
최근 프로젝트를 진행하면서 랭킹 시스템을 구현했다. 랭킹 시스템을 구현하면서 처음에는 RDB를 이용하여 실시간 순위를 구현하려고 하다가 많은 자료들을 찾아보니 Redis를 사용해서 구현하는 편이 효율적이라는 말을 들어 Redis를 이용하여 랭킹 시스템을 구현했었다.
여기서 의문점이 들었다. 구글에 랭킹 시스템에 대해서 검색하면 거의 다 Redis를 사용하여 구현하는 방법만 나온다. 나는 정말 Redis 를 이용해서 구현하는 것이 효율적일까? RDB는 별로일까? 하는 궁금증이 생겨 직접 실험해보기로 했다.
어떻게 테스트 하였는지 자세하게 적어 두었는데 급한 분들은 맨 아래 결과 부터 확인하면 좋을 것 같다!
프로젝트 구조
먼저 어떤 구조로 실험을 설계 했는지 설명할 필요가 있을 것 같다.
랭킹 요구사항
우선 랭킹에 대한 요구사항은 다음과 같이 설정했다.
- 상위 30명의 랭킹을 보여준다.
- 유저의 이름, 프로필 사진, 현재 점수 를 리더보드에 보여준다.
- 랭킹은 실시간으로 갱신된다.
- 랭킹이 실시간으로 갱신된다는 말은 점수가 바뀔때 마다 바로 랭킹을 집계해야한다는 것을 의미한다.
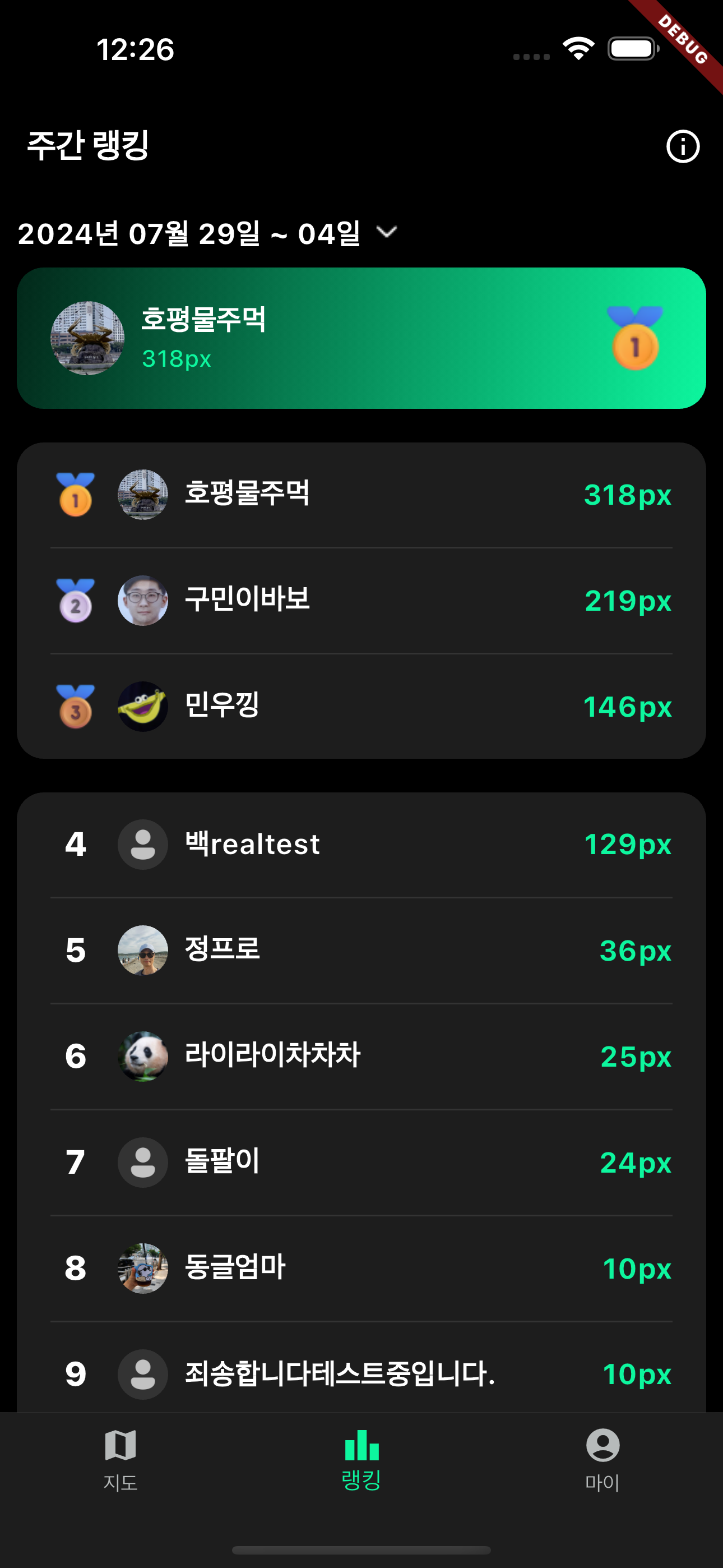
위 그림과 같이 랭킹을 제공할 예정이다.
이제 Redis, RDB 를 사용한 아키텍처는 어떻게 구성해두고 실험 했는지 설명하겠다.
RDB
MySQL 을 사용할 것이고 어플리케이션 서버, 데이터베이스 서버 2개만 사용할 것이다. 이때 랭킹을 위해 사용되는 테이블을 설명하겠다.
테이블 구조
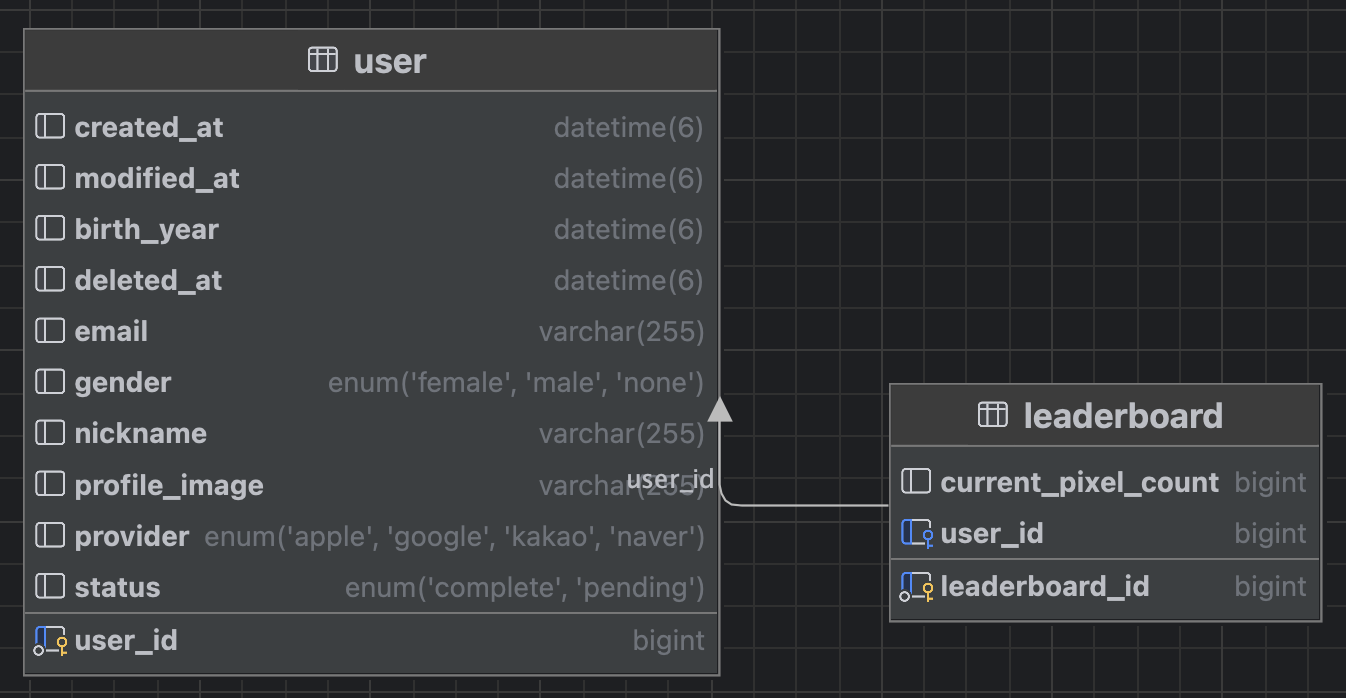
크게 2가지 테이블이 사용되었는데 user 테이블은 user의 회원정보를 나타낸다. 닉네임, 프로필 사진 등을 저장한다.
leaderboard 테이블에는 user_id 와 user 의 현재 점수를 저장한다. current_pixel_count 가 점수이다.
로직
우선 각 user별로 leaderboard 테이블에 점수를 0으로 초기화 하여 넣어둘 것이다. 그리고 점수를 수정 할 때 마다 leaderboard 의 current_pixel_count 를 수정한다.
랭킹을 가져올때 leaderboard 의 데이터들을 정렬하여 상위 30개의 데이터를 가져오는 방식으로 구성하였다. 쿼리를 살펴보면 다음과 같다.
SELECT l.*, u.*
FROM leaderboard l
JOIN user u
ON l.user_id = u.id
ORDER BY l.current_pixel_count DESC
LIMIT 30;전체 데이터를 점수를 기준으로 내림차순으로 정렬한 후 30개의 데이터만 가져오는 방식이다. 매 요청마다 데이터를 정렬해서 가져와야한다.
Redis
Redis를 사용할 때는 Sorted Set 이라는 자료구조를 사용할 것이다.
Sorted Set
Sorted Set은 Redis 가 제공하는 자료구조이다. score 값으로 정렬된 문자열을 관리하는 자료구조이다. score 가 동일한 문자열이 있다면 사전순으로 정렬된다.
Sorted Set 의 연산은 대부분 log(N) 의 시간 복잡도를 가져 매우 빠르다. 새로운 데이터를 삽입하는 것이나 특정 문자열의 등수를 조회하는 것, 범위 안의 데이터를 조회하는 것 등의 연산을 지원한다.
로직
RDB 를 사용할 때와 비슷하게 각 user에 대해 Sorted Set 에 user id와 점수를 0으로 넣어둔다. 점수를 수정할 때는 Sorted Set의 score 를 수정한다.
랭킹을 가져올때는 Redis 와 RDB 를 같이 써야한다. 왜냐하면 Redis에는 user id 와 점수만 존재 하기 때문에 닉네임이나 프로필사진 같은 부가 정보는 DB 에서 가져와야한다.
Redis는 Sorted Set 을 사용했기 때문에 삽입될 때 정렬된 상태를 유지해 저장된다. 때문에 랭킹을 조회할때 마다 전체 데이터를 정렬할 필요가 없다.
테스트 준비
프로젝트를 알아 보았으니 테스트는 어떤 환경에서 진행하고 어떤 방식으로 진행했는지 설명하도록 하겠다.
테스트 환경
테스트 환경을 선택하는 것에도 고민이 있었다. 로컬에서 테스트 하는 것과 실제 운영중인 서버와 비슷한 클라우드 환경에서 테스트 하는 것이 고민되었다.
사실 좀 빠르게 테스트하고 편의를 위해서는 로컬에서 서버와 DB, Redis를 띄어두고 하는 것이 제일 간편했다. 하지만 테스트 해보니까 속도 들이 너무 빨랐다. 이유는 다음과 같다.
- 우선 동일한 컴퓨터안에서 통신하니 네트워크 부하가 없었다.
- 서버들의 성능이 현재 운영중인 서버보다 성능이 좋았다.
- 왜냐하면 맥북 프로에서 테스트 했기때문에 클라우드의 t2.small 이런것과 비교도 안되게 성능이 좋았다.
그래서 결국 운영중인 서버환경과 비슷한 클라우드 서버를 빌려 실험 해보기로 했다.
클라우드 스펙
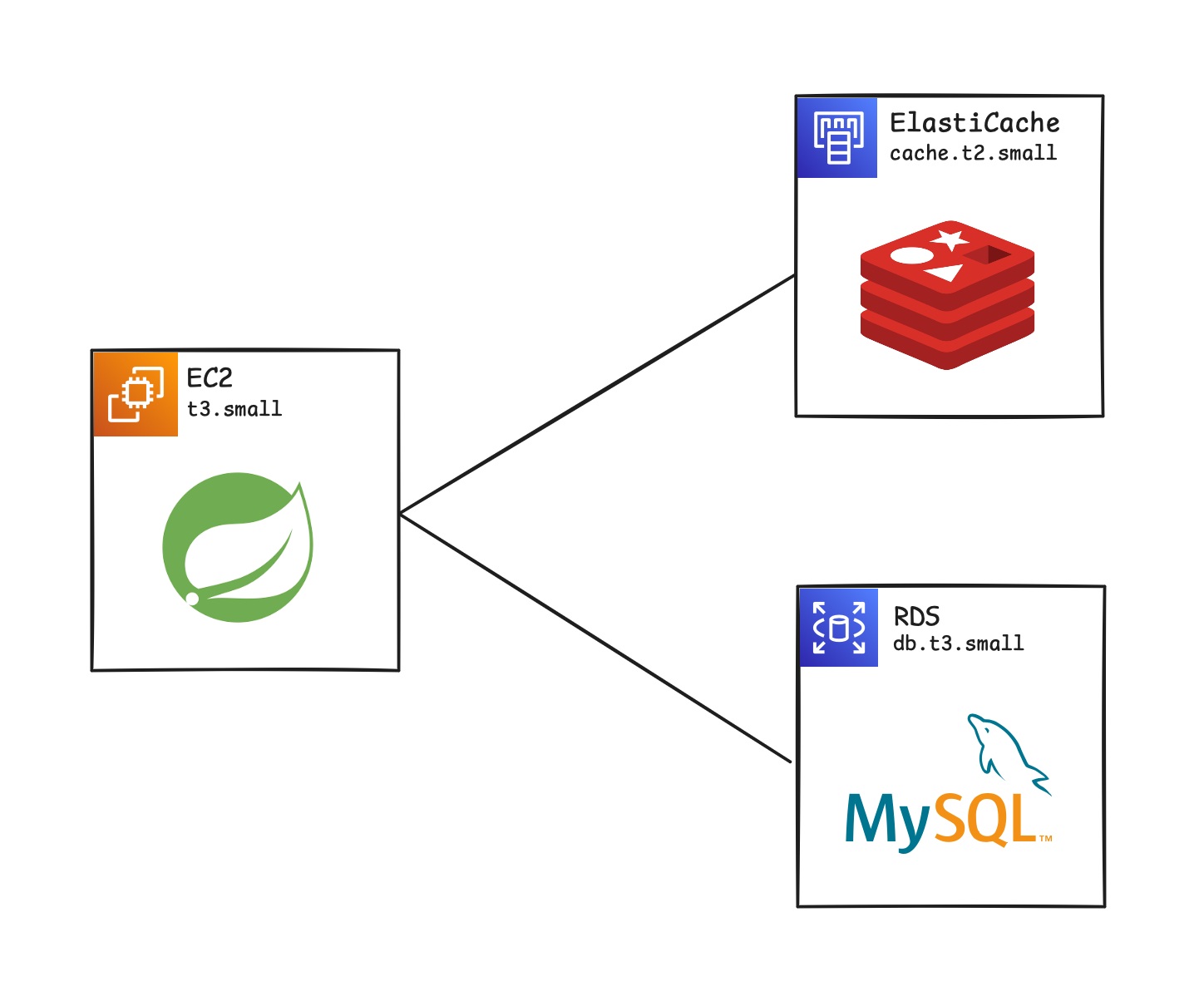
서버 스펙들은 다음과 같다.
- EC2 : t3.small
- RDS : db.t3.small
- ElastiCache : cache.t2.small
테스트 방법
테스트는 RDB, Redis 각각 저장된 user 수에 따라 응답속도를 체크해보고자 하였다. user 수를 증가시키며 속도를 체크했다. 즉 user 가 100명 있을 때, 300명 있을 때, 1,000명 있을때 이런 식으로 체크 했다.
요청을 한번만 보내는 것은 정확도가 떨어진다고 판단하여 각 user의 수 마다 여러번의 요청을 보내기로 하였다. Jmeter 를 사용했다. 스레드 세팅은 다음과 같다.
- Number of Threads : 200
- Ramp-up-period : 5
- Loop Count : 3
실제 서버 상황과 비슷하게 맞추기 위해 단순하게 600번을 쏘는 것이 아닌 어느 정도 부하를 주어 테스트 해보기로 했다.
테스트 자동화
user 의 수를 5개 정도만 테스트 해볼 것이 아니고 많은 상황에서 테스트 할 계획이다. 그 때 마다 일일이 손으로 테스트 user를 채우고 Jmeter 를 누를 순 없다. 그래서 버튼 하나로 자동화 할 수 있도록 만들었다.
User 수
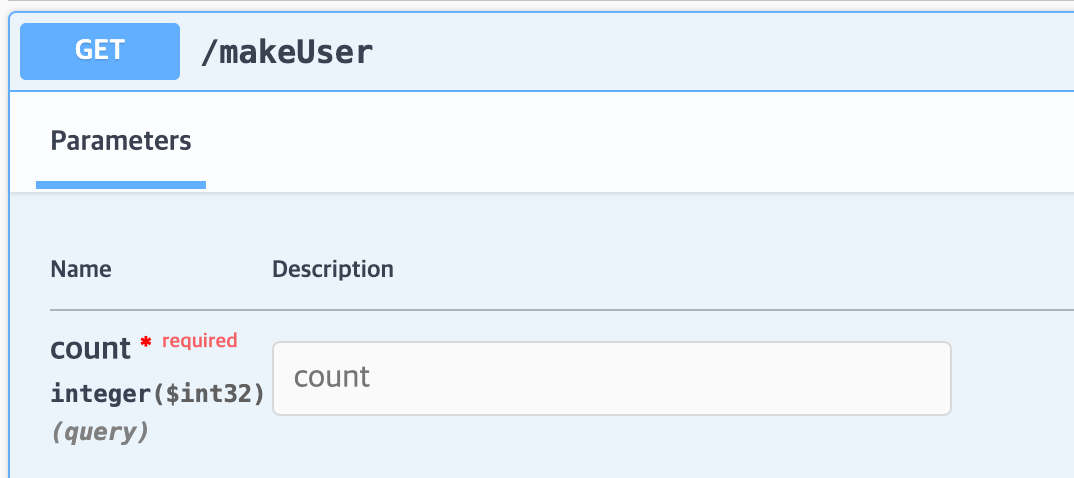
먼저 user 의 수를 채울 수 있는 api를 만들어 두었다. 이 api에 만들고 싶은 user 이 수를 넣으면 자동으로 user를 DB에 저장하고 Redis와 leaderboard 테이블에 점수를 랜덤값으로 넣어둔다.
Jmeter
jmeter는 GUI 외에도 CLI 로도 작동시킬 수 있다. 그러기 위해서는 jmeter 설정 파일을 만들어야한다.
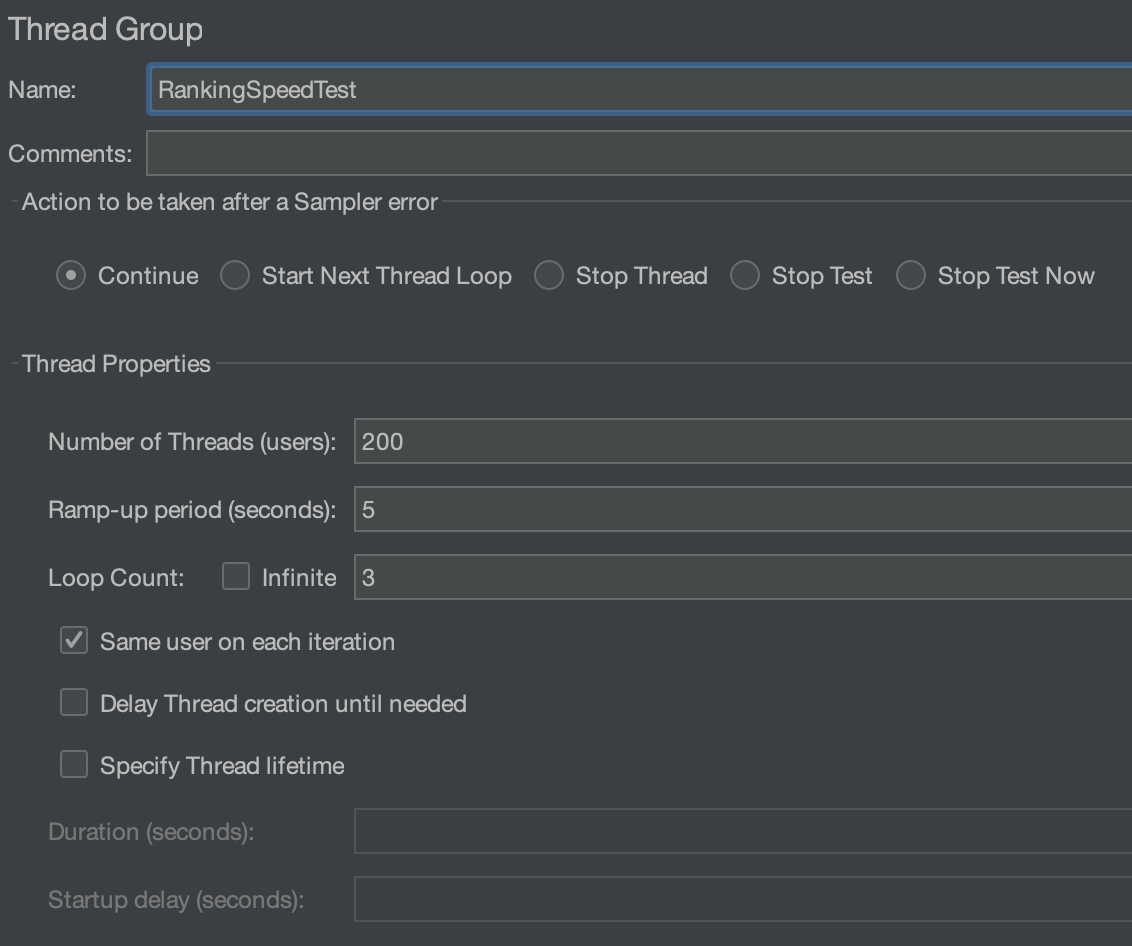
위 같은 GUI 를 통해 테스트 할 설정 파일을 만들수 있다. 나는 RDS, Redis 각각 만들었다.
jmeter -n -t "path/wher/your.jmx" -l "/path/your/result.csv"위 명령어로 실행 시킬 수 있다.
Shell script
CLI 로 실행가능하다는 것은 Shell 스크립트를 쓸 수 있다는 것을 의미한다!! 그래서 나는 shell 스크립트로 자동화 스크립트를 짜서 실행시켰다.
#!/bin/bash
user_count=100
for (( i=100; i<=2000; i+=100 ))
do
create_count=$i
user_count=$((user_count + create_count))
# user 생성
echo "\n----------------------유저 생성하는 중-----------------------"
curl -X 'GET' \
"http://3.38.191.213:8080/makeUser?count=${create_count}" \
echo -e "\n----------------------유저 생성 완료-----------------------"
sleep 3
# all_ranking_rdb
echo -e "\n----------------------all_ranking_rdb-----------------------"
jmeter -n -t "/Users/koomin/development/jmeter/ranking_speed_test/all_ranking_rdb.jmx" -l "/Users/koomin/development/jmeter/ranking_speed_test/rdb/all_ranking/all_ranking_rdb_${user_count}.csv"
sleep 3
# all_ranking_redis
echo -e "\n----------------------all_ranking_redis-----------------------"
jmeter -n -t "/Users/koomin/development/jmeter/ranking_speed_test/all_ranking_redis.jmx" -l "/Users/koomin/development/jmeter/ranking_speed_test/redis/all_ranking/all_ranking_redis_${user_count}.csv"
sleep 3
done이런 식으로 user 의 수를 증가 시키면서 테스트를 실행하게 자동화 해두었다. 이 많은 경우를 일일이 손으로 테스트 했다면 중간에 그만 두었을 것이다.
여기 까지 읽느라 수고 많았다. 드디어 Redis vs RDB 의 결과를 확인하자!!
결과
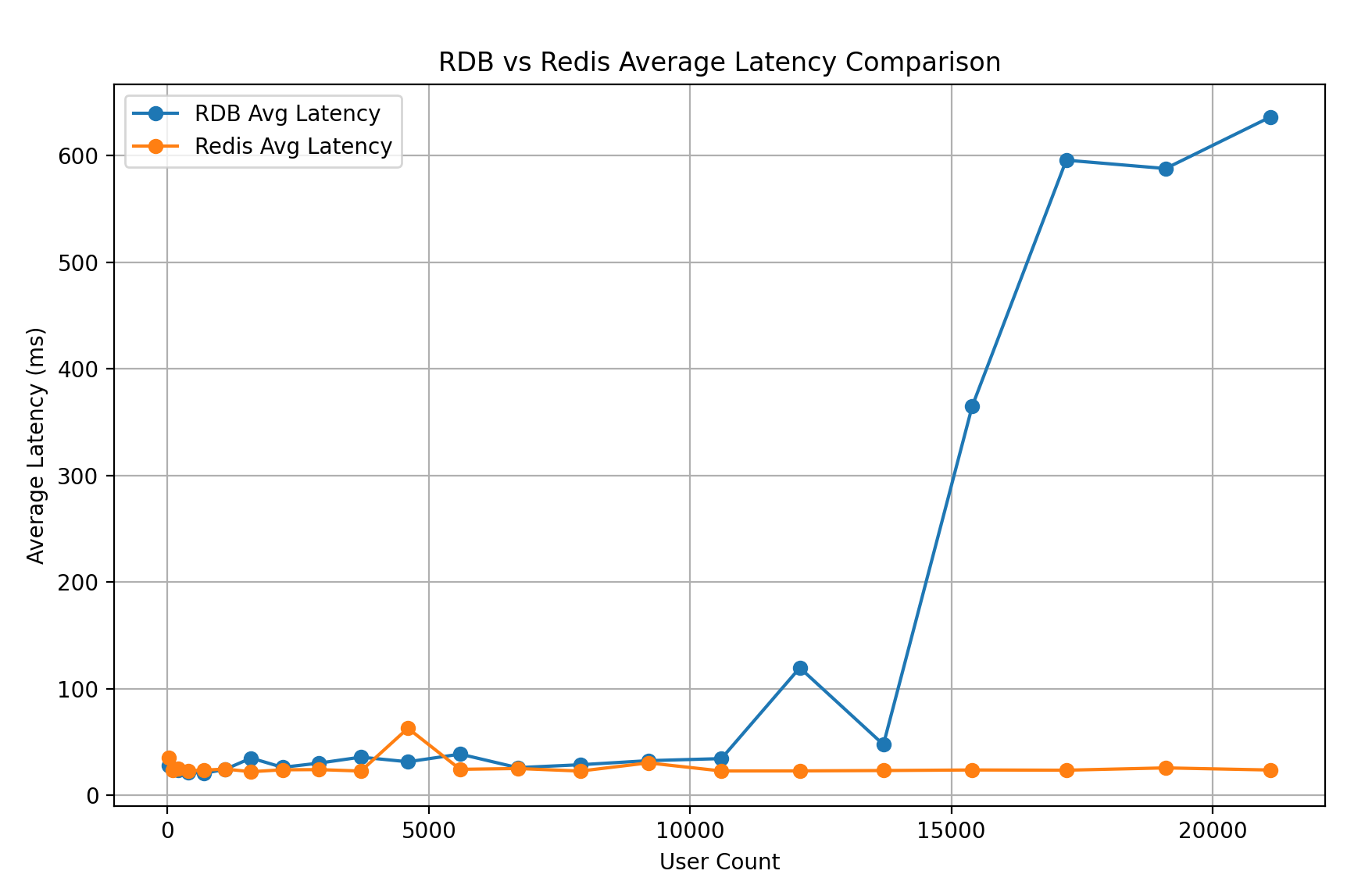
위 그래프와 같은 결과가 나왔다. 파란색이 RDB 를 연결한 테스트, 주황색이 Redis를 연결한 테스트이다. 그래프를 보면 알 수 있듯이 차이는 극명하게 난다. 약 10,000 명의 유저 수를 넘어가는 순간 RDB 쪽의 평균 응답 속도가 급작스럽게 올라가는 것을 볼 수 있다.
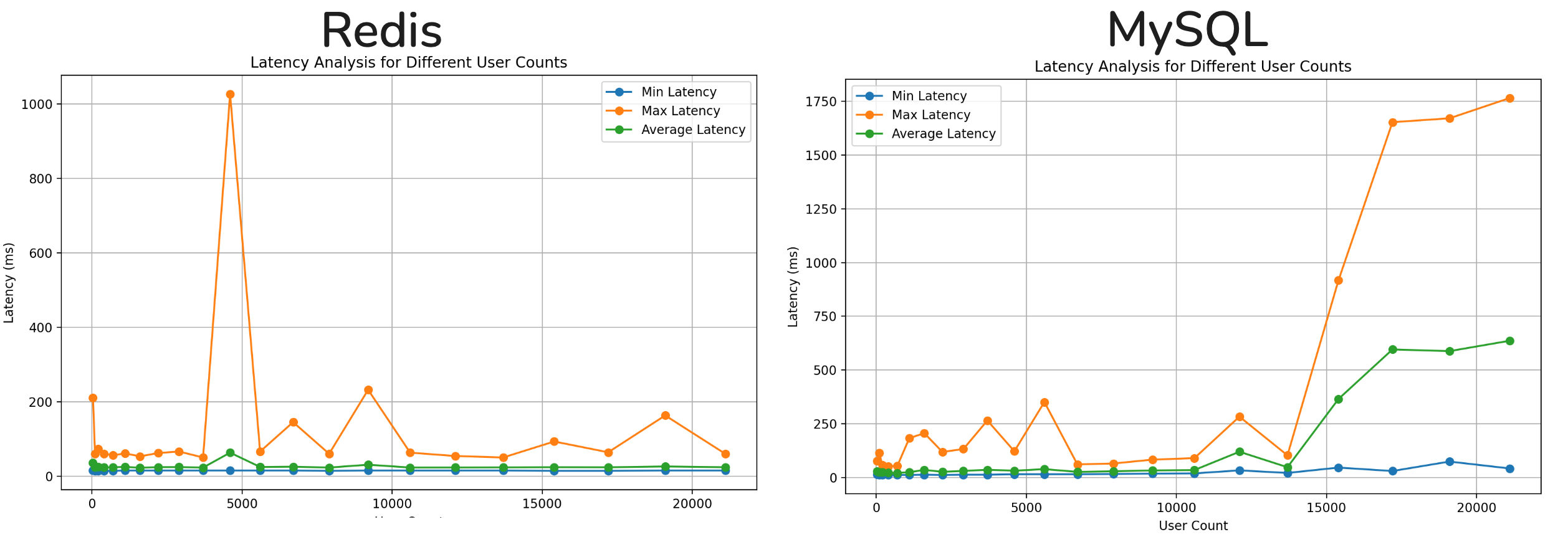
아래 그래프는 RDB, Redis 의 경우에서 얻은 평균 응답속도, 최소 응답 속도, 최대 응답 속도를 나타낸 그래프이다. 최대 응답 속도의 경우는 네트워크 문제등의 이유로 값이 일정하지 않고 튀는 모습을 볼 수 있다.
Redis
Redis 의 경우 Sorted Set 을 사용했기 때문에 유저수가 많아져도 응답속도에 차이가 없는 것을 볼 수 있다. 왜냐하면 Sorted Set 의 연산 속도가 Log(n) 으로 데이터가 많아지더라도 빠른 시간에 처리 할 수 있기 때문이다. 따라서 정렬해야 할 유저수가 적든 많든 비슷한 속도를 보여주었다.
RDB
RDB 의 경우는 10,000 명 까지는 비슷한 처리 속도를 보여주었지만 10,000 명 이 넘어가는 시점부터 응답 속도가 급작스럽게 증가한다. RDB의 경우에는 매 요청마다 테이블에 저장된 점수를 정렬하여 반환해야하기 때문에 확실히 Redis 보다는 부하가 더 걸리는 것을 확인 할 수 있었다.
아마 내가 예상하기로는 10,000 명부터 응답속도가 올라간 이유는 RDS 서버의 성능 때문이지 않을까 생각이 된다. 10000명이 넘어서부터 메모리에 캐싱 해둘 공간이 부족하거나 처리량을 따라가지 못하여 증가한 것이라고 생각된다. RDS 의 하드웨어 성능을 높이면 10,000 이 아니라 그 보다 위에서 응답 시간이 증가하지 않을까 생각된다.
결론
10,000명 이하의 유저 수를 대상으로 RDB와 Redis의 평균 응답 속도를 비교한 결과, 두 시스템 간의 성능 차이가 거의 없다는 것을 확인할 수 있다. 따라서 유저 수가 10,000명 미만이라면 RDB를 사용해도 성능상 큰 차이를 느끼기 어려울 것이다.
물론 이번 테스트는 랭킹 API 호출에만 집중했으며, 실제 서비스 환경처럼 다양한 작업이 동시에 이루어지지는 않지만, 그럼에도 불구하고 유저 수가 많지 않은 경우에는 Redis를 사용하는 것이 오버 엔지니어링이라는 생각이 든다.
Redis를 사용하더라도 속도 차이는 미미하지만, Redis를 관리하는 데 추가적인 비용이 발생하기 때문에 유저 수가 적은 상황에서는 RDB를 사용하는 것이 더 효율적일 것이다.
그러나 유저 수가 많아지고 사용량이 증가하는 경우에는 Redis를 사용하는 것이 성능 면에서 유리할 수 있다. RDS의 하드웨어 성능을 높이는 것도 하나의 방법일 수 있지만, 성능을 높일수록 비용이 급격히 상승하게 된다. 비용을 무작정 증가시킬 수는 없기 때문에, 어느 정도 유저 수가 있는 상황에서는 RDB 대신 Redis를 사용하는 것이 최선의 방법이라고 생각한다.
한계
20,000만명 까지만 테스트 해보았기 때문에 20,000만명 보다 많은 사용자에서 Redis 가 버텨줄지는 테스트 해보지 못했다.
그리고 내가 테스트한 환경에 대한 결과이기 때문에 모든 환경에서 같은 결과가 나온다고 보장할 수 없다. 같은 RDB 를 사용해도 인덱스나 쿼리 튜닝에 따라 더 결과가 좋아질 수도 있다. 때문에 위 결과를 맹신하지 말고 구현하려는 환경에 따라 선택하는 것이 좋을 것이라고 생각한다. 위 결과는 참고 정도만 하면 좋을 것 같다.
마무리
랭킹을 구현하려면 Redis 만을 사용해야한다고 머리속에 박혀있었는데 이번 테스트를 통해 살짝은 생각이 바뀐 것 같다. 일정 유저수 전까지는 RDB와 Redis 의 응답속도의 차이가 거의 없었기 때문에 무조건 Redis 를 사용해야하는 것은 없다고 느꼈다.오히려 프로젝트 상황에 맞는 기술을 잘 선택하는 것이 중요하다고 느껴졌다.
지금은 우리 프로젝트 환경에 대해서 테스트도 안해보고 Redis를 사용해 구현하였다. 하지만 다음 부터는 기술을 선택할 때는 테스트도 해보고 여러 방면에서의 고민을 통해 우리 프로젝트 상황에 맞는 기술을 선택해야겠다.

혹시 leaderboard user_id에 index는 걸려있는 상태였을까요?