Big-O 표기법 (Big-O Notation)
빅오(Big-O) 표기법이란?
빅오 표기법은 알고리즘이 입력 데이터(n)가 커질 때, 실행 시간이나 메모리 사용량이 얼마나 빨리 증가하는지를 수학적으로 간단하게 표현하는 방법입니다. 즉, "데이터가 많아질수록 내 코드가 얼마나 느려질까?"를 한눈에 보여주는 지표입니다.
빅오 표기법의 핵심 특징
상한선(최악의 경우): 빅오는 "최악의 경우 이 정도 시간/공간이 걸린다"는 상한선을 나타냅니다.
상수와 영향력 없는 항 무시: 데이터가 아주 많아지면, 작은 수치(상수)나 영향력이 적은 항은 무시합니다.
시간 복잡도와 공간 복잡도: 주로 시간(실행 속도)에 쓰지만, 메모리 사용량(공간 복잡도)에도 적용할 수 있습니다.
빅오 표기법의 대표적인 예시와 비유
| 표기법 | 예시 코드/알고리즘 | 설명 및 일상 비유 |
|---|---|---|
| O(1) | 배열에서 인덱스로 값 찾기 | "냉장고에서 딱 정해진 위치에 있는 물건 꺼내기"처럼, 데이터 양과 상관없이 항상 같은 시간에 끝남 |
| O(log n) | 이진 탐색 | "책에서 원하는 페이지를 반씩 접으면서 찾기"처럼, 데이터가 두 배로 늘어도 몇 번만 더 찾으면 됨 |
| O(n) | for문 한 번 돌기 | "줄 선 사람 한 명씩 체크하기"처럼, 데이터가 두 배면 시간도 두 배 걸림 |
| O(n log n) | 퀵정렬, 병합정렬 | "여러 번 반씩 나누면서 전체를 훑어야 하는 상황" |
| O(n^2) | 이중 for문(버블정렬 등) | "모든 사람끼리 악수하기"처럼, 데이터가 두 배면 시간은 네 배 걸림 |
| O(2^n) | 피보나치 재귀, 모든 조합 탐색 | "모든 경우의 수를 다 해보기"처럼, 데이터가 조금만 늘어도 시간이 폭발적으로 증가 |
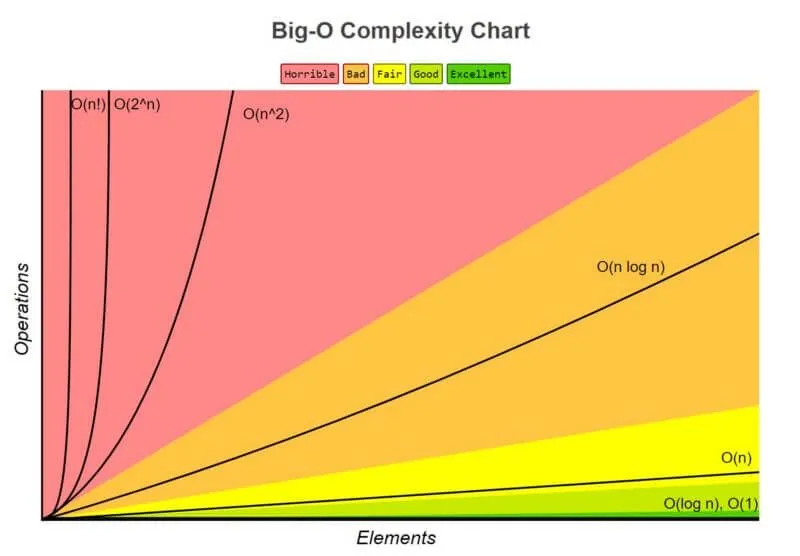
O(1) < O(log n) < O(n) < O(n log n) < O(n²) < O(2ⁿ) < O(n!) (오른쪽으로 갈수록 성능 나쁨)
시퀀스 자료구조
-
리스트
* 특징
- 대괄호[]를 사용하여 생성합니다.
- 다양한 데이터 타입(숫자, 문자열, 다른 리스트 등)의 객체 참조(메모리 주소)를 함께 저장할 수 있습니다.
- 요소의 추가, 삭제, 수정이 자유롭습니다.
*주요 연산 및 시간 복잡도 (동적 배열 구현 기준)
-
인덱싱: my_list[i] → O(1) (매우 빠름). 🔵 연속된 메모리 구조 덕분에 특정 위치의 주소를 바로 계산하여 접근할 수 있습니다.
-
슬라이싱: my_list[i:j] → O(k) (k는 슬라이스 길이). 슬라이스 길이만큼의 새로운 리스트를 생성하고 요소를 복사합니다.
-
길이 확인: len(my_list) → O(1). 🔵 리스트 객체 내부에 저장된 길이 정보(ob_size)를 바로 반환합니다.
-
요소 포함 확인: item in my_list → O(n) (선형 탐색). 🔴 처음부터 끝까지 요소를 하나씩 비교하며 찾아야 합니다.
-
맨 뒤에 추가: my_list.append(item) → 평균 O(1), 최악 O(n). 🔵 대부분의 경우, 미리 할당된 메모리 공간(allocated)의 끝에 요소를 추가하고 길이(ob_size)만 늘리면 되므로 O(1)입니다. 하지만, 공간이 꽉 차면 더 큰 메모리 공간을 새로 할당하고 기존 요소들을 모두 복사해야 하므로 드물게 O(N) (최악) 시간이 걸립니다. (이러한 메모리 재할당(resize) 전략 덕분에 평균적으로 O(1) 성능을 보입니다.)
-
특정 위치에 삽입: my_list.insert(i, item) → O(n). 🔴 지정된 위치(i) 이후의 모든 요소들을 메모리상에서 한 칸씩 뒤로 밀어야 삽입할 공간을 확보할 수 있습니다.
-
맨 뒤 요소 삭제: my_list.pop() → O(1). 🔵 맨 뒤 요소를 제거하고 길이(ob_size)만 줄이면 됩니다. (메모리가 너무 많이 남으면 축소(resize)될 수 있음)
-
특정 위치 요소 삭제: my_list.pop(i), del my_list[i] → O(n). 🔴 지정된 위치(i)의 요소를 삭제하고, 그 뒤의 모든 요소들을 한 칸씩 앞으로 당겨 빈 공간을 메워야 합니다.
-
특정 값 삭제: my_list.remove(value) → O(n). 🔴 값을 찾기 위해 선형 탐색(O(N))을 하고, 찾은 후에는 해당 요소를 삭제하고 뒤 요소들을 이동(O(N))시켜야 합니다.
-
정렬: my_list.sort() → O(n log n). Timsort라는 효율적인 알고리즘을 사용합니다.
-
뒤집기: my_list.reverse() → O(n). 리스트의 절반만큼 요소 위치를 맞바꿉니다.
-
슬라이스 대입/삭제: my_list[i:j] = iterable, del my_list[i:j] → O(N+k) (N은 리스트 길이, k는 iterable/슬라이스 길이). 관련된 요소들을 이동시키거나 복사해야 할 수 있습니다.
-
튜플
* 특징
-
(소괄호)를 사용하여 생성 (소괄호 생략 가능).
-
한번 생성되면 요소의 추가, 삭제, 수정이 불가능.
-
리스트보다 약간 더 메모리 효율적이고 빠름 (고정 크기).
-
딕셔너리의 키(key) 로 사용될 수 있음 (리스트는 불가).
-
함수의 다중 반환값 처리 등에 유용.
-
리스트와 유사하게 인덱싱, 슬라이싱, len(), in, +, * 연산 가능.
-
변경 관련 연산 (append, insert, pop, remove, sort 등)은 사용 불가!
-
해시테이블
-
집합
* 특징:
- 수학의 집합 개념과 유사 (합집합, 교집합, 차집합 등 연산 가능).
- 요소의 존재 여부를 매우 빠르게 확인 가능 (해시 테이블 기반).
- 요소들이 정렬되어 있지 않음. (입력 순서 유지 안됨 - 단, 내부적으로는 해시값 순서 등으로 관리될 수 있음)
- 요소는 반드시 해시 가능(hashable) 해야 함 (숫자, 문자열, 튜플 등. 리스트, 딕셔너리, 다른 집합은 요소로 가질 수 없음).
* 주요 연산 및 시간 복잡도
- 요소 추가: my_set.add(item) → 평균 O(1), 최악 O(n)
- 요소 제거:
- my_set.remove(item): 요소가 없으면 KeyError 발생. → 평균 O(1), 최악 O(n)
- my_set.discard(item): 요소가 없어도 에러 발생 안 함. → 평균 O(1), 최악 O(n)
- 임의 요소 제거: my_set.pop(): 임의의 요소를 제거하고 반환 (순서 없으므로 어떤게 나올지 모름). 집합이 비면 KeyError. → 평균 O(1), 최악 O(n)
- 모든 요소 제거: my_set.clear() → O(1)
- 요소 포함 확인: item in my_set → 평균 O(1), 최악 O(n)
- 길이 확인: len(my_set) → O(1)
- 합집합: set1 | set2 또는 set1.union(set2) → O(len(set1) + len(set2))
- 교집합: set1 & set2 또는 set1.intersection(set2) → O(min(len(set1), len(set2)))
- 차집합: set1 - set2 또는 set1.difference(set2) → O(len(set1))
- 대칭 차집합: set1 ^ set2 또는 set1.symmetric_difference(set2) → O(len(set1) + len(set2))
-
딕셔너리
* 특징:
-
(중괄호) 안에 key: value 형태로 작성하여 생성.
-
키(Key):
a.고유(Unique) 해야 함. 중복된 키 사용 시 마지막 값으로 덮어써짐.
b.변경 불가능(Immutable) 하고 해시 가능(Hashable) 해야 함. (숫자, 문자열, 튜플 등 사용 가능. 리스트, 딕셔너리, 집합은 키로 사용 불가) -
값(Value):
a.어떤 데이터 타입이든 가능 (숫자, 문자열, 리스트, 다른 딕셔너리 등).
b.중복 가능. -
순서:
Python 3.6 이하: 순서 없음 (unordered). 출력 시 순서 보장 안 됨.
Python 3.7 이상: 입력된 순서가 유지됨 (ordered). (CPython 구현 기준)
* 주요 연산 및 시간 복잡도
- 값 접근/검색: my_dict[key] → 평균 O(1), 최악 O(n) (키가 없으면 KeyError 발생)
- 값 접근 (get): my_dict.get(key, default=None) → 평균 O(1), 최악 O(n) (키가 없어도 에러 대신 default 값 반환)
- 값 추가/수정: my_dict[key] = value → 평균 O(1), 최악 O(n) (키가 이미 있으면 수정, 없으면 추가)
- 값 삭제:
del my_dict[key]: 키가 없으면 KeyError. → 평균 O(1), 최악 O(n)
my_dict.pop(key, default=None): 키가 없으면 default 반환 (없으면 KeyError). → 평균 O(1), 최악 O(n) - 키 존재 확인: key in my_dict → 평균 O(1), 최악 O(n)
- 길이 확인: len(my_dict) → O(1)
- 모든 키 보기: my_dict.keys() → 뷰(view) 객체 반환. O(1)
- 모든 값 보기: my_dict.values() → 뷰 객체 반환. O(1)
- 모든 키-값 쌍 보기: my_dict.items() → 뷰 객체 반환. O(1)
- 모든 요소 제거: my_dict.clear() → O(1)
-
