이 글에서는 무엇을 말할까?
- 우선 Join의 종류에 대해 간단하게 설명할 것이다. 그래야 내가 겪은 문제를 이해할 수 있다.
- join의 원리를 잘못 이해하여 QueryDSL로 groupby 를 사용할 때 삽질했던 경험을 공유한다.
join의 종류
내가 겪은 문제와 관련이 있는 join에 대해서 간단히 집고 넘어가보겠다.
- inner join : 기준 테이블과 조인 테이블 모두 데이터가 존재해야 조회된다.
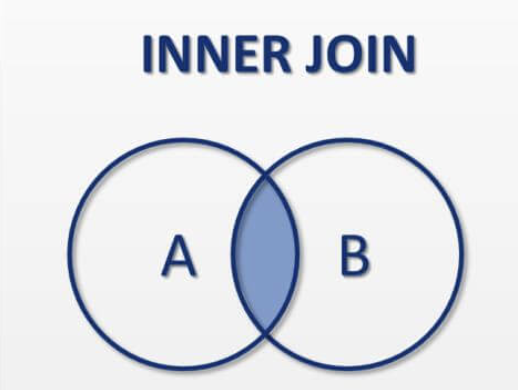
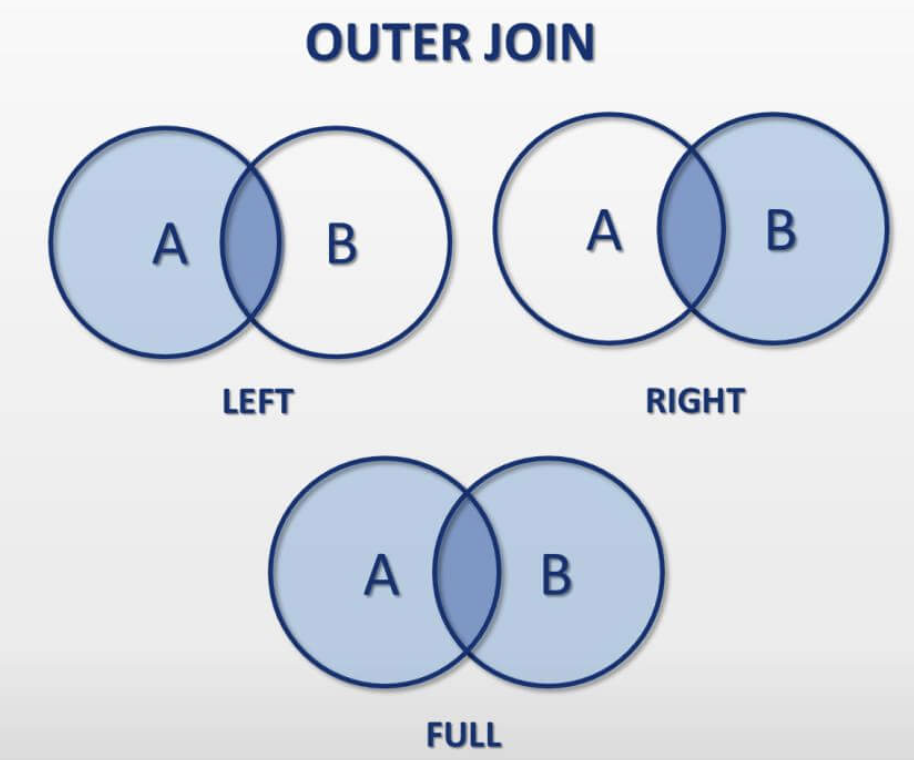
- outer join : 기준(left든 right든)테이블에만 데이터가 존재하면 조회 된다.
내가 겪은 문제는 이 2개 join의 결과가 같았을 때 발생했다. 예시는 아래 사진과 같다
![]()
자 이제 간단하게 join에 대해 설명은 끝났으니 JPA에서 무슨 문제가 있었는지 설명해보겠다.
우선 간단하게 요구사항을 설명해보겠다.
![]()
위와 같은 테이블 구조가 있고 반환해줘야하는 데이터는 아래 json 형태와 같다.
{
[
parent_id : 1,
name : "parent_name",
childList : [
{
"id": 1,
"name": "child1"
},
{
"id": 2,
"name": "child2"
},
....
],
parent_id : 2,
name : "parent_name2",
childList : [
{
"id": 3,
"name": "child3"
},
{
"id": 4,
"name": "child4"
},
....
]
]
}이해를 편하게 하기 위해 작성했던 Class 몇개만 올려두겠다. 전체 코드는 깃헙링크 에서 확인해보면 된다.
Parent Class
@Entity
@Getter
@Builder
@AllArgsConstructor
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name", length = 200)
private String name;
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY)
private List<Child> children = new ArrayList<Child>();
}
Child Class
@Entity
@Getter
@Builder
@AllArgsConstructor
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name", length = 200)
private String name;
@JsonIgnore
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "parent_id")
private Parent parent;
}
ParentAndChildDto Class
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ParentAndChildDto {
private Long id;
private String name;
private List<ChildDto> childDtoList = new ArrayList<>();
}
ChildDto
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ChildDto {
private Long id;
private String name;
}
굳이 Parent와 Child를 양방향으로 연결한 이유는 요구사항에서 Parent의 수를 기준으로 Pagination기능을 넣어달라고 하셔서 양방향이 가능하게 하였다.
위의 요구사항을 보고 가장 먼저 든 생각은 groupBy를 쓰는 것이었다.
groupBy를 쓰면 아주 간단하고 빠르게 문제가 해결될 것 같았다.
실제 요구사항에서는 다양한 검색조건, 정렬조건 등이 있었기 때문에 querydsl를 이용하였다.
그리고 그렇게 나는 inner join을 사용했다.
이유는 간단했다. 솔직히 inner join, left join 결과가 같을꺼라고 예상이 되니 아무거나 써도 된다고 생각했고 실제로 필요한 데이터는 교집합인 데이터만 필요했으니 inner join을 사용했다.
그렇게 코드를 작성했다.
내 코딩 스타일은 보통 처음부터 끝까지 다 완성한다음에 테스트를 하는 것이 아닌 스케치를 먼저 하고 색을 칠하듯이 간단하게 필요한 조건을 하나씩 추가해보면서 원하는 데이터가 잘 나오는지 중간중간 확인해보면서 코드를 작성한다.
아래는 테스트 겸 첫번째로 작성했던 코드이다.
public Map<Long, List<Child>> findChildOfParentInnerJoin() {
return queryFactory.from(parent)
.innerJoin(parent.children, child)
.transform(groupBy(parent.id).as(list(child)));
}결과는 아래와 같이 완벽했다.
groupBy를 위와 같이 쓴 이유는 Map구조로 return이 가능하고 내가 원하던 형태와 유사했기 때문이다. 참조한 블로그
{
"1": [
{
"id": 1,
"name": "child1"
},
{
"id": 3,
"name": "child3"
}
],
"2": [
{
"id": 2,
"name": "child2"
},
{
"id": 4,
"name": "child4"
}
],
"3": [
{
"id": 5,
"name": "child5"
},
{
"id": 6,
"name": "child6"
}
]
}그리고 코드를 다시 이렇게 수정했다.(아주 자신만만하게)
public List<ParentAndChildDto> findChildOfParent() {
return queryFactory.from(parent)
.innerJoin(parent.children, child)
.transform(groupBy(parent.id).list(
Projections.fields(
ParentAndChildDto.class,
parent.id,
parent.name,
list(
Projections.fields(
ChildDto.class,
child.id,
child.name
)
).as("childDtoList")
)
));
}
근데 결과가...
[
{
"id": 1,
"name": "parent1",
"childDtoList": [
{
"id": 1,
"name": "child1"
}
]
},
{
"id": 2,
"name": "parent2",
"childDtoList": [
{
"id": 2,
"name": "child2"
}
]
},
{
"id": 1,
"name": "parent1",
"childDtoList": [
{
"id": 3,
"name": "child3"
}
]
},
...
]이렇게 나오는 것이었다. 같은 id로 groupBy를 못해주고 있었다.
DB에 무슨 데이터가 잘못됐나 계속 살펴봤지만 아무 문제는 없었고 약 3시간 가량 고민하다가 찾아낸 결과는 groupBy를 하기전에 정렬을 하는 것이었다.
public List<ParentAndChildDto> findChildOfParent() {
return queryFactory.from(parent)
.innerJoin(parent.children, child)
.orderBy(parent.id.asc()) // 정렬 조건 추가
.transform(groupBy(parent.id).list(
Projections.fields(
ParentAndChildDto.class,
parent.id,
parent.name,
list(
Projections.fields(
ChildDto.class,
child.id,
child.name
)
).as("childDtoList")
)
));
}이렇게 하니까 갑자기 귀신같이 원하던 결과가 잘 나왔다...
하지만 이해가 가지 않았다.
이때까지도 innerjoin은 아무 잘못없어보였다.
모든 경우의 수를 테스트 한 후에 마지막 남은 하나의 경우의 수인 inner join을 left join으로 바꿔 테스트를 하였다.
갑자기 모든 문제가 해결됐다.
왜 됐을까?
위에서 내가 언급했던 inner join과 left outer join의 결과를 다시 보고오자.
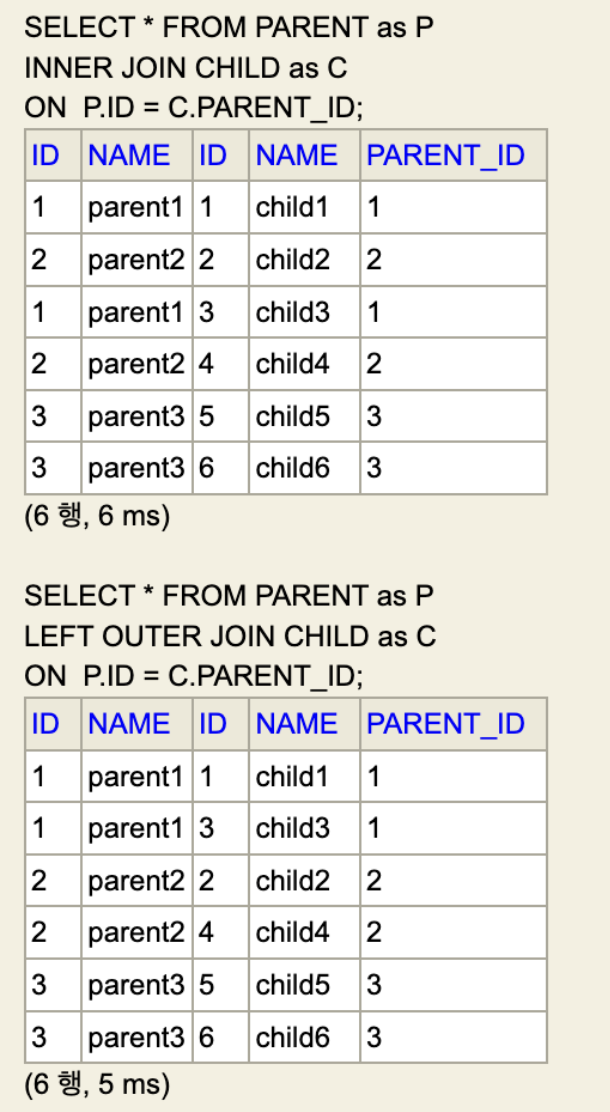
사실 처음에 결과가 같다고 생각했지만 같은 것이 아니었다.
Inner join은 정렬이 안되지만 left Outer join은 Parent table의 id를 기준으로 자동 정렬되었다. 내부적으로 자동 정렬이 되는 것이었다.
근데 groupBy가 정렬이 필요해..? 라고 생각하면 아니였다.
그래서 일반적으로 쓰는 groupBy로 테스트를 해보니 정렬과 상관없이 groupby가 잘 되었다.
쿼리를 확인해보았다.
transform(groupby...를 사용한 groupby는 사실 groupby쿼리를 날리는 것이 아니었다. 실제 db에 날아가는 쿼리는
select
parent0_.id as col_0_0_,
parent0_.id as col_1_0_,
parent0_.name as col_2_0_,
children1_.id as col_3_0_,
children1_.name as col_4_0_
from
parent parent0_
left outer join
child children1_
on parent0_.id=children1_.parent_id 위의 모습과 같았고 transform을 통해 내부적으로 map으로 변환시켜주는 것이었다.
일반적인 groupby가 잘 작동했던 이유는 실제로 groupby 쿼리가 함께 날아가기 때문이었다.
결론
transform(groupby...위의 폼을 사용해서 groupBy를 map 형태로 받고 싶다면...
내부적으로 정렬된 상태에서만 groupBy가 가능한 것 같다.
방법 1 : 정렬조건을 추가한다.
방법 2 : left join을 사용한다.(혹은 정렬이 되는 join)
제가 잘못이해하고 있거나 잘못 작성한 부분이 있다면 지적, 비판, 피드백 뭐든 해주시면 감사하겠습니다!
