이번 포스팅 역시 한국어 웹으로 되어있는 자료가 거의 없어서 작정하는 포스팅이다. 이번 글에서는 STDP를 사용하여 SNN이 비지도 학습하여 MNIST 데이터셋을 분류할 수 있는 학습 과정에 대해서 간단하게 알아본다.
본 블로그는 학생이 직접 공부하고 남기는 기록으로써 잘못된 내용이 있다면 댓글 달아주시면 감사하겠습니다.
이번 포스팅은 더더욱 그저 제 이해만으로만 적은 글이기 때문에 그럴 수 있습니다....
1. 포아송 인코딩(Possion Encoding)
SNN은 알다시피 각 뉴런의 전도에 대해서 시간 차이가 존재한다. 이미지를 시간당 스파이크가 발생하는 형태로 이미지를 입력해야하는데, 그러기 위해서는 우선 이미지의 각 픽셀을 각 뉴런의 스파이크 발생 빈도로 나타내야 한다.
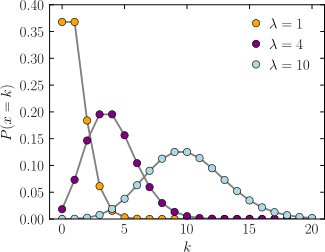
이 과정에서 Possion Distribution을 사용한다.
Possion Distribution이란?
단위 시간 내에 어떤 사건이 발생할 횟수를 확률변수로 가지는 확률 분포이다. 다음은 푸아송 분포의 확률질량함수는 다음과 같다.
위 식에서 는 시퀀스의 발생 횟수를 뜻하고 에는 픽셀의 밝기를 뜻하며 는 사건이 번 발생할 확률을 뜻한다.
푸아송 인코딩에서는 각 픽셀의 밝기가 위의 에 할당되어 시간당 스파이크가 몇번 발생할지에 대한 확률 분포가 나타나고 그 확률을 기반으로 랜덤으로 스파이크 발생 횟수를 결정하여 SNN의 입력층에 스파이크 시퀀스를 전달하게 된다.
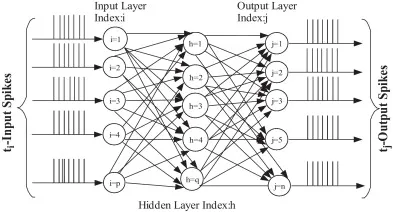
2. STDP를 사용한 SNN 비지도 학습
이미지가 시간당 스파이크의 발생 횟수로 출력층으로 전달된 후에는 초기에 랜덤으로 지정된 시냅스 강도 를 기반으로 입력을 SNN에 통과 시킨다. STDP의 개념에서 알 수 있듯이 LTP와 LTD를 이용해 출력층 뉴런이 어떤 숫자를 나타내도록 매핑하는 것이 아니라 출력층 뉴런의 출력이 각 숫자마다 비슷한 활동 전위 발생 양상을 띨 수 있도록 비지도 학습한다.
시냅스 강도의 변화는
- 시냅스 전 스파이크가 시냅스 후 스파이크보다 Δt만큼 먼저 발생할 때:
- 시냅스 후 스파이크가 시냅스 전 스파이크보다 Δt만큼 먼저 발생할 때:
STDP에 대해서 더 알아보고 싶다면 이전 포스팅을 참고하길 바란다.
링크 : https://velog.io/@koon_and_meme/STDPSpike-timing-dependent-plasticity%EB%9E%80
3. 뉴런의 출력을 기반으로 클러스터링
출력층 뉴런의 스파이크 시퀀스를 이용해 클러스터링을 진행한다.
4. 클러스터링 된 이미지 분류
예를들어 1부터 9까지의 숫자를 학습시켰다면 각 클러스터링 시킨 데이터 군집의 자료를 확인하고 각 군집이 어떤 숫자인지 확인한다
마무리
너무 공식 없이 어떤 식으로 학습하는지만 말했다. 다음 포스팅은 공식과 함께 나이브하게 구현한 SNN MNIST 분류기에 대해서 포스팅 해보겠다.
참고 문헌
- Unsupervided learing of digit recognition using spike-timing-dependent plasticity
- Improving multi-layer spiking neural networks by incorporating brain-inspired rules
- STDP-based spiking deep convolutional neural networks for object recognition
- Stochastic Spiking Neural Networks with First-to-Spike Coding
- Deep Learning in Spiking Neural Networks
