
Kafka
- 분산 이벤트 스트리밍 플랫폼
- 대규모 데이터를 실시간으로 처리하기 위해 사용
- 고성능, 확장성, 내구성 가용성
Producer: 데이터 생산자
Comsumer: 데이터 소비자
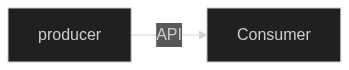
통신 방법
API
직접 통신, 단순하고 간단한 방법이다. 하지만 Concumer에 장애가 발생한다면 직접 호출하기 때문에 장애가 전파될 수도 있고, 전달되지 않는다면, 데이터 유실 가능성이 있다.
대규모 데이터를 안전하게, 고성능으로 처리하는데 한계가 있다.
Message Queue
Producer와 Consumer 사이에 Message Queue에 데이터 전송을 위힘해볼 수 있다. 직접적으로 결합되지 않기 때문에 장애 전파될 위험은 감소될 수도 있고, 데이터 유실 위험을 낮출 수도 있고, 데이터에 대한 처리가 비동기로 수행될 수도 있다.

Producer와 Consumer가 많아진다면?
처리해야될 데이터가 늘어난다면?
Message Queue 장애가 발생한다면?
데이터에 대해 복잡한 라우팅이 필요하다면?
단일 Message Queue로 대규모 데이터를 처리하기 어려울 수 있다.

여러 Message Queue를 만들고, 이를 처리하는 시스템을 고려할 수 있다.
Message Queue(메시지 중개자)가 여러 Message Queue를 관리함으로써 대규모 데이터를 병렬로 처리하며, 복잡한 데이터 요구사항을 처리한다.
만약 Producer가 생산하는 데이터가 Broker나 Consumer의 처리향을 넘어가면, 리소스 부족으로 장애가 전파될 수도 있고, 데이터 유실될 수 있다.

Consumer가 Message Broker에서 데이터를 push받는게 아니라, Consumer가 Message Broker에서 데이터를 pull 해온다. 자신의 처리향에 따라서 조절할 수 있다.
Producer가 데이터 생산(publish), Consumer는 데이터 구독(subscribe)
pub/sub 패턴
그렇다면 이러한 시스템을 직접 구축해야되나? 고성능, 안전성, 가용성을 위한 분산 시스템을 구축하는 것은 쉽지 않다.
직접 구축할 필요 없이 Kafka를 사용하면된다.
Kafka

머메이드 문법상 <-- 없으면 방향이 틀어지기 때문에 방향 제거 불가
kafka는 데이터를 구분하기 위해 topic이라는 단위를 사용한다.
- Producer는 topic 단위로 이벤트를 생산 및 전송
- Consumer는 topic 단위로 이벤트를 구독 및 소비한다.
- topic: Kafka에서 생산 및 소비되는 데이터를 논리적으로 구분하는 단위
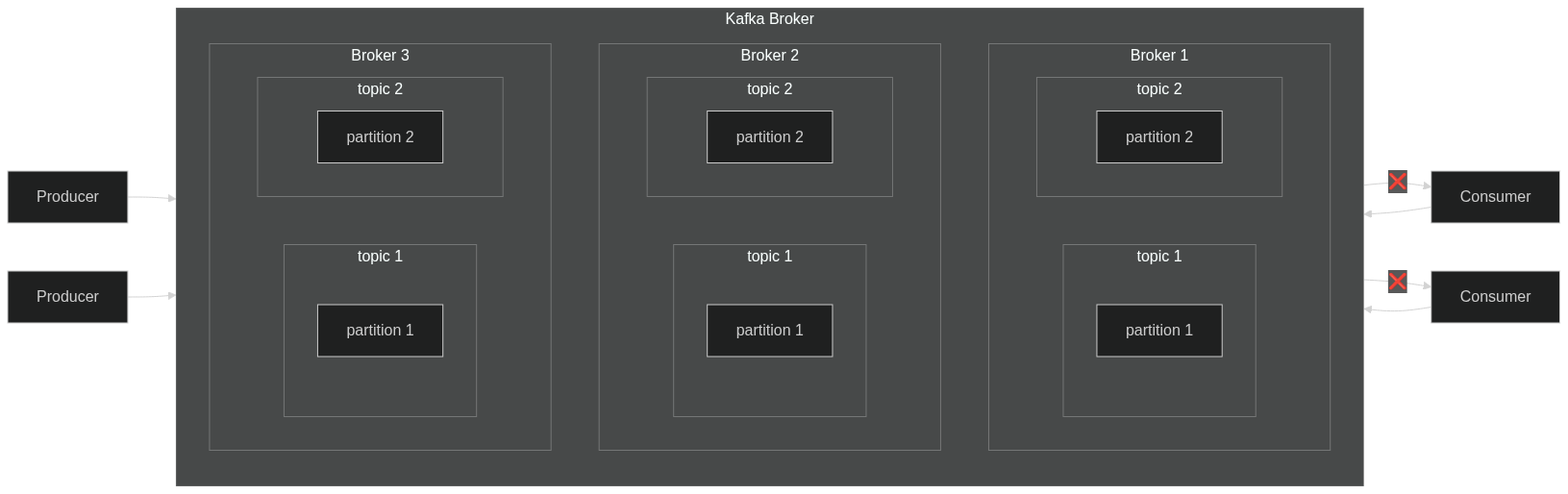
Broker: kafka에서 데이터 중개 및 처리해주는 애플리케이션 실행 단위Kafka Cluter: 여러개의 Broker가 모여서 하나의 분산형 시스템을 구성한 것Partition: Topic이 분산되는 단위, 각 Topic은 여러 개의 Partition으로 분산 저장 및 병렬 처리된다.Offset: 각 데이터에 대해 고유한 위치, Consumer Group은 각 그룹이 처리한 Offset을 관리한다.Consumer Group: 각 Topic의 Partition 단위로 Offset을 관리한다.
