
운영용 서버의 다운으로 깨닳은 모니터링의 필요성
서버가 예상치 않게 죽어버린 적이 있는가? 나는 있다. 최근 그라운드 플립이라는 프로젝트를 배포하여 실제 서비스 중이었다. 어느 순간 우리 서비스를 사용하던 친구에게 연락이 왔다.
운영용 서버가 죽은 것이었다. 이때 당시 인프콘에 방문중이어서 서버를 확인 할 시간이 없었는데 꽤 오랜시간 서버가 다운되어있었다.
이때 나는 서버의 상태를 내가 실시간으로 알아야겠다는 것을 느꼈다.
이때는 배포한지 얼마 되지 않은 상태라 대부분 우리 팀의 지인들이 사용자라 큰 문제는 없었지만 좀 더 시간이 지나 많은 사람들이 유입되면 큰 장애 포인트라고 생각이 되었다. 그래서 바로 서버의 상태를 알림으로 전송하는 서비스를 구축해놓기로 했다.
어떤 식으로 구성 할까?
이전에 CodeDeploy의 결과를 Slack 으로 알림을 받는 기능을 구현해본 적이 있다. 그래서 비슷하게 서버의 상태를 Slack 으로 전송하도록 만들면 어떨까 하는 생각을 했다. 그렇다면 어떤 정보를 서버에 보내야할까?
우선 내가 생각한 지표는 2개다.
✅ 서버의 health 상태
서버가 정상적으로 운영중인지 다운되었는지를 아는 것이 목표이기 때문에 서버의 health check API 의 상태를 모니터링 하기로 했다.
우리 프로젝트에서는 ELB 를 사용하여 라우팅을 하는데 ELB에서 서버의 health 를 확인하는 기능을 제공한다.
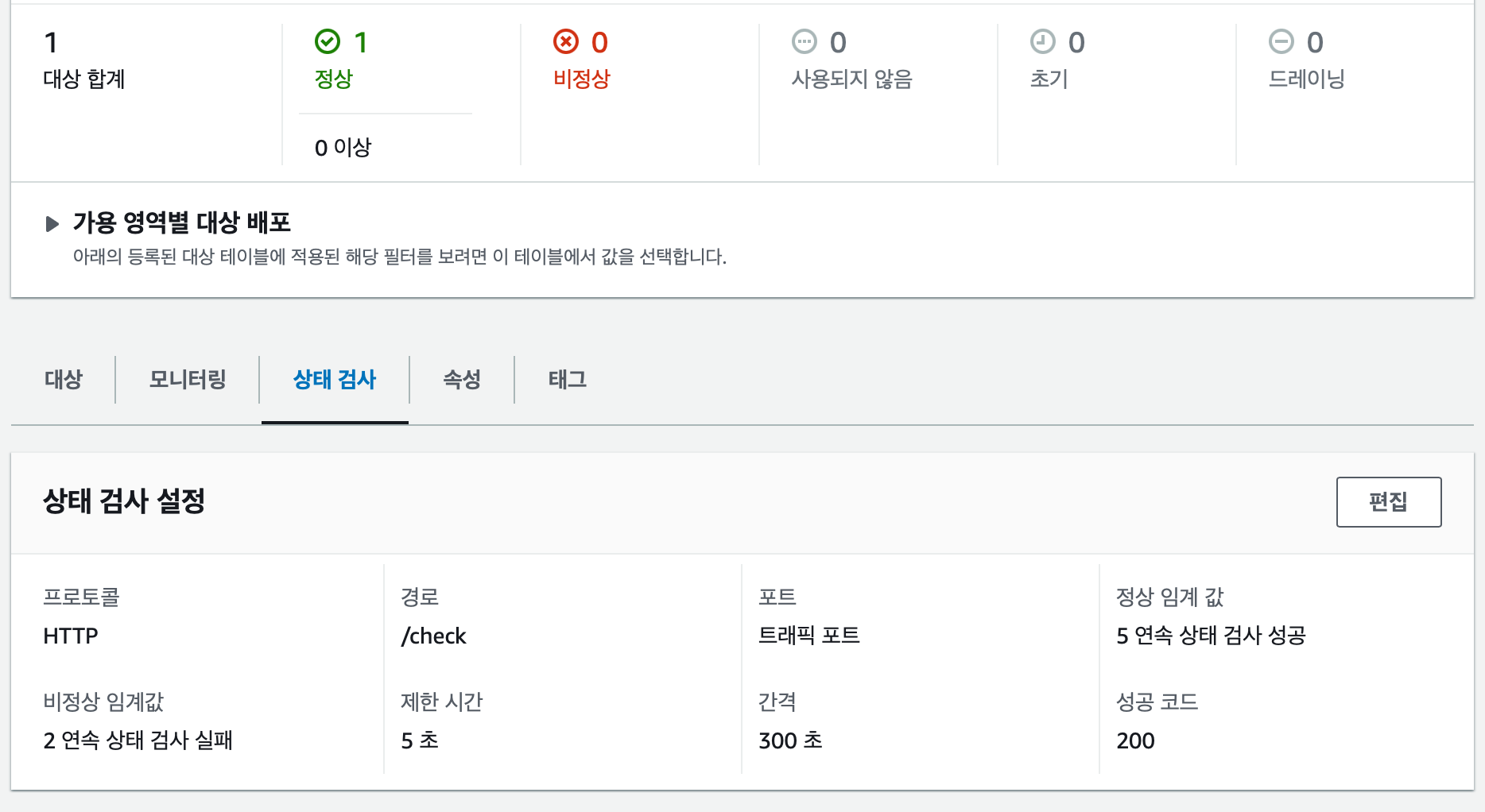
ELB를 세팅 할 때 연결된 서버들의 상태를 검사하는 기능을 설정 할 수 있다.
이 지표를 사용하여 서버가 비정상 상태로 감지 되면 Slack으로 알림을 보내는 기능을 도입하고자 하였다.
🥵 CPU 부하
위의 health 상태는 서버가 죽은 다음에 알 수 있는 정보이다. 이때는 사실 이미 장애가 발생한 후라서 장애가 발생하지 않게 대비 할 수는 없다.
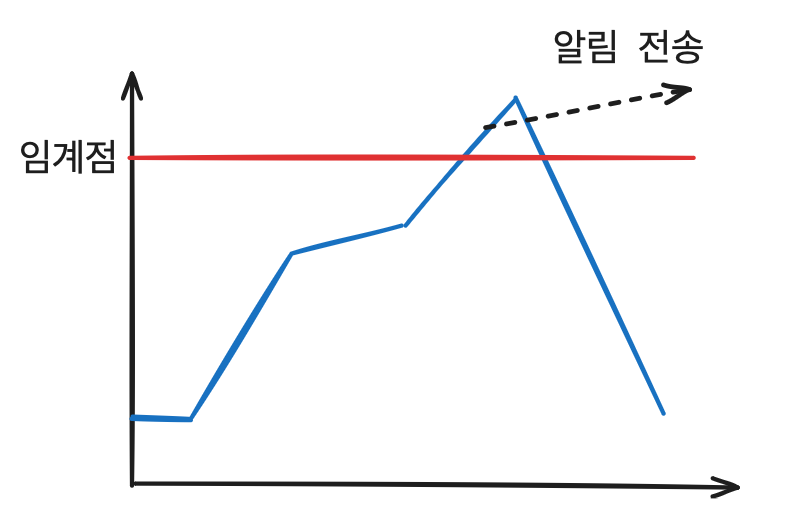
따라서 서버가 죽게 하지 않기 위해 CPU의 부하를 모니터링 해 일정 수준의 부하가 넘어가면 알림을 받을 수 있게 하려고 한다. 알림이 오면 서버의 상태를 개선할 수 있는 대비를 할 수 있게 하기 위함이다.
😶 어떤 식으로 알림을 보낼까?
이전 글 에서 AWS Chatbot 을 사용하여 aws 의 지표를 Slack 으로 보내는 방법을 도입해본적이 있기 때문에 Slack을 사용하기로 했다.
찾아보니 CloudWatch 에서 특정 지표에 대해서 경보를 만들어 낼 수 있다고 한다. 그 경보를 SNS(Simple Notification Service) 라는 메시징 서비스에 전달 할 수 있고 AWS Chatbot 은 SNS 주제를 구독해 메시지를 Slack에 전달 할 수 있다고 한다.
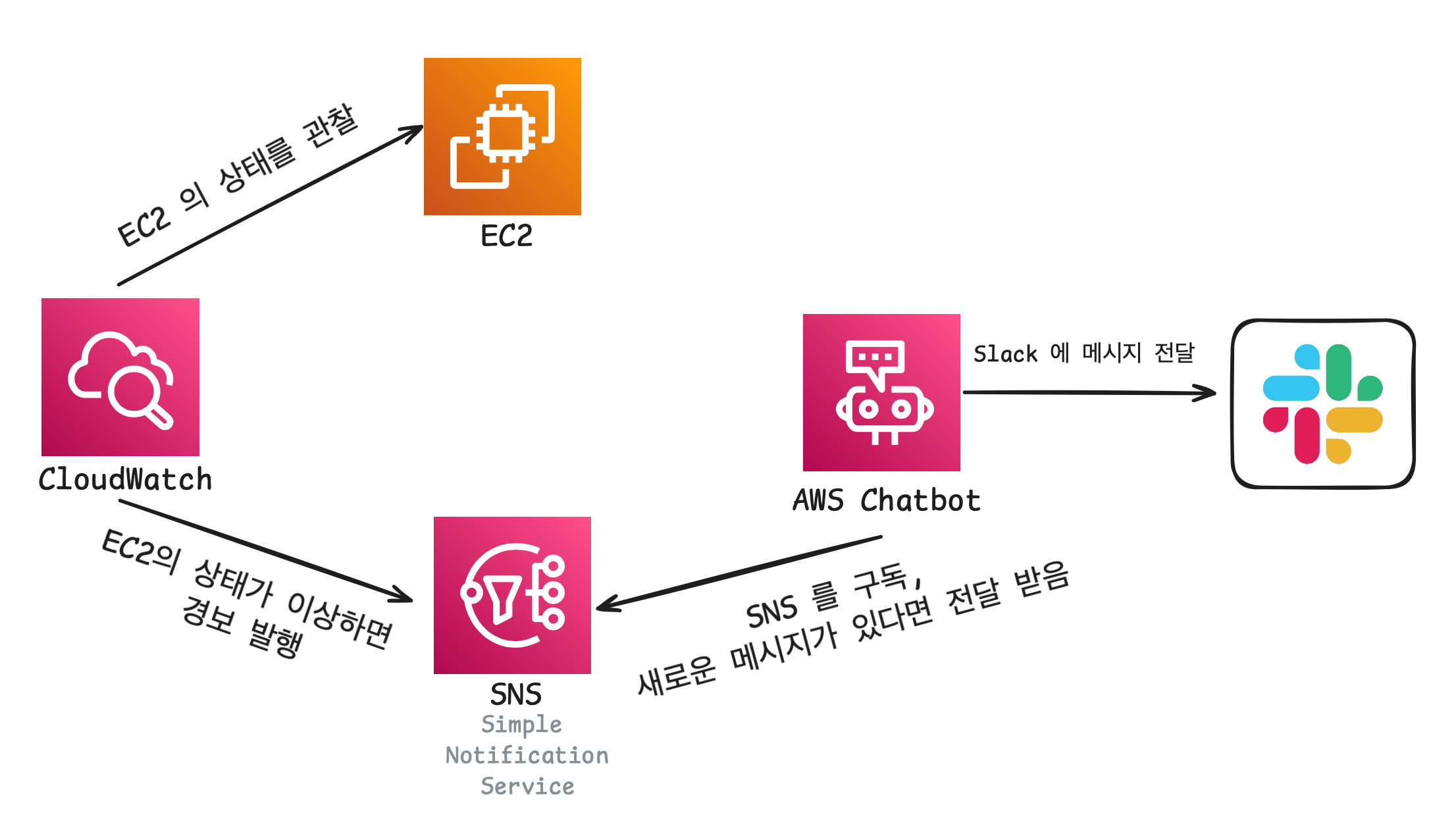
위 다이어그램 같은 플로우로 알림을 보낼 수 있다. aws 친화적이라서 비교적 간편하게 모니터링 시스템을 구축 할 수 있다.
💵 비용은?
그럼 편하게 구축할 수 있는 것을 알겠는데 편한만큼 비싸지 않을까?
정답은 비싸지않다.
SNS

백만개당 0.6 달러 정도여서 1억개 여도 60 달러 의 비용 밖에 발생하지 않는다. 경보가 그렇게 자주있는 이벤트는 아니기 때문에 충분하다고 생각한다.
Chatbot
chatbot 은 가격이 무료다!
CloudWatch

프리티어에서 10개의 경보가 무료이다!
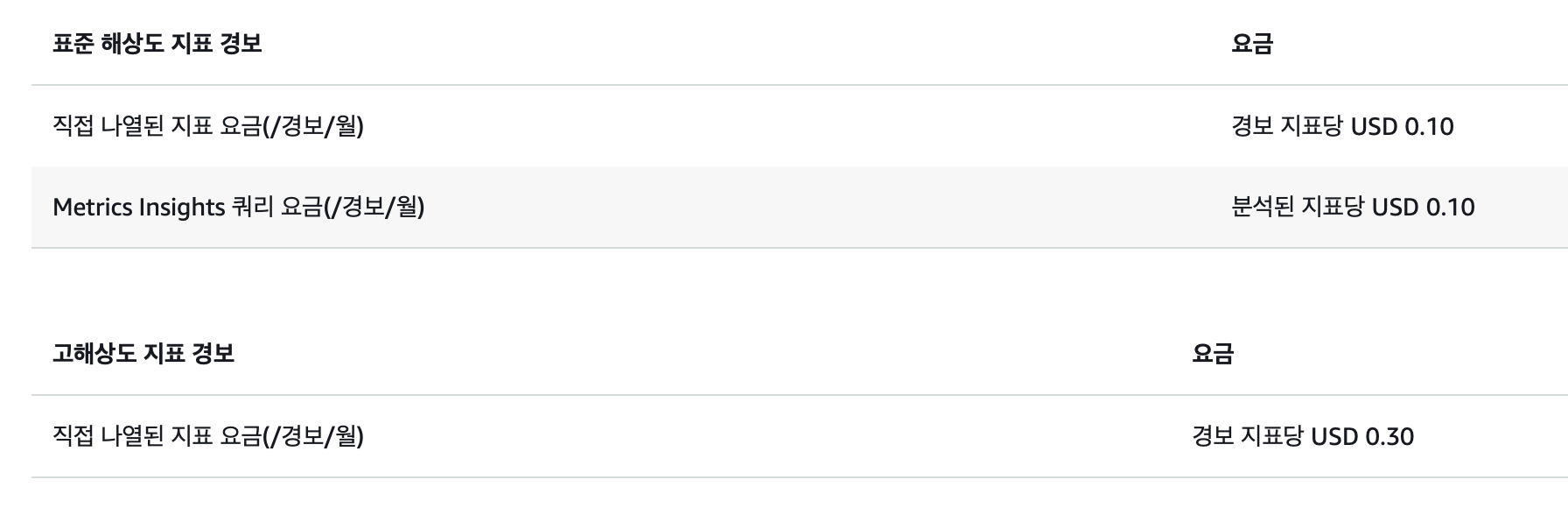
10 개 넘어가는 경우도 지표 1개당 월 0.10 ~ 0.30 달러 정도라서 그렇게 비싸지 않다.
🛠️ 만들어보기
1️⃣ AWS Chatbot 과 Slack 연동하기
이 부분은 이전 글 에 자세히 적어 놓았기 때문에 참고 해주길바란다.
먼저 Slack을 AWS Chatbot 에 연결해야한다.

우선 AWS Chatbot 에 들어가서 새 클라이언트 구성 을 누른다.
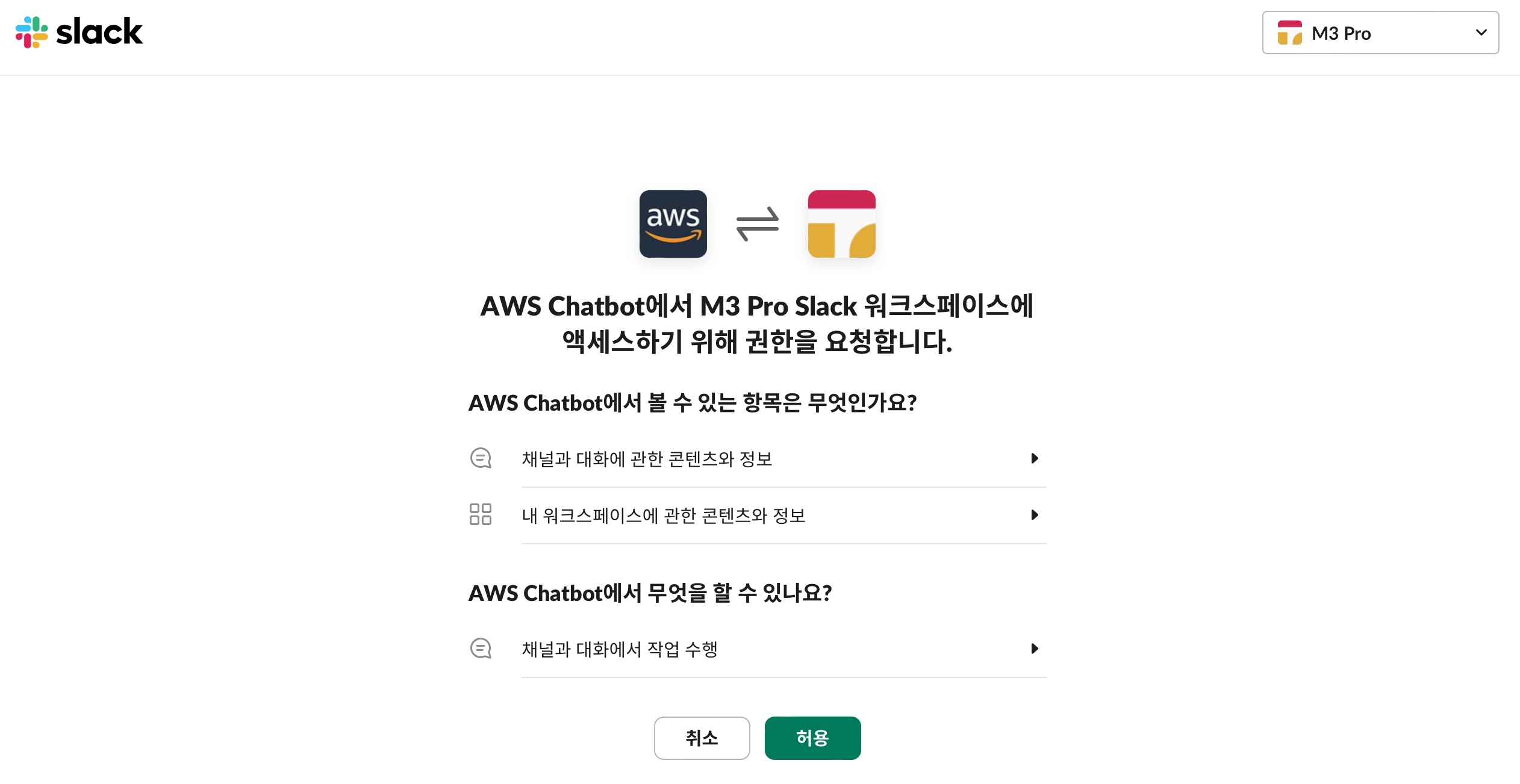
Slack 으로 리다이렉션 되면서 연결할 Slack의 워크스페이스를 선택하는 화면이 나온다. 여기서 연결하고하 하는 워크스페이스를 선택하면 끝이다.
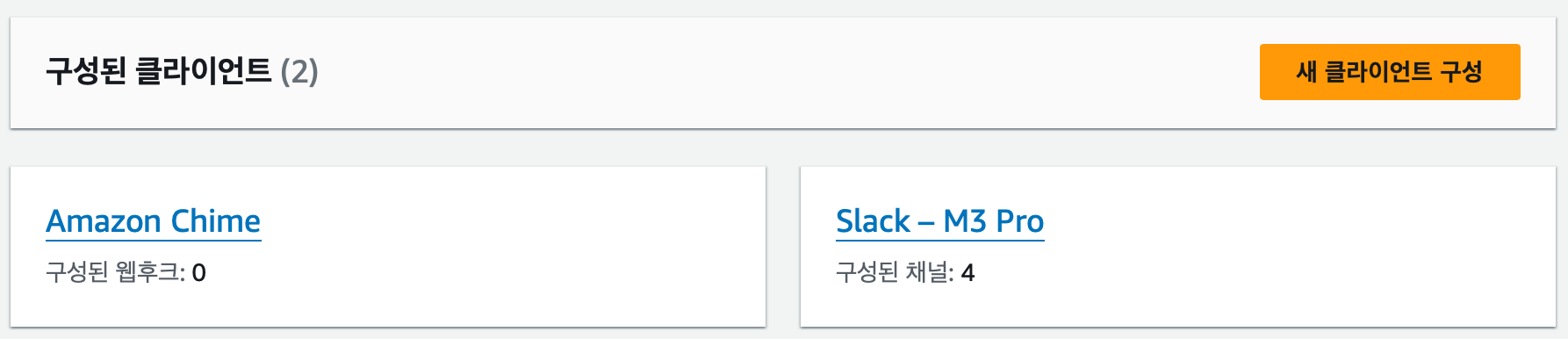
성공적으로 연결이되었다면 위와 같이 Slack-{workspace 이름} 으로 된 항목이 뜬다.
2️⃣ SNS 주제 생성하기
경보내용을 전달할 SNS 주제를 생성한다. 주제를 생성하는 방법은 간단하다. Amazon SNS 에 접속한다.

주제 생성 버튼을 누른다.
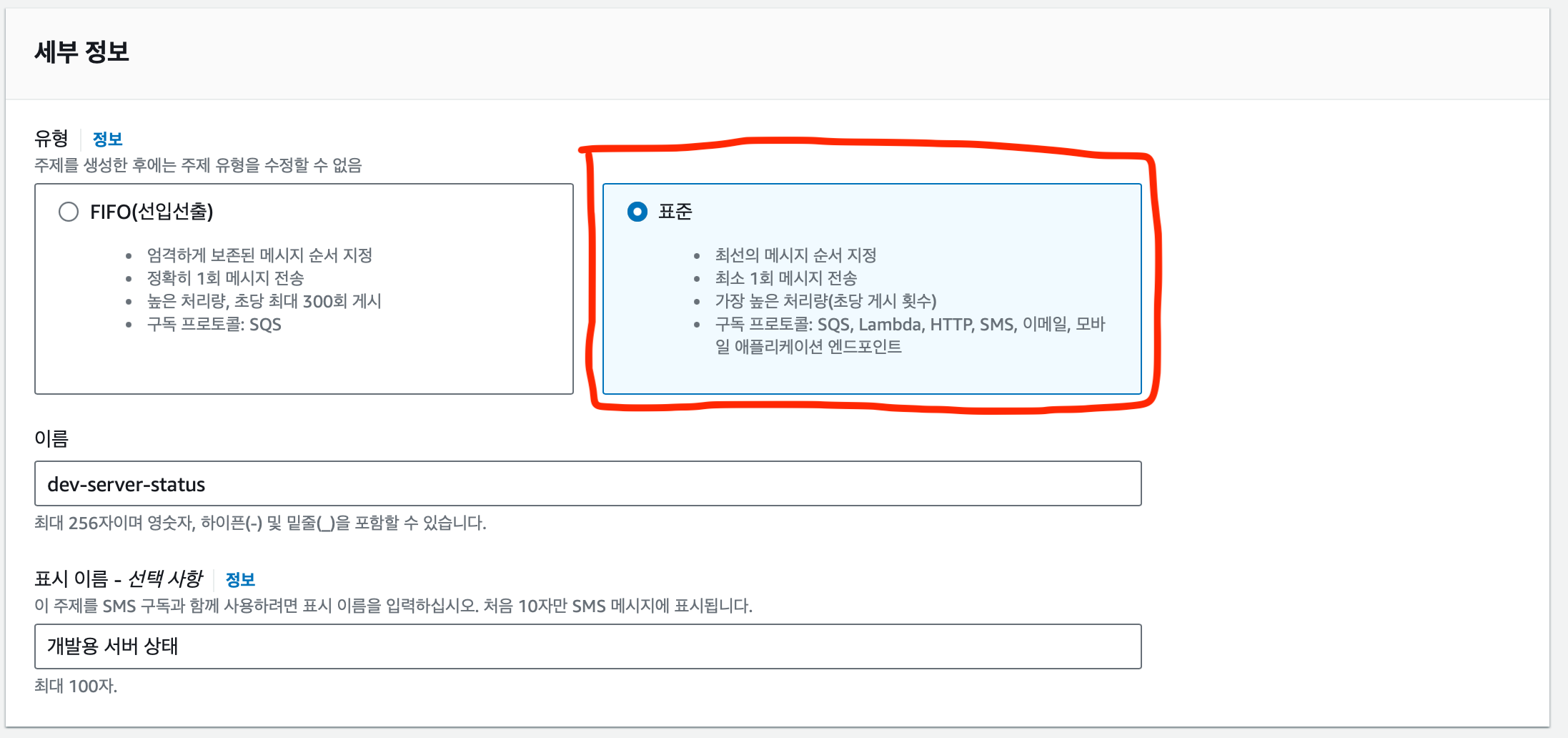
세부 정보를 작성한다.
- 유형이 중요한데 반드시 표준을 선택해야한다.
- FIFO 를 선택하면 Slack 채널 구성을 생성할 수 없다.

- FIFO 를 선택하면 Slack 채널 구성을 생성할 수 없다.
- 이름은 aws 상에서 구분 할 수 있게 작성하자.
- 표시 이름은 선택이기 때문에 필요한 경우만 작성하자.
생성후 이름을 잘 기억해두자. 경보는 모두 이 주제에 전송한다.
3️⃣ 채널 구성하기
SNS 주제로부터 받은 메시지를 전달할 채널을 구성해야한다. 이 부분도 이전 글에 적어 두었지만 살짝 달라지는 부분이 있어 달라지는 부분 위주로 설명한다.
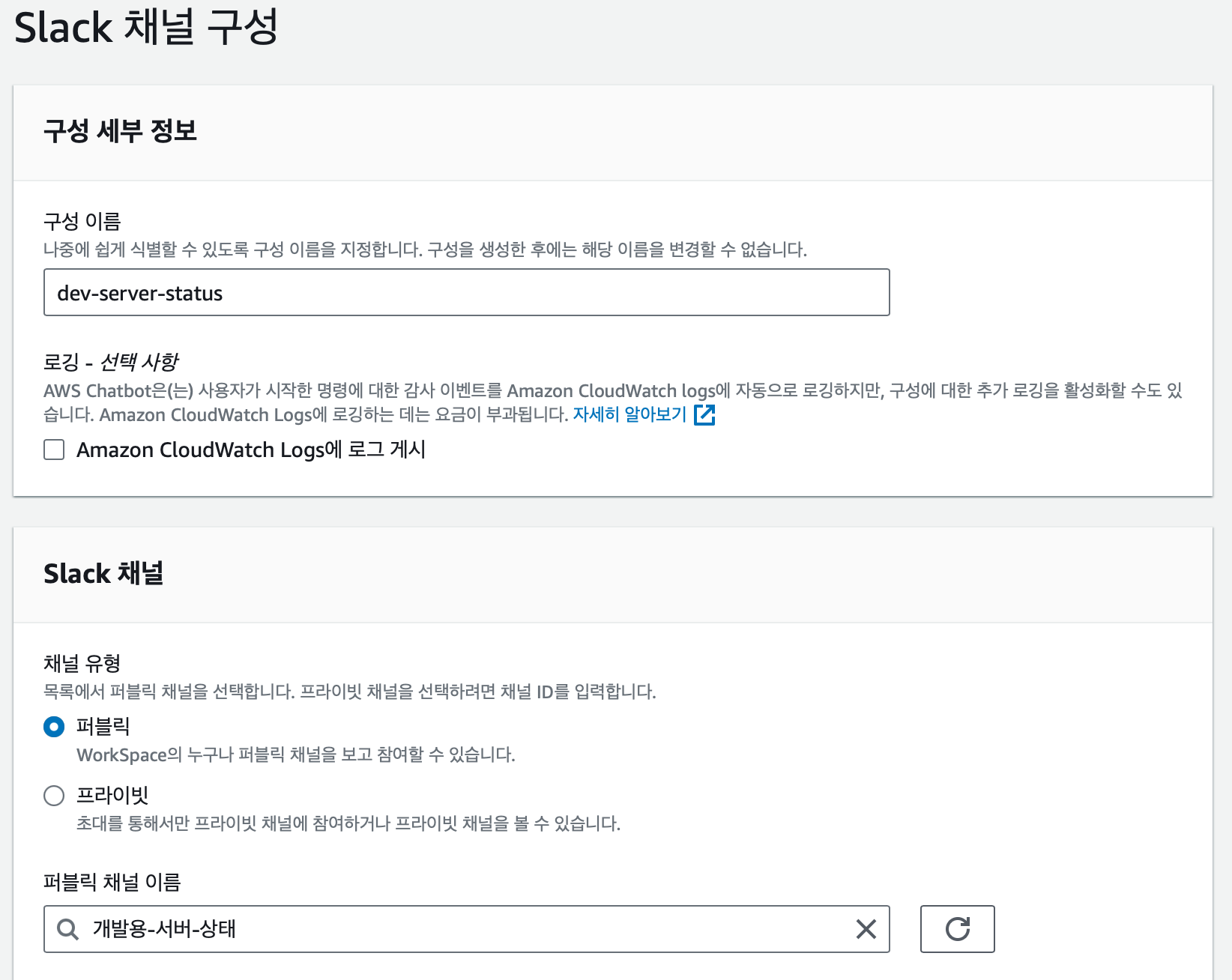
채널 구성 정보를 설정한다.
- 이름을 알아보기 쉬운이름으로 설정한다.
- 연결하고자 하는 채널을 선택한다.
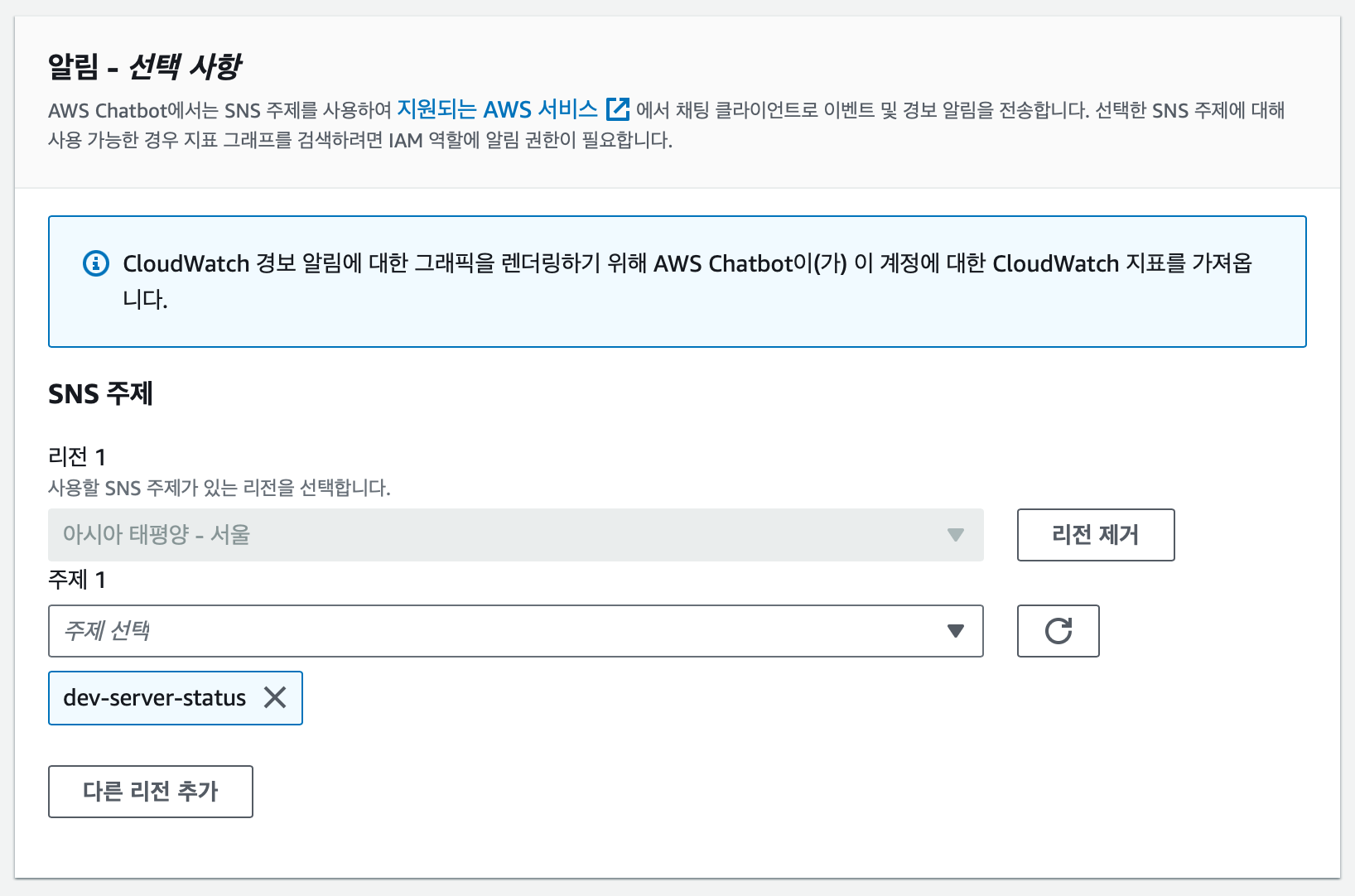
- 채널의 IAM 은 새로 생성하거나 기존에 만들어둔 역할을 부여한다.
- 채널 가드 레일 정책에
AmazonSNSFullAcess정책을 추가 해주어야한다.
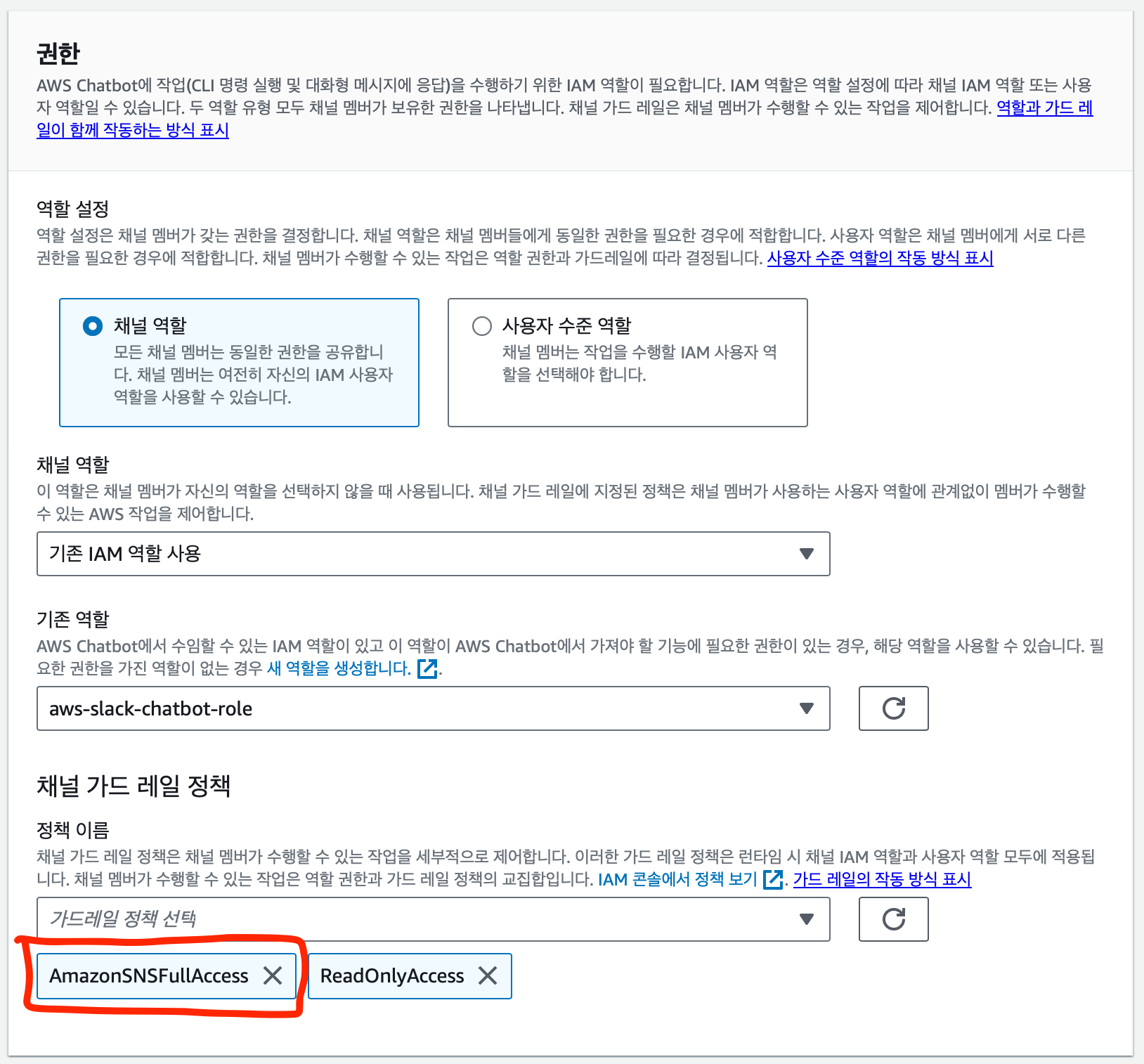
마지막으로 알림을 선택한다.
- 리전은 본인이 사용하는 리전을 선택한다. 나의 경우 아시아 태평양 - 서울 을 ****사용중이다.
- 주제는 위에서 만들어 두었던 주제 이름을 선택한다. 나의 경우 dev-server-status로 만들었다.

마지막으로 저장을 누르면 채널 생성 완료다!
4️⃣ CloudWatch 경보 생성하기
이 부분은 2가지 지표를 수집 하기 때문에 각각의 경우로 나누어서 설명하고자 한다. 먼저 CPU 부하 체크다.
CPU 부하 경보 생성하기
CloudWatch 에 접속하여 경보탭에 들어가면 생성하는 버튼이 나온다.
 경보 생성버튼을 클릭한다.
경보 생성버튼을 클릭한다.
지표선택을 클릭해 찾고자 하는 지표를 찾는다.
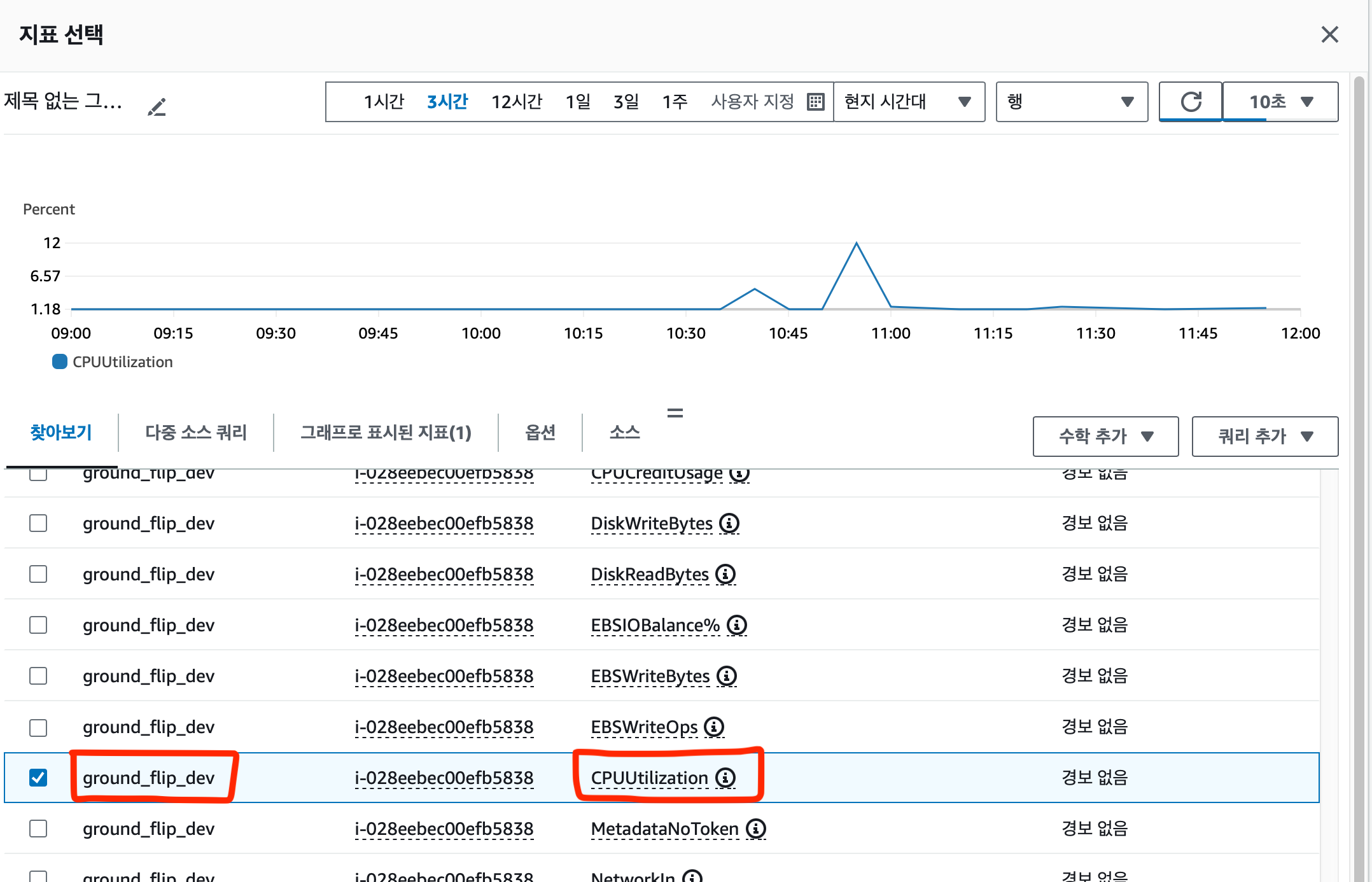
EC2 → 인스턴스별 지표 에 있다. 여기서 지표를 얻고자하는 인스턴스의 이름을 찾고 CPUUtilization 을 찾는다.
처음에는 인스턴스 이름 열에 아무 이름도 없을 수도 있다. 그럴때는
이 부분을 클릭하면 페이지가 바뀌며 다른 인스턴스들도 보인다.
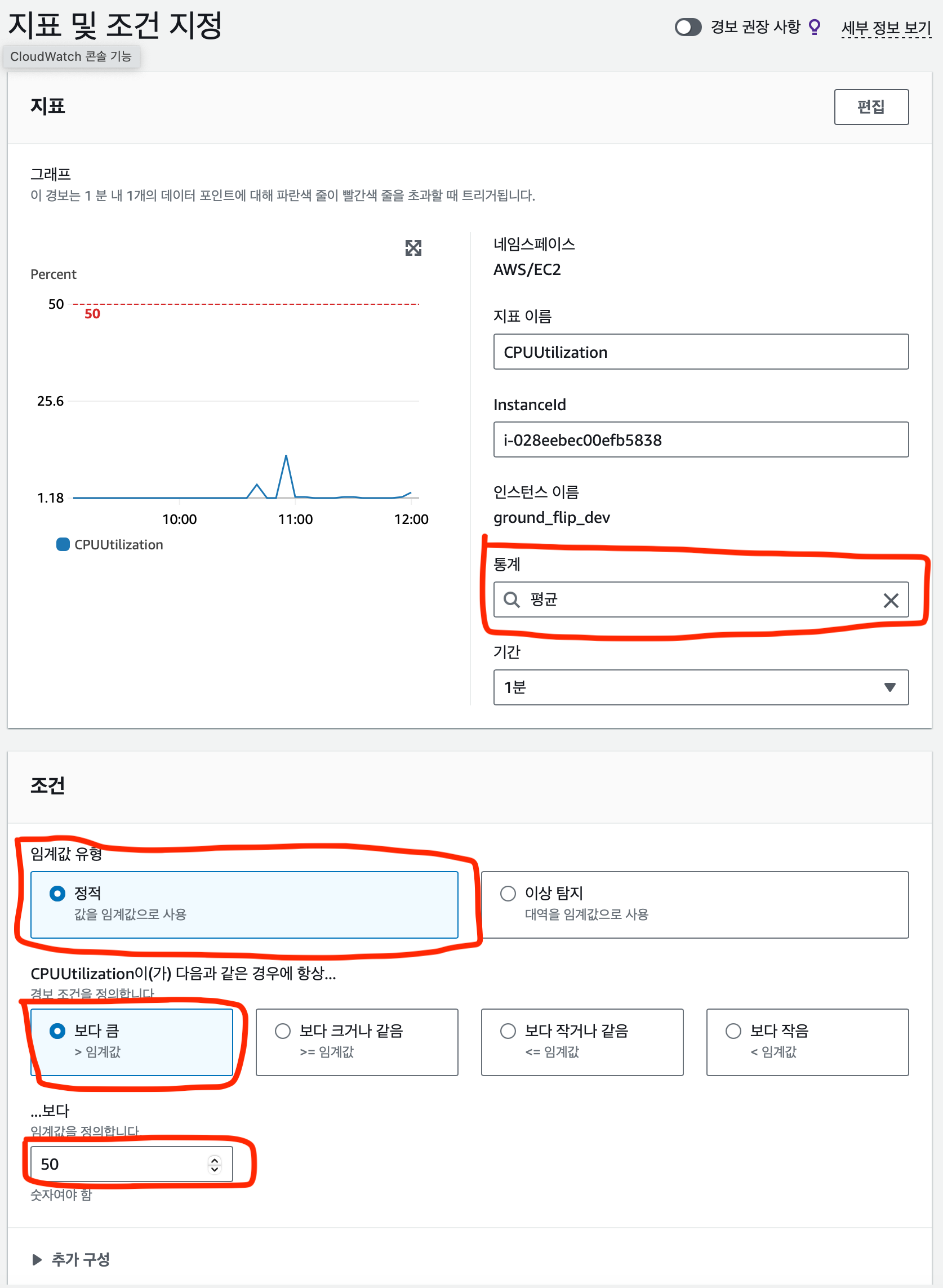
지표 및 조건 을 지정해야한다.
- 지표
통계 같은 경우는 기간동안의 통계를 의미한다. 위 사진의 경우 1분동안의 cpu 부하의 평균을 의미한다. 나는 1분동안의 평균 부하를 지표로 삼았다. 다른 값을 지표로 삼길 원한다면 바꿀 수 있다. 합계, 최대, 최소 등 다양한 통계를 이용가능하다.
- 조건
경보를 발생하는 조건을 50%로 하고 싶었기 때문에 임계값은 50으로 하였다. 조건은 “보다 큼” 으로 설정하였다. 임계값 유형은 대역보다는 값이 필요했기에 정적을 선택했다.
이 외에도 본인이 원하는 조건을 자유롭게 지정할 수 있기에 본인의 상황에 맞는 조건을 지정하자.
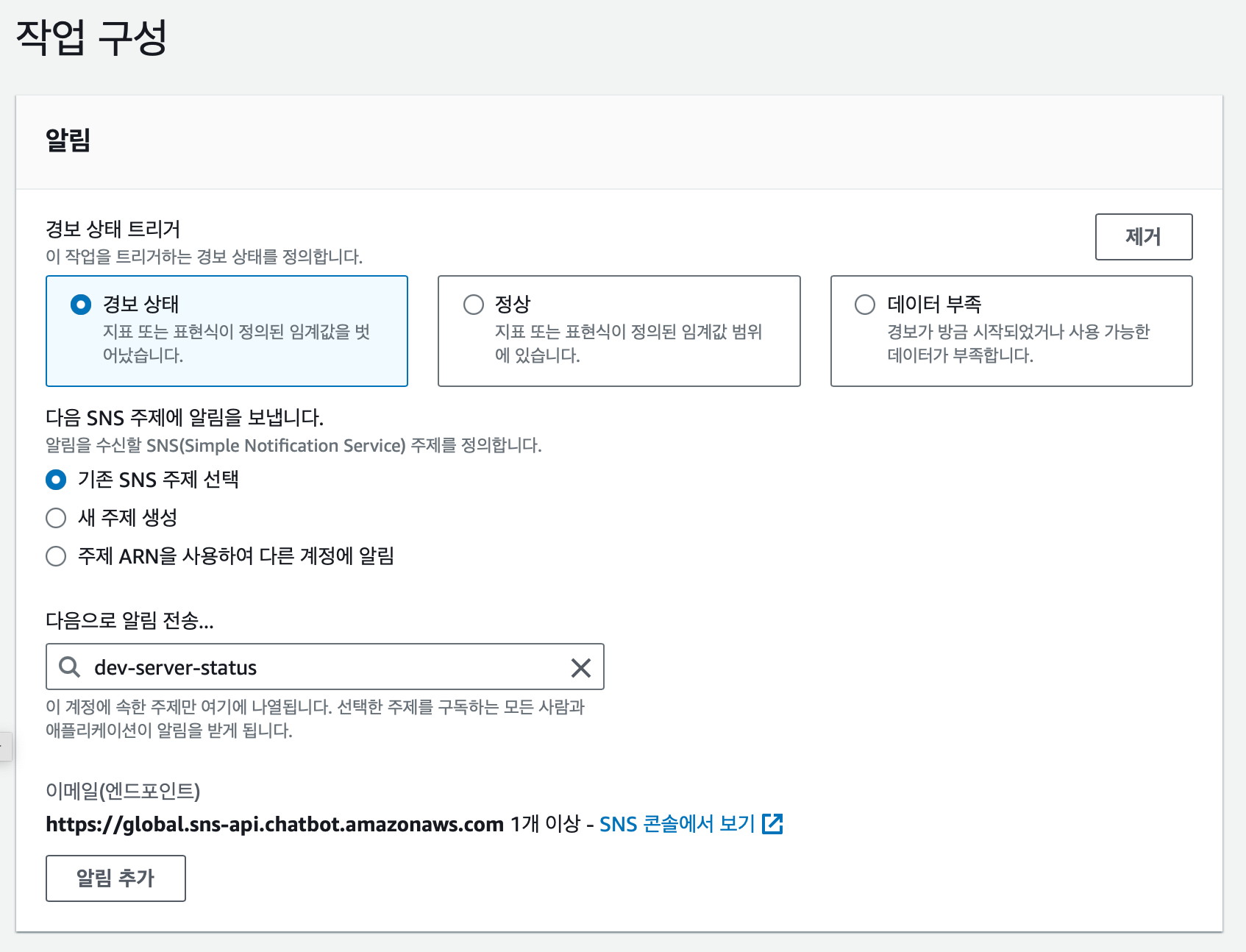
그 다음 작업 구성을 설정한다. 이때 어떤 곳에 알림을 보낼지 설정할 수 있다. 아까 위에서 만들어둔 dev-server-status SNS 에 알림을 전송하도록 설정했다.
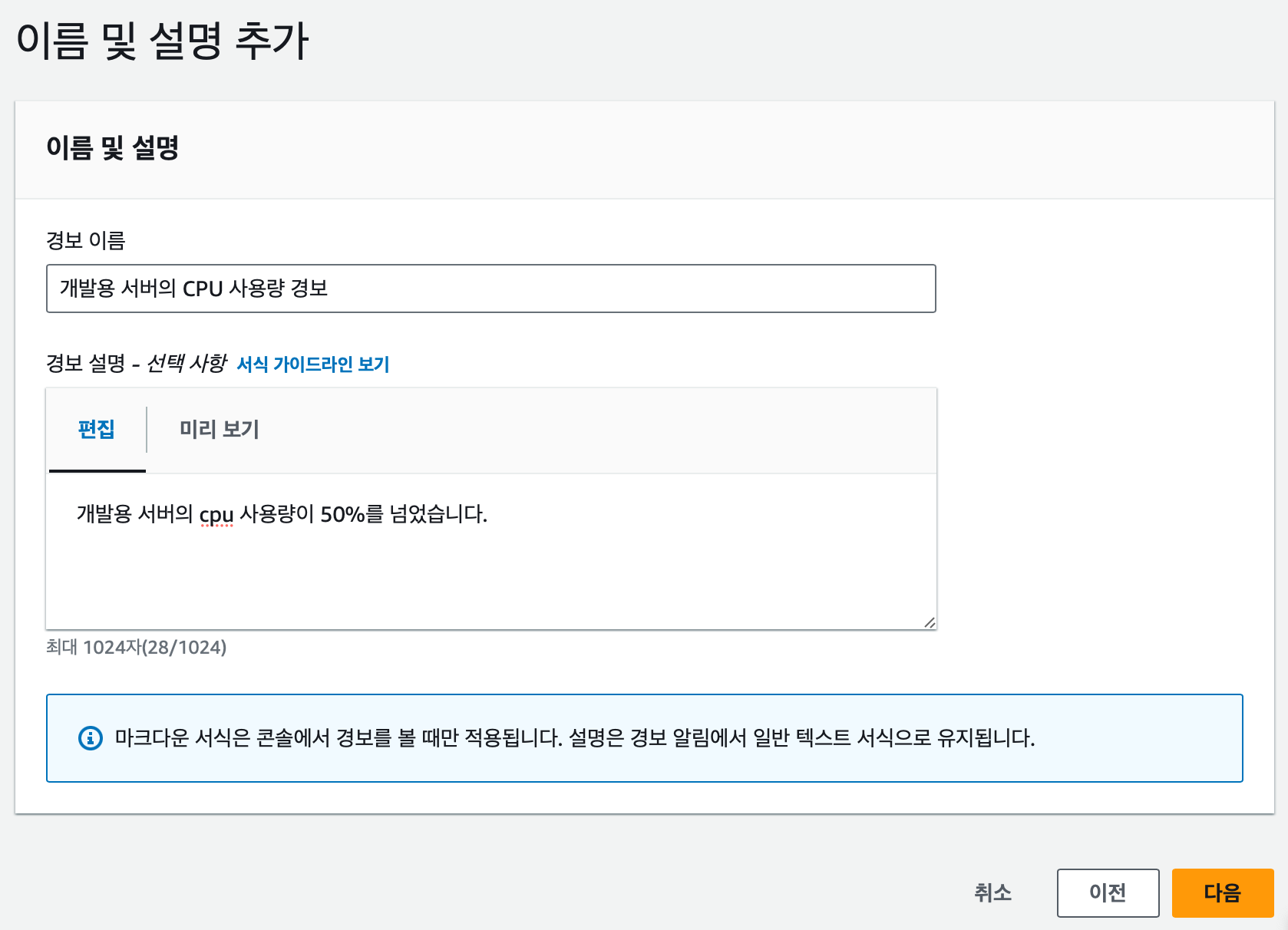
경보의 이름과 설명을 적는다. 경보의 이름과 설명은 Slack 에도 전송되기 때문에 잘 적어두는 것이 좋을 것 같다.
이후 미리보기 및 생성 창이 나오는데 의도한 대로 되었는지 검토해보고 경보 생성 버튼을 누르면 생성이 완료된다!
💯 CPU 부하 알림 테스트
알림 서비스를 구현했으면 실제 알림이 잘 오는지 확인을 해봐야된다. 이때 stress 라는 리눅스 명령어를 사용하면된다.
## 설치
sudo apt update
sudo apt install stress
## 사용
stress -c 2 -t 600-c뒤에 사용할 cpu 코어 수를 넣는다.-t뒤에 부하를 줄 시간을 넣는다. 초 단위로 설정된다. 위 예시대로면 600초 → 10분이다.
위 명령을 실행하면 EC2 CPU 에 부하가 걸린다.
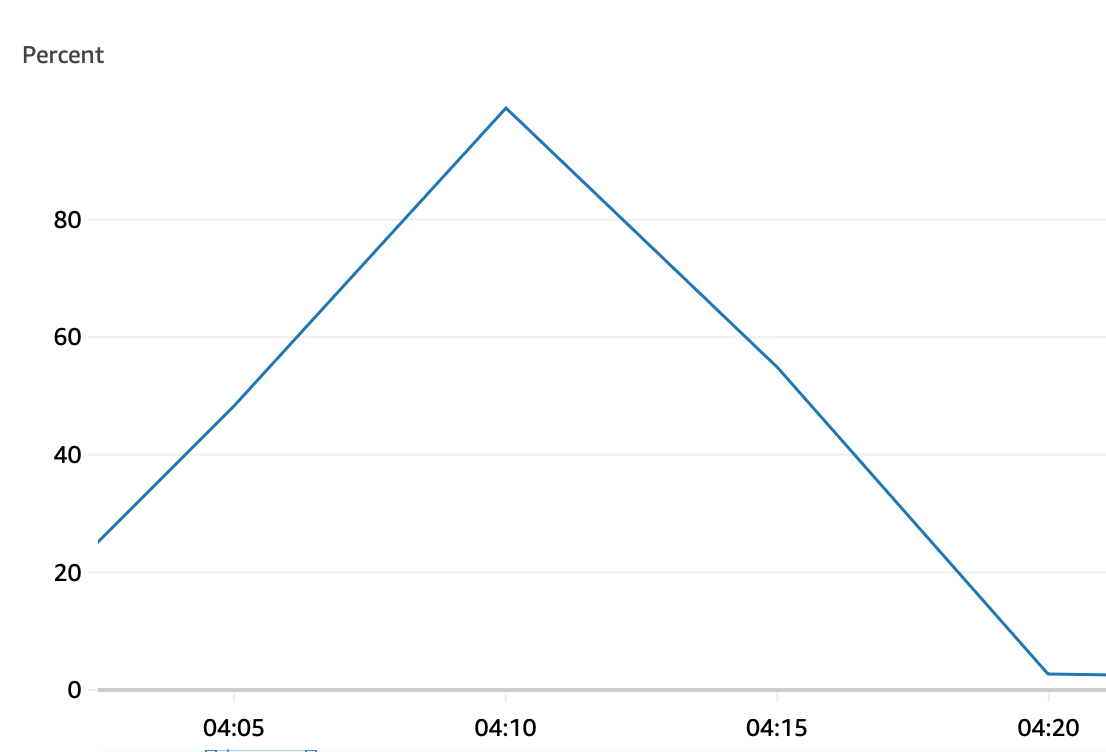
부하가 정상적으로 100% 까지 올라가고
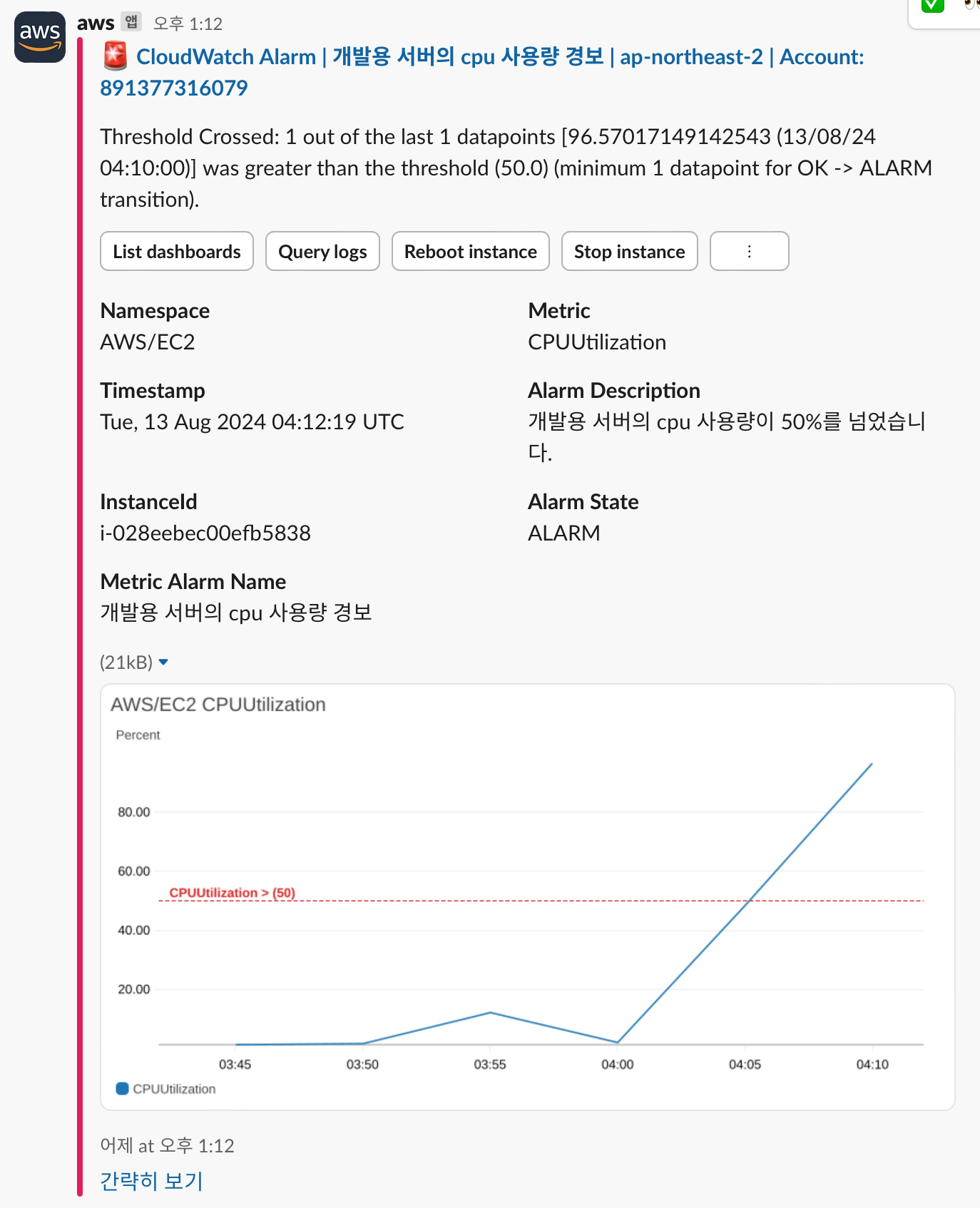
정상적으로 Slack 에 알림이 발송된다!!
서버의 health 상태 경보 생성하기
위의 CPU 부하와 방식이 동일하다. 지표와 조건을 설정하는 부분만 살펴보자.
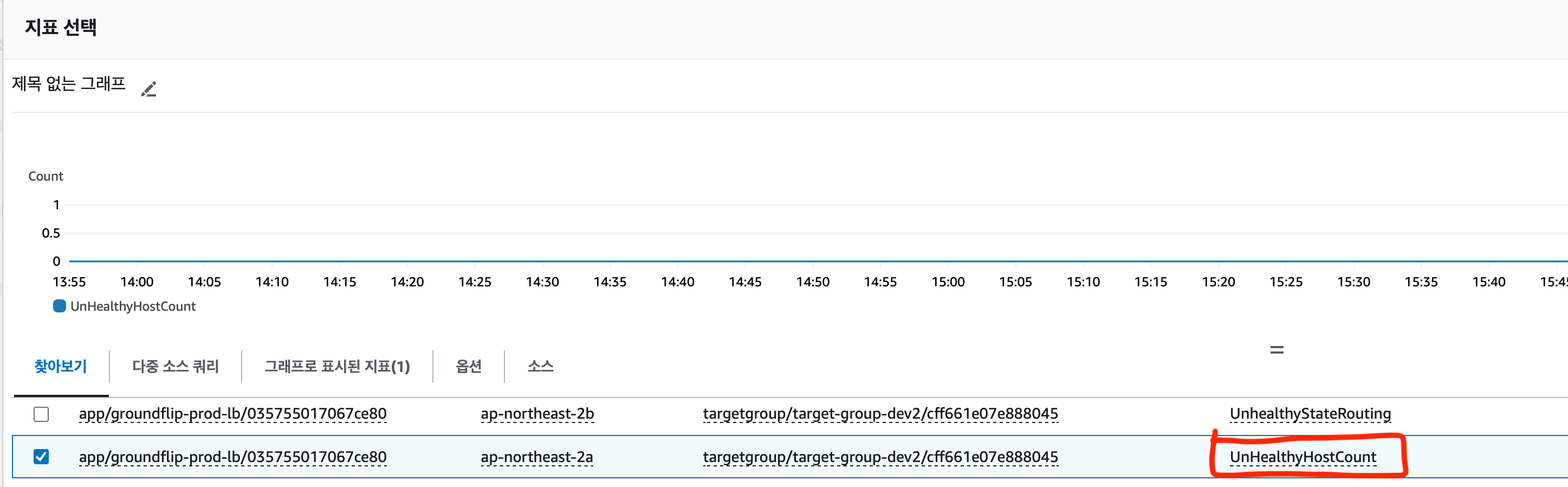
Application ELB → AppELB별, AZ별, TG별 지표 의 UnHealthyHostCount 지표를 선택한다. LoadBalancer 와 ```
TargetGroup
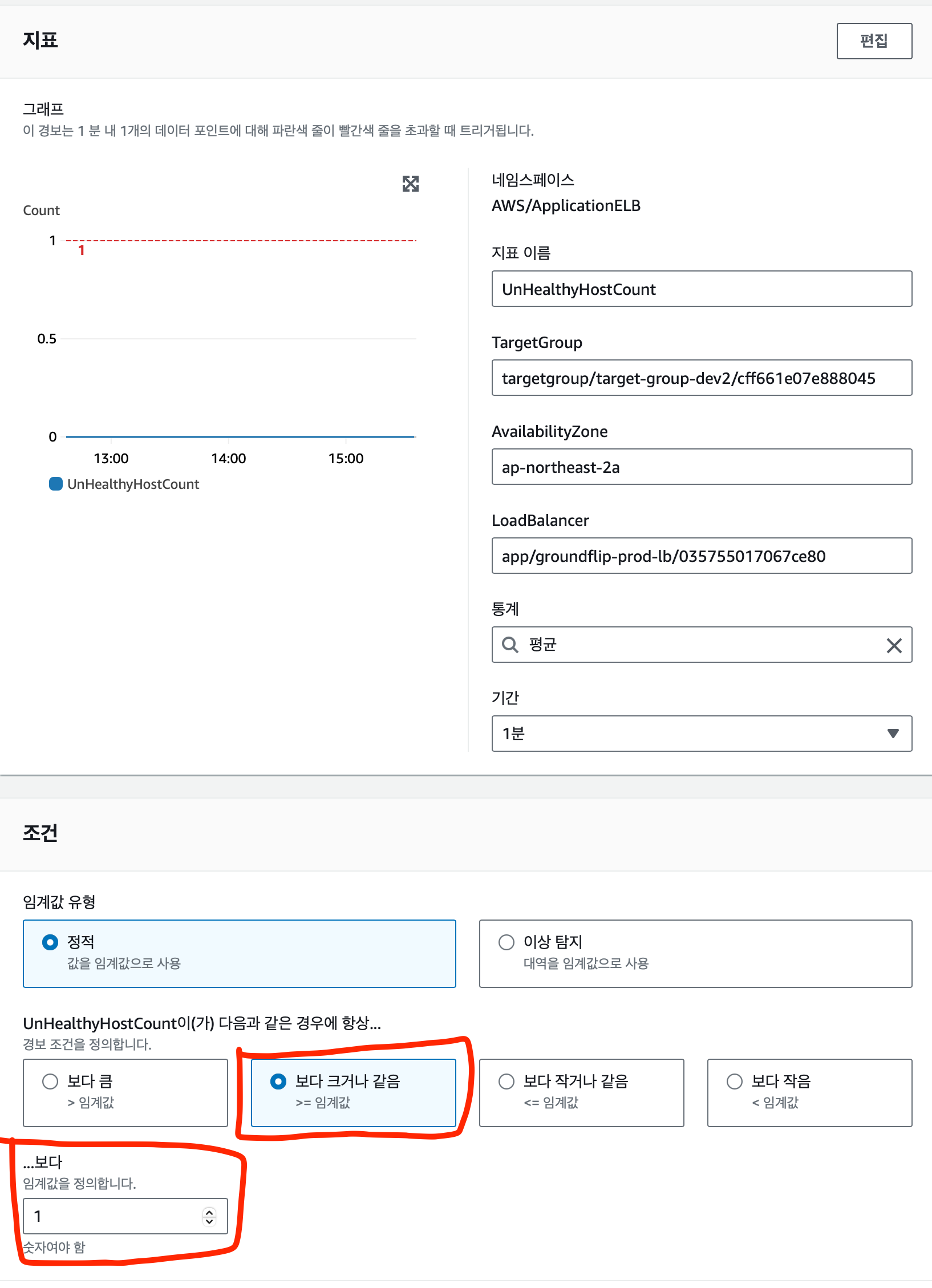
unhealthy 한 서버가 1개라도 있으면 바로 경보가 발생하게 구성하였다.
나머지 부분은 CPU 부하 부분과 동일하게 구성하면 **Slack** 으로 알림을 받을 수 있다.
### 💯 서버의 health 상태 테스트
잘 동작하는지 확인하기 위해 잘 돌아가는 인스턴스를 종료해보았다.
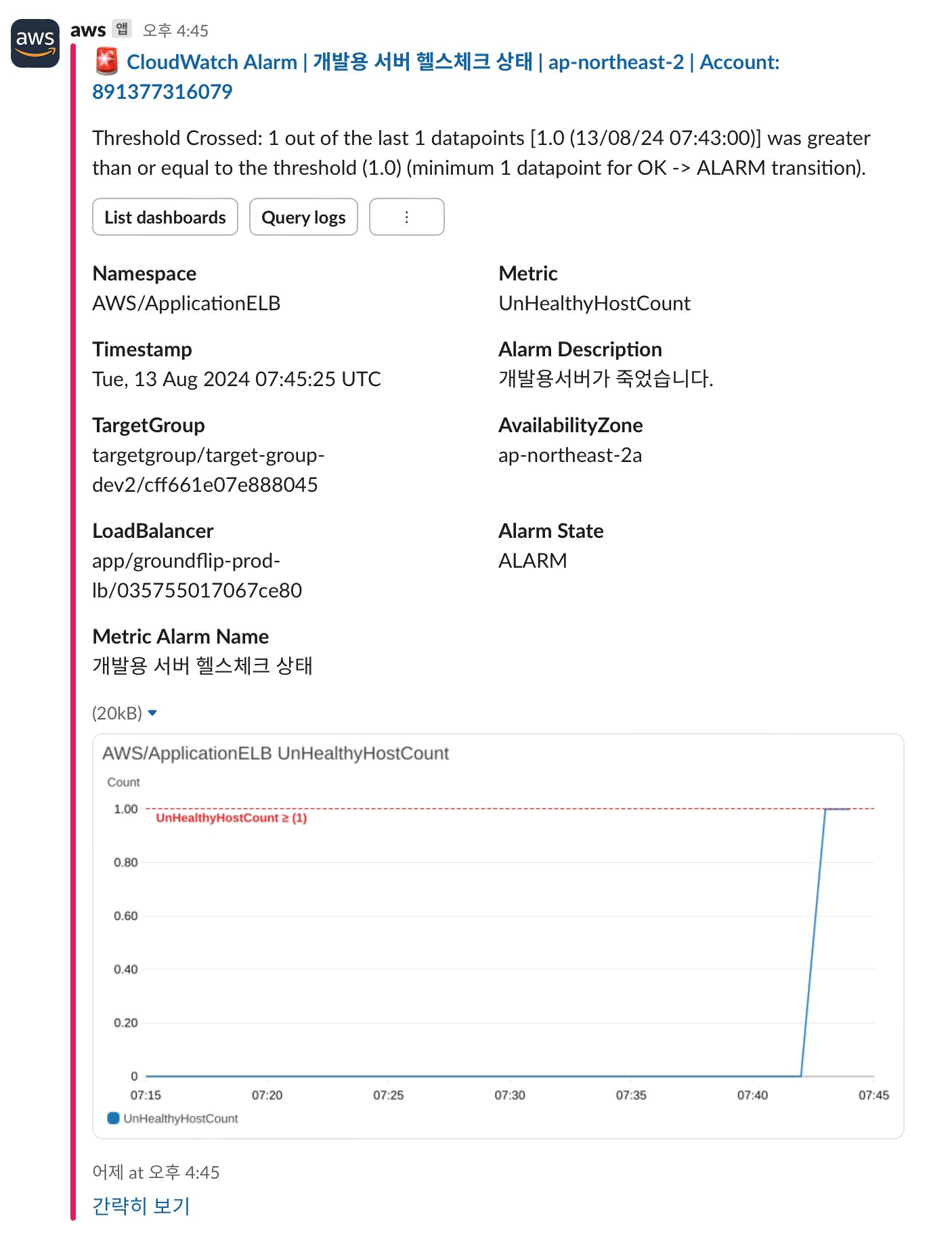
> 정상적으로 지표가 변화하고 경보가 잘 발생하여 Slack 으로 알림이 오는 것을 확인 했다!
>
# 마무리
위 예시들은 개발용 서버를 예시로 들었지만 실제로는 운영용 서버에 적용을 해둔 상태이다. 본인에게 맞는 지표를 잘 커스텀해서 경보 시스템을 구축한다면 운영에 있어서 편할 것으로 생각된다. 난이도도 어렵지 않기 때문에 **AWS** 와 **Slack** 을 사용한다면 해봐도 나쁘지 않는 작업이라고 생각한다.
## 아쉬운 점
CPU 부하를 감지하는 알림을 만들어두긴 했지만 아직 이 경보가 울렸을 때 **대응 할 방법을 구상해두지 않았다.** 이 경우에는 **오토 스케일링**을 통해 한번 대응 책을 적용해보고 싶다. 다음번에 오토 스케일링을 적용한 후기를 올려보도록 하겠다.
또한 ec2 인스턴스가 여러대가 되는 경우는 아직 확인을 못해보아서 추후 오토 스케일링을 적용하고 확인해보려한다.
지금까지 긴글 읽어주셔서 감사합니다! 😄