실행 즉시 오류발생!
@NoArgsConstructor
public class JUnit4_Template {
@Before
public void setup(){ // 각메소드의 이름은 이미 관례화 되어있다.
log.trace("setup() invoked.");
} // setup
// 1.JUnit4 기반에서는, 테스트 메소드 이름의 시작은 반드시 'testXXX'로 해야합니다.
// 2.JUnit4 기반에서는 , 모든 사전/사후/테스트 메소드의 접근제한자를 public 으로 해야함
// 3. 사전 (@Before) / 사후 (@After) 메소드는 무조건 강제로 구현하는 것이 아니라, 필요할 때만 작성
// 필요없으면 작성안해도된다.
@Test
public void testXXX1(){
log.trace("testXXX()1 invoked.");
}// textXXX1
@SuppressWarnings("unused")
@Test
public void testXXX2(){
log.trace("testXXX()2 invoked.");
// (*주의*) 테스트의 목적대로, 테스트 코드의 수행결과가 사전에 기대했던 값 (Expected Values)와
// 일치하는지 여부를 검증하는 코드가 메소드 블록 마지막에 주로 나옵니다.
// 예:
String result = null;
assertNotNull(result); // Assertion methods -> 기대값이 아니면, AssertionError를 throw함
log.info("\t + OK");
}// textXXX2
@Test(timeout=1000)
public void testXXX3() throws InterruptedException{
log.trace("testXXX()3 invoked.");
Thread.sleep(1500);
}// textXXX3
@After
public void tearDown() { // 각메소드의 이름은 이미 관례화 되어있다.
log.trace("tearDown() invoked.");
// 주로, 테스트 메소드 수행에 사용한 각종 자원객체를 해제하거나
// 환경설정을 취소함
}// tearDown
} // end class
버전5 봐보면
▼JUnit 명칭부터 달라졌다. 순서를 만들기도 하고 Before/After 를 더 큰 단위로 묶을 수 있음
package org.zerock.myapp;
import java.util.concurrent.TimeUnit;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.ClassOrderer.OrderAnnotation;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Order;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestClassOrder;
import org.junit.jupiter.api.TestInstance;
import org.junit.jupiter.api.TestInstance.Lifecycle;
import org.junit.jupiter.api.Timeout;
import lombok.NoArgsConstructor;
import lombok.extern.log4j.Log4j2;
//=======================================//
// 1. JUnit5 -> "JUnit Jupyter"로 이름이 바뀜
// 2. 사용가능한 어노테이션이 많이 증가
// 3. 테스트 클래스로부터. 테스트 객체를 생성하는 방법이 2가지로 바뀜:
// (1)PER_CLASS (테스트 객체 1개만 생성) (2) PER_METHOD (테스트 메소드 수행시마다, 객체 생성)
// 4. 테스트 메소드의 수행 순서를 결정할 수 있게 된다(@TESTMethodOrder) -> 받은 JUnit안내파일에 적혀있음
// 5.
//=======================================//
@Log4j2
@NoArgsConstructor
@TestInstance(Lifecycle.PER_CLASS) //테스트 객체 1개만생성
//@TestInstance(Lifecycle.PER_METHOD) // 테스트 메서드를 실행시킬때마다 객체를 생성하겠다.
// 테스트 클래스 안에 , 여러개의 테스트 메소드가 있을 때,
// 테스트 클래스의 전체 테스트 메소드 수행시, 각 메소드의 수행순서를 @Order 어노테이션을
// 통해 실행 순서를 지정할 때 사용합니다.
@TestClassOrder(OrderAnnotation.class)
public class JUnit5_Template {
// 사전처리 메소드(@BeforeAll, @BeforeEach)는 선택이다.
@BeforeAll
void beforeAll() {
log.trace("beforeAll() invoked.");
}// beforeAll
@BeforeEach
void beforeEach() {
log.trace("beforeEach() invoked.");
} // beforeEach;;
@Test
@Order(2)
@DisplayName("덧셈 메소드 수행 테스트")
@Timeout(value=1, unit= TimeUnit.SECONDS)
void contextLoad1() {
log.trace("contextLoad1() invoked.");
} // contextLoad1
@Test
@Order(1)
@DisplayName("곱셈 메소드 수행 테스트")
@Timeout(value=1, unit= TimeUnit.SECONDS)
void contextLoad2() {
log.trace("contextLoad2() invoked.");
} // contextLoad1
// 사후처리 메소드(@AfterEach, @AfterAll)는 선택이다.
@AfterEach
void afterEach() {
log.trace("afterEach() invoked.");
}// afterEach
@AfterAll
void afterAll() {
log.trace("afterAll() invoked.");
}// afterALl
}// testContextLoads
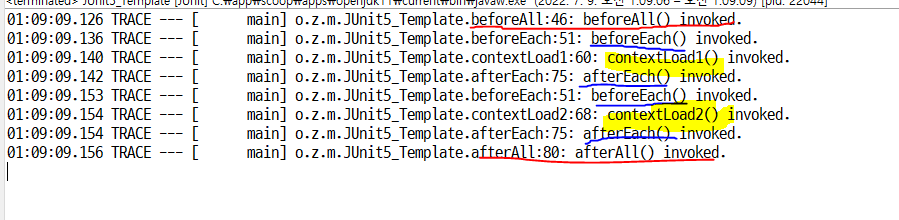
테스트 수행 전/후로 어떤 것들이 먼저 수행되고 전체적인 수행과정이 어떤지를 봐야함

이런 식으로 어떤 메소드를 시행했는지 에러처리를 했는지 확인가능
충분한 테스트 이 후에 적용되는 프로그램 설계를 할 수 있습니다.
점점 졸리다보니까 의식의 흐름대로 작성했다.. 여기까지..

일단 흐자