
이전글에서 동시성 문제를 발견한 과정에 대해 소개했었다. 이번 글에서는 그에 이어서 동시성 문제를 해결한 과정에 대해 글을 써보려한다. 해결방법을 선택한 이유부터 구현방법 한계점 까지 내가 느낀점을 소개한다.
해결방법 선택하기
지난 글에서 동시성문제가 원인이라는 것을 발견했기때문에 이제 동시성 문제를 해결할 방법을 찾아야했다. 이 문제를 해결하기 위해 고려한 방법은 크게 3가지 정도가 있었다. 각각을 간단하게 소개하고 선택한 이유와 선택하지 않은 이유를 설명한다.
자바의 Synchronized 키워드 사용하기
스프링에서 Synchronized 키워드를 사용하는 방법이다. 기본적으로 자바는 멀티스레드 언어이기 때문에 하나의 공유 자원에 동시에 접근 할 수 있다. 내가 겪은 문제도 여러 HTTP 요청을 스프링에서 멀티 스레드를 사용해서 동시에 처리하기 때문에 생긴 문제였다.
Synchronized 를 메서드에 사용하면 한번에 하나의 스레드만 메서드에 접근 할 수 있다.
public synchronized void occupyPixel(PixelOccupyRequest pixelOccupyRequest) {
// 땅을 차지 하려는 user id
Long occupyingUserId = pixelOccupyRequest.getUserId();
// 차지 하려는 땅을 조회
Pixel targetPixel = pixelRepository.findByXAndY(pixelOccupyRequest.getX(), pixelOccupyRequest.getY())
.orElseThrow(() -> new AppException(ErrorCode.PIXEL_NOT_FOUND));
// 소유하고 있는 픽셀의 개수 추가
updateRankingOnCache(targetPixel, occupyingUserId);
//픽셀의 소유주 변경
targetPixel.updateUserId(occupyingUserId);
}이런 식으로 메서드에 붙이면 하나의 스레드가 pixel의 소유주를 변경하는 동안 다른 스레드가 접근하지못한다. 때문에 동시성 문제를 해결할 수 있다.
하지만 우리 프로젝트의 해결방법으로 선택하지는 않았다. 이유는 다음 이유들 때문이다.
Transactional 문제
Synchronized 키워드로 간단하게 해결될 것 같지만 그렇지 않다. 위의 occupyPixel 에는 사실 @Transactional 어노테이션이 붙어있는데 Synchronized 는 @Transactional 과 같이 사용하면 동시성 문제가 해결되지 않는다.
간단하게 설명하자면 Transactional 이 AOP 로 동작하기때문에 트랜잭션이 시작하고 커밋되는 과정은 Synchronized 가 적용되지 않는다. 그래서 트랜잭션이 커밋되기 전에 다른 스레드가 Synchronized 메서드에 접근이 된다. 그렇기 때문에 다른 추가 적인 로직을 사용하여 좀 복잡하게 처리해야한다.
분산환경
Synchronized 는 하나의 프로세스 안에서만 적용된다. 여러개의 프로세스를 사용하는 분산환경에서는 사용할 수 없다. 우리 프로젝트는 로드밸런서를 통해 auto scaling 이 적용되어있어 여러개의 스프링 프로세스가 돌아간다. 따라서 우리는 Synchronized 를 사용하여 동시성 문제를 해결하기는 어려움이 있다.
데이터 베이스에서 해결하기
💡 미작성분산락 사용하기
마지막으로 고려한 방법은 분산락이다. 분산락은 사용하면 멀티 프로세스 환경에서 공유자원에 접근하는 문제를 효과적으로 해결할 수 있다. 분산락의 원리는 공유자원에 대한 락을 외부의 시스템에서 관리하고 각각의 애플리케이션에서 락을 관리하는 시스템을 확인하여 공유자원에 접근 하는 방식이다.
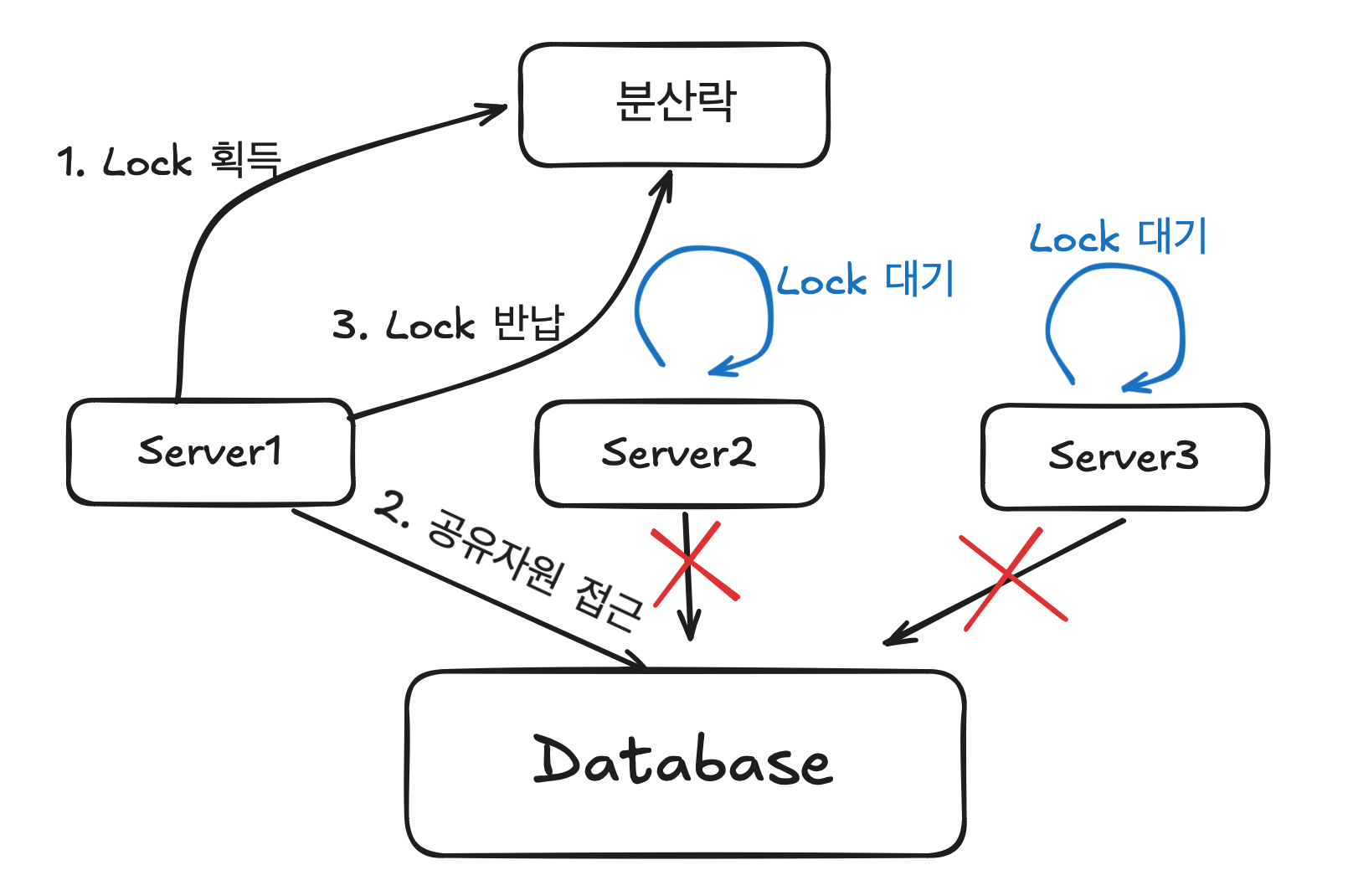
위 그림 처럼 공유 자원에 접근하려면 Lock 을 획득한 상태에서만 접근 가능하게 된다.
- Server1에서 Lock 을 획득 했다면 나머지들은 Lock 을 얻을 때 까지 공유자원에 접근 할 수 없다.
- Lock을 얻을 때까지 대기하고 있는다.
- 공유자원 접근이 끝났다면 Lock 을 반납하여 다른 서비스들이 Lock 획득하여 공유자원에 접근하도록 하는 방식이다.
분산락을 사용하면 여러 서버가 사용되는 분산 환경에서 효과적으로 동시성 문제를 해결할 수 있다. 그리고 DB에서 락을 관리하는 로직이 수행되지 않기 때문에 DB의 부하를 줄일 수 있는 장점이있다.
분산락을 구현할 서비스 선택하기
zookeeper, redis 등을 사용하여 분산락을 구현할 수 있다. zookeeper 는 팀에서 사용해 본 사람이 없어 러닝 커브가 있을 것이라고 판단하여 제외하였다.
Redis 는 이미 랭킹과 jwt 블랙리스트를 구현하기 위해 인프라가 구축되어있는 상태였다. 그리고 Redis 는 싱글 스레드 기반이기 때문에 잠금 처리를 효과적으로 처리 할 수 있다고 판단해 Redis 를 선택했다.
구현방법 선택하기
Redis 를 선택하긴 했는데 어떤 방식으로 구현해야할까? 찾아보니 Redis를 사용한 방법에도 여러 가지가 존재했다.
스핀락 방식
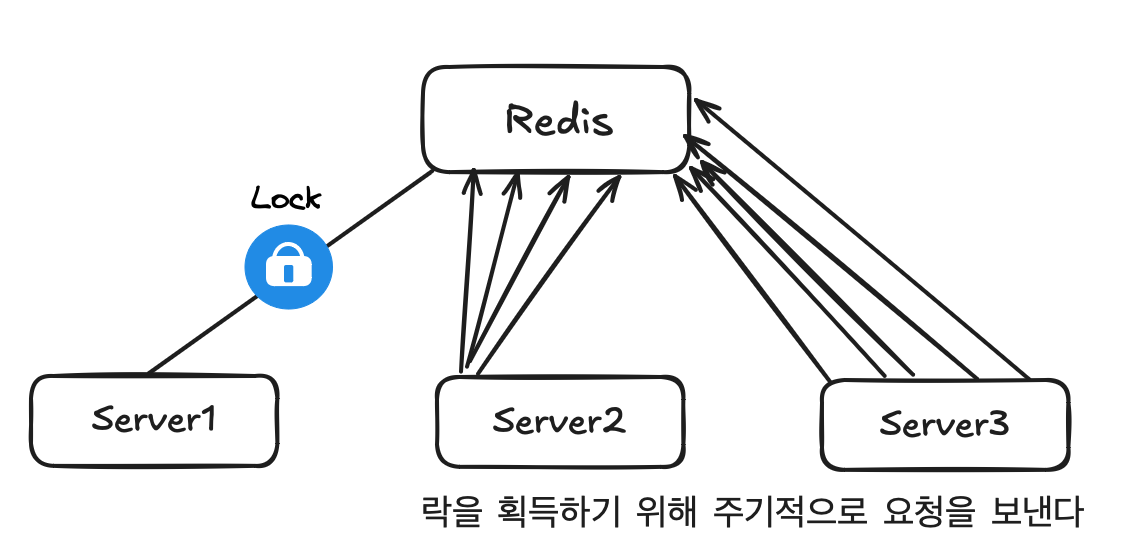
락을 지정해두고 락을 획득할 때 까지 Redis 에 계속 요청을 보내 확인하는 방식이다 (폴링). Redis의 SETNX 를 사용하여 구현할 수 있고 스프링에서는 Lettuce 같은 것을 활용하여 구현할 수 있다.
하지만 이 방식은 락을 획득할 때 까지 Redis 에 지속적으로 요청을 보내야되서 Redis에 부하가 많이 걸린다는 단점이있다. 그리고 타임 아웃이나 성능을 최적하기 위해 요청을 보내는 타이밍을 조절하는 방식을 구현하는 것이 복잡했다. 그래서 사용하지 않기로 했다.
Pub / Sub 방식
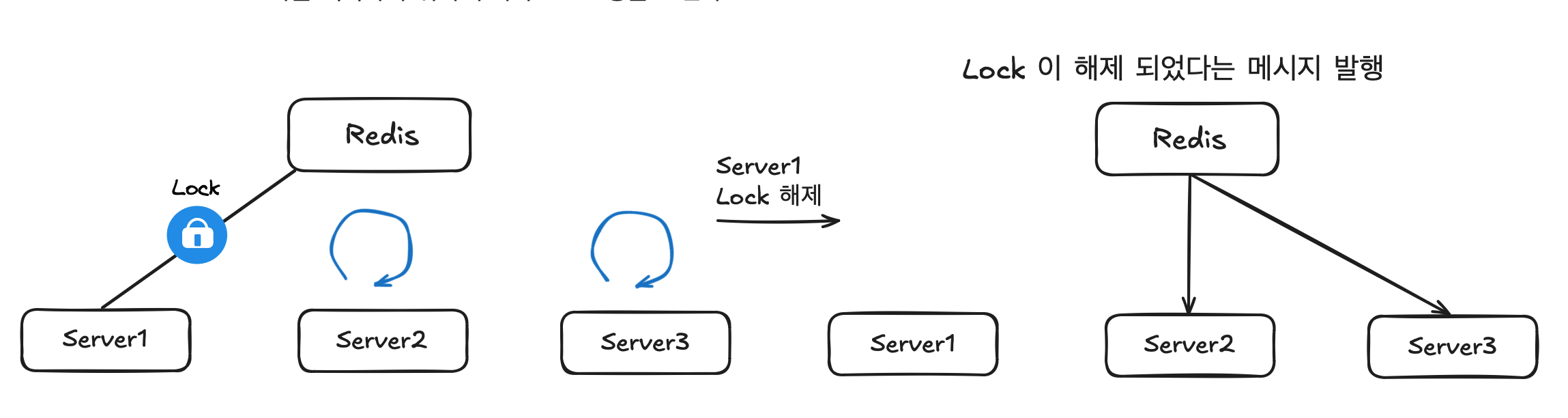
이 방식은 Redis 의 message broker를 사용한다. 이 방식을 사용하면 스핀락과 달리 lock 을 획득할 때 까지 Redis에 요청을 보내지 않아도 되서 Redis 가 받는 부하가 줄어든다.
대신 Redis에서 Lock의 사용이 끝나면 메시지를 발행하여 대기하고 있는 자원들에게 알리는 방식이다. 스핀락 방식보다 복잡해보이지만 자바의 Redis client 인 Redisson 을 사용하면 쉽게 구현할 수 있기 때문에 이 방식을 사용하기로 했다.
Reddison 을 사용해 구현하기
우선 build.gradle 파일에 의존성을 추가 해준다.
implementation 'org.redisson:redisson-spring-boot-starter:3.16.3'그 후 스프링 Bean 을 등록 해준다.
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port);
return Redisson.create(config);
}
}이제 RedissonClient 를 사용해서 구현해야하는데 이 부분이 살짝 복잡하다. 우선 코드 부터 보자.
private static final String REDISSON_LOCK_PREFIX = "LOCK:";
private final RedissonClient redissonClient;
@Transactional
public void occupyPixelWithLock(PixelOccupyRequest pixelOccupyRequest) {
// lock 이름 설정
String lockName = REDISSON_LOCK_PREFIX + pixelOccupyRequest.getX() + pixelOccupyRequest.getY();
// lock 객체를 얻어온다. (lock 을 획득한 상태는 아니다.)
RLock rLock = redissonClient.getLock(lockName);
// 대기 시간과 최대 락을 들고 있는 시간과 단위를 설정
long waitTime = 5L;
long leaseTime = 3L;
TimeUnit timeUnit = TimeUnit.SECONDS;
try {
// lock 획득을 시도한다. 성공하면 true 가 반환된다.
boolean available = rLock.tryLock(waitTime, leaseTime, timeUnit);
if (!available) {
throw new AppException(ErrorCode.LOCK_ACQUISITION_ERROR);
}
// 픽셀을 소유하는 로직
Long occupyingUserId = pixelOccupyRequest.getUserId();
Long communityId = Optional.ofNullable(pixelOccupyRequest.getCommunityId()).orElse(-1L);
Pixel targetPixel = pixelRepository.findByXAndY(pixelOccupyRequest.getX(), pixelOccupyRequest.getY())
.orElseThrow(() -> new AppException(ErrorCode.PIXEL_NOT_FOUND));
updateRankingOnCache(targetPixel, occupyingUserId);
targetPixel.updateUserId(occupyingUserId);
// flush 하여 db 에 반영시킨다.
pixelRepository.saveAndFlush(targetPixel);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// lock 을 풀어준다.
rLock.unlock();
}
}락 이름
우선 락의 이름을 정해야한다. 우리 프로젝트에서 락을 거는 이유는 pixel 의 소유주 정보를 수정하는 작업에서 동시성 문제가 발생해서이다. 따라서 pixel 단위로 lock 을 건다. pixel 에서 x,y 를 합친 문자열은 고유하기 때문에 lock 의 이름은 “Lock:{pixel.x}{pixel.y}” 로 결정하였다.
이제 x,y 픽셀을 수정하려는 요청들은 “Lock:{pixel.x}{pixel.y}” 이 락을 구독하여 확인 하면 된다.
Timeout
- 대기 시간과 소유 시간을 적절하게 잘 설정해야한다.
- 소유시간을 너무 짧게 설정하면 작업이 끝나기도 전에 락이 풀려버릴 것이다.
- 반대로 너무 길게 설정하면 작업이 끝나도 불필요하게 다른 스레드에서 대기하는 일이 발생 할 것이다.
Transaction
@Transactional 이 붙어있는데 pixelRepository.saveAndFlush(targetPixel); flush 를 하고 있다. 이유는 Lock을 풀기전에 트랜잭션이 commit 되어야되는데 @Transactional 특성상 프록시 객체가 생성되고 그 안에 Lock 관련 로직이 들어가기 때문에 Lock 이 풀린 후에 커밋이 된다.
Lock 을 풀기전에 커밋이 되어야하는 이유는 Lock을 풀고 commit 하면 commit 이 일어나기전에 다른 스레드가 pixel을 조회할 것 이기 때문에 동시성 문제가 해결되지 않는다.
따라서 이 문제를 해결하기 위해 jpa 의 flush 를 사용해서 Lock 을 풀기전에 pixel의 소유주를 수정한 작업을 DB에 반영시키는 것이다.
컬리 블로그 를 참고해보면 Lock 로직을 AOP 로 분리하였는데 참고 해봐도 좋을 듯 하다!
결과
위 코드대로 분산락을 적용한후 다시 Jmeter 로 테스트 해보았다. 같은 픽셀에 소유주를 userId 75 로 바꾸는 요청을 1초 동안 50번 보냈다.
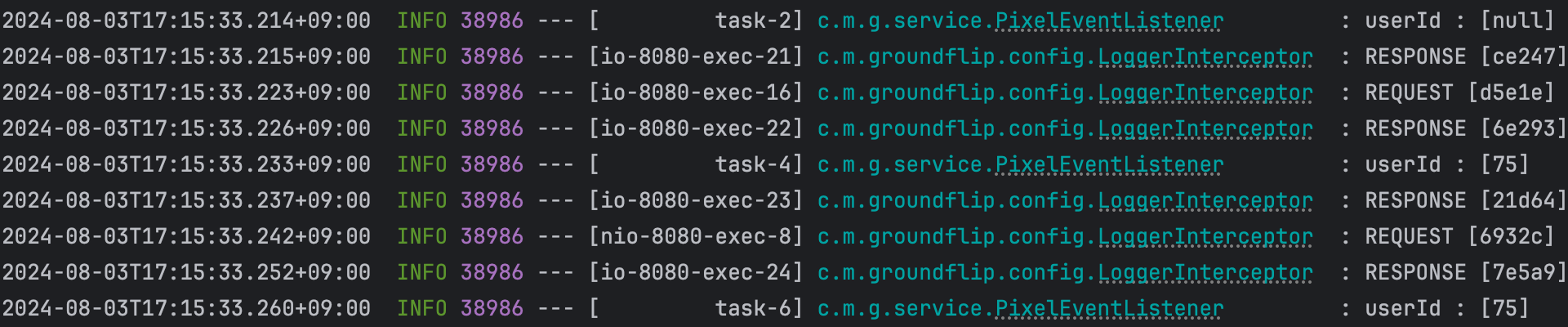
결과는 성공이다!
로그를 확인 해보면 첫 요청만 null로 인식되고 그 다음 요청부터는 첫 요청에서 소유주를 바꾼 데이터를 참조하는 것을 확인 할 수 있다.
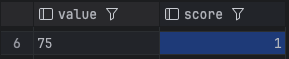
Redis 를 확인해봐도 정상적으로 1이 들어가는 것을 확인 할 수 있었다!
한계
동시성 문제를 해결했지만 장점만 있는 것은 아니다.
성능
우선 락을 적용하지 않았을 보다 평균 응답 속도가 증가했다. 기존 로직에 비해서는 Redis 와 통신하는 비용이 추가 되었으니 말이다. Jmeter로 테스트 하는 김에 성능도 같이 측정해보았다.
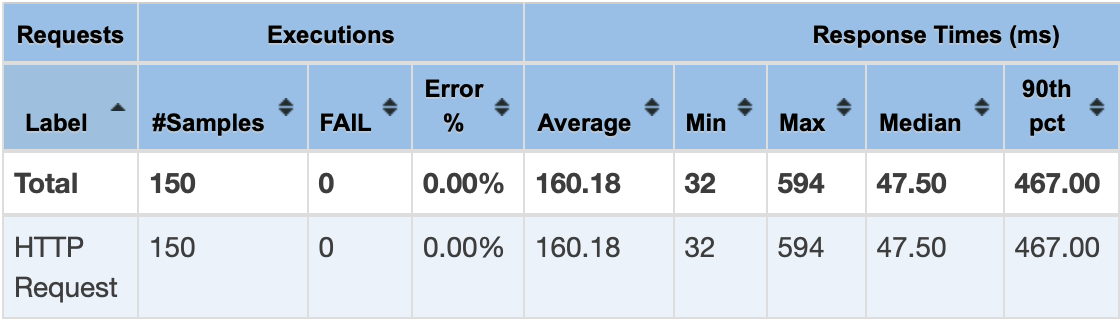
1초동안 50번씩 요청하는 방식으로 측정했다.
락을 걸지 않은 경우
분산 락을 걸은 경우
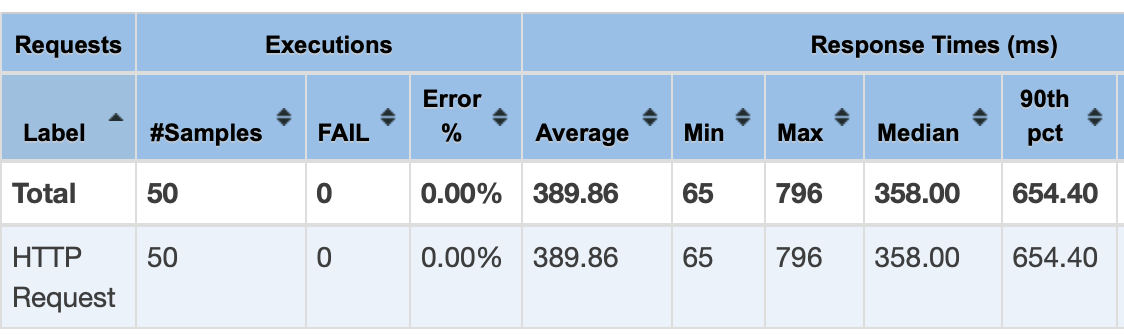
결과를 살펴보면 일단 Average 는 160.18 에서 389.86 으로 2배 정도 증가한 것을 확인 할 수 있다. 확실히 Redis 와 통신하는 비용이 추가 되어서 성능이 살짝 떨어지긴 한 것 같다.
하지만 성능이 살짝 떨어진 것 때문에 동시성 문제를 포기할 가치는 없다고 판단해서 이대로 적용하기로 했다.
Redis 의존성
두번째 한계점은 Redis 의존성이 너무 높아진 것이다. 픽셀을 차지하는 로직에서 반드시 Redis에 의존하기 때문이다. Redis 에서 장애가 나면 우리 프로젝트의 핵심 로직인 땅을 따먹는 서비스가 아예 먹통이 되버린다는 한계점이있다. (SPOF)
이를 위해 추후에 Redis 를 안정적으로 운영하기 위한 방법들을 적용해야 할 것 같다.
마무리
생각보다 동시성 문제를 해결하기 위해 고려해야할 것이 많은 것 같다. 방법도 여러가지이고 우리 서비스에 맞는 방법을 고르는 것이 쉽지 않은 문제인 것 같다. 무조건적으로 분산락을 동시성 문제의 해결책으로 선택하기 보다는 서비스에 맞는 해결책을 선택 해야할 것이라고 느꼈다.
아직 개선 할 점이 많지만 동시성 문제를 잡아낼 수 있어 뜻깊은 시간이었다!
