
지난 포스팅에서 그라운드 플립 서버의 부하테스트를 진행해보았다. t3a.small 서버 한대로 부하를 걸었을 때 동시접속자 230명 까지가 안정적인 응답속도를 보여주었었다.
이번 글에서는 스케일 업과 스케일 아웃을 직접 적용 해보며 최대로 받을 수 있는 부하가 늘어나는지 테스트 해보려한다.
지난 부하테스트 결과
스케일 업과 스케일 아웃에 앞서 지난 포스팅에서의 결과를 복기 하고 시작하려한다.
테스트 환경
- EC2 : t3.small
- RDS : db.t3.small
- ElastiCache : cache.t2.small
ec2 한대로 테스트를 진행하였다.
테스트 결과
| 동시접속자수 | 평균 응답 속도 | CPU 최대 사용량 | DB 최대 사용량 | Redis 최대 사용량 | 에러 비율 |
|---|---|---|---|---|---|
| 30명 | 16.96 ms | 18.6 % | 11 % | 3.72 % | 0 % |
| 60명 | 16.12 ms | 32.5 % | 6.83 % | 4.73 % | 0 % |
| 100명 | 18.12 ms | 46.6 % | 9.37 % | 5.91 % | 0 % |
| 130명 | 18.92 ms | 66.2 % | 10.5 % | 6.7 % | 0 % |
| 160명 | 18.81 ms | 72.3 % | 12.6 % | 7.31 % | 0 % |
| 190명 | 23.15 ms | 83.9 % | 12.9 % | 8.13 % | 0 % |
| 200명 | 29.5 ms | 89.7 % | 13.2 % | 8.33 % | 0 % |
| 230명 | 119.61 ms | 95.5 % | 14.1 % | 8.5 % | 0 % |
| 250명 | 310.10 ms | 95.9 % | 17.4 % | 8.62 % | 0.69 % |
동시접속자 약 230명까지 안정적인 응답속도를 보여주었다. 230명이 넘어가는 시점 부터 서버의 CPU 사용량이 99%를 넘어가며 응답속도가 느려지고 요청을 처리하지 못하여 에러 비율이 많아졌었다.
과연 스케일 업과 스케일 아웃을 적용하면 최대로 받을 수 있는 부하가 높아질지 지금 바로 알아보자.
스케일 업
먼저 해볼 작업은 스케일 업이다. 아무래도 스케일 아웃 보다는 설정하는 과정이 간단하기 때문에 먼저 하려고한다.
스케일 업이란?
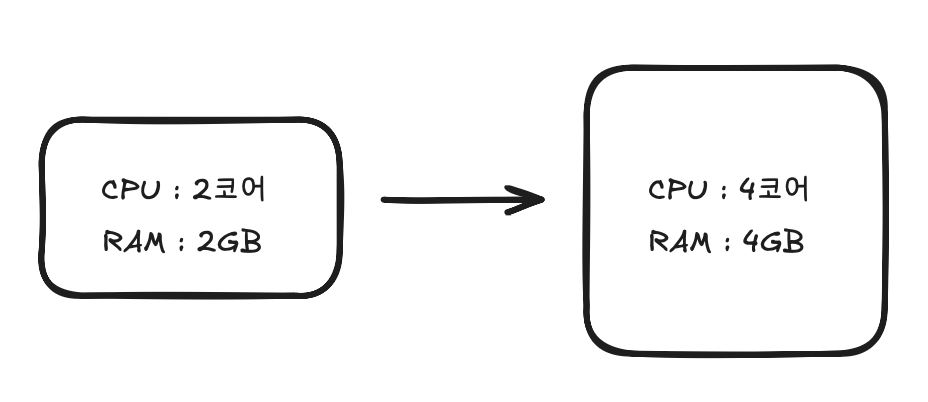
스케일 업이란 서버에 CPU 나 RAM 등의 하드웨어 스펙을 추가하여 고성능의 서버로 교환하는 방법을 말한다. 비교적 간단하고, 관리가 용이한 장점이 있는 방면, 하드웨어 교체를 위해 서비스를 중단해야한다는 단점이 있는 방법이다.
테스트 시작!
아래는 우리가 현재 사용하고 있는 ec2 인스턴스인 t3a의 스펙표이다.
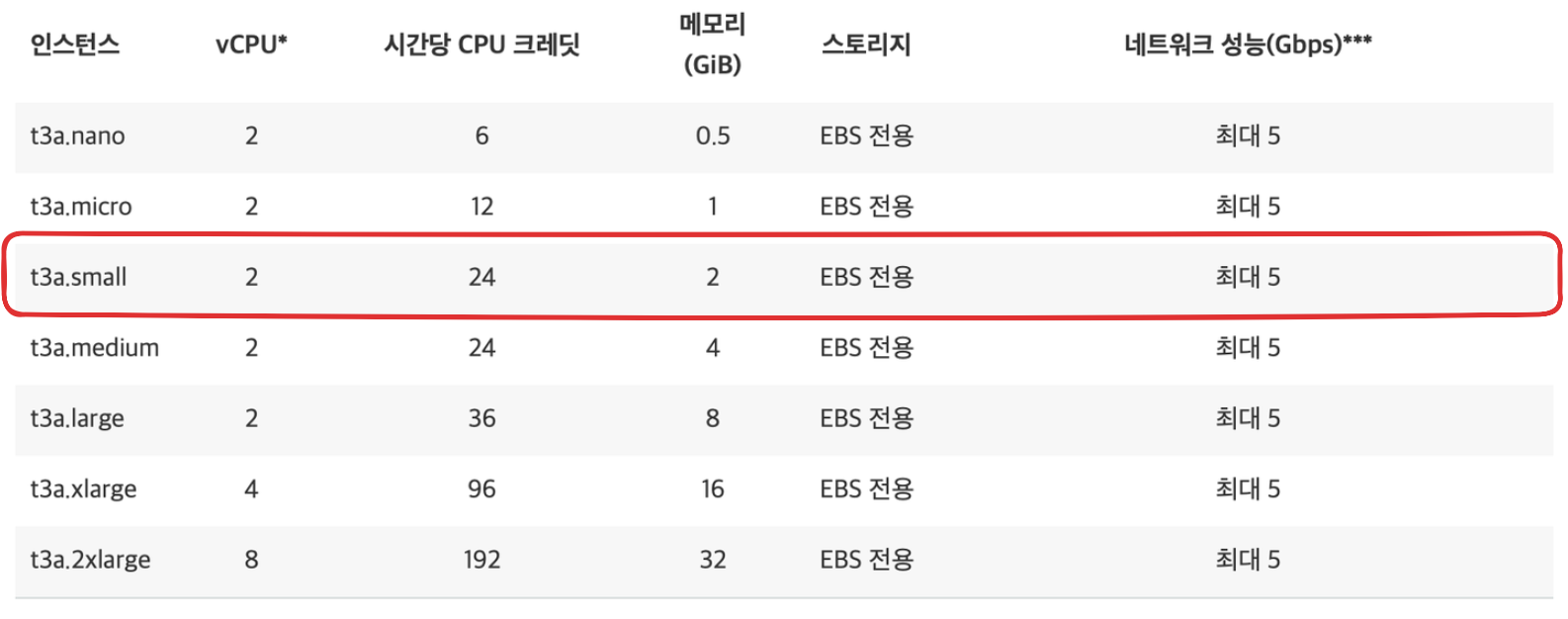
현재 우리는 t3a.small 을 사용하고 있기 때문에 t3a.small 보다 좋은 인스턴스인 t3a.medium, t3a.large 를 사용하여 테스트를 하였다.
t3a.medium
t3a.medium 은 t3a.small 과 cpu 성능은 동일하지만 메모리가 4GB 로 2배 차이가 난다. 메모리가 올라가면 처리할 수 있는 양이 많아지는지 테스트 해보았다.
결과
| 동시접속자수 | 평균 응답 속도 | CPU 최대 사용량 | DB 최대 사용량 | Redis 최대 사용량 | 에러 비율 |
|---|---|---|---|---|---|
| 100명 | 20.9 ms | 46.5 % | 9.4 % | 5.8 % | 0 % |
| 160명 | 18.28 ms | 68 % | 11 % | 7.54 % | 0 % |
| 190명 | 27.12 ms | 85 % | 12.9 % | 8.46 % | 0 % |
| 200명 | 486.42 ms | 100 % | 12.7 % | 6.5 % | 0 % |
분석
메모리 용량을 올리는 것으로는 기존의 t3s.small 과 거의 차이가 나지 않는다. 이는 기존 스펙에서 문제점이 메모리는 아니라는 점을 알 수 있다.
t3a.large
t3a.large는 t3a.small 에 비해 cpu 성능과 메모리 성능 둘다 업그레이드된 버전이다. 시간당 cpu 크레딧 사용량이 36 으로 1.5배 차이가 난다. 하지만 코어 수 자체는 증가하지 않아 큰 성능 향상은 없을 것으로 예상된다.
결과
| 동시접속자수 | 평균 응답 속도 | CPU 최대 사용량 | DB 최대 사용량 | Redis 최대 사용량 | 에러 비율 |
|---|---|---|---|---|---|
| 190명 | 25.11 ms | 84.6 % | 12.4 % | 8.14 % | 0 % |
| 200명 | 24.76 ms | 86.1 % | 12.6 % | 8.42 % | 0 % |
| 230명 | 80.25 ms | 94.9 % | 13.9 % | 8.54 % | 0 % |
| 250명 | 147.37 ms | 96.7 % | 14.2 % | 8.69 % | 0 % |
| 270명 | 249.27 ms | 96.6 % | 14.1 % | 8.93 % | 0 % |
| 300명 | 316.66 ms | 98.3 % | 14 % | 9.03 % | 12 % |
분석
기존 t3a.small 은 250명에서 에러가 발생하였는데 t3a.large 는 300명 까지 가야 에러가 발생하는 것을 확인 할 수 있다. 시간당 cpu 크레딧 사용량이 늘어서 기존 보다는 많은 양의 요청을 처리 할 수 있는 것으로 보인다.
실제 cpu 코어 수도 늘어나는 t3a.xlarge 를 사용하면 좀 더 많은 처리율을 보여 줄 것이라고 생각된다.
스케일 업에 대해서
지금 까지 스케일 업을 했을 때의 성능 차이를 테스트 해보았다. 나는 이번 테스트를 통해서 스케일 업은 비효율적이라고 느꼈다. 이유는 가격이다. 아래 가격 표를 살펴보자.
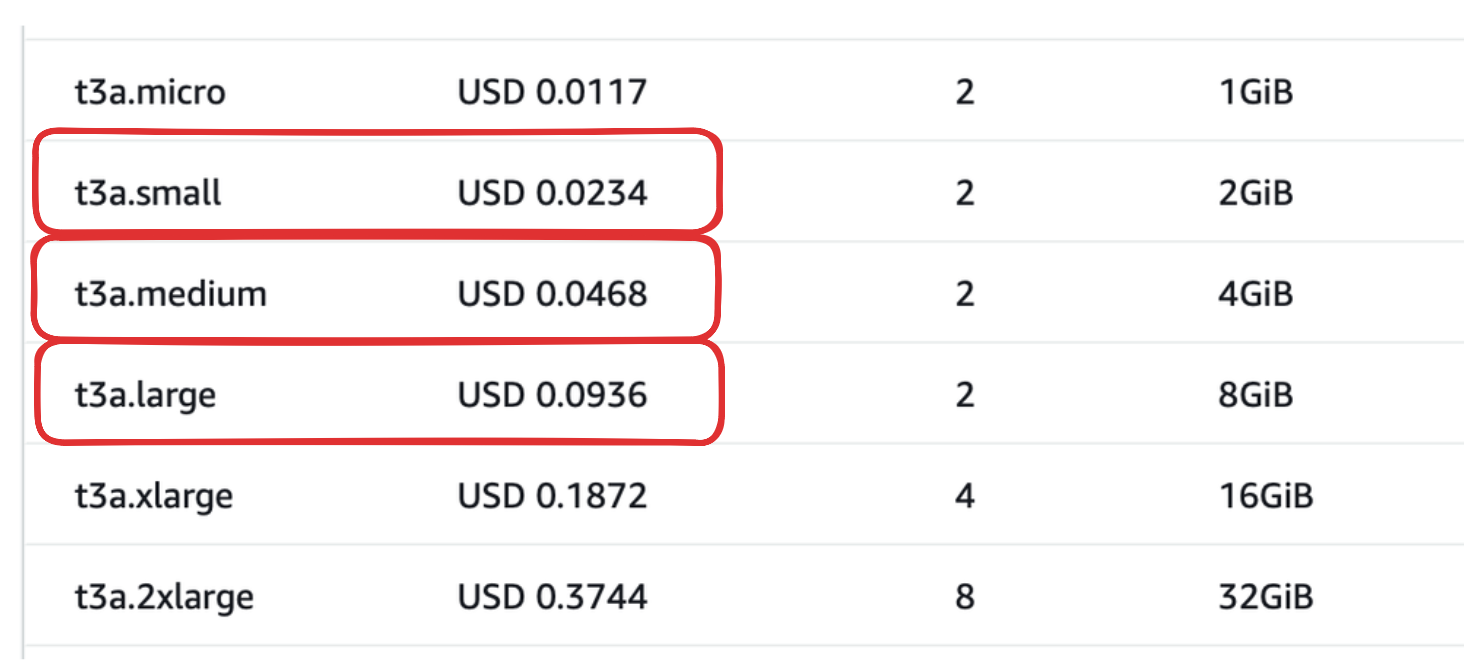
가격표를 살펴보면 medium 은 small의 2배, large는 small 의 4배 차이가 난다. 하지만 성능은 금액이 올라가는 만큼 상승되지 않았다. medium 의 경우에는 가격이 2배 차이가 남에도 불구하고 성능은 기존과 거의 동일하다. large 는 4배 차이가 나는데에도 불구하고 성능은 2배도 좋아지지 않았다.
스케일 아웃
이번에는 스케일 아웃을 적용하여 테스트를 해보았다. 스케일 아웃을 적용하는 것은 스케일 업에 비해서는 비교적 복잡했다.
스케일 아웃이란?
스케일 아웃은 스케일 업과 다르게 서버의 개수를 늘려서 처리 능력을 개선 시키는 방법이다. 서버의 수를 유연하게 조정 할 수 있고, 서비스가 커짐에 따라 확장성이 뛰어난 장점이 있다. 단점으로는 서버가 많아질 수록 네트워크가 복잡해지고 유지 관리 비용이 증가한다는 것이다.
스케일 아웃을 적용한 방법
스케일 아웃을 적용하는 여러 가지 방법이 있겠지만, 나는 aws의 로드 밸런서를 사용하여 적용했다.
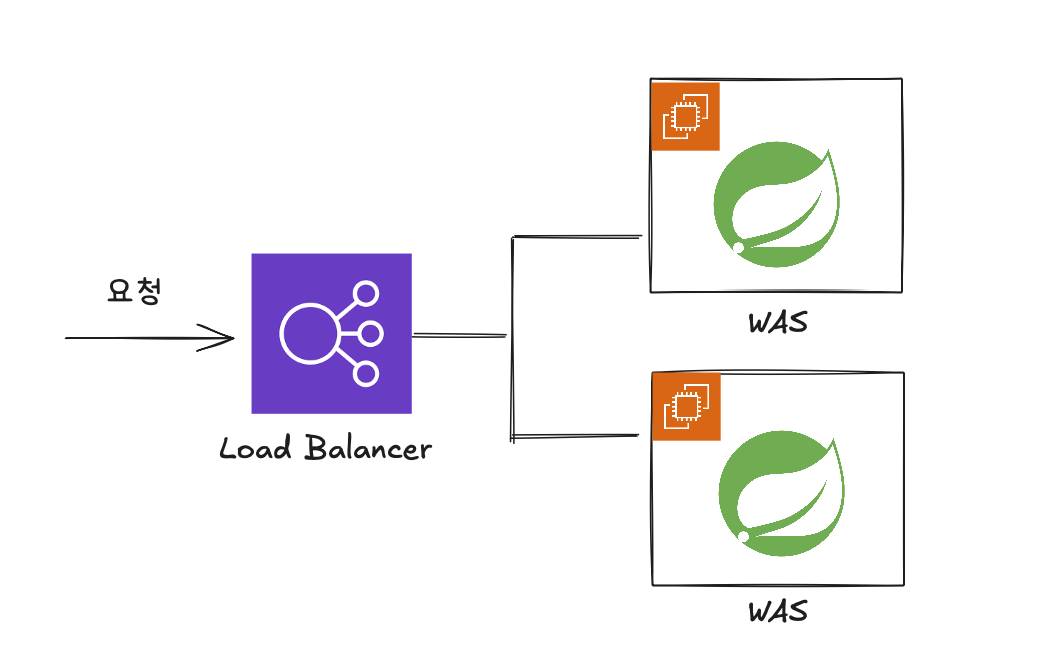
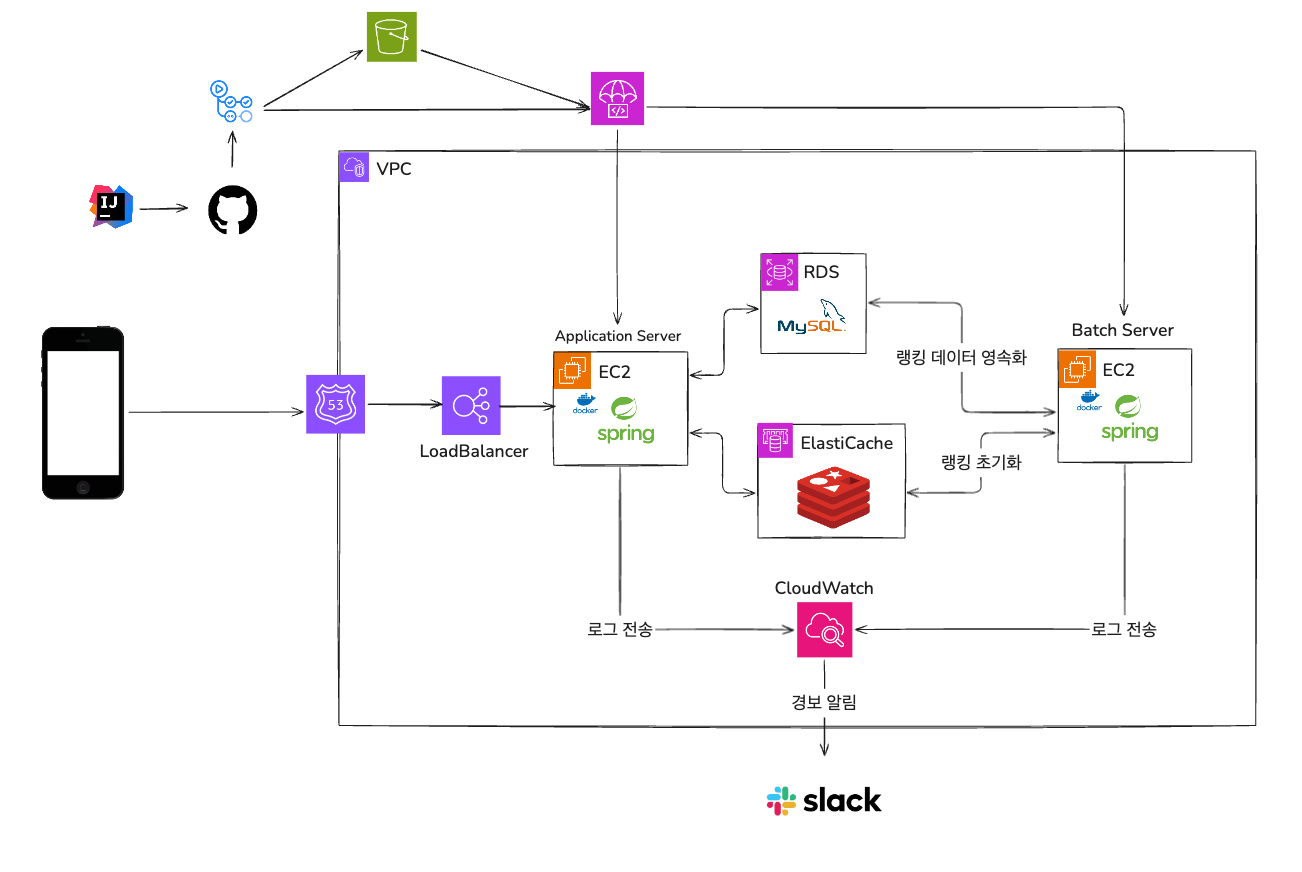
위 그림과 같이 ec2 서버 앞단에 Load Balancer 를 위치 시켰고 로드 밸런싱 대상 그룹에 만들어둔 ec2 2개를 연결 시켜 적용하였다.
사실 원래 하나의 서버의 CPU 사용량이 50% 가 넘어가면 오토 스케일링 처리를 해두었다. 하지만 이렇게 되면 처음부터 서버가 여러개 켜진 상태에서 테스트가 안되기 때문에 미리 서버 2대를 준비해두고 테스트를 진행하였다.
인스턴스는 기존에 사용중이던 t3a.small 2대를 사용하였다.
결과
| 동시접속자수 | 평균 응답 속도 | 서버1 CPU 최대 사용량 | 서버2 CPU 최대 사용량 | DB 최대 사용량 | Redis 최대 사용량 | 에러 비율 |
|---|---|---|---|---|---|---|
| 130명 | 16.36 ms | 33.7 % | 34.8 % | 10.1 % | 6.39 % | 0 % |
| 160명 | 18.59 ms | 39 % | 41.2 % | 12.6 % | 7.33 % | 0 % |
| 190명 | 17.78 ms | 44.4 % | 47.8 % | 12.4 % | 8.03 % | 0 % |
| 200명 | 17.61 ms | 47.3 % | 48 % | 12.8 % | 8.31 % | 0 % |
| 230명 | 17.97 ms | 49.8 % | 52 % | 14.2 % | 8.93 % | 0 % |
| 250명 | 19.58 ms | 52.7 % | 54.7 % | 14.5 % | 9.37 % | 0 % |
| 270명 | 17.10 ms | 57.7 % | 60.1 % | 15.1 % | 10 % | 0 % |
| 330명 | 22.57 ms | 68.4 % | 69.7 % | 17.1 % | 11.5 % | 0 % |
| 360명 | 22.17 ms | 73.4 % | 72.3 % | 19.1 % | 12.3 % | 0 % |
| 390명 | 25.12 ms | 75.6 % | 79.6 % | 19 % | 12.9 % | 0 % |
| 430명 | 23.82 ms | 81.1 % | 82.7 % | 19.8 % | 13.4 % | 0 % |
| 490명 | 83.76 ms | 91.4 % | 91.1 % | 21.8 % | 13.7 % | 0 % |
| 500명 | 300.03ms | 96.7 % | 97.5 % | 18.3 % | 11.7 % | 57.6 % |
그래프

결과 분석
평균 응답 속도
평균 응답 속도를 확인 해보면 약 490 명 정도 까지는 83.76ms 로 안정적인 응답 속도를 보여주는 것을 확인 할 수 있다. 서버 1대를 사용했을 때는 230명 ~ 250명 정도 까지 안정적이었던 것을 보면 약 2배 정도의 요청을 안정적인 속도로 처리 할 수 있음을 볼 수 있다.
서버 CPU 사용량
두 서버의 CPU 사용량을 보면 거의 비슷한 사용량으로 증가하는 것으로 보아 로드 밸런싱이 잘되고 있는 것을 확인 할 수 있었다. 하나의 서버에서 처리하던 요청들이 다른 서버로 분산되어 처리량이 증가한 것을 알 수 있다.
DB / Redis 사용량
DB 와 Redis 사용량은 서버의 개수에는 영향을 받지 않고 요청의 개수에 따라서 증가한다. 서버에서 처리할 수 있는 양이 늘어 더 많은 요청이 DB 와 Redis 까지 전달되어 사용량이 서버 1개를 사용 할 때 보다는 더 증가 했음을 알 수 있다.
그럼에도 두 서버의 사용량이 30%를 안넘는 것을 보다 DB 와 Redis 는 아직 여유롭다고 판단된다.
가격
이번 스케일 아웃에서는 t3a.small 인스턴스를 2개를 사용하였기 때문에 기존에 비해 비용이 2배로 증가한다. 하지만 스케일 업과는 다르게 비용이 2배 증가한 만큼 성능도 2배로 증가한 것을 확인 할 수 있었다.
스케일 업 VS 스케일 아웃
지금 까지 스케일 업과 스케일 아웃 모두 적용해보고 테스트를 진행해보았다. 내 테스트 결과로는 스케일 아웃이 스케일 업보다 더 적절한 방법이라고 생각이든다. 이유는 다음과 같다.
1. 가격 대비 성능
스케일 업의 경우 가격이 2배, 4배로 올라도 하드웨어 성능이 크게 향상되지 않아서 가격 대비 요청 처리 능력이 좋지 않았다. 반면, 스케일 아웃은 가격을 2배로 늘려 서버 2개를 사용하면 요청 처리량이 거의 2배로 올라갈 만큼 효율이 좋았다.
또한 스케일 업은 사용자가 줄어들면 리소스가 그대로 낭비되지만, 스케일 아웃은 사용하지 않는 서버를 중지시키면 되기 때문에 필요한 경우에만 비용을 늘릴 수 있어 훨씬 효율적이다.
2. 다운타임
스케일 업은 인스턴스 스펙을 변경하려면 서버를 중단해야 했다. 그 사이 서비스가 멈추는 심각한 문제점이 있었다. 하지만 스케일 아웃은 기존 서버를 그대로 둔 채 새로 생성된 서버에 트래픽을 분산시키면 되기 때문에 다운타임이 발생하지 않았다.
3. 확장성
스케일 업은 접속자가 늘어난다고 무한히 하드웨어 스펙을 올릴 수는 없다. 하드웨어 성능에는 한계가 있기 때문이다. 반면 스케일 아웃은 접속자 수가 늘어나는 만큼 서버를 증설해서 부하를 분산시켜 처리할 수 있기 때문에 더 효율적이다. 물론 서버를 무한히 증설할 수는 없겠지만, 스케일 업에 비하면 훨씬 더 확장성이 좋다.
단점으로는 스케일 아웃의 경우 분산처리와 복잡성 때문에 유지 관리가 복잡해지긴한다. 하지만 이 관리비용이 스케일 업 할 때의 비용보다는 효율적이라고 느껴지기 때문에 스케일 아웃이 더 적절하다는 생각이 들었다.
마무리
이상으로 부하테스트를 전부 마쳤다. 이렇게 서버를 여러대 빌려서 테스트 하는 것은 비용이 많이 드는 작업이지만 소프트웨어 마에스트로 지원비 덕분에 대학생 수준에서는 쉽게 해볼 수 없는 실험을 해볼 수 있어서 의미있는 시간이었던 것 같다.
스케일 업과 스케일 아웃 같은 경우는 기존에는 이론으로만 알고 실제로 적용하여 성능이 향상되는 것은 확인 할 수 없었는데 이번 기회를 통해 실제로 적용해보고 결과를 확인 할 수 있어 좋은 경험이었다.
